На PASS Summit преди няколко седмици Microsoft пусна CTP2.1 на SQL Server 2019, а едно от големите подобрения на функциите, които са включени в CTP, е Scalar UDF Inlining. Преди тази версия исках да си поиграя с разликата в производителността между вграждането на скаларни UDF и RBAR (ред-по-агонизиращ ред) изпълнение на скаларни UDF в по-ранните версии на SQL Server и се натъкнах на опция за синтаксис за СЪЗДАВАНЕ НА ФУНКЦИЯ изявление в SQL Server Books Online, което никога не бях виждал преди.
DDL за СЪЗДАВАНЕ НА ФУНКЦИЯ поддържа клауза WITH за функционални опции и докато четях Книги онлайн забелязах, че синтаксисът включва следното:
-- Клаузи за функциите на Transact-SQL::= { [ ШИФРОВАНИЕ ] | [ ОБВЪЗВАНЕ НА СХЕМИ ] | [ ВРЪЩА NULL ПРИ NULL ВХОД | ИЗВИКАНО ПРИ НУЛЕВО ВХОД ] | [ EXECUTE_AS_Clause ] }
Бях наистина любопитен относно ВРЪЩАНЕ НА NULL ПРИ NULL INPUT функция, така че реших да направя някои тестове. Бях много изненадан да открия, че всъщност това е форма на скаларна оптимизация на UDF, която е в продукта поне от SQL Server 2008 R2.
Оказва се, че ако знаете, че скаларен UDF винаги ще връща резултат NULL, когато е предоставен NULL вход, тогава UDF ВИНАГИ трябва да бъде създаден с ВЪРНА NULL НА NULL INPUT опция, тъй като тогава SQL Server изобщо не изпълнява дефиницията на функцията за всички редове, където входът е NULL – на практика го свързва на късо и избягва пропиляното изпълнение на тялото на функцията.
За да ви покажа това поведение, ще използвам екземпляр на SQL Server 2017 с най-новата Кумулативна актуализация, приложена към него и AdventureWorks2017 база данни от GitHub (можете да я изтеглите от тук), която се доставя с dbo.ufnLeadingZeros функция, която просто добавя водещи нули към входната стойност и връща низ от осем символа, който включва тези водещи нули. Ще създам нова версия на тази функция, която включва ВРЪЩА NULL ПРИ NULL INPUT опция, за да мога да я сравня с оригиналната функция за производителност на изпълнение.
ИЗПОЛЗВАЙТЕ [AdventureWorks2017]; ИЗПОЛЗВАЙТЕ СЪЗДАВАЙТЕ ФУНКЦИЯ [dbo].[ufnLeadingZeros_new]( @Value int ) ВРЪЩА varchar(8) СЪС СХЕМАТА, ВРЪЩА NULL ПРИ NULL INPUT DECLARE @ Retur( charVaRE ); SET @ReturnValue =CONVERT(varchar(8), @Value); SET @ReturnValue =REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue; ВРЪЩАНЕ (@ReturnValue); КРАЙ; ОТПРАВИ За целите на тестване на разликите в производителността при изпълнение в рамките на двигателя на базата данни на двете функции, реших да създам сесия с разширени събития на сървъра, за да проследя sqlserver.module_end събитие, което се задейства в края на всяко изпълнение на скаларния UDF за всеки ред. Това ми позволи да демонстрирам семантиката на обработка ред по ред и също така ми позволи да проследя колко пъти функцията действително е била извикана по време на теста. Реших също да събера sql_batch_completed и sql_statement_completed събития и филтрирайте всичко по session_id за да се уверя, че улавям информация, свързана само със сесията, в която действително изпълнявах тестовете (ако искате да повторите тези резултати, ще трябва да промените 74 на всички места в кода по-долу на какъвто и да е идентификатор на сесията на вашия тест кодът ще се изпълнява). Сесията на събитието използва TRACK_CAUSALITY така че е лесно да се преброи колко изпълнения на функцията са извършени чрез activity_id.seq_no стойност за събитията (която се увеличава с едно за всяко събитие, което отговаря на session_id филтър).
СЪЗДАВАНЕ НА СЪБИТИЯ СЕСИЯ [Session72] НА СЪРВЪР ДОБАВЯНЕ НА СЪБИТИЕ sqlserver.module_end( КЪДЕ ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ДОБАВЯНЕ НА СЪБИТИЕ sqlserver. [package0].[equal_uint64]([sqlserver].[session_id],(74)))), ДОБАВЯНЕ НА СЪБИТИЕ sqlserver.sql_batch_starting( КЪДЕ ([package0].[equal_uint64]([sqlserver].[session_id],(7)) ))), ДОБАВЯНЕ НА СЪБИТИЕ sqlserver.sql_statement_completed( КЪДЕ ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ДОБАВЯНЕ НА СЪБИТИЕ sqlserver.sql_statement_starting( lint WHER].[e 4. ([sqlserver].[session_id],(74)))) С (TRACK_CAUSALITY=ON) GO
След като стартирах сесията на събитието и отворих Live Data Viewer в Management Studio, изпълних две заявки; едно, използващо оригиналната версия на функцията за добавяне на нули към CurrencyRateID колона в Sales.SalesOrderHeader таблица и новата функция за генериране на идентичен изход, но с помощта на ВРЪЩА NULL НА NULL INPUT опция и взех информацията за действителния план за изпълнение за сравнение.
ИЗБЕРЕТЕ SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) ОТ Sales.SalesOrderHeader; ИЗБЕРЕТЕ SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) ОТ Sales.SalesOrderHeader; ОТПРАВИ
Прегледът на данните за разширените събития показа няколко интересни неща. Първо, оригиналната функция се изпълни 31 465 пъти (от броя на module_end събития) и общото процесорно време за sql_statement_completed събитието беше 204 мс с продължителност 482 мс.
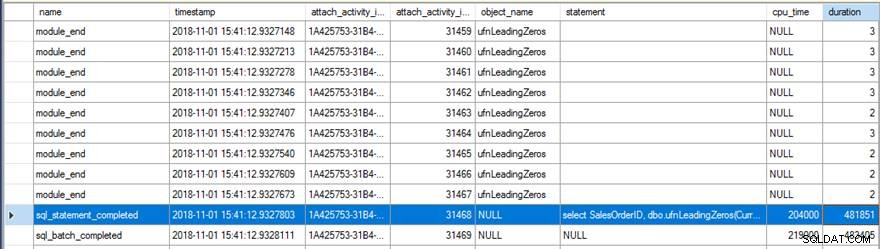
Новата версия с ВРЪЩА NULL ПРИ NULL INPUT посочената опция се изпълнява само 13 976 пъти (отново от броя на module_end събития) и времето на процесора за sql_statement_completed събитието беше 78 мс с продължителност 359 мс.

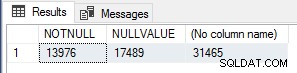
Намерих това за интересно, така че, за да проверя броя на изпълнението, изпълних следната заявка, за да преброя NOT NULL редове със стойност, NULL редове със стойност и общи редове в Sales.SalesOrderHeader таблица.
ИЗБЕРЕТЕ SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) КАТО NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) КАТО NULL STO.
Тези числа отговарят точно на номера на module_end събития за всеки от тестовете, така че това определено е много проста оптимизация на производителността за скаларни UDF, които трябва да се използват, ако знаете, че резултатът от функцията ще бъде NULL, ако входните стойности са NULL, за късо съединение/байпас на изпълнението на функцията изцяло за тези редове.
Информацията за QueryTimeStats в действителните планове за изпълнение също отразява повишаването на производителността:
Това е доста значително намаляване на времето на процесора само по себе си, което може да бъде съществена болезнена точка за някои системи.
Използването на скаларни UDFs е добре познат анти-шаблон на дизайна за производителност и има различни методи за пренаписване на кода, за да се избегне тяхното използване и удар по производителността. Но ако те вече са на мястото си и не могат лесно да бъдат променени или премахнати, просто пресъздайте UDF с ВЪРНА НУЛ ПРИ НУЛЕВ ВХОД опцията може да бъде много прост начин за подобряване на производителността, ако има много NULL входове в набора от данни, където се използва UDF.