Тази статия е 7-та част от поредица за изрази за именувани таблици. В част 5 и част 6 покрих концептуалните аспекти на изразите за обща таблица (CTE). Този месец и следващия фокусът ми се насочва към съображенията за оптимизиране на CTEs.
Ще започна с бързо преразглеждане на концепцията за разгръщане на изрази за именувани таблици и ще демонстрирам нейната приложимост към CTE. След това ще насоча вниманието си към съображенията за постоянство. Ще говоря за аспектите на постоянството на рекурсивните и нерекурсивните CTE. Ще обясня кога има смисъл да се придържаме към CTEs спрямо кога всъщност има по-смислено да се работи с временни таблици.
В моите примери ще продължа да използвам примерните бази данни TSQLV5 и PerformanceV5. Можете да намерите скрипта, който създава и попълва TSQLV5 тук, и неговата ER диаграма тук. Можете да намерите скрипта, който създава и попълва PerformanceV5 тук.
Замяна/отпадане
В част 4 от поредицата, която се фокусира върху оптимизирането на извлечени таблици, описах процес на разместване/замяна на таблични изрази. Обясних, че когато SQL Server оптимизира заявка, включваща извлечени таблици, той прилага правила за трансформация към първоначалното дърво от логически оператори, произведени от синтактичния анализатор, вероятно измествайки нещата през това, което първоначално са били границите на израза на таблицата. Това се случва до степен, че когато сравните план за заявка, използваща извлечени таблици, с план за заявка, която върви директно срещу основните базови таблици, където сами сте приложили логиката на разместване, те изглеждат еднакво. Описах също техника за предотвратяване на разместването с помощта на TOP филтъра с много голям брой редове като вход. Демонстрирах няколко случая, в които тази техника беше доста удобна — единият, при който целта беше да се избегнат грешки, а друг — от съображения за оптимизация.
Версията TL;DR за заместване/отмяна на CTE е, че процесът е същият като при производните таблици. Ако сте доволни от това твърдение, можете да се чувствате свободни да пропуснете този раздел и да преминете направо към следващия раздел за постоянството. Няма да пропуснете нищо важно, което не сте чели преди. Въпреки това, ако сте като мен, вероятно искате доказателство, че това наистина е така. След това вероятно ще искате да продължите да четете този раздел и да тествате кода, който използвам, докато преглеждам ключовите примери за отмяна, които демонстрирах преди с извлечени таблици, и ги преобразувам за използване на CTE.
В част 4 демонстрирах следната заявка (ще я наречем заявка 1):
ИЗПОЛЗВАЙТЕ TSQLV5; ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка ОТ ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE дата на поръчка>='20180101' ) КАТО D1 WHERE дата на поръчка>='20180201' ) КАТО D2 WHERE дата на поръчка>='01'18) WHERE orderdate>='20180401';
Заявката включва три нива на влагане на производни таблици плюс външна заявка. Всяко ниво филтрира различен диапазон от дати на поръчка. Планът за заявка 1 е показан на фигура 1.
 Фигура 1:План за изпълнение на заявка 1
Фигура 1:План за изпълнение на заявка 1
Планът на фигура 1 ясно показва, че е осъществено разместване на извлечените таблици, тъй като всички предикати на филтъра са били обединени в един обхващащ предикат на филтъра.
Обясних, че можете да предотвратите процеса на разместване, като използвате смислен TOP филтър (за разлика от TOP 100 PERCENT) с много голям брой редове като вход, както показва следната заявка (ще я наречем Заявка 2):
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка ОТ ( ИЗБЕРЕТЕ ВЪРХА (9223372036854775807) * ОТ ( ИЗБЕРЕТЕ ВЪРХА (9223372036854775807) * ОТ ( ИЗБЕРЕТЕ ВЪРХА (9223372036854775807) ИЗБЕРЕТЕ ВЪРХА (9223372036854775807) ИЗБЕРЕТЕ ВЪРХА (9223372036854775807) ИЗБЕРЕТЕ ВЪРХА) 20180201' ) КАТО D2 WHERE дата на поръчка>='20180301' ) КАТО D3 WHERE дата на поръчка>='20180401';
Планът за заявка 2 е показан на фигура 2.
 Фигура 2:План за изпълнение на заявка 2
Фигура 2:План за изпълнение на заявка 2
Планът ясно показва, че разглобяването не е извършено, тъй като можете ефективно да видите границите на извлечената таблица.
Нека опитаме същите примери с CTE. Ето заявка 1, преобразувана за използване на CTEs:
С C1 AS ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT * FROM C1 WHERE orderdate>='20180201' ), C3 AS ( SELECT * FROM C2 WHERE orderdate>=' 20180301' ) ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка ОТ C3 WHERE orderdate>='20180401';
Получавате точно същия план, показан по-рано на Фигура 1, където можете да видите, че е извършено разглобяването.
Ето заявка 2, преобразувана за използване на CTEs:
С C1 AS ( ИЗБЕРЕТЕ ВЪРХА (9223372036854775807) * ОТ Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT TOP (9223372036854775807) * E2da ASte SELECT> C2da ASte> SELECT НАГОРЕ (9223372036854775807) * ОТ C2 WHERE дата на поръчка>='20180301' ) ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка ОТ C3 WHERE дата на поръчка>='20180401';
Получавате същия план, както е показано по-рано на Фигура 2, където можете да видите, че разглобяването не е извършено.
След това нека да разгледаме отново двата примера, които използвах, за да демонстрирам практичността на техниката за предотвратяване на разглобяването – само този път с помощта на CTE.
Нека започнем с грешната заявка. Следната заявка се опитва да върне редове за поръчка с отстъпка, която е по-голяма от минималната отстъпка и където реципрочната стойност на отстъпката е по-голяма от 10:
ИЗБЕРЕТЕ идентификатор на поръчка, идентификатор на продукт, отстъпка ОТ Sales.OrderDetails КЪДЕ отстъпка> (ИЗБЕРЕТЕ МИН.(отстъпка) ОТ Sales.OrderDetails) И 1.0 / отстъпка> 10.0;
Минималната отстъпка не може да бъде отрицателна, по-скоро е нула или по-висока. Така че вероятно си мислите, че ако ред има нулева отстъпка, първият предикат трябва да се оцени като false и че късото съединение трябва да предотврати опита за оценка на втория предикат, като по този начин се избягва грешка. Въпреки това, когато стартирате този код, получавате грешка при деление на нула:
Съобщение 8134, ниво 16, състояние 1, ред 99 Възникна грешка при разделяне на нула.
Проблемът е, че въпреки че SQL Server поддържа концепция за късо съединение на ниво физическа обработка, няма гаранция, че той ще оцени предикатите на филтъра в писмен ред отляво надясно. Често срещан опит да се избегнат подобни грешки е да се използва израз на именувана таблица, който обработва частта от филтриращата логика, която искате да бъде оценена първа, и външната заявка да обработва филтриращата логика, която искате да бъде оценена втора. Ето опитаното решение с помощта на CTE:
С C AS ( ИЗБЕРЕТЕ * ОТ Sales.OrderDetails КЪДЕ отстъпка> (ИЗБЕРЕТЕ МИН.(отстъпка) ОТ Sales.OrderDetails) ) ИЗБЕРЕТЕ идентификатор на поръчката, productid, отстъпка ОТ C WHERE 1.0 / отстъпка> 10.0;
За съжаление обаче, отмяната на табличния израз води до логически еквивалент на първоначалната заявка за решение и когато се опитате да изпълните този код, отново получавате грешка при деление на нула:
Съобщение 8134, ниво 16, състояние 1, ред 108 Възникна грешка при разделяне на нула.
Използвайки нашия трик с TOP филтъра във вътрешната заявка, вие предотвратявате разместването на табличния израз, както следва:
С C AS ( ИЗБЕРЕТЕ TOP (9223372036854775807) * ОТ Sales.OrderDetails КЪДЕ отстъпка> (ИЗБЕРЕТЕ МИН.(отстъпка) ОТ Sales.OrderDetails) ) ИЗБЕРЕТЕ идентификатор на поръчка, productid, отстъпка ОТ C WHERE 1.0 / отстъпка;Този път кодът работи успешно без никакви грешки.
Нека да преминем към примера, в който използвате техниката, за да предотвратите разместването по съображения за оптимизация. Следният код връща само изпращачи с максимална дата на поръчка, която е на или след 1 януари 2018 г.:
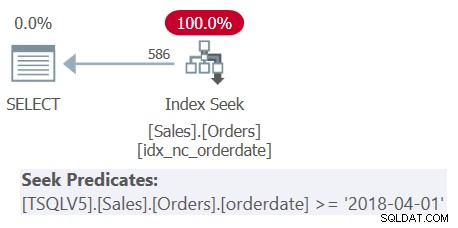
ИЗПОЛЗВАЙТЕ PerformanceV5; С C AS ( ИЗБЕРЕТЕ S.shipperid, (ИЗБЕРЕТЕ MAX(O.orderdate) ОТ dbo.Orders AS O WHERE O.shipperid =S.shipperid) КАТО maxod ОТ dbo.Shippers AS S ) SELECT shipperid, maxod ОТ C, КЪДЕ maxod> ='20180101';Ако се чудите защо да не използвате много по-просто решение с групирана заявка и филтър HAVING, това е свързано с плътността на колоната на shipperid. Таблицата „Поръчки“ съдържа 1 000 000 поръчки и пратките на тези поръчки се обработват от петима изпращачи, което означава, че средно всеки изпращач обработва 20% от поръчките. Планът за групирана заявка, изчисляваща максималната дата на поръчка на изпращач, ще сканира всички 1 000 000 реда, което води до хиляди прочитания на страници. Всъщност, ако маркирате само вътрешната заявка на CTE (ще я наречем Заявка 3), като изчислявате максималната дата на поръчка за изпращач и проверите плана за изпълнение на нейния план, ще получите плана, показан на фигура 3.
Фигура 3:План за изпълнение на заявка 3
Планът сканира пет реда в клъстерирания индекс на изпращачите. На изпращач, планът прилага търсене срещу покриващ индекс на Поръчки, където (shipperid, orderdate) са водещите ключове в индекса, отиващи направо към последния ред във всяка секция на изпращача на ниво лист, за да изтегли максималната дата на поръчка за текущата изпращач. Тъй като имаме само петима изпращачи, има само пет операции за търсене на индекс, което води до много ефективен план. Ето мерките за ефективност, които получих, когато изпълних вътрешната заявка на CTE:
продължителност:0 ms, CPU:0 ms, четене:15Въпреки това, когато стартирате цялостното решение (ще го наречем Query 4), получавате напълно различен план, както е показано на Фигура 4.
Фигура 4:План за изпълнение на заявка 4
Това, което се случи, е, че SQL Server отмени табличния израз, преобразувайки решението в логически еквивалент на групирана заявка, което води до пълно сканиране на индекса за поръчки. Ето числата за ефективност, които получих за това решение:
продължителност:316 ms, CPU:281 ms, четения:3854Това, от което се нуждаем тук, е да предотвратим извършването на разместването на табличния израз, така че вътрешната заявка да бъде оптимизирана с търсения спрямо индекса на Поръчки, а външната заявка просто да доведе до добавяне на оператор Filter в план. Постигате това с помощта на нашия трик, като добавяте TOP филтър към вътрешната заявка, така (ще наречем това решение Заявка 5):
С C AS ( ИЗБЕРЕТЕ TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) ОТ dbo.Orders AS O WHERE O.shipperid =S.shipperid) КАТО maxod ОТ dbo.Shippers AS S ) SELECT shipperid , maxod ОТ C КЪДЕ maxod>='20180101';Планът за това решение е показан на Фигура 5.
Фигура 5:План за изпълнение на заявка 5
Планът показва, че желаният ефект е постигнат и съответно цифрите на производителността потвърждават това:
продължителност:0 ms, CPU:0 ms, четене:15И така, нашето тестване потвърждава, че SQL Server се справя със заместването/отмяната на CTE, точно както прави за извлечените таблици. Това означава, че не трябва да предпочитате едно пред друго поради причини за оптимизация, а по-скоро поради концептуални различия, които имат значение за вас, както е обсъдено в част 5.
Постоянство
Често срещано погрешно схващане относно CTE и изразите на именувани таблици като цяло е, че те служат като някакъв вид средство за постоянство. Някои смятат, че SQL Server запазва набора от резултати от вътрешната заявка към работна таблица и че външната заявка всъщност взаимодейства с тази работна таблица. На практика обикновените нерекурсивни CTE и производните таблици не се запазват. Описах логиката на разместване, която SQL Server прилага при оптимизиране на заявка, включваща изрази на таблици, което води до план, който взаимодейства директно с основните базови таблици. Имайте предвид, че оптимизаторът може да избере да използва работни таблици, за да запази междинните набори от резултати, ако има смисъл да го прави или поради съображения за производителност, или други, като например защита за Хелоуин. Когато го направи, в плана виждате Spool или Index Spool оператори. Такива избори обаче не са свързани с използването на таблични изрази в заявката.
Рекурсивни CTEs
Има няколко изключения, при които SQL Server запазва данните на израза на таблицата. Едното е използването на индексирани изгледи. Ако създадете клъстериран индекс в изглед, SQL Server запазва набора от резултати на вътрешната заявка в клъстерирания индекс на изгледа и го поддържа в синхрон с всички промени в основните базови таблици. Другото изключение е, когато използвате рекурсивни заявки. SQL Server трябва да задържи междинните набори от резултати на котвените и рекурсивните заявки в пул, така че да има достъп до набора от резултати от последния кръг, представен от рекурсивната препратка към името на CTE всеки път, когато рекурсивният член се изпълнява.
За да демонстрирам това, ще използвам една от рекурсивните заявки от част 6 от поредицата.
Използвайте следния код, за да създадете таблицата Employees в базата данни tempdb, попълнете я с примерни данни и създайте поддържащ индекс:
ЗАДАДЕТЕ NOCOUNT ON; ИЗПОЛЗВАЙТЕ tempdb; DROP ТАБЛИЦА, АКО СЪЩЕСТВУВА dbo.Employees; GO CREATE TABLE dbo.Employees ( empid INT NOT NULL ОГРАНИЧЕНИЕ PK_Employees ПРАВИЛЕН КЛЮЧ, mgrid INT НУЛЕВО ОГРАНИЧЕНИЕ FK_Employees_Employees ПРЕПОРЪКИ dbo.Employees, empname VARCHAR(25) sa NEMPLOT NULL идентификатор (25) INSERT INTO dbo.Employees(empid, mgrid, empname, salary) VALUES(1, NULL, 'David' , $10000.00), (2, 1, 'Eitan' , $7000.00), (3, 1, 'Ina' , 0 $7500). , (4, 2, 'Seraph' , $5000,00), (5, 2, 'Jiru', $5500,00), (6, 2, 'Steve', $4500,00), (7, 3, 'Aaron', $5000,00), ( 8, 5, 'Lilach' , $3500,00), (9, 7, 'Rita', $3000,00), (10, 5, 'Sean', $3000,00), (11, 7, 'Gabriel', $3000,00), (12, 9, 'Емилия' , 2000,00 $), (13, 9, 'Майкъл', 2000,00 $), (14, 9, 'Диди', 1500,00 $); СЪЗДАЙТЕ УНИКАЛЕН ИНДЕКС idx_unc_mgrid_empid НА dbo.Employees(mgrid, empid) INCLUDE(empname, заплата); ОТПРАВИИзползвах следния рекурсивен CTE, за да върна всички подчинени на корен мениджър на входно поддърво, като използвах служител 3 като мениджър за въвеждане в този пример:
ДЕКЛАРИРАНЕ @root КАТО INT =3; С C AS ( ИЗБЕРЕТЕ empid, mgrid, empname ОТ dbo.Employees WHERE empid =@root UNION ВСИЧКИ ИЗБЕРЕТЕ S.empid, S.mgrid, S.empname ОТ C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid ) ИЗБЕРЕТЕ empid, mgrid, empname ОТ C;Планът за тази заявка (ще я наречем заявка 6) е показан на фигура 6.
Фигура 6:План за изпълнение на заявка 6
Забележете, че първото нещо, което се случва в плана, вдясно от основния SELECT възел, е създаването на работна таблица, базирана на B-дърво, представена от оператора Index Spool. Горната част на плана обработва логиката на закотвяния член. Той изтегля въведените редове за служители от клъстерирания индекс на Employees и го записва в пулта. Долната част на плана представлява логиката на рекурсивния член. Изпълнява се многократно, докато не върне празен набор от резултати. Външният вход към оператора Nested Loops получава мениджърите от предишния кръг от макарата (оператор Table Spool). Вътрешният вход използва оператор Index Seek срещу неклъстериран индекс, създаден на Employees(mgrid, empid), за да получи преките подчинени на мениджърите от предишния кръг. Резултатът от всяко изпълнение на долната част на плана също се записва в индексната макара. Забележете, че като цяло 7 реда бяха записани в макарата. Един се връща от закрепващия член и още 6 се връща от всички изпълнения на рекурсивния член.
Като настрана, интересно е да се забележи как планът се справя с ограничението за максимална рекурсия по подразбиране, което е 100. Обърнете внимание, че долният оператор Compute Scalar продължава да увеличава вътрешния брояч, наречен Expr1011, с 1 с всяко изпълнение на рекурсивния член. След това операторът Assert задава флаг на нула, ако този брояч надхвърли 100. Ако това се случи, SQL Server спира изпълнението на заявката и генерира грешка.
Кога да не продължавате
Обратно към нерекурсивните CTE, които обикновено не се запазват, вие трябва да разберете от гледна точка на оптимизация кога е добре да ги използвате в сравнение с действителните инструменти за постоянство като временни таблици и променливи на таблици. Ще разгледам няколко примера, за да демонстрирам кога всеки подход е по-оптимален.
Нека започнем с пример, при който CTE се справят по-добре от временните таблици. Това често се случва, когато нямате множество оценки на един и същ CTE, а може би просто модулно решение, при което всеки CTE се оценява само веднъж. Следният код (ще го наречем Query 7) прави заявка към таблицата Orders в базата данни за ефективност, която има 1 000 000 реда, за да върне годините на поръчки, в които повече от 70 различни клиенти са направили поръчки:
ИЗПОЛЗВАЙТЕ PerformanceV5; С C1 AS ( ИЗБЕРЕТЕ ГОДИНА (ДАТА на поръчка) КАТО година на поръчка, custid ОТ dbo.Orders ), C2 AS ( ИЗБЕРЕТЕ година на поръчка, COUNT(DISTINCT custid) КАТО numcusts ОТ C1 GROUP BY orderyear ) SELECT order year, numcusts ОТ C2 WHERE numcusts;<> /предварително>Тази заявка генерира следния изход:
orderyear numcusts ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000Изпълних този код с помощта на SQL Server 2019 Developer Edition и получих плана, показан на Фигура 7.
Фигура 7:План за изпълнение на заявка 7
Обърнете внимание, че разместването на CTE доведе до план, който изтегля данните от индекс в таблицата Orders и не включва буфериране на вътрешния набор от резултати от заявка на CTE. Получих следните числа за производителност, когато изпълнявах тази заявка на моята машина:
продължителност:265 ms, CPU:828 ms, четене:3970, записване:0Сега нека опитаме решение, което използва временни таблици вместо CTE (ще го наречем Решение 8), като така:
ИЗБЕРЕТЕ ГОДИНА(дата на поръчката) КАТО година на поръчка, custid INTO #T1 FROM dbo.Orders; ИЗБЕРЕТЕ година на поръчка, COUNT(DISTINCT custid) КАТО numcusts INTO #T2 ОТ #T1 ГРУПА ПО година на поръчка; ИЗБЕРЕТЕ година на поръчка, numcusts ОТ #T2 WHERE numcusts> 70; ИЗПУСКАНЕ ТАБЛИЦА #T1, #T2;Плановете за това решение са показани на Фигура 8.
Фигура 8:Планове за решение 8
Забележете, че операторите за вмъкване на таблица записват наборите от резултати във временните таблици #T1 и #T2. Първият е особено скъп, тъй като записва 1 000 000 реда в #T1. Ето номерата на производителността, които получих за това изпълнение:
продължителност:454 ms, CPU:1517 ms, четене:14359, записвания:359Както можете да видите, решението с CTEs е много по-оптимално.
Кога да продължите
Така че модулното решение, което включва само една оценка на всеки CTE, винаги е за предпочитане пред използването на временни таблици? Не е задължително. В базирани на CTE решения, които включват много стъпки и водят до сложни планове, при които оптимизаторът трябва да приложи много оценки на мощността в много различни точки от плана, може да се окажете с натрупани неточности, които водят до неоптимален избор. Една от техниките, за да се опитате да се справите с такива случаи, е да запазите някои междинни резултати, които се задават във временни таблици и дори да създадете индекси върху тях, ако е необходимо, давайки на оптимизатора нов старт с нова статистика, увеличавайки вероятността за по-качествени оценки на кардиналите, че надявам се да доведе до по-оптимален избор. Дали това е по-добро от решение, което не използва временни таблици, е нещо, което ще трябва да тествате. Понякога компромисът с допълнителни разходи за запазване на междинните набори от резултати в името на получаването на по-качествени оценки за мощността ще си струва.
Друг типичен случай, при който използването на временни таблици е предпочитаният подход, е когато базираното на CTE решение има множество оценки на една и съща CTE, а вътрешната заявка на CTE е доста скъпа. Помислете за следното базирано на CTE решение (ще го наречем Query 9), което съответства на всяка година и месец на поръчка с различна година и месец на поръчка, който има най-близкия брой поръчки:
С OrdCount AS ( ИЗБЕРЕТЕ ГОДИНА (дата на поръчка) КАТО година на поръчка, MONTH (дата на поръчка) КАТО месец на поръчка, COUNT(*) КАТО номера на поръчки ОТ dbo. Поръчки ГРУПА ПО ГОДИНА (дата на поръчка), MONTH (дата на поръчка) ) ИЗБЕРЕТЕ O1.година на поръчка, O1 .ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 ОТ OrdCount КАТО O1 CROSS APPLY ( SELECT TOP (1) O2.ordermonth, O2.ordermonth, O2.numorders КАТО FROM O2 WHERE O2.година на поръчка <> O1.година на поръчка ИЛИ O2.месец на поръчка <> O1.месец на поръчка ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) КАТО O2;Тази заявка генерира следния изход:
<предварителна> поръчкагодина поръчка месец номера поръчка година2 поръчка месец2 номера2 ----------- ----------- ----------- -------- --- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20161 02 02 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2019 г 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 211199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 2012 6 3 21211 2017 6 20551 2016г. 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 rows засегнати)Планът за заявка 9 е показан на фигура 9.
Фигура 9:План за изпълнение на заявка 9
Горната част на плана съответства на екземпляра на OrdCount CTE, който е псевдоним като O1. Тази справка води до една оценка на CTE OrdCount. Тази част от плана изтегля редовете от индекс в таблицата Поръчки, групира ги по година и месец и обобщава броя на поръчките за група, което води до 49 реда. Долната част на плана съответства на корелираната извлечена таблица O2, която се прилага на ред от O1, следователно се изпълнява 49 пъти. Всяко изпълнение отправя заявка към OrdCount CTE и следователно води до отделна оценка на вътрешната заявка на CTE. Можете да видите, че долната част на плана сканира всички редове от индекса на Поръчки, групира и ги обобщава. По принцип получавате общо 50 оценки на CTE, което води до 50 пъти сканиране на 1 000 000 реда от Поръчки, групирането и агрегирането им. Не звучи като много ефективно решение. Ето мерките за производителност, които получих, когато изпълнявах това решение на моята машина:
продължителност:16 секунди, CPU:56 секунди, чете:130404, записва:0Като се има предвид, че са включени само няколко десетки месеца, това, което би било много по-ефективно, е да се използва временна таблица за съхраняване на резултата от една дейност, която групира и агрегира редовете от Поръчки и след това има както външните, така и вътрешните входове на операторът APPLY взаимодейства с временната таблица. Ето решението (ще го наречем Решение 10) с помощта на временна таблица вместо CTE:
ИЗБЕРЕТЕ ГОДИНА(дата на поръчка) КАТО година на поръчка, MONTH(дата на поръчка) КАТО месец на поръчка, COUNT(*) КАТО номера на поръчки В #OrdCount ОТ dbo.Поръчки ГРУПА ПО ГОДИНА(дата на поръчка), MONTH(дата на поръчка); ИЗБЕРЕТЕ O1.orderyear, O1.ordermonth, O1.numorders, O2.orderyear КАТО година на поръчка2, O2.ordermonth AS ordermonth2, O2.numorders КАТО номера2 ОТ #OrdCount КАТО O1 КРЪСТ ПРИЛОЖИ (ИЗБЕРЕТЕ ВЪРХУ (1) O2.год на поръчка, O2.or , O2.numorders FROM #OrdCount AS O2 WHERE O2.orderyear <> O1.orderyear ИЛИ O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2; DROP TABLE #OrdCount;Тук няма много смисъл от индексирането на временната таблица, тъй като ТОП филтърът се основава на изчисление в неговата спецификация за подреждане и следователно сортирането е неизбежно. Въпреки това, много добре може да се окаже, че в други случаи, с други решения, също би било уместно за вас да помислите за индексиране на вашите временни таблици. Във всеки случай, планът за това решение е показан на Фигура 10.
Фигура 10:Планове за изпълнение на Решение 10
Наблюдавайте в горния план как тежкото повдигане, включващо сканиране на 1 000 000 реда, групирането и агрегирането им, се случва само веднъж. 49 реда се записват във временната таблица #OrdCount и след това долният план взаимодейства с временната таблица както за външните, така и за вътрешните входове на оператора Nested Loops, който обработва логиката на оператора APPLY.
Ето числата за производителност, които получих за изпълнението на това решение:
продължителност:0,392 секунди, CPU:0,5 секунди, чете:3636, записва:3По-бързо е с порядък от CTE базираното решение.
Какво следва?
В тази статия започнах отразяването на съображения за оптимизация, свързани с CTE. Показах, че процесът на разместване/заместване, който се извършва с производни таблици, работи по същия начин с CTE. Обсъдих също факта, че нерекурсивните CTE не се запазват и обясних, че когато постоянството е важен фактор за производителността на вашето решение, трябва да се справите сами, като използвате инструменти като временни таблици и променливи в таблицата. Следващия месец ще продължа дискусията, като разгледам допълнителни аспекти на CTE оптимизацията.