Групиран агрегатен избутване
Изпращане на данни от SentryOne към калкулатора DTU на базата данни на Azure SQL
Минимално регистриране с INSERT...SELECT в Heap Tables
Въведение в статистиката за чакане
Най-близкото съвпадение, част 1
Подобрете производителността на UDF с NULL НА NULL INPUT
Използване на причинно-следствената връзка за разбиране на изпълнението на заявка
Най-близкото съвпадение, част 2
Клониране на бази данни с PSDatabaseClone
Пример за оценка на нивата на съвместимост и кардиналността
Най-близкото съвпадение, част 3
Мигриране от AnswerHub към WordPress:Приказка за 10 технологии
T-SQL вторник #106:ВМЕСТО тригери
Специални острови
Какво да правите (или да не правите) относно най-добрите статистики за чакане
Решения за читатели за предизвикателството на специалните острови
Разбиране на изтриването на буфера на журнала
Прагове за оптимизиране – групиране и агрегиране на данни, част 2
Значението на изходните линии
Прагове за оптимизиране – групиране и агрегиране на данни, част 3

Ръководство за проектиране на база данни за календарни събития и напомняния в MySQL
Mysql
Основи на табличните изрази, част 7 – CTE, съображения за оптимизация
Database
Онлайн инструменти за изпробване на SQL дизайн и заявки
Database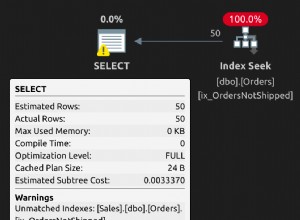
Филтрирани индекси и принудителна параметризация (редукс)
Database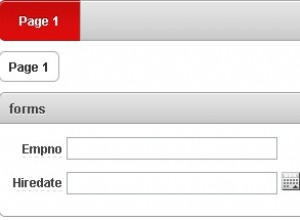
Създаване на формуляр в APEX за задаване на променливи в заявка за интерактивен отчет
Oracle
Тестване на мрежово натоварване с помощта на iPerf
Database