Наскоро стартирахме нов сайт за поддръжка, където можете да задавате въпроси, да изпращате отзиви за продукти или заявки за функции или да отваряте билети за поддръжка. Част от целта беше да централизираме всички места, където предлагахме помощ на общността. Това включваше сайта за въпроси и отговори SQLPerformance.com, където Пол Уайт, Хюго Корнелис и много други помагаха да се решат най-сложните въпроси за настройка на заявката и план за изпълнение, стигайки чак до февруари 2013 г. Казвам ви със смесени чувства, че Сайтът за въпроси и отговори е затворен.
Има обаче и обратна страна. Вече можете да задавате тези трудни въпроси в новия форум за поддръжка. Ако търсите старото съдържание, то все още е там, но изглежда малко по-различно. Поради различни причини, за които няма да влизам днес, след като решихме да спрем оригиналния сайт за въпроси и отговори, в крайна сметка решихме просто да хостваме цялото съществуващо съдържание на WordPress сайт само за четене, вместо да го мигрираме в задния край на новия сайт.
Тази публикация не е за причините зад това решение.
Чувствах се много зле от това колко бързо трябваше да излезе офлайн сайтът за отговори, DNS се превключи и съдържанието мигрира. Тъй като на сайта беше внедрен предупредителен банер, но AnswerHub всъщност не го направи видим, това беше шок за много потребители. Затова исках да се уверя, че съхранявам правилно възможно най-много от съдържанието и исках то да е правилно. Тази публикация е тук, защото реших, че би било интересно да поговорим за действителния процес, колко различни части от технологиите са участвали в извършването му и да покажа резултата. Не очаквам някой от вас да се възползва от този край до край, тъй като това е сравнително неясен път на миграция, а по-скоро като пример за обвързване на куп технологии заедно за изпълнение на задача. Също така ми служи като добро напомняне, че много неща в крайна сметка не са толкова лесни, колкото звучат, преди да започнете.
TL;DR е следното:прекарах куп време и усилия, за да направя архивираното съдържание да изглежда добре, въпреки че все още се опитвам да възстановя последните няколко публикации, които дойдоха към края. Използвах тези технологии:
- Perl
- SQL сървър
- PowerShell
- Предаване (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Оттук и заглавието. Ако искате голяма част от кървавите детайли, ето ги. Ако имате въпроси или обратна връзка, моля, свържете се или коментирайте по-долу.
AnswerHub предостави 665 MB файл с дъмп от базата данни MySQL, която е домакин на съдържанието на въпроси и отговори. Всеки редактор, който опитах, се задави, така че първо трябваше да го разбия на файл за таблица, използвайки този удобен Perl скрипт от Джаред Чейни. Таблиците, от които се нуждаех, се наричаха network11_nodes (въпроси, отговори и коментари), network11_authoritables (потребители) и network11_managed_files (всички прикачени файлове, включително качвания на план):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Сега те не бяха изключително бързи за зареждане в SSMS, но поне там можех да използвам Ctrl +H за да промените (например) това:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
Към това:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
След това можех да заредя данните в SQL Server, за да мога да ги манипулирам. И повярвайте ми, аз го манипулирах.
След това трябваше да извлека всички прикачени файлове. Вижте, дъмп файлът на MySQL, който получих от доставчика, съдържаше един милион INSERT изявления, но нито един от действителните планови файлове, които потребителите са качили — базата данни имаше само относителните пътища до файловете. Използвах T-SQL, за да създам серия от команди на PowerShell, които ще извикат Invoke-WebRequest за да извлечете всички файлове и да ги съхраните локално (много начини да обедрите тази котка, но това беше лесно). От това:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Това доведе до този набор от команди (заедно с предварителна команда за разрешаване на този проблем с TLS); цялото нещо мина доста бързо, но не препоръчвам този подход за никаква комбинация от {massive set of files} и/или {low bandwidth}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Това изтегли почти всички прикачени файлове, но, разбира се, някои бяха пропуснати поради грешки в стария сайт, когато бяха качени първоначално. Така че в новия сайт понякога може да видите препратка към прикачен файл, който не съществува.
След това използвах Panic Transmit 5, за да кача temp папка към новия сайт и сега, когато съдържанието се качи, връзки към /s/temp/1-proc.pesession ще продължи да работи.
След това преминах към SSL. За да поискаме сертификат на новия сайт на WordPress, трябваше да актуализираме DNS за answers.sqlperformance.com, за да сочи CNAME към нашия хост WordPress, WPEngine. Тук беше нещо като пиле и яйце - трябваше да претърпим известно време за престой за https URL адреси, които биха се провалили без сертификат на новия сайт. Това беше добре, защото сертификатът на стария сайт беше изтекъл, така че наистина не бяхме по-зле. Освен това трябваше да изчакам да направя това, докато изтеглих всички файлове от стария сайт, защото след като DNS се обърне, нямаше да има начин да стигна до тях, освен през някаква задна врата.
Докато чаках DNS да се разпространи, започнах да работя върху логиката за изтегляне на всички въпроси, отговори и коментари в нещо консумативно в WordPress. Не само, че схемите на таблиците са различни от WordPress, типовете обекти също са доста различни. Визията ми беше да комбинирам всеки въпрос – и всички отговори и/или коментари – в една публикация.
Трудната част е, че таблицата с възли просто съдържа всичките три типа съдържание в една и съща таблица, с родителски и оригинални („главни“) родителски препратки. Техният преден код вероятно използва някакъв вид курсор, за да премине през и да покаже съдържанието в йерархичен и хронологичен ред. Не бих имал този лукс в WordPress, така че трябваше да нанизвам HTML с един кадър. Само като пример, ето как изглеждаха данните:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Не можех да подреждам по идентификатор, или тип, или по родител, тъй като понякога коментар ще дойде по-късно за по-ранен отговор, първият отговор не винаги ще бъде приетият отговор и т.н. Исках този изход (където ++ представлява едно ниво на отстъп):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Започнах да пиша рекурсивен CTE и,
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Резултати:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
гений. Проверих на място десетина други и се зарадвах, че преминавам към следващата стъпка. Благодарих на Анди изобилно, няколко пъти, но нека го направя отново:Благодаря, Анди!
Сега, когато можех да върна целия набор в реда, който ми хареса, трябваше да извърша известна манипулация на изхода, за да приложа HTML елементи и имена на класове, които ще ми позволят да маркирам въпроси, отговори, коментари и отстъпи по смислен начин. Крайната цел беше изходът, който изглеждаше така (и имайте предвид, че това е един от по-простите случаи):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Няма да преминавам през нелепия брой итерации, през които трябваше да премина, за да стигна до надеждна форма на този изход за всичките 5000+ артикула (което се преведе до почти 1000 публикации, след като всичко беше залепено). На всичкото отгоре трябваше да ги генерирам под формата на INSERT изявления, които след това бих могъл да поставя в phpMyAdmin на сайта на WordPress, което означаваше да се придържам към тяхната странна синтактична диаграма. Тези изявления трябваше да включват друга допълнителна информация, изисквана от WordPress, но не присъстваща или точна в изходните данни (като post_type ). И тази администраторска конзола щеше да изтече при твърде много данни, така че трябваше да я разделя на ~750 вмъквания наведнъж. Ето процедурата, с която завърших (това всъщност не е да науча нещо конкретно, а просто демонстрация на това колко манипулации на импортираните данни са били необходими):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO Резултатът от това не е завършен и все още не е готов за добавяне в WordPress:
 Примерен изход (щракнете, за да увеличите)
Примерен изход (щракнете, за да увеличите)
Ще ми трябва допълнителна помощ от C#, за да превърна действителното съдържание (включително маркирането) в HTML и CSS, които мога да контролирам по-добре, и да напиша изхода (куп INSERT изявления, които случайно включват куп HTML код) към файлове на диска, които мога да отворя и поставя в phpMyAdmin. За HTML, обикновен текст + намаление, което започна така:
ИЗБЕРЕТЕ нещо от dbo.sometable;
[1]:https://на друго място
Ще трябва да стане това:
Има публикация в блога тук , която говори за това, както и тази публикация .
ИЗБЕРЕТЕ нещо от dbo.sometable; За да постигна това, използвах помощта на MarkdownSharp, библиотека с отворен код, произхождаща от Stack Overflow, която обработва голяма част от преобразуването на markdown-to-HTML. Беше подходящо за моите нужди, но не идеално; Все пак ще трябва да извърша допълнителна манипулация:
- MarkdownSharp не позволява неща като
target=_blank, така че ще трябва да ги инжектирам сам след обработка; - кодът (всичко с префикс с четири интервала) наследява
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Да, това е грозен куп код, но най-накрая ме доведе до набора от изход, който няма да накара phpMyAdmin да повръща и който WordPress ще се представи добре (достатъчно). Просто извиках програмата C# няколко пъти с различни диапазони от параметри:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
След това отворих всеки от файловете, поставих ги в phpMyAdmin и натиснах GO:
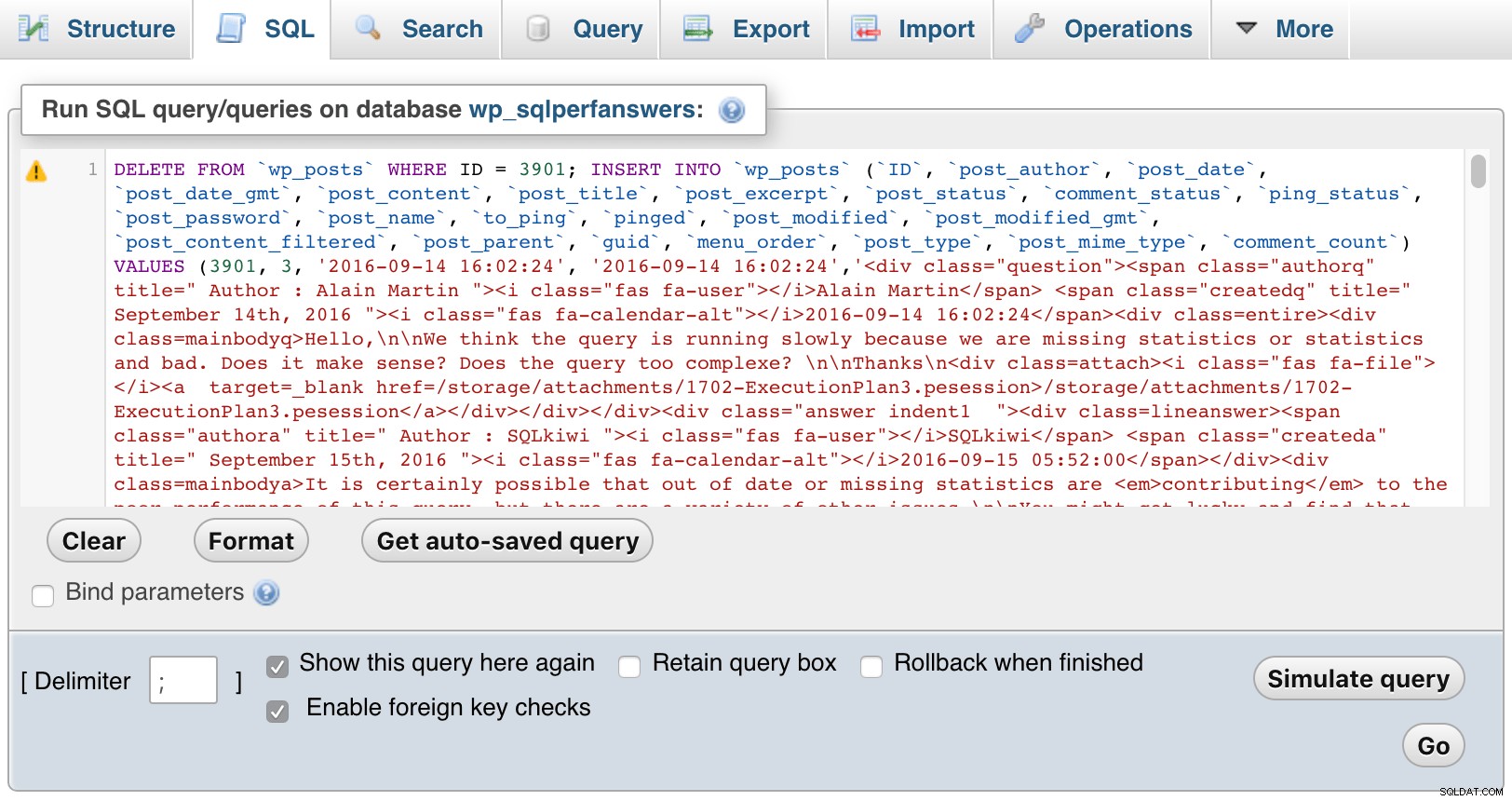 phpMyAdmin (щракнете, за да увеличите)
phpMyAdmin (щракнете, за да увеличите) Разбира се, трябваше да добавя малко CSS в WordPress, за да помогна за разграничаването на въпроси, коментари и отговори, както и да отстъпя коментарите, за да показвам отговори както на въпроси, така и на отговорите, да вмъквам коментари, отговарящи на коментари и т.н. Ето как изглежда един откъс, когато преминете към въпросите за един месец:
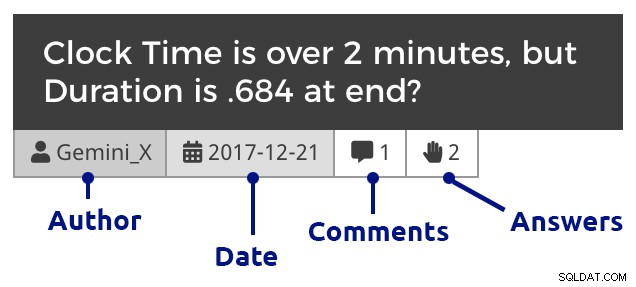 Плочка за въпроси (щракнете, за да увеличите)
Плочка за въпроси (щракнете, за да увеличите) И след това примерна публикация, показваща вградени изображения, множество прикачени файлове, вложени коментари и отговор:
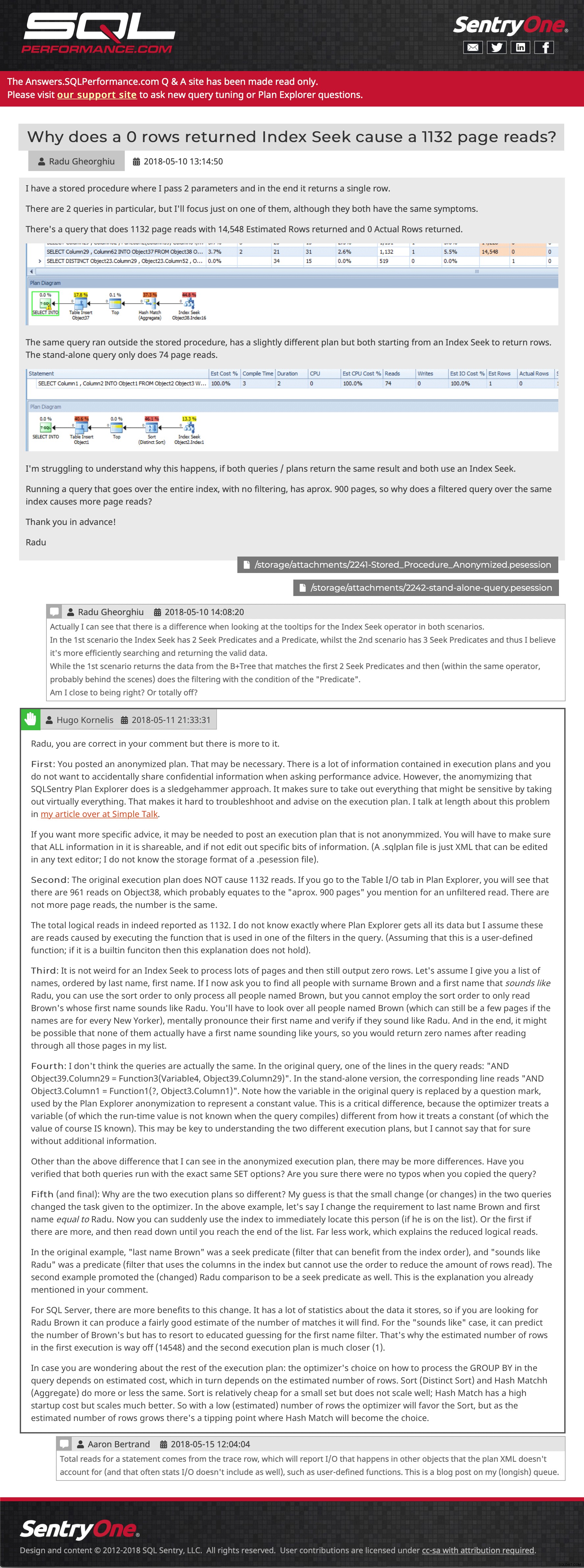 Примерен въпрос и отговор (щракнете, за да отидете там)
Примерен въпрос и отговор (щракнете, за да отидете там) Все още се опитвам да възстановя няколко публикации, изпратени на сайта след правенето на последното резервно копие, но ви приветствам да разгледате. Моля, уведомете ни, ако забележите нещо, което липсва или не е на място, или дори просто да ни кажете, че съдържанието все още е полезно за вас. Надяваме се да въведем отново функционалността за качване на план от Plan Explorer, но това ще изисква работа с API на новия сайт за поддръжка, така че днес нямам ETA за вас.
- Answers.SQLPerformance.com