Тази статия е третата от поредица за оптимизационни прагове за групиране и агрегиране на данни. В част 1 разгледах предварително поръчания алгоритъм Stream Aggregate. В част 2 разгледах непредварително поръчания алгоритъм за сортиране + поток. В тази част разглеждам алгоритъма на Hash Match (Aggregate), който ще наричам просто Hash Aggregate. Също така предоставям обобщение и сравнение между алгоритмите, които разглеждам в Част 1, Част 2 и Част 3.
Ще използвам същата примерна база данни, наречена PerformanceV3, която използвах в предишните статии от поредицата. Просто се уверете, че преди да стартирате примерите в статията, първо стартирате следния код, за да пуснете няколко ненужни индекса:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Единствените два индекса, които трябва да бъдат оставени в тази таблица, са idx_cl_od (клъстериран с orderdate като ключ) и PK_Orders (неклъстериран с orderid като ключ).
Хеш агрегат
Алгоритъмът Hash Aggregate организира групите в хеш таблица въз основа на някаква вътрешно избрана хеш функция. За разлика от алгоритъма Stream Aggregate, не е необходимо да консумира редовете в групов ред. Помислете за следната заявка (ще я наречем Заявка 1) като пример (принудително използване на хеш агрегат и сериен план):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
Фигура 1 показва плана за заявка 1.
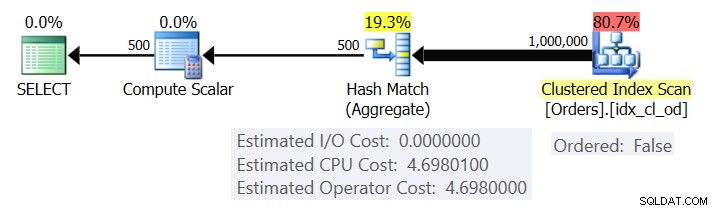
Фигура 1:План за заявка 1
Планът сканира редовете от клъстерирания индекс с помощта на свойство Ordered:False (сканирането не е необходимо за доставяне на редовете, подредени от ключа на индекса). Обикновено оптимизаторът предпочита да сканира най-тесния покриващ индекс, който в нашия случай се оказва клъстерираният индекс. Планът изгражда хеш таблица с групираните колони и агрегатите. Нашата заявка изисква въведен INT агрегат COUNT. Планът всъщност го изчислява като стойност, въведена от BIGINT, следователно операторът Compute Scalar, прилагайки имплицитно преобразуване към INT.
Microsoft не споделя публично хеш алгоритмите, които използват. Това е много патентована технология. И все пак, за да илюстрираме концепцията, нека предположим, че SQL Server използва хеш функцията % 250 (модул 250) за нашата заявка по-горе. Преди да обработим каквито и да е редове, нашата хеш таблица има 250 кофи, представляващи 250 възможни резултата от хеш функцията (0 до 249). Докато SQL Server обработва всеки ред, той прилага хеш функцията
orderid empid ------- ----- 320 3 30 5 660 253 820 3 850 1 1000 255 700 3 1240 253 350 4 400 255
Фигура 2 показва три състояния на хеш таблицата:преди обработката на който и да е ред, след обработката на първите 5 реда и след обработката на първите 10 реда. Всеки елемент в свързания списък съдържа кортежа (empid, COUNT(*)).
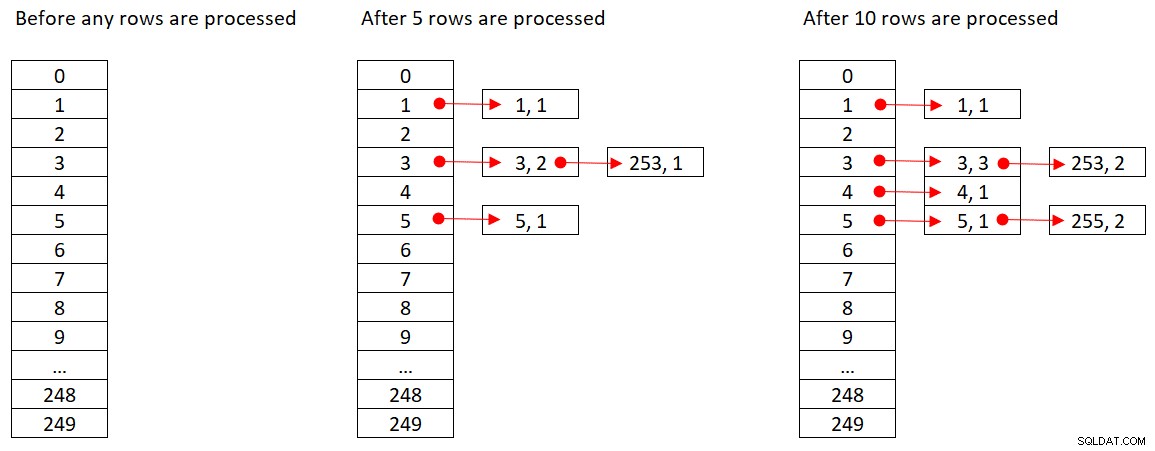
Фигура 2:Състояния на хеш таблица
След като операторът Hash Aggregate приключи с консумацията на всички входни редове, хеш таблицата има всички групи с крайното състояние на агрегата.
Подобно на оператора Sort, операторът Hash Aggregate изисква предоставяне на памет и ако паметта му свърши, трябва да се прехвърли към tempdb; обаче, докато сортирането изисква предоставяне на памет, което е пропорционално на броя на редовете за сортиране, хеширането изисква предоставяне на памет, което е пропорционално на броя на групите. Така че особено когато наборът за групиране има висока плътност (малък брой групи), този алгоритъм изисква значително по-малко памет, отколкото когато се изисква изрично сортиране.
Помислете за следните две заявки (наречете ги Заявка 1 и Заявка 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
Фигура 3 сравнява предоставените памет за тези заявки.

Фигура 3:Планове за заявка 1 и заявка 2
Забележете голямата разлика между предоставянето на памет в двата случая.
Що се отнася до разходите на оператора Hash Aggregate, връщайки се към фигура 1, забележете, че няма I/O цена, а само цена на процесора. След това опитайте да промените формулата за изчисляване на разходите на процесора, като използвате техники, подобни на тези, които разгледах в предишните части от поредицата. Факторите, които потенциално могат да повлияят на разходите на оператора, са броят на входните редове, броят на изходните групи, използваната агрегатна функция и това, по което групирате (кардиналност на набора от групи, използвани типове данни).
Очаквате този оператор да има начални разходи за подготовка за изграждане на хеш таблицата. Също така бихте очаквали да се мащабира линейно по отношение на броя на редовете и групите. Това наистина е, което открих. Въпреки това, докато разходите както на операторите Stream Aggregate, така и на Sort не се влияят от това, по което групирате, изглежда, че цената на оператора Hash Aggregate е — както по отношение на мощността на набора за групиране, така и на използваните типове данни.
За да забележите, че кардиналността на набора за групиране влияе върху цената на оператора, проверете разходите за процесора на операторите Hash Aggregate в плановете за следните заявки (наречете ги Заявка 3 и Заявка 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1);
Разбира се, искате да сте сигурни, че прогнозният брой входни редове и изходни групи е еднакъв и в двата случая. Прогнозните планове за тези заявки са показани на Фигура 4.
Фигура 4:Планове за заявка 3 и заявка 4
Както можете да видите, цената на процесора на оператора Hash Aggregate е 0,16903 при групиране по една целочислена колона и 0,174016 при групиране по две целочислени колони, като всички останали са равни. Това означава, че мощността на групиращия набор наистина влияе върху цената.
Що се отнася до това дали типът данни на групирания елемент влияе на цената, използвах следните заявки, за да проверя това (наречете ги Запитване 5, Заявка 6 и Запитване 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT)
OPTION(HASH GROUP, MAXDOP 1);
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY orderid % 1000
OPTION(HASH GROUP, MAXDOP 1);
SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT)
OPTION(HASH GROUP, MAXDOP 1); Плановете и за трите заявки имат еднакъв приблизителен брой входни редове и изходни групи, но всички те получават различни прогнозни разходи на процесора (0,121766, 0,16903 и 0,171716), следователно използваният тип данни влияе на разходите.
Видът на агрегатната функция също изглежда оказва влияние върху разходите. Например, помислете за следните две заявки (наречете ги Заявка 8 и Заявка 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Прогнозната цена на процесора за Hash Aggregate в плана за заявка 8 е 0,166344, а в заявка 9 е 0,16903.
Би могло да бъде интересно упражнение да се опитате да разберете по какъв точно начин мощността на набора за групиране, типовете данни и използваните агрегатни функции влияят върху цената; Просто не преследвах този аспект на изчисляването на разходите. Така че, след като изберете набора за групиране и агрегатната функция за вашата заявка, можете да конструирате обратното инженерство на формулата за изчисляване на разходите. Например, нека направим обратен инженеринг на формулата за изчисляване на разходите на процесора за оператора Hash Aggregate, когато групирате по една колона с цяло число и връщате агрегата MAX(orderdate). Формулата трябва да бъде:
CPU цена на оператора =<начална цена> + @numrows * <цена на ред> + @numgroups * <цена на група>Използвайки техниките, които демонстрирах в предишните статии от поредицата, получих следната формула за обратно проектиране:
Цена на процесора на оператора =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Можете да проверите точността на формулата, като използвате следните заявки:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Получавам следните резултати:
numrows numgroups predictedcost estimatedcost ----------- ----------- -------------- -------------- 100000 1000 0.703315 0.703316 100000 2000 0.721023 0.721024 200000 3000 1.40659 1.40659 200000 6000 1.45972 1.45972 500000 5000 3.44558 3.44558 500000 10000 3.53412 3.53412
Формулата изглежда е на място.
Обобщение и сравнение на разходите
Сега имаме формулите за изчисляване на разходите за трите налични стратегии:предварително поръчан поток на агрегат, сортиране + агрегат на поток и хеш агрегат. Следната таблица обобщава и сравнява характеристиките на разходите на трите алгоритма:
| Предварително поръчан агрегат за поток | Сортиране + Обобщение на потока | Хеш агрегат | |
| Формула | @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,0112613 + Малък брой редове: 9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06 Голям брой редове: 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087
* Групиране по една колона с цяло число, връщане на MAX( |
| Мащабиране | линеен | n log n | линеен |
| Разходи за стартиране на I/O | никакъв | 0,0112613 | никакъв |
| Разходи за стартиране на процесора | никакъв | ~ 0,0001 | 0,017749 |
Съгласно тези формули, Фигура 5 показва начина, по който всяка от стратегиите се мащабира за различен брой входни редове, като се използва фиксиран брой групи от 500 като пример.
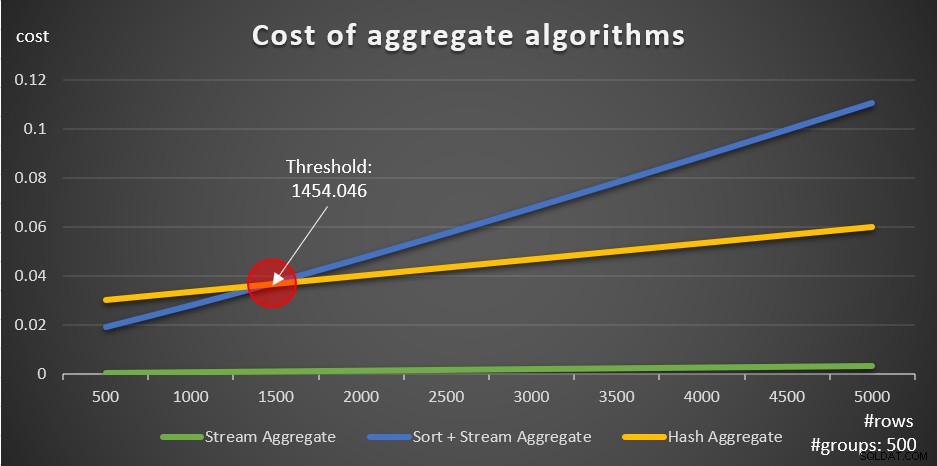
Фигура 5:Цена на обобщените алгоритми
Можете ясно да видите, че ако данните са предварително подредени, например в покриващ индекс, предварително поръчаната стратегия Stream Aggregate е най-добрият вариант, независимо от това колко реда са включени. Да предположим например, че трябва да направите заявка в таблицата „Поръчки“ и да изчислите максималната дата на поръчка за всеки служител. Вие създавате следния покриващ индекс:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
Ето пет заявки, емулиращи таблица с поръчки с различен брой редове (10 000, 20 000, 30 000, 40 000 и 50 000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
Фигура 6 показва плановете за тези заявки.
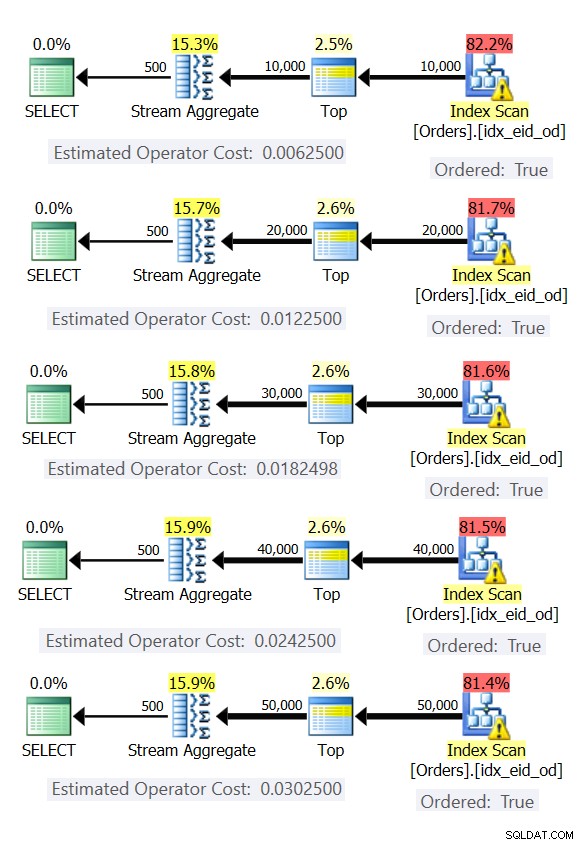
Фигура 6:Планове с предварително поръчана стратегия Stream Aggregate
Във всички случаи плановете извършват подредено сканиране на покриващия индекс и прилагат оператора Stream Aggregate, без да е необходимо изрично сортиране.
Използвайте следния код, за да премахнете индекса, който сте създали за този пример:
DROP INDEX idx_eid_od ON dbo.Orders;
Другото важно нещо, което трябва да се отбележи относно графиките на фигура 5, е какво се случва, когато данните не са предварително поръчани. Това се случва, когато няма индекс за покриване на място, както и когато групирате по манипулирани изрази, за разлика от базовите колони. Има праг за оптимизация — в нашия случай на 1454,046 реда — под който стратегията за сортиране + поточно агрегат има по-ниска цена и на или над която стратегията за хеш агрегатиране има по-ниска цена. Това е свързано с факта, че първият хешира по-ниска стартова цена, но се мащабира по n log n начин, докато вторият има по-висока стартова цена, но се мащабира линейно. Това прави първият предпочитан с малък брой входни редове. Ако нашите формули за обратно проектиране са точни, следните две заявки (наречете ги Заявка 10 и Заявка 11) трябва да получат различни планове:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Плановете за тези заявки са показани на фигура 7.
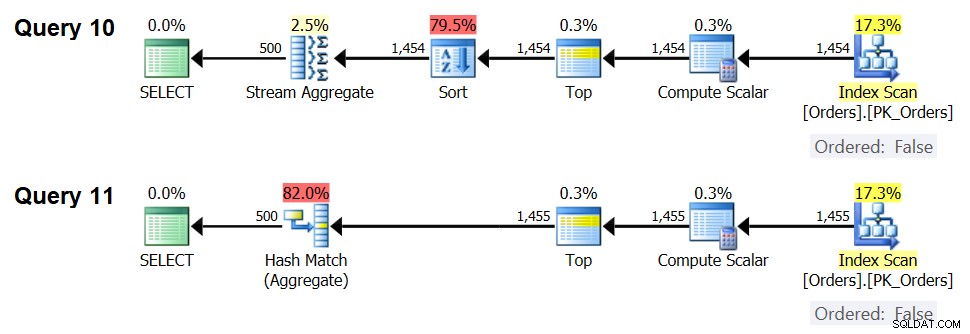
Фигура 7:Планове за заявка 10 и заявка 11
Всъщност, с 1454 реда за въвеждане (под прага за оптимизиране), оптимизаторът естествено предпочита алгоритъма Sort + Stream Aggregate за заявка 10, а с 1455 реда за въвеждане (над прага за оптимизиране), оптимизаторът естествено предпочита Hash Aggregate за алгоритъм на Query1. .
Потенциал за оператор на адаптивен агрегат
Един от трудните аспекти на праговете за оптимизация са проблемите с подслушването на параметри при използване на чувствителни към параметри заявки в съхранени процедури. Разгледайте следната съхранена процедура като пример:
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INT AS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= @initialorderid GROUP BY empid; GO
Създавате следния оптимален индекс, за да поддържате заявката за съхранена процедура:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
Създадохте индекса с orderid като ключ за поддръжка на филтъра за диапазон на заявката и включихте empid за покритие. Това е ситуация, при която наистина не можете да създадете индекс, който едновременно да поддържа филтъра за диапазон и да има филтрирани редове, предварително подредени от набора за групиране. Това означава, че оптимизаторът ще трябва да направи избор между алгоритмите Sort + stream Aggregate и Hash Aggregate. Въз основа на нашите формули за изчисляване на разходите, прагът за оптимизиране е между 937 и 938 входни реда (да речем, 937,5 реда).
Да предположим, че изпълнявате съхранената процедура за първи път с въведен първоначален идентификатор на поръчка, който ви дава малък брой съвпадения (под прага):
EXEC dbo.EmpOrders @initialorderid = 999991;
SQL Server създава план, който използва алгоритъма Sort + Stream Aggregate и кешира плана. Последващите изпълнения използват повторно кеширания план, независимо от това колко реда са включени. Например, следното изпълнение има няколко съвпадения над прага за оптимизиране:
EXEC dbo.EmpOrders @initialorderid = 990001;
Все пак той използва повторно кеширания план, въпреки факта, че не е оптимален за това изпълнение. Това е класически проблем с подслушването на параметри.
SQL Server 2017 въвежда възможности за адаптивна обработка на заявки, които са предназначени да се справят с подобни ситуации, като определят по време на изпълнение на заявката коя стратегия да се използва. Сред тези подобрения е оператор Adaptive Join, който по време на изпълнение определя дали да активира Loop или Hash алгоритъм въз основа на изчислен праг за оптимизация. Нашата обобщена история настоява за подобен оператор Adaptive Aggregate, който по време на изпълнение ще направи избор между стратегия за сортиране + поточно агрегат и стратегия за Hash Aggregate, въз основа на изчислен праг за оптимизация. Фигура 8 илюстрира псевдоплан, базиран на тази идея.
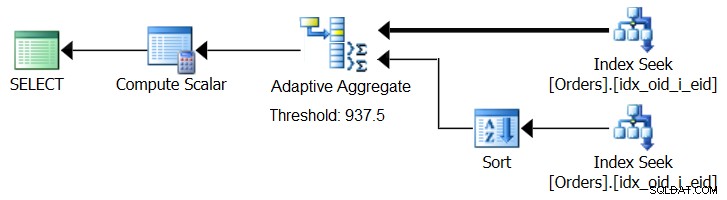
Фигура 8:Псевдо план с оператор Adaptive Aggregate
Засега, за да получите такъв план, трябва да използвате Microsoft Paint. Но тъй като концепцията за адаптивна обработка на заявки е толкова интелигентна и работи толкова добре, разумно е да се очакват допълнителни подобрения в тази област в бъдеще.
Изпълнете следния код, за да премахнете индекса, който сте създали за този пример:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Заключение
В тази статия разгледах изчисляването на разходите и мащабирането на алгоритъма Hash Aggregate и го сравних със стратегиите Stream Aggregate и Sort + Stream Aggregate. Описах прага за оптимизация, който съществува между стратегиите Sort + Stream Aggregate и Hash Aggregate. При малък брой входни редове се предпочита първото, а при големи числа второто. Също така описах потенциала за добавяне на оператор Adaptive Aggregate, подобен на вече внедрения оператор Adaptive Join, за да помогне за справянето с проблемите с подслушване на параметри при използване на чувствителни към параметри заявки. Следващия месец ще продължа дискусията, като разгледам съображенията за паралелизъм и случаите, които изискват пренаписване на заявка.