Един от най-често срещаните термини, които се появяват в дискусиите относно настройката на производителността на SQL Server, е статистика на чакането . Това се връща много назад, дори преди този документ на Microsoft от 2006 г. "SQL Server 2005 чака и опашки."
Изчакванията не са абсолютно всичко и тази методология не е единственият начин за настройка на екземпляр, без значение за индивидуална заявка. Всъщност чаканията често са безполезни, когато всичко, което имате, е заявката, която ги е претърпяла, и никакъв заобикалящ контекст, особено дълго след факта. Това е така, защото доста често това, което една заявка чака не е по вина на заявката . Като всяко нещо има изключения, но ако избирате инструмент или скрипт само защото предлага тази много специфична функционалност, мисля, че си правите лоша услуга. Склонен съм да следвам един съвет, който Пол Рандал ми даде преди време:
...по принцип препоръчвам да започнете с изчакване на целия екземпляр. Никога не бих започнал отстраняване на неизправности чрез разглеждане на отделните изчакващи заявки.
Понякога, да, може да искате да копаете по-дълбоко в отделна заявка и да видите какво чака тя; всъщност Microsoft наскоро добави статистика за чакане на ниво заявка, за да покаже план, за да помогне с този анализ. Но тези числа обикновено няма да ви помогнат да настроите производителността на вашия екземпляр като цяло, освен ако не помагат да се посочи нещо, което също оказва влияние върху цялото ви работно натоварване. Ако видите една заявка от вчера, която се изпълняваше в продължение на 5 минути, и забележите, че нейният тип на изчакване е LCK_M_S , какво ще правиш сега? Как ще проследите какво всъщност е блокирало заявката и е причинило този тип чакане? Може да е било причинено от транзакция, която не е била ангажирана по някаква друга причина, но не можете да видите това, ако не можете да видите състоянието на цялата система и се фокусирате само върху отделните заявки и изчакванията, които са изпитали.
Джейсън Хол (@SQLSaurus) мимоходом спомена нещо, което беше интересно и за мен. Той каза, че ако статистиката за изчакване на ниво заявка беше толкова важна част от усилията за настройка, че тази методология щеше да бъде включена в Query Store от самото начало. Той беше добавен наскоро (в SQL Server 2017). Но все още не получавате статистика за изчакване на изпълнение; получавате средни стойности във времето, като статистиката на заявката и статистиката на процедурите, която виждате в DMV. Така че внезапните аномалии може да са очевидни въз основа на други показатели, които се улавят при изпълнение на заявка, но не въз основа на средните стойности на времената на изчакване, които се изтеглят върху всички екзекуции. Можете да персонализирате обхвата на изчакванията да се обобщават, но при натоварени системи това все още може да не е достатъчно детайлно, за да направите това, което смятате, че ще направи за вас.
Целта на тази публикация е да обсъдим някои от по-често срещаните видове изчакване, които виждаме в нашата клиентска база, и какви действия можете (и не трябва) да предприемете, когато се случат. Имаме база данни с анонимни статистически данни за изчакване, които събираме от нашите клиенти на Cloud Sync от доста време и от май 2017 г. показваме на всички как те изглеждат в библиотеката SQLskills Waits.
Пол говори за причината за библиотеката, както и за нашата интеграция с тази безплатна услуга. По принцип вие търсите тип чакане, който изпитвате или сте любопитни, и той обяснява какво означава това и какво можете да направите по въпроса. Ние допълваме тази качествена информация с диаграма, показваща колко разпространено е текущото чакане сред нашата потребителска база, сравнявайки това с всички останали видове чакане, които виждаме, така че можете бързо да разберете дали имате работа с общ тип чакане или нещо малко повече екзотичен. (Имайте предвид, че SQL Sentry не включва доброкачествените, фонови и опашки изчаквания, които представляват шум и че повечето от скриптовете там се филтрират, като WAITFOR или LAZYWRITER_SLEEP – това просто не са източници на проблеми с производителността.)
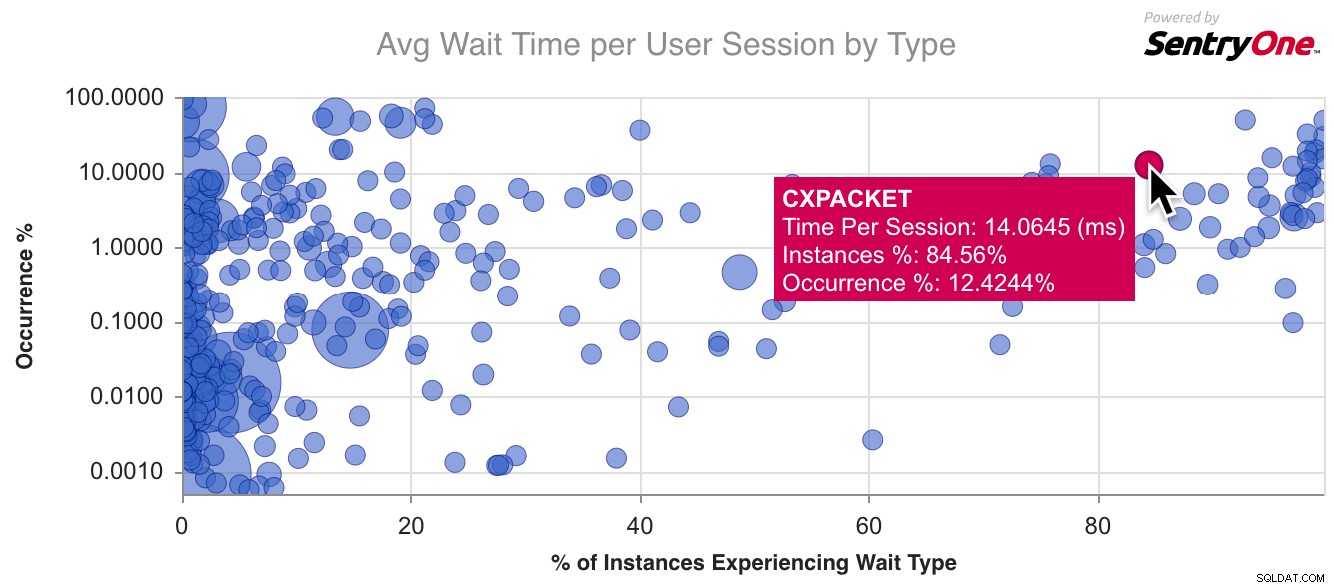
Ето примерна диаграма за CXPACKET , най-често срещаният тип чакане:
Започнах да отивам малко по-далеч от това, начертавайки някои от по-често срещаните типове чакане и отбелязвайки някои от свойствата, които споделят. Преведено във въпроси, които тунерът може да има за типа на изчакване, който изпитва:
- Може ли типът на чакане да бъде решен на ниво заявка?
- Възможно ли е основният симптом на чакането да повлияе на други заявки?
- Вероятно ли е да имате нужда от повече информация извън контекста на една заявка и видовете изчаквания, които изпитва, за да „решите“ проблема?
Когато се заех да напиша тази публикация, целта ми беше просто да групирам най-често срещаните типове изчакване и след това да започна да записвам бележки за тях, свързани с горните въпроси. Джейсън извади най-често срещаните от библиотеката, а след това нарисувах малко пилешка драскотина върху бяла дъска, която по-късно подредих малко. Това първоначално проучване доведе до разговор, който Джейсън изнесе за най-новия TechOutbound SQL Cruise в Аляска. Някак се срамувам, че той проведе разговор месеци преди да успея да завърша този пост, така че нека просто да продължим с него. Ето най-големите изчаквания, които виждаме (които до голяма степен съвпадат с проучването на Пол от 2014 г.), моите отговори на горните въпроси и някои коментари за всеки:
За да взаимодействате с връзките в таблицата по-долу, моля, посетете тази страница на по-широк екран.
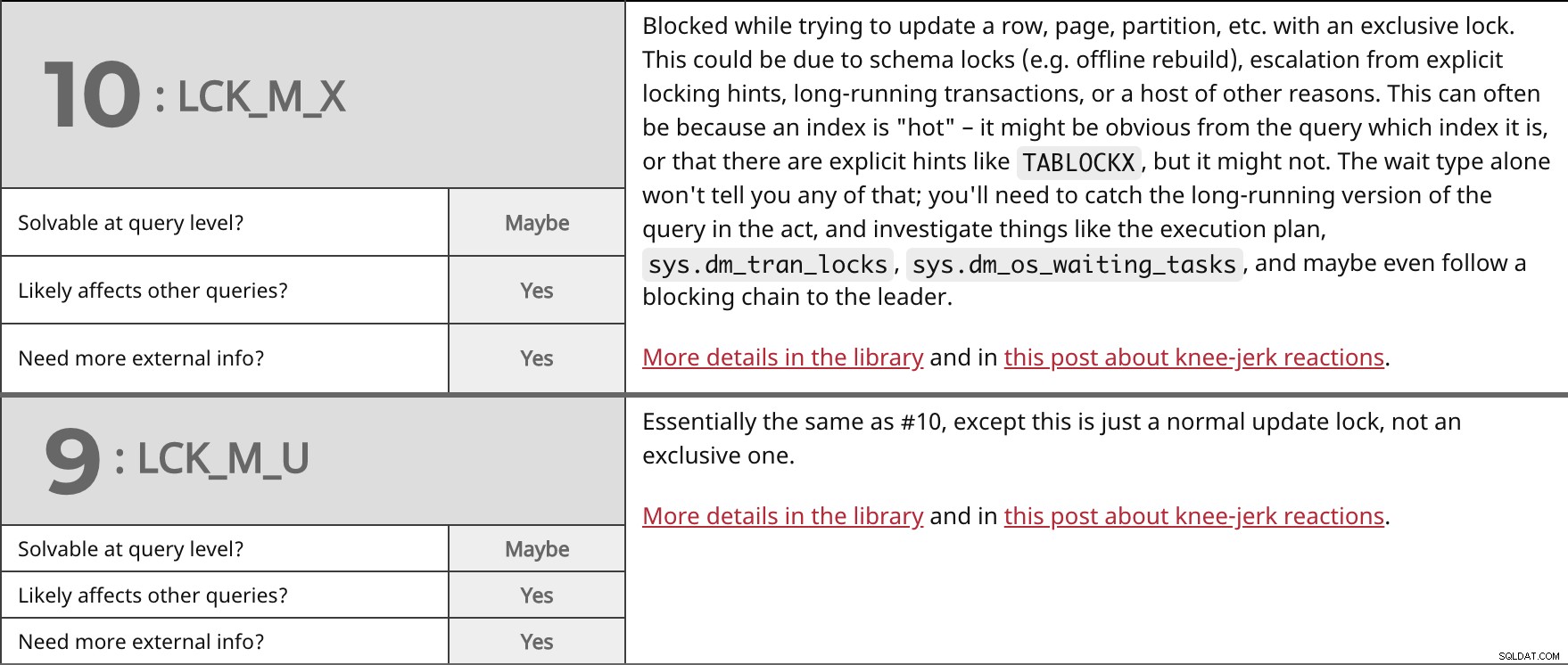
Блокиран при опит за актуализиране на ред, страница, дял и т.н. с изключително заключване. Това може да се дължи на заключвания на схеми (например офлайн повторно изграждане), ескалация от изрични намеци за заключване, продължителни транзакции или множество други причини. Това често може да се дължи на факта, че индексът е „горещ“ – може да е очевидно от заявката кой индекс е или че има изрични намеци като TABLOCKX , но може и да не е така. Типът чакане сам по себе си няма да ви каже нищо от това; ще трябва да хванете продължителната версия на заявката в действие и да проучите неща като плана за изпълнение, sys.dm_tran_locks , sys.dm_os_waiting_tasks , и може би дори последвайте блокираща верига до лидера. Повече подробности в библиотеката и в тази публикация за реакциите на коляното. | ||
| Разрешимо на ниво заявка? | Може би | |
| Да | ||
| Имате нужда от повече външна информация? | Да | |
|
По същество същото като #10, с изключение на това, че това е просто нормално заключване на актуализацията, а не изключително. Повече подробности в библиотеката и в тази публикация за реакциите на коляното. | ||
| Разрешимо на ниво заявка? | Може би | |
| Да | ||
| Имате нужда от повече външна информация? | Да | |
|
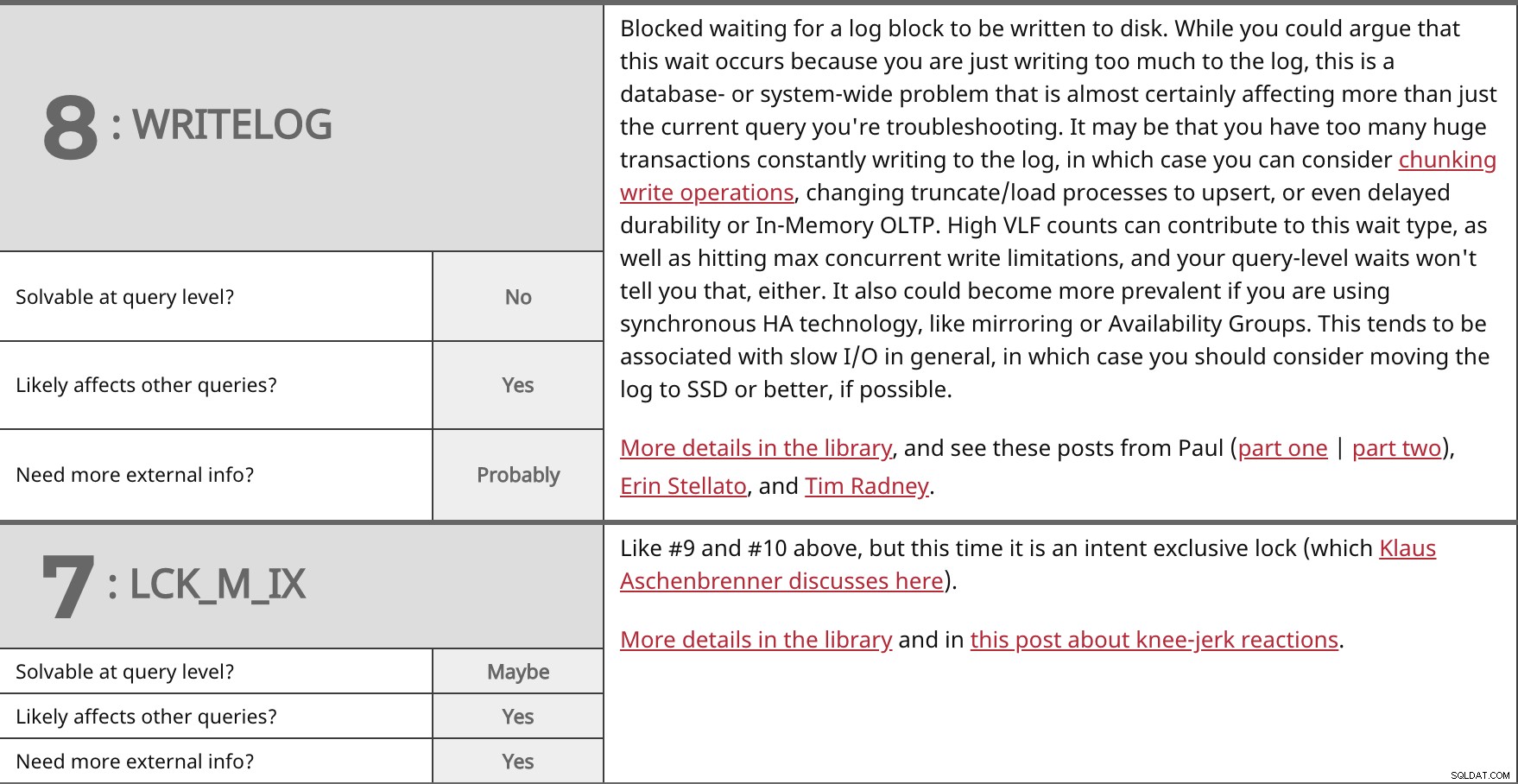
Блокира се, чака се запис на регистрационен блок на диска. Въпреки че бихте могли да твърдите, че това изчакване се случва, защото просто пишете твърде много в дневника, това е проблем в базата данни или в цялата система, който почти сигурно засяга повече от само текущата заявка, която отстранявате. Възможно е да имате твърде много огромни транзакции, които постоянно записват в регистрационния файл, в който случай можете да помислите за разделяне на операции за запис, промяна на процесите на съкращаване/зареждане на upsert или дори забавена издръжливост или OLTP в паметта. Високите стойности на VLF могат да допринесат за този тип чакане, както и за достигане на максималните ограничения за едновременно записване, а изчакванията на ниво заявка също няма да ви кажат това. Също така може да стане по-разпространено, ако използвате синхронна HA технология, като огледално копиране или групи за наличност. Това обикновено се свързва с бавен I/O като цяло, в който случай трябва да помислите за преместване на регистрационния файл на SSD или по-добре, ако е възможно. Повече подробности в библиотеката и вижте тези публикации от Пол (част първа | част втора), Ерин Стелато и Тим Радни. | ||
| Разрешимо на ниво заявка? | Не | |
| Да | ||
| Имате нужда от повече външна информация? | Вероятно | |
|
Като #9 и #10 по-горе, но този път това е изключително заключване (което Клаус Ашенбренер обсъжда тук). Повече подробности в библиотеката и в тази публикация за реакциите на коляното. | ||
| Разрешимо на ниво заявка? | Може би | |
| Да | ||
| Имате нужда от повече външна информация? | Да | |
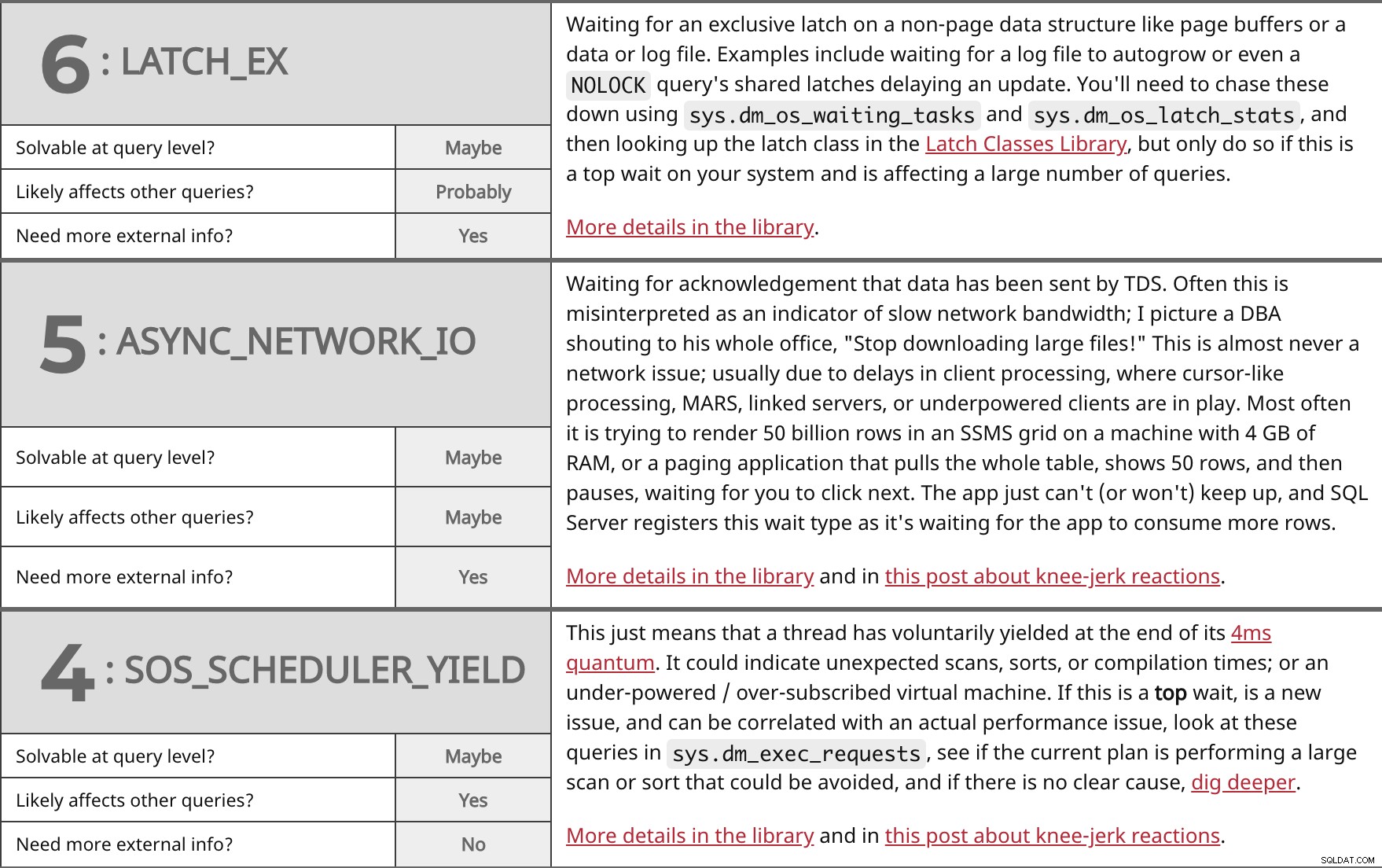
Чака се ексклузивно заключване на структура от данни извън страницата, като буфери на страници или файл с данни или регистрационен файл. Примерите включват изчакване за автоматично нарастване на регистрационен файл или дори NOLOCK споделените ключалки на заявката забавят актуализацията. Ще трябва да ги преследвате с помощта на sys.dm_os_waiting_tasks и sys.dm_os_latch_stats , и след това потърсете класа Latch в библиотеката Latch Classes, но го направете само ако това е най-голямо изчакване във вашата система и засяга голям брой заявки. Повече подробности в библиотеката. | ||
| Разрешимо на ниво заявка? | Може би | |
| Вероятно | ||
| Имате нужда от повече външна информация? | Да | |
|
Изчаква се потвърждение, че данните са изпратени от TDS. Често това се тълкува погрешно като индикатор за бавна честотна лента на мрежата; Представям си DBA, който крещи на целия си офис:„Спрете да изтегляте големи файлове!“ Това почти никога не е проблем с мрежата; обикновено поради закъснения в обработката на клиента, когато в играта са подобна на курсора обработка, MARS, свързани сървъри или клиенти с недостатъчно мощност. Най-често се опитва да изобрази 50 милиарда реда в SSMS мрежа на машина с 4 GB RAM или приложение за пейджинг, което изтегля цялата таблица, показва 50 реда и след това прави пауза, чакайки да щракнете върху следващия. Приложението просто не може (или няма) да се справи и SQL Server регистрира този тип на изчакване, тъй като изчаква приложението да консумира повече редове. Повече подробности в библиотеката и в тази публикация за реакциите на коляното. | ||
| Разрешимо на ниво заявка? | Може би | |
| Може би | ||
| Имате нужда от повече външна информация? | Да | |
Това просто означава, че дадена нишка доброволно е отстъпила в края на своя квант от 4 мс. Може да показва неочаквани сканирания, сортиране или времена за компилация; или виртуална машина с недостатъчно захранване/прекомерно абонаментиране. Ако това е отгоре чакайте, е нов проблем и може да бъде свързан с действителен проблем с производителността, вижте тези заявки в sys.dm_exec_requests , вижте дали текущият план извършва голямо сканиране или сортиране, което може да бъде избегнато, и ако няма ясна причина, копайте по-дълбоко. Повече подробности в библиотеката и в тази публикация за реакциите на коляното. | ||
| Разрешимо на ниво заявка? | Може би | |
| Да | ||
| Имате нужда от повече външна информация? | Не | |
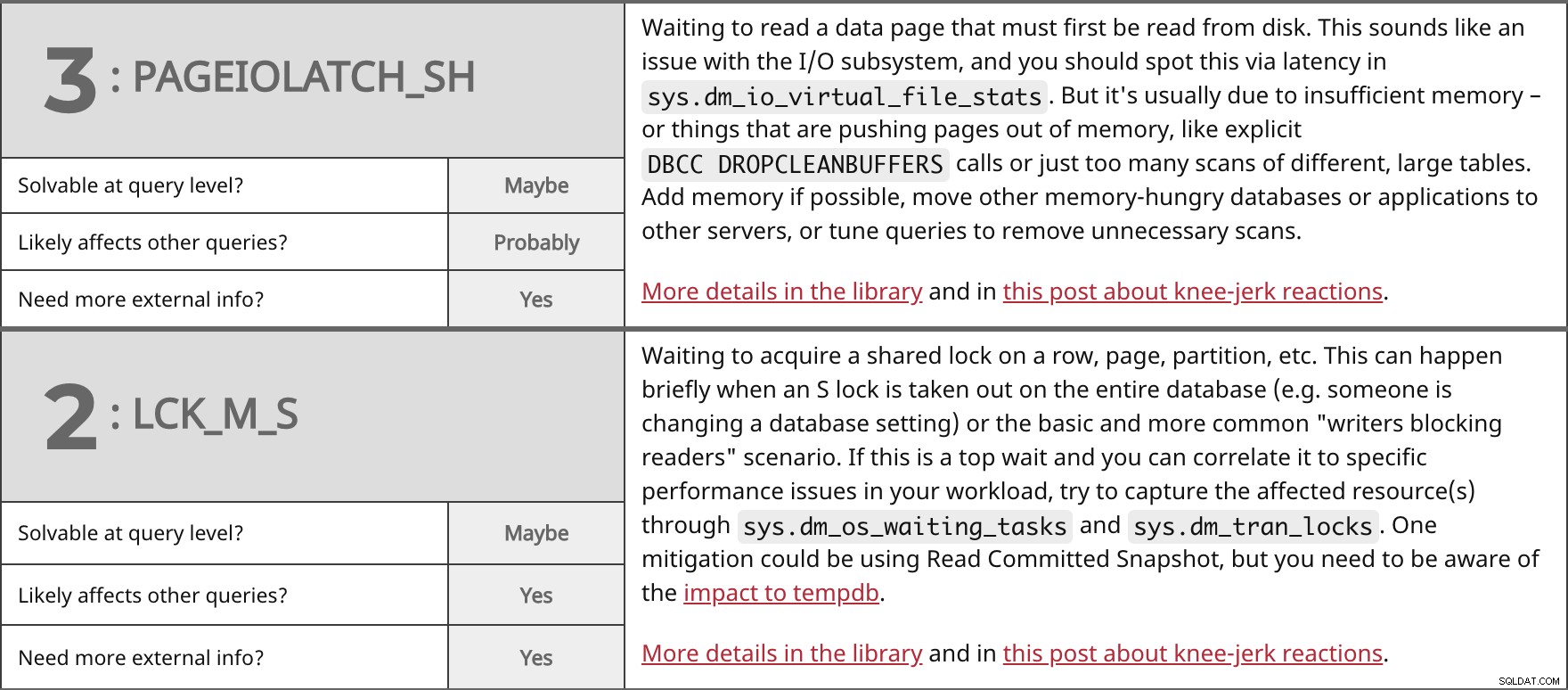
Изчаква се четене на страница с данни, която първо трябва да бъде прочетена от диска. Това звучи като проблем с I/O подсистемата и трябва да забележите това чрез латентност в sys.dm_io_virtual_file_stats . Но обикновено се дължи на недостатъчна памет – или неща, които изтласкват страници от паметта, като изрично DBCC DROPCLEANBUFFERS обаждания или просто твърде много сканирания на различни големи таблици. Добавете памет, ако е възможно, преместете други жадни за памет бази данни или приложения на други сървъри или настройте заявки, за да премахнете ненужните сканирания. Повече подробности в библиотеката и в тази публикация за реакциите на коляното. | ||
| Разрешимо на ниво заявка? | Може би | |
| Вероятно | ||
| Имате нужда от повече външна информация? | Да | |
Изчаква се придобиване на споделено заключване на ред, страница, дял и т.н. Това може да се случи за кратко, когато се извади S заключване на цялата база данни (напр. някой променя настройка на база данни) или основният и по-често срещан сценарий „писатели блокират читателите“. Ако това е най-голямо чакане и можете да го свържете с конкретни проблеми с производителността в работното си натоварване, опитайте се да уловите засегнатите ресурс(и) чрез sys.dm_os_waiting_tasks и sys.dm_tran_locks . Едно смекчаване може да бъде използването на Read Committed Snapshot, но трябва да сте наясно с въздействието върху tempdb. Повече подробности в библиотеката и в тази публикация за реакциите на коляното. | ||
| Разрешимо на ниво заявка? | Може би | |
| Да | ||
| Имате нужда от повече външна информация? | Да | |
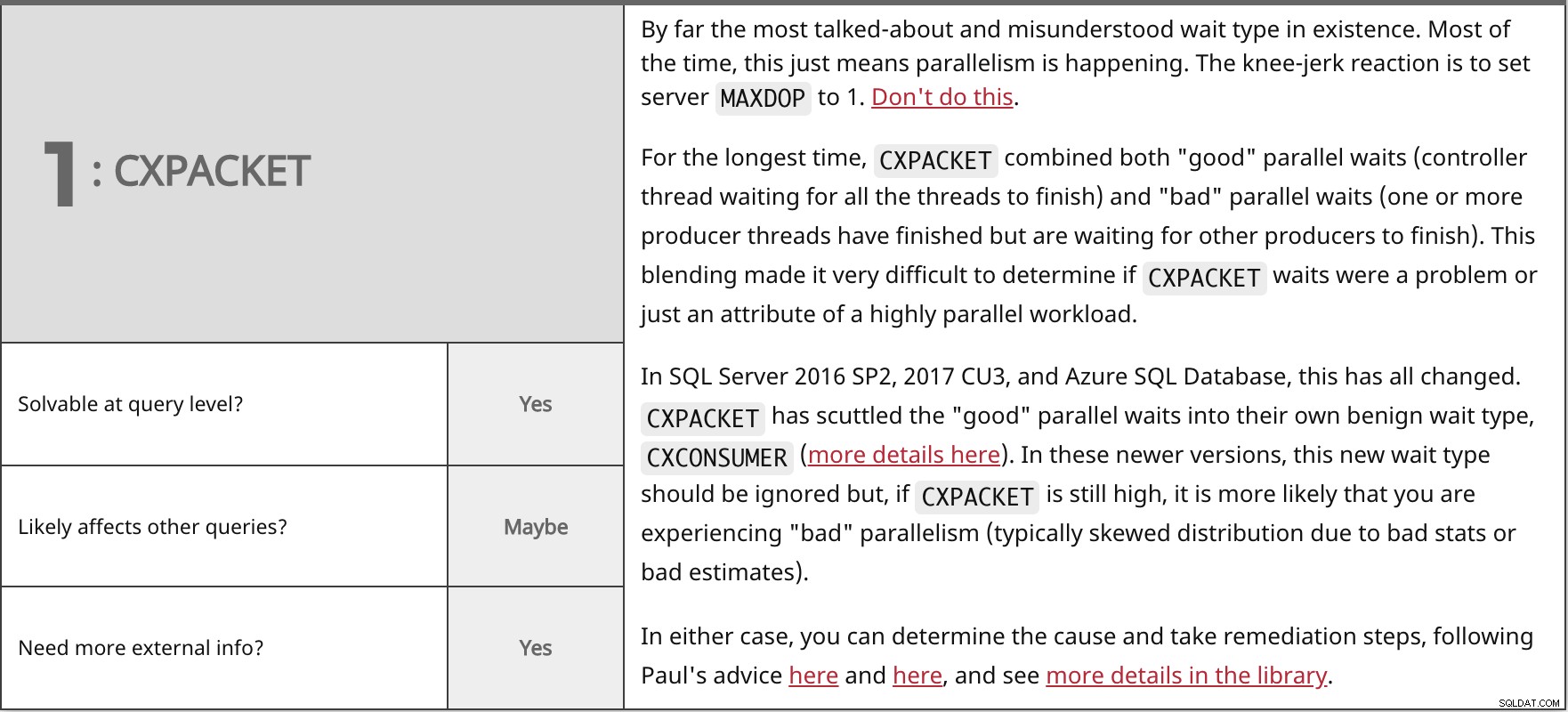
Досега най-обсъжданият и неразбран тип чакане, който съществува. През повечето време това просто означава, че се случва паралелизъм. Реакцията на коляното е да настроите сървър MAXDOP до 1. Не правете това.
За най-дълго време
В SQL Server 2016 SP2, 2017 CU3 и Azure SQL база данни всичко това се промени. И в двата случая можете да определите причината и да предприемете стъпки за отстраняване, като следвате съветите на Пол тук и тук, и да видите повече подробности в библиотеката. | ||
| Разрешимо на ниво заявка? | Да | |
| Може би | ||
| Имате нужда от повече външна информация? | Да | |
Резюме
В повечето от тези случаи е по-добре да гледате на изчакванията на ниво екземпляр и да се ориентирате само към изчаквания на ниво заявка, когато отстранявате неизправности при конкретни заявки, които показват проблеми с производителността, независимо от типа на чакане. Това са неща, които се появяват по други причини, като продължителна продължителност, висока CPU или висок I/O, и не могат да се обяснят с по-прости неща (като сканиране на клъстерен индекс, когато сте очаквали търсене).
Дори на ниво екземпляр, не преследвайте всяко изчакване, което се превръща в най-голямото изчакване във вашата система – вие ВИНАГИ изчакайте най-много и никога няма да можете да спрете да го преследвате. Уверете се, че игнорирате доброкачествените изчаквания (Пол поддържа списък) и се тревожете само за изчаквания, които можете да свържете с действителен проблем с производителността, който изпитвате. Ако CXPACKET чаканията са големи, и какво от това? Има ли други симптоми освен това числото да е „високо“ или да е в горната част на списъка?
Всичко се свежда до това защо отстранявате проблеми на първо място. Дали един потребител се оплаква от един екземпляр на фалшива заявка? Вашият сървър е на колене? Нещо по средата? В първия случай, разбира се, знаенето защо една заявка е бавна може да бъде полезно, но е доста скъпо да проследите (няма значение да запазите за неопределено време) всички изчаквания, свързани с всяка една заявка, през целия ден, всеки ден, при случайния случай искате да се върнете и да ги прегледате по-късно. Ако това е широко разпространен проблем, изолиран от тази заявка, трябва да можете да определите какво прави тази заявка бавна, като я стартирате отново и съберете плана за изпълнение, времето за компилация и други показатели по време на изпълнение. Ако това е еднократно нещо, което се е случило миналия вторник, независимо дали имате чакания за този единствен екземпляр на заявката или не, може да не сте в състояние да разрешите проблема без повече контекст. Може би е имало блокиране, но няма да знаете от какво, или може би е имало I/O скок, но ще трябва да отидете да проследите този проблем отделно. Типът чакане сам по себе си обикновено просто не предоставя достатъчно информация, освен в най-добрия случай указател към нещо друго.
Разбира се, и тук трябва да спечеля прехраната си. Нашият водещ продукт, SQL Sentry, използва холистичен подход към наблюдението. Ние събираме статистически данни за изчакване за целия екземпляр, категоризираме ги вместо вас и ги изобразяваме в графика на нашето табло:
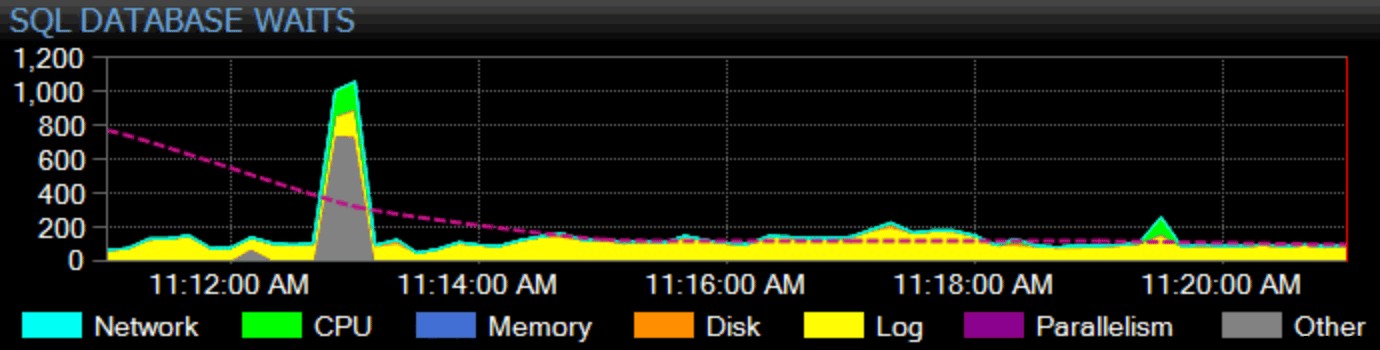
Можете да персонализирате как се категоризира всяко отделно чакане и дали тази категория дори се показва на таблото за управление. Можете да сравните текущите статистически данни за изчакване с вградени или персонализирани базови линии и дори да настроите сигнали или действия, когато надвишават определено отклонение от базовото ниво. И, може би най-важното, можете да разгледате точка от данни от миналото и да синхронизирате цялото табло за управление с този момент във времето, така че да можете да уловите целия заобикалящ контекст и всяка друга ситуация, която може да е повлияла на проблема. Когато намерите по-детайлни неща, върху които да се съсредоточите, като блокиране, висока латентност на диска или заявки с висок I/O или дълга продължителност, можете да разгледате тези показатели и да стигнете до корена на проблема доста бързо.
За повече информация както за общите подходи за изчакване, така и за нашето решение конкретно, можете да разгледате бялата книга на Кевин Клайн, Отстраняване на неизправности на SQL Server за изчакване на статистики, и можете да изтеглите уебинар от две части, представен от Пол Рандал, Анди Юн (@SQLBek), и Анди Малън (@AMtwo):
- Част 1:Отстраняване на проблеми с производителността с помощта на статистика за чакане
- Част 2:Бърз анализ на статистиката за чакане със SentryOne
И ако искате да завъртите платформата SentryOne, можете да започнете тук с оферта за ограничено време:
Изтеглете 15-дневна безплатна пробна версия