Тази статия е втората от поредица за прагове за оптимизация, свързани с групирането и агрегирането на данни. В част 1 предоставих формулата за обратно проектиране за операторската цена на Stream Aggregate. Обясних, че този оператор трябва да консумира редовете, подредени от набора за групиране (всякакъв ред на неговите членове), и че когато данните се получат предварително подредени от индекс, получавате линейно мащабиране по отношение на броя на редовете и броя на групи. Освен това в такъв случай не е необходимо предоставяне на памет.
В тази статия се фокусирам върху изчисляването на разходите и мащабирането на операция, базирана на агрегатен поток, когато данните не се получават предварително поръчани от индекс, а трябва да бъдат сортирани първо.
В моите примери ще използвам примерната база данни PerformanceV3, както в част 1. Можете да изтеглите скрипта, който създава и попълва тази база данни от тук. Преди да стартирате примерите от тази статия, уверете се, че първо изпълните следния код, за да пуснете няколко ненужни индекса:
ОТПУСКАНЕ ИНДЕКС idx_nc_sid_od_cid НА dbo.Orders; ИЗПУСКАНЕ ИНДЕКС idx_unc_od_oid_i_cid_eid НА dbo.Orders;
Единствените два индекса, които трябва да останат в тази таблица, са idx_cl_od (клъстериран с orderdate като ключ) и PK_Orders (неклъстериран с orderid като ключ).
Сортиране + Обобщение на потока
Фокусът на тази статия е да се опитаме да разберем как се мащабира агрегатната операция на поток, когато данните не са предварително подредени от набора за групиране. Тъй като операторът Stream Aggregate трябва да обработи подредените редове, ако те не са предварително подредени в индекс, планът трябва да включва изричен оператор за сортиране. Така че цената на обобщената операция, която трябва да вземете предвид, е сумата от разходите на операторите Sort + Stream Aggregate.
Ще използвам следната заявка (ще я наречем Заявка 1), за да демонстрирам план, включващ такава оптимизация:
ИЗБЕРЕТЕ shipperid, MAX(orderdate) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
Планът за тази заявка е показан на фигура 1.

Фигура 1:План за заявка 1
Причината да използвам табличен израз с TOP филтър е да контролирам точния брой (приблизителни) редове, участващи в групирането и агрегирането. Прилагането на контролирани промени улеснява опитите и обратното проектиране на формулите за изчисляване на разходите.
Ако се чудите защо да филтрирате толкова малък брой редове в този пример, това е свързано с праговете за оптимизация, които правят тази стратегия предпочитана пред алгоритъма на Hash Aggregate. В част 3 ще опиша изчисляването на разходите и мащабирането на алтернативата на хеш. В случаите, когато оптимизаторът не избере сама по себе си агрегатна операция на потока, например когато са включени голям брой редове, винаги можете да го принудите с намек OPTION(ORDER GROUP) по време на процеса на изследване. Когато се фокусирате върху изчисляването на разходите за серийни планове, очевидно можете да добавите намек за MAXDOP 1, за да премахнете паралелизма.
Както бе споменато, за да оцените цената и мащаба на непредварително поръчан агрегиран алгоритъм за поток, трябва да вземете предвид сумата от операторите Sort + Stream Aggregate. Вече знаете формулата за изчисляване на разходите за оператора Stream Aggregate от част 1:
@numrows * 0,0000006 + @numgroups * 0,0000005В нашата заявка имаме 100 прогнозни входни реда и 5 прогнозни изходни групи (5 отделни идентификатора на изпращача, изчислени въз основа на информация за плътността). Така че цената на оператора Stream Aggregate в нашия план е:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Нека се опитаме да разберем формулата за изчисляване на разходите за оператора Sort. Не забравяйте, че фокусът ни е върху прогнозната цена и мащабирането, защото крайната ни цел е да разберем праговете за оптимизиране, при които оптимизаторът променя избора си от една стратегия към друга.
Оценката на разходите за I/O изглежда е фиксирана:0,0112613. Получавам една и съща цена за вход/изход, независимо от фактори като брой редове, брой колони за сортиране, тип данни и т.н. Това вероятно се дължи на някаква очаквана I/O работа.
Що се отнася до цената на процесора, уви, Microsoft не излага публично точните алгоритми, които използват за сортиране. Въпреки това, сред често срещаните алгоритми, използвани за сортиране от двигателите на базата данни като цяло, са различни реализации на сортиране чрез сливане и бързо сортиране. Благодарение на усилията, положени от Пол Уайт, който обича да разглежда следите на стека за отстраняване на грешки в Windows (не всички имаме стомах за това), имаме малко повече поглед върху темата, публикувана в неговата поредица „Internals of the Seven SQL Server Сортове.” Според констатациите на Пол общият клас за сортиране (използван в горния план) използва сортиране чрез сливане (първо вътрешно, след това преминаване към външно). Средно този алгоритъм изисква n log n сравнения, за да сортира n елемента. Имайки това предвид, вероятно е безопасен залог като отправна точка да приемем, че частта на CPU от разходите на оператора се основава на формула като:
CPU цена на оператора =<начална цена> + @numrows * LOG(@numrows) * <цена за сравнение>Разбира се, това може да е прекалено опростяване на действителната формула за изчисляване на разходите, която Microsoft използва, но при липса на никаква документация по въпроса, това е първоначалното най-добро предположение.
След това можете да получите разходите за сортиране на процесора от два плана на заявка, създадени за сортиране на различен брой редове, да речем 1000 и 2000, и въз основа на тези и горната формула да извършите обратно инженерство на разходите за сравнение и разходите за стартиране. За тази цел не е нужно да използвате групирана заявка; достатъчно е просто да направите основно ORDER BY. Ще използвам следните две заявки (ще ги наречем Заявка 2 и Заявка 3):
SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Смисълът на подреждането според резултата от изчисление е да се принуди операторът за сортиране да се използва в плана.
Фигура 2 показва съответните части от двата плана:
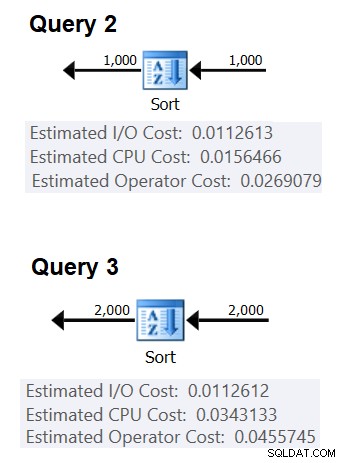
Фигура 2:Планове за заявка 2 и заявка 3
За да опитате да извлечете цената на едно сравнение, ще използвате следната формула:
сравнителна цена =
((<заявка 3 цена на процесора> – <начална цена> ) – (<Цена на процесора за заявка 2> – <цена при стартиране> ))
/ (
(0,0343133 – 0,0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2,25061348918698E-06
Що се отнася до началната цена, можете да я заключите въз основа на всеки от плановете, например въз основа на плана, който сортира 2000 реда:
начална цена =0.0343133 – 2000*LOG(2000) * 2.25061348918698E-06 =9.99127891201565E-0156
И по този начин нашата формула за сортиране на разходите на процесора става:
CPU цена на оператора за сортиране =9,99127891201865E-05 + @numrows * LOG(@numrows) * 2,25061348918698E-06Използвайки подобни техники, ще откриете, че фактори като средния размер на реда, броя на колоните за подреждане и техните типове данни не влияят на прогнозната цена на процесора за сортиране. Единственият фактор, който изглежда релевантен, е прогнозният брой редове. Обърнете внимание, че сортирането ще се нуждае от предоставяне на памет и предоставянето е пропорционално на броя на редовете (не на групите) и на средния размер на реда. Но в момента фокусът ни е върху прогнозните разходи на оператора и изглежда, че тази оценка се влияе само от прогнозния брой редове.
Тази формула изглежда прогнозира цената на процесора до праг от около 5000 реда. Опитайте със следните числа:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
ИЗБЕРЕТЕ numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 КАТО предвидени разходи ОТ (СТОЙНОСТИ(100), (200), (300), (100) , (2000), (3000), (4000), (5000)) AS D(numrows);
Сравнете какво предвижда формулата и прогнозните разходи на процесора, които плановете показват за следните заявки:
SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 като myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Получих следните резултати:
numrows predicatedcost приблизителен коефициент на разходите ----------- --------------- -------------- --- ---- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133 1.00000 3000 0.0541576 0.0541576 1.00000 4000 0.0747667 0.0747665 1.00000 5000 0.0959445 0.0959442 1.00000
Колоната predictedcost показва прогнозата въз основа на нашата формула за обратно проектиране, колоната prodictedcost показва прогнозната цена, която се появява в плана, а съотношението на колоната показва съотношението между последната и първата.
Предсказанието изглежда доста точно до 5000 реда. Въпреки това, с числа, по-големи от 5000, нашата формула за обратно проектиране спира да работи добре. Следната заявка ви дава прогнозите за 6K, 7K, 10K, 20K, 100K и 200K редове:
ИЗБЕРЕТЕ numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 КАТО предвидени разходи ОТ (VALUES(6000), (7000), (20000), (100000), (100000) ) AS D(numrows);
Използвайте следните заявки, за да получите приблизителните разходи на процесора от плановете (обърнете внимание на намека да наложите сериен план, тъй като при по-голям брой редове е по-вероятно да получите паралелен план, където формулите за изчисляване на разходите са коригирани за паралелизъм):
ИЗБЕРЕТЕ идентификатор на поръчка % 1000000000 като myorderid ОТ (ИЗБЕРЕТЕ TOP (6000) * FROM dbo.Orders) КАТО D ПОРЪЧАЙТЕ ПО myorderid ОПЦИЯ(MAXDOP 1); ИЗБЕРЕТЕ идентификатор на поръчка % 1000000000 като myorderid ОТ (SELECT TOP (7000) * FROM dbo.Orders) КАТО D ORDER BY myorderid OPTION(MAXDOP 1); ИЗБЕРЕТЕ идентификатор на поръчка % 1000000000 като myorderid ОТ (SELECT TOP (10000) * FROM dbo.Orders) КАТО D ORDER BY myorderid OPTION(MAXDOP 1); ИЗБЕРЕТЕ идентификатор на поръчка % 1000000000 като myorderid ОТ (SELECT TOP (20000) * FROM dbo.Orders) КАТО D ORDER BY myorderid OPTION(MAXDOP 1); ИЗБЕРЕТЕ идентификатор на поръчка % 1000000000 като myorderid ОТ (SELECT TOP (100000) * FROM dbo.Orders) КАТО D ORDER BY myorderid OPTION(MAXDOP 1); ИЗБЕРЕТЕ идентификатор на поръчка % 1000000000 като myorderid ОТ (SELECT TOP (200000) * FROM dbo.Orders) КАТО D ORDER BY myorderid OPTION(MAXDOP 1);
Получих следните резултати:
numrows predicatedcost приблизителен коефициент на разходите ----------- --------------- -------------- --- --- 6000 0.117575 0.160970 1.3691 7000 0.139583 0.244848 1.7541 10000 0.207389 0.603420 2.9096 20000 0.445878 1.311710 2.9419 100000 2.591210 7.623920 2.9422 200000 5.494330 16.165700 2.9423
Както можете да видите, след 5000 реда нашата формула става все по-малко точна, но любопитното е, че съотношението на точност се стабилизира на около 2,94 при около 20 000 реда. Това означава, че при големи числа нашата формула все още се прилага, само с по-висока цена за сравнение и че приблизително между 5 000 и 20 000 реда, тя преминава постепенно от по-ниската цена за сравнение към по-високата. Но какво би могло да обясни разликата между малкия и големия мащаб? Добрата новина е, че отговорът не е толкова сложен, колкото съвместяването на квантовата механика и общата теория на относителността с теорията на струните. Просто в по-малкия мащаб Microsoft иска да отчете факта, че е вероятно да се използва кеш паметта на процесора и за целите на разходите те приемат фиксиран размер на кеша.
Така че, за да разберете разходите за сравнение в голям мащаб, искате да използвате сортирането на CPU разходите от два плана за числа над 20 000. Ще използвам 100 000 и 200 000 реда (последните два реда в таблицата по-горе). Ето формулата за извеждане на цената за сравнение:
сравнителна цена =(16,1657 – 7,62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6,62193536908588E-06
След това ето формулата за извеждане на началните разходи въз основа на плана за 200 000 реда:
начална цена =16,1657 – 200000*LOG(200000) * 6,62193536908588E-06 =1,35166186417734E-04
Много добре може да се окаже, че началните разходи за малки и големи мащаби са еднакви и че разликата, която получихме, се дължи на грешки при закръгляването. Във всеки случай, при голям брой редове, първоначалните разходи стават незначителни в сравнение с разходите за сравнение.
В обобщение, ето формулата за цената на процесора на оператора за сортиране за големи числа (>=20000):
Операторска цена на процесора =1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06Нека тестваме точността на формулата с 500K, 1M и 10M редове. Следният код ви дава прогнозите на нашата формула:
ИЗБЕРЕТЕ numrows, 1.35166186417734E-04 + numrows * LOG(numrows) * 6.62193536908588E-06 AS предвидени разходи ОТ (VALUES(500000), (1000000 AS), (1000000 AS), (0100000 AS);Използвайте следните заявки, за да получите прогнозните разходи за процесора:
ИЗБЕРЕТЕ идентификатор на поръчка % 1000000000 като myorderid ОТ (ИЗБЕРЕТЕ TOP (500000) * FROM dbo.Orders) КАТО D ORDER BY myorderid OPTION(MAXDOP 1); ИЗБЕРЕТЕ идентификатор на поръчка % 1000000000 като myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) КАТО D ПОРЪЧКА ПО myorderid OPTION(MAXDOP 1); ИЗБЕРЕТЕ КОНТРОЛНА СУМА(NEWID()) като myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Ords AS O2) КАТО D ORDER BY myorderid OPTION(MAXDOP 1);Получих следните резултати:
numrows predicatedcost приблизителен коефициент на разходите ----------- --------------- -------------- --- --- 500000 43,4479 43,448 1,0000 1000000 91,4856 91,486 1,0000 10000000 1067,3300 1067,340 1,0000Изглежда, че нашата формула за големи числа се справя доста добре.
Сглобяване на всичко
Общата цена за прилагане на агрегат за поток с изрично сортиране за малък брой редове (<=5000 реда) е:
<Разходи за сортиране на I/O> + <Сортиране на CPU цена> +=
0.0112613
+ 9.99127891201865E-05 + @numrows * LOG(@ numrows) * 2.25061348918698E-06
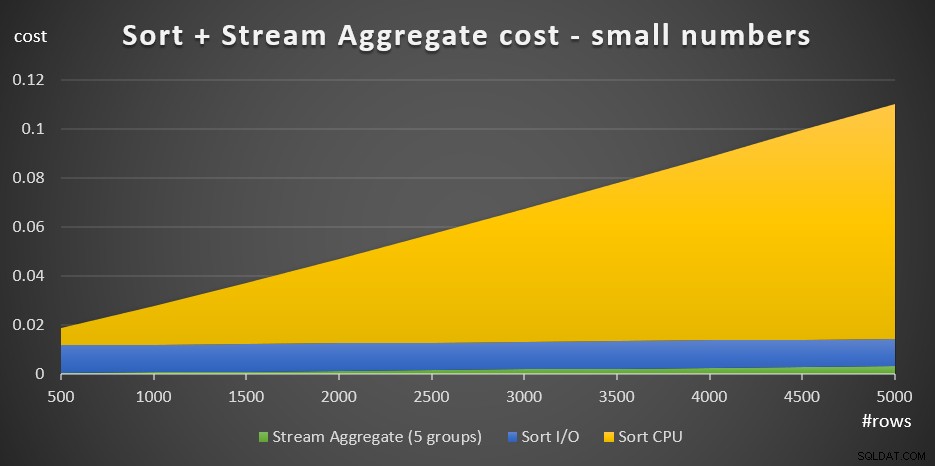
+ @numrows * 0.0000006 + @numgroups * 0.0000005Фигура 3 има диаграма с площи, показваща как се мащабират тези разходи.
Фигура 3:Разходи за сортиране + агрегат за поток за малък брой редовеЦената на процесора за сортиране е най-съществената част от общите агрегатни разходи за сортиране + поток. И все пак, с малък брой редове, стойността на потока Aggregate и частта за сортиране I/O от цената не са съвсем незначителни. Визуално можете да видите ясно и трите части на диаграмата.
Що се отнася до голям брой редове (>=20 000), формулата за изчисляване на разходите е:
0.0112613
+ 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+ @numrows * 0.06 нагоре * 0.06 нагоре * 0.060.Не видях голяма полза в преследването на точния начин на прехода на разходите за сравнение от малкия към големия мащаб.
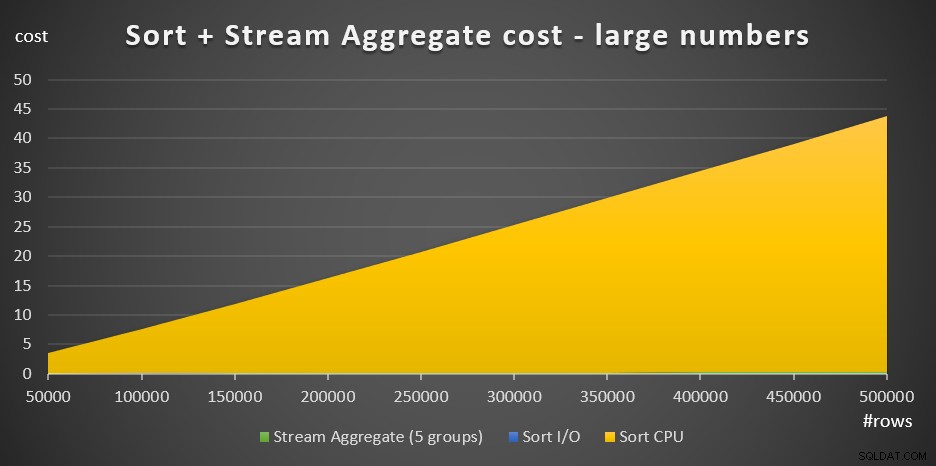
Фигура 4 има диаграма с площи, показваща как се мащабират разходите за големи числа.
Фигура 4:Разходи за сортиране + агрегат за поток за голям брой редовеПри голям брой редове стойността на Stream Aggregate и Sort I/O цената са толкова незначителни в сравнение с цената на CPU за сортиране, че дори не се виждат с просто око в диаграмата. В допълнение, частта от разходите за сортиране на процесора, приписана на стартиращата работа, също е незначителна. Следователно единствената част от изчисляването на разходите, която има наистина значение, е общата цена за сравнение:
@numrows * LOG(@numrows) * <разходи за сравнение>Това означава, че когато трябва да оцените мащабирането на стратегията Sort + Stream Aggregate, можете да я опростите само до тази доминираща част. Например, ако трябва да оцените как цената ще се увеличи от 100 000 реда до 100 000 000 реда, можете да използвате формулата (обърнете внимание, че цената за сравнение е без значение):
(100000000 * LOG(100000000)* <разходи за сравнение>) / (100000 * LOG(100000)* <разходи за сравнение>) =1600Това ви казва, че когато броят на редовете се увеличи от 100 000 с коефициент 1 000 до 100 000 000, прогнозната цена се увеличава с коефициент 1 600.
Мащабирането от 1 000 000 до 1 000 000 000 реда се изчислява като:
(1000000000 * LOG(1000000000)) / (1000000 * LOG(1000000)) =1500Тоест, когато броят на редовете се увеличи от 1 000 000 с коефициент 1 000, прогнозната цена се увеличава с коефициент 1 500.
Това са интересни наблюдения за начина, по който стратегията Sort + Stream Aggregate се мащабира. Поради много ниската си стартова цена и допълнително линейно мащабиране, бихте очаквали тази стратегия да се справи добре с много малък брой редове, но не толкова добре с големи числа. Освен това фактът, че операторът Stream Aggregate сам по себе си представлява толкова малка част от разходите в сравнение с това, когато е необходимо и сортиране, ви казва, че можете да получите значително по-добра производителност, ако ситуацията е такава, че можете да създадете поддържащ индекс .
В следващата част от поредицата ще разгледам мащабирането на алгоритъма на Hash Aggregate. Ако ви харесва това упражнение да се опитвате да разберете формули за изчисляване на разходите, вижте дали можете да го разберете за този алгоритъм. Важното е да разберете факторите, които го влияят, начина му на мащабиране и условията, при които се справя по-добре от другите алгоритми.