Въведение
Постигане на минимално регистриране с INSERT...SELECT може да бъде сложен бизнес. Съображенията, изброени в Ръководството за производителност на зареждане на данни, все още са доста изчерпателни, въпреки че трябва да прочетете и SQL Server 2016, Минимално регистриране и въздействие на размера на партидата при операции за групово зареждане от Парикшит Савджани от екипа на SQL Server Tiger, за да получите актуализираната картина за SQL Server 2016 и по-нови версии, при групово зареждане в клъстерирани таблици на rowstore. Въпреки това тази статия се занимава единствено с предоставянето на нови подробности относно минимално регистриране при групово зареждане на традиционните (не „оптимизирани за паметта“) таблици на heap с помощта на INSERT...SELECT . Таблици с клъстериран индекс на b-дърво са разгледани отделно във втора част от тази серия.
Heap таблици
При вмъкване на редове с помощта на INSERT...SELECT в купчина без неклъстерирани индекси, документацията универсално гласи, че такива вмъквания ще се записват минимално стига TABLOCK намек е налице. Това е отразено в обобщените таблици, включени в Ръководството за ефективност при зареждане на данни и постът на Tiger Team. Обобщените редове за хеп таблици без индекси са еднакви и в двата документа (без промени за SQL Server 2016):

Изричен TABLOCK намекът не е единственият начин да се изпълни изискването за заключване на ниво таблица . Можем също да зададем „заключване на масата при насипно натоварване“ опция за целевата таблица с помощта на sp_tableoption или чрез активиране на документиран флаг за проследяване 715. (Забележка:Тези опции не са достатъчни за активиране на минимално регистриране при използване на INSERT...SELECT защото INSERT...SELECT не поддържа заключване на групови актуализации).
„Възможно е едновременно“ колоната в резюмето се отнася само за методи за групово зареждане, различни от INSERT...SELECT . Едновременното зареждане на хеп таблица ене възможно с INSERT...SELECT . Както е отбелязано в Ръководството за ефективност при зареждане на данни , групово зареждане с INSERT...SELECT приема изключително X заключване на масата, а не масовата актуализация BU необходимо заключване за едновременни насипни товари.
Всичко това настрана — и ако приемем, че няма друга причина да не очаквате минимално регистриране при групово зареждане на неиндексирана купчина с TABLOCK (или еквивалент) — вложката все още може и да не да бъде минимално регистриран...
Изключение от правилото
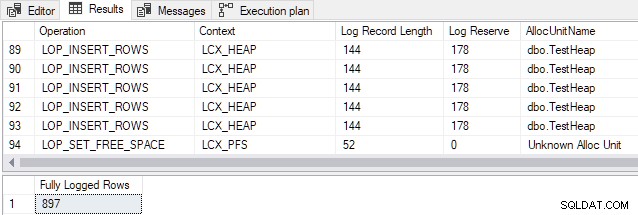
Следният демо скрипт трябва да се изпълни на екземпляр за разработка в нова тестова база данни настроен да използва SIMPLE модел за възстановяване. Той зарежда редица редове в таблица на купчина с помощта на INSERT...SELECT с TABLOCK , и отчети за генерираните записи в регистъра на транзакциите:
СЪЗДАДЕТЕ ТАБЛИЦА dbo.TestHeap( id integer NOT NULL IDENTITY, c1 integer NOT NULL, padding char(45) NOT NULL DEFAULT '');GO-- Изчистете logCHECKPOINT;GO-- Вмъкнете rowsINSERT dbo.TestHeap WITH (TAB ) (c1)SELECT TOP (897) CHECKSUM(NEWID())FROM master.dbo.spt_values КАТО SV;GO-- Показване на записите в дневникаSELECT FD.Operation, FD.Context, FD.[Дължина на записа в дневника], FD.[Log Record]. Reserve], FD.AllocUnitName, FD.[Име на транзакцията], FD.[Информация за заключване], FD.[Описание]FROM sys.fn_dblog(NULL, NULL) КАТО FD;GO-- Пребройте броя на напълно регистрираните редовеSELECT [ Напълно регистрирани редове] =COUNT_BIG(*) ОТ sys.fn_dblog(NULL, NULL) КАТО FDWHERE FD.Operation =N'LOP_INSERT_ROWS' И FD.Context =N'LCX_HEAP' И FD.AllocUnitName =N'dbo;Резултатът показва, че всички 897 реда са напълно регистрирани въпреки че очевидно отговаря на всички условия за минимално регистриране (показани са само извадка от регистрационни записи поради причини за пространство):
Същият резултат се вижда, ако вмъкването се повтори (т.е. няма значение дали таблицата на heap е празна или не). Този резултат противоречи на документацията.
Минималният праг за регистриране за купчини
Броят редове, които човек трябва да добави в един
INSERT...SELECTизявление за постигане на минимално регистриране в неиндексирана купчина с активирано заключване на таблицата зависи от изчислението, което SQL Server извършва при оценката на общия размер на данните, които трябва да бъдат въведени. Входните данни за това изчисление са:
- Версията на SQL Server.
- Прогнозният брой редове, водещи към Вмъкване оператор.
- Целеви размер на реда в таблицата.
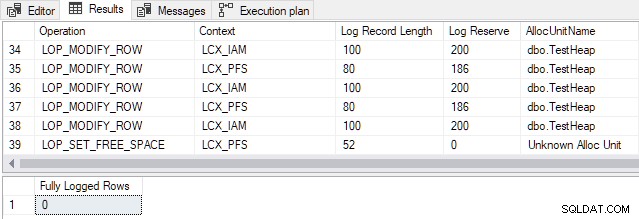
За SQL Server 2012 и по-стари версии , преходната точка за тази конкретна таблица е898 реда . Промяна на номера в демонстрационния скрипт
TOPКлауза от 897 до 898 произвежда следния изход:
Генерираните записи в дневника на транзакциите се отнасят до разпределението на страници и поддръжката на Карта за разпределение на индекси (IAM) и Свободно пространство за страници (PFS) структури. Запомнете това минимално регистриране означава, че SQL Server не регистрира всяко вмъкване на ред поотделно. Вместо това се записват само промените в метаданните и структурите за разпределение. Промяната от 897 на 898 реда позволява минимално регистриране за тази конкретна таблица.
За SQL Server 2014 и по-нови версии , точката на преход е950 реда за тази маса. Изпълняване на
INSERT...SELECTсTOP (949)ще използва пълно регистриране – промяна наTOP (950)ще произведе минимално регистриране .Праговете сане зависи от Оценката на кардиналността използван модел или нивото на съвместимост на базата данни.
Изчисляване на размера на данните
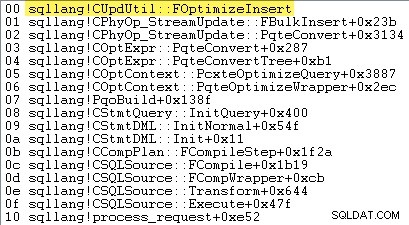
Дали SQL Server решава да използва насипно натоварване на набор от редове — и следователно дали минимално регистриране е наличен или не — зависи от резултата от поредица от изчисления, извършени в метод, наречен
sqllang!CUpdUtil::FOptimizeInsert, което или връща true за минимално регистриране или false за пълно регистриране. Примерен стек от повиквания е показан по-долу:
Същността на теста е:
- Вложката трябва да е за повече от 250 реда .
- Общият размер на вмъкнатите данни трябва да се изчисли като най-малко 8 страници .
Проверката за повече от 250 реда зависи единствено от приблизителния брой редове, пристигащи в Вмъкване на таблица оператор. Това е показано в плана за изпълнение като „Прогнозен брой редове“ . Бъдете внимателни с това. Лесно е да се създаде план с нисък приблизителен брой редове, например чрез използване на променлива в
TOPклауза безOPTION (RECOMPILE). В този случай оптимизаторът предполага 100 реда, които няма да достигнат прага и така предотвратява насипното натоварване и минимално регистриране.Изчисляването на общия размер на данните е по-сложно и не съвпада „Прогнозен размер на реда“ вливащи се в Вмъкване на таблица оператор. Начинът, по който се извършва изчислението, е малко по-различен в SQL Server 2012 и по-рано в сравнение със SQL Server 2014 и по-нови. И все пак и двете дават резултат с размер на ред, който е различен от това, което се вижда в плана за изпълнение.
Изчисляване на размера на реда
Общият размер на данните за вмъкване се изчислява чрез умножаване на прогнозния брой редове от очаквания максимален размер на ред . Изчисляването на размера на реда е точката, която се различава между версиите на SQL Server.
В SQL Server 2012 и по-стари, изчислението се извършва от
sqllang!OptimizerUtil::ComputeRowLength. За таблицата за тестова купчина (умишлено проектирана с прости колони с фиксирана дължина, които не са нула, използвайки оригиналния FixedVar формат за съхранение на ред) схемата на изчислението е:
- Инициализирайте FixedVar генератор на метаданни.
- Вземете информация за тип и атрибут за всяка колона в Вмъкване на таблица входен поток.
- Добавете въведени колони и атрибути към метаданните.
- Финализирайте генератора и го попитайте за максималния размер на реда.
- Добавете допълнителни разходи за нулевата растерна карта и брой колони.
- Добавете четири байта за ред битове за състояние и изместване на реда спрямо броя на колоните с данни.
Физически размер на ред
Може да се очаква резултатът от това изчисление да съответства на физическия размер на реда, но не е така. Например, с изключено управление на реда за базата данни:
ИЗБЕРЕТЕ DDIPS.index_type_desc, DDIPS.alloc_unit_type_desc, DDIPS.page_count, DDIPS.record_count, DDIPS.min_record_size_in_bytes, DDIPS.max_record_size_in_bytes, DDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_size_in_in_DDIPS. U'), 0, -- heap NULL, -- всички дялове 'ПОДРОБНО' ) КАТО DDIPS;… дава рекорден размер от 60 байта във всеки ред на тестовата таблица:
Това е както е описано в Оценка на размера на купа:
- Общ размер на байтовете за всички с фиксирана дължина колони =53 байта:
id integer NOT NULL=4 байтаc1 integer NOT NULL=4 байтаpadding char(45) NOT NULL=45 байта.- Нулева растерна карта =3 байта :
- =2 + int((Брой_колове + 7) / 8)
- =2 + int((3 + 7) / 8)
- =3 байта.
- Заглавка на ред =4 байта .
- Общо 53 + 3 + 4 =60 байта .
Също така съответства на прогнозния размер на реда, показан в плана за изпълнение:
Подробности за вътрешни изчисления
Вътрешното изчисление, използвано за определяне дали се използва насипно натоварване, дава различен резултат въз основа на следния вмъкване на поток информация за колоната, получена с помощта на дебъгер. Използваните номера на типове съвпадат с
sys.types:
- Обща фиксирана дължина размер на колоната =66 байта :
- Въведете идентификатор 173
binary(8)=8 байта (вътрешни).- Въведете идентификатор 56
integer=4 байта (вътрешни).- Въведете идентификатор 104
bit=1 байт (вътрешен).- Въведете идентификатор 56
integer=4 байта (idколона).- Въведете идентификатор 56
integer=4 байта (c1колона).- Въведете идентификатор 175
char(45)=45 байта (paddingколона).- Нулева растерна карта =3 байта (както преди).
- Заглавка на ред служебни =4 байта (както преди).
- Изчислен размер на реда =66 + 3 + 4 =73 байта .
Разликата е, че входният поток захранва Вмъкване на таблица операторът съдържа три допълнителни вътрешни колони . Те се премахват, когато се генерира шоуплан. Допълнителните колони съставляват локатора за вмъкване на таблица , който включва отметката (RID или локатор на редове) като свой първи компонент. Това са метаданни за вложката и в крайна сметка не се добавя към таблицата.
Допълнителните колони обясняват несъответствието между изчисленията, извършени от
OptimizerUtil::ComputeRowLengthи физическия размер на редовете. Това може да се разглежда като бъг :SQL Server не трябва да брои колоните с метаданни в потока за вмъкване към крайния физически размер на реда. От друга страна, изчислението може просто да бъде оценка на най-доброто усилие с помощта на общата актуализация оператор.Изчислението също не взема под внимание други фактори като 14-байтовите допълнителни разходи за версията на редове. Това може да се тества чрез повторно стартиране на демонстрационния скрипт с една от изолацията на моментни снимки или прочетете изолацията на извършени моментни снимки опциите на базата данни са активирани. Физическият размер на реда ще се увеличи с 14 байта (от 60 байта на 74), но прагът за минимално регистриране остава непроменен на 898 реда.
Изчисляване на прага
Вече имаме всички подробности, от които се нуждаем, за да видим защо прагът е 898 реда за тази таблица на SQL Server 2012 и по-ранни версии:
- 898 реда отговарят на първото изискване за повече от 250 реда .
- Размер на изчисления ред =73 байта.
- Прогнозен брой редове =897.
- Общ размер на данните =73 байта * 897 реда =65481 байта.
- Общо страници =65481 / 8192 =7,9932861328125.
- Това е точно под второто изискване за>=8 страници.
- За 898 реда броят на страниците е 8,002197265625.
- Това е >=8 страници така че минимално регистриране е активиран.
В SQL Server 2014 и по-нови версии , промените са:
- Размерът на реда се изчислява от генератора на метаданни.
- Вътрешната колона с цяло число в локатора на таблица вече не присъства в потока за вмъкване. Това представлява унификатора , което се отнася само за индекси. Изглежда вероятно това е премахнато като корекция на грешка.
- Очакваният размер на реда се променя от 73 на 69 байта поради пропуснатата колона с цяло число (4 байта).
- Физическият размер все още е 60 байта. Останалата разлика от 9 байта се отчита от допълнителните 8-байтови RID и 1-байтови битови вътрешни колони в потока за вмъкване.
За да достигнете прага от 8 страници с 69 байта на ред:
- 8 страници * 8192 байта на страница =65536 байта.
- 65535 байта / 69 байта на ред =949,7971014492754 реда.
- Затова очакваме минимум 950 реда за да активирате насипно зареждане на набор от редове за тази таблица на SQL Server 2014 нататък.
Обобщение и заключителни мисли
За разлика от методите за групово зареждане, които поддържат размер на партидата , както е обхванато в публикацията от Parikshit Savjani,
INSERT...SELECTв неиндексирана купчина (празна или не) не винаги води до минимално регистриране, когато е посочено заключване на таблица.За да активирате минимално регистриране с
INSERT...SELECT, SQL Server трябва да очаква повече от 250 реда с общ размерпоне една степен (8 страници).При изчисляване на приблизителния общ размер на вмъкване (за сравнение с прага от 8 страници), SQL Server умножава прогнозния брой редове по изчислен максимален размер на ред. SQL Server брои вътрешни колони присъства в потока за вмъкване при изчисляване на размера на реда. За SQL Server 2012 и по-стари, това добавя 13 байта на ред. За SQL Server 2014 и по-нови версии той добавя 9 байта на ред. Това засяга само изчислението; това не засяга крайния физически размер на редовете.
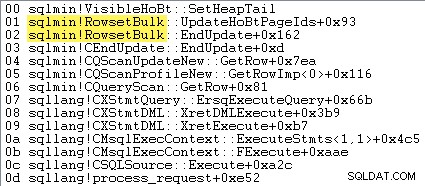
Когато груповото зареждане с минимално регистриран диск е активно, SQL Server не вмъкване на редове един по един. Екстентите се разпределят предварително и редовете за вмъкване се събират в цели нови страници от
sqlmin!RowsetBulkпреди да бъде добавен към съществуващата структура. Примерен стек от повиквания е показан по-долу:
Логическите показанияне се отчитат за целевата таблица, когато се използва минимално регистрирано групово натоварване на купчина – Вмъкване на таблица операторът не трябва да чете съществуваща страница, за да намери точката на вмъкване за всеки нов ред.
Плановете за изпълнение в момента не се показват колко реда или страници са били вмъкнати чрез групово зареждане на набор от редове и минимално регистриране . Може би тази полезна информация ще бъде добавена към продукта в бъдеща версия.