Като консултант, работещ със SQL Server, много пъти ме карат да разгледам сървър, който изглежда, че има проблеми с производителността. Докато извършвам сортиране на сървъра, задавам определени въпроси, като например:какво е нормалното ви използване на процесора, какви са средните ви латентности на диска, какво е нормалното ви използване на паметта и т.н. Отговорът обикновено е „не знаем“ или „не улавяме тази информация редовно“. Липсата на скорошно изходно ниво прави много трудно да се разбере как изглежда ненормалното поведение. Ако не знаете какво е нормално поведение, как да разберете със сигурност дали нещата са по-добри или по-лоши? Често използвам изразите „ако не го наблюдаваш, не можеш да го измериш“ и „ако не го измерваш, не можеш да го управляваш“.
От гледна точка на наблюдение, като минимум, организациите трябва да наблюдават неуспешни задачи като архивиране, поддръжка на индекси, DBCC CHECKDB и всякакви други важни задачи. Лесно е да настроите известия за неуспехи за тях; но също така се нуждаете от процес, за да сте сигурни, че заданията се изпълняват според очакванията. Виждал съм работни места, които се окачват и никога не са завършени. Уведомление за неизправност няма да задейства аларма, тъй като задачата никога не е успешна или неуспешна.
От базова линия на ефективността има няколко ключови показатели, които трябва да бъдат уловени. Създадох процес, който използвам с клиенти, който редовно улавя ключови показатели и съхранява тези стойности в потребителска база данни. Моят процес е прост:специална база данни със съхранени процедури, които използват общи скриптове, които вмъкват наборите от резултати в таблици. Имам задачи на SQL Agent за изпълнение на съхранените процедури на редовни интервали и скрипт за почистване за изчистване на данни, по-стари от X дни. Показателите, които винаги улавям, включват:
Продължителност на живота на страницата :PLE е може би един от най-добрите начини да прецените дали вашата система е под натиск от вътрешната памет. Повечето системи имат PLE стойности, които се колебаят по време на нормални натоварвания. Обичам да променям тези стойности, за да знам какви са минималните, средните и максималните стойности. Харесва ми да се опитам да разбера какво е причинило спад на PLE през определени часове от деня, за да видя дали тези процеси могат да бъдат настроени. Много пъти някой прави сканиране на таблицата и промива буферния пул. Възможността за правилно индексиране на тези заявки може да помогне. Просто се уверете, че наблюдавате правилния PLE брояч – вижте тук .
Използване на процесора :Наличието на базова линия за използване на процесора ви позволява да знаете, ако вашата система внезапно е под натиск на процесора. Често, когато потребителят се оплаква от проблеми с производителността, той ще забележи, че процесорът изглежда високо. Например, ако CPU се движи около 80%, те може да намерят това притеснително, но ако CPU също е бил 80% през същото време през предходните седмици, когато не са докладвани проблеми, вероятността процесът да е проблемът е много ниска. Тенденционният CPU не е само за улавяне, когато процесорът скача и остава на постоянно висока стойност. Имам много истории за това, когато бях докаран в мост за конференция с една сериозност, защото имаше проблем с приложение. Като DBA, носех шапката на „Приемател на обвинения по подразбиране“. Когато екипът на приложението каза, че има проблем с базата данни, трябваше да докажа, че не е, сървърът на базата данни беше виновен, докато не се докаже, че е невинен. Ярко си спомням инцидент, при който екипът на приложението беше уверен, че сървърът на базата данни има проблеми, защото потребителите не могат да се свържат. Те бяха чели в интернет, че SQL Server може да страда от глад на пула на нишки, ако отказва връзки. Скочих на сървъра и започнах да разглеждам ресурсите и какви процеси се изпълняваха в момента. След няколко минути съобщих, че въпросният сървър е много отегчен. Въз основа на нашите базови показатели, процесорът обикновено беше 60% и беше неактивен около 20%, продължителността на живота на страницата беше забележимо по-висока от нормалната и нямаше заключване или блокиране, I/O изглеждаше страхотно, няма грешки в никакви регистрационни файлове и броят на сесиите беше около 1/3 от нормалния им брой. След това направих коментар:„Изглежда, че потребителите дори не достигат до сървъра на базата данни.“ Това привлече вниманието на хората в мрежата и те разбраха, че промяната, която направиха в балансиращото натоварване, не работи правилно и установиха, че над 50% от връзките се насочват неправилно и не стигат до сървъра на базата данни. Ако не знаех каква е изходната линия, щеше да ни отнеме много повече време, за да постигнем резолюцията.
Диск I/O :Улавянето на дискови метрики е много важно. DMV sys.dm_io_virtual_file_stats е кумулативен от последното рестартиране на сървъра. Улавянето на вашите I/O латентности за определен интервал от време ще ви даде базова линия за това, което е нормално през това време. Разчитането на кумулативната стойност може да ви даде изкривени данни от дейности след работно време или дълги периоди, когато системата е била неактивна. Пол обсъди това тук .
Размери на файлове на базата данни :Наличието на инвентаризация на вашите бази данни, която включва размер на файла, използван размер, свободно пространство и други, може да ви помогне да прогнозирате растежа на базата данни. Често ме молят да прогнозирам колко място за съхранение ще е необходимо за сървър на база данни през следващата година. Без да знам седмичната или месечната тенденция на растеж, нямам начин интелигентно да измисля фигура. След като започна да проследявам тези стойности, мога правилно да променя това. В допълнение към тенденцията, можех да открия и кога има неочакван растеж на базата данни. Когато видя неочакван растеж и разследвам, обикновено откривам, че някой или е дублирал таблица, за да направи някои тестове (да, в производството!), или е извършил някакъв друг еднократен процес. Проследяването на този тип данни и възможността да реагирате при възникване на аномалии помага да се покаже, че сте проактивни и наблюдавате системите си.
Изчакайте статистика :Наблюдението на статистиката за чакане може да ви помогне да започнете да откривате причината за определени проблеми с производителността. Много нови администратори на база данни се притесняват, когато за първи път започнат да изследват статистически данни за чакане и не осъзнават, че чаканията винаги се случват и това е просто начинът, по който работи системата за планиране на SQL Server. Има и много изчаквания, които могат да се считат за доброкачествени или най-вече безобидни. Пол Рандъл изключва тези предимно безобидни изчаквания в своя популярен скрипт за статистика за чакане. Пол също така е изградил огромна библиотека от различни типове на изчакване и заключващи класове с описания и друга информация за отстраняване на неизправности при изчаквания и ключалки.
Документирах процеса на събиране на данни и можете да намерите кода в моя блог . В зависимост от ситуацията и видовете проблеми, които клиентът може да има, може също да искам да заснема допълнителни показатели. Глен Бери публикува блог за процес, който той събра, който улавя среден брой задачи, среден брой изпълнявани задачи, среден брой чакащи I/O, използване на процесора на SQL Server и средна продължителност на живота на страницата във всички NUMA възли. Бързо търсене в интернет ще открие няколко други процеса за събиране на данни, които хората са споделили, дори SQL Server Tiger Team има процес, който използва T-SQL и PowerShell.
Използването на персонализирана база данни и изграждането на ваш собствен пакет за събиране на данни е валидно решение за улавяне на базова линия, но повечето от нас не се занимават с изграждане на пълноценни решения за наблюдение на SQL Server. Има много повече, които биха били полезни за улавяне, неща като продължителни заявки, топ заявки и съхранени процедури, базирани на памет, I/O и CPU, блокиране, фрагментиране на индекс, транзакции в секунда и много други. За това винаги препоръчвам на клиентите да закупят инструмент за наблюдение на трета страна. Тези доставчици са специализирани в поддържането на най-новите тенденции и функции на SQL Server, така че да можете да съсредоточите времето си върху това да се уверите, че SQL Server е възможно най-стабилен и бърз.
Решения като SQL Sentry (за SQL Server) и DB Sentry (за Azure SQL база данни) улавя всички тези показатели вместо вас и ви позволява лесно да създавате различни базови линии. Можете да имате нормално изходно ниво, края на месеца, края на тримесечието и др. След това можете да приложите базовата линия и да видите визуално как нещата са различни. По-важното е, че можете да конфигурирате произволен брой сигнали за различни условия и да получавате известия, когато показателите надхвърлят вашите прагове.
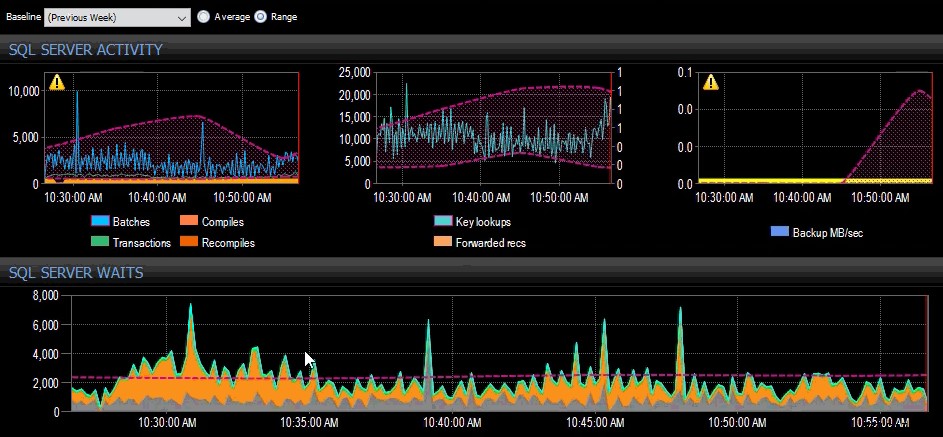 Базовата линия от миналата седмица е приложена към няколко показателя на SQL Server в таблото за управление на SQL Sentry.
Базовата линия от миналата седмица е приложена към няколко показателя на SQL Server в таблото за управление на SQL Sentry.
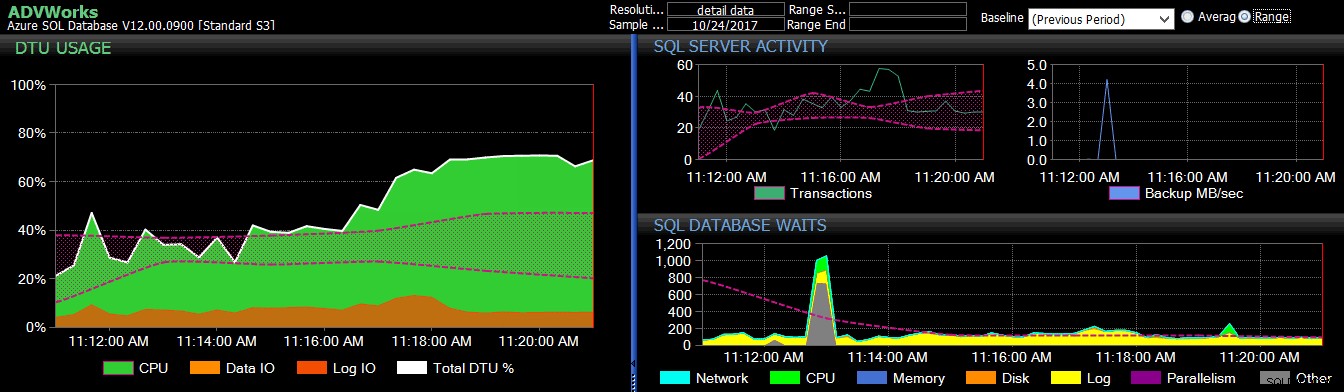 Основната линия от предишния период се прилага към няколко показателя на Azure SQL база данни на таблото за управление на DB Sentry.
Основната линия от предишния период се прилага към няколко показателя на Azure SQL база данни на таблото за управление на DB Sentry.
За повече информация относно изходните линии в SentryOne вижте тези публикации на техния екипен блог или този 2-минутно видео във вторник . Интересувате ли се от изтегляне на пробна версия? И там са ви покрили .