Въведение
В SQL Server 2012 групираното (векторно) агрегиране може да използва паралелно изпълнение в пакетен режим, но само за частичния агрегат (за нишка). Свързаният глобален агрегат винаги се изпълняваше в режим на ред, след Потоци за преразпределение обмен.
SQL Server 2014 добави възможността за извършване на паралелно групирано агрегиране в пакетен режим в рамките на един Hash Match Aggregate оператор. Това елиминира ненужната обработка в режим на ред и премахва необходимостта от обмен.
SQL Server 2016 въведе обработка в сериен пакетен режим и обобщено натискане надолу . Когато натискането е успешно, агрегирането се извършва в рамките на Сканиране на Columnstore оператор, вероятно работещ директно върху компресирани данни и се възползвайки от инструкциите на SIMD CPU.
Подобренията в производителността, възможни с избутване на агрегата, могат да бъдат много съществени. Документацията изброява някои от условията, необходими за постигане на избутване, но има случаи, в които липсата на „локално обобщени редове“ не може да бъде напълно обяснена само от тези подробности.
Тази статия обхваща допълнителни фактори, които влияят на съвкупното натискане надолу за GROUP BY само заявките . Натискане на скаларен агрегат (агрегиране без GROUP BY клауза), натискане на филтъра и натискане на изрази може да бъдат разгледани в бъдеща публикация.
Хранилище в Columnstore
Първото нещо, което трябва да се каже, е, че обобщеното избутване се прилага само за компресирани данни, така че редовете в делта магазин не отговарят на условията. Освен това натискането надолу може да зависи от вида на използваната компресия. За да разберете това, е необходимо първо да прегледате как работи хранилището в columnstore на високо ниво:
компресирана група редове съдържа сегмент на колона за всяка колона. Стойностите на необработените колони са кодирани в 4-байтово или 8-байтово цяло число, използващо стойност или речник кодиране.
Кодиране на стойност може да намали броя на битовете, необходими за съхранение, като превежда необработените стойности, използвайки базово изместване и модификатор на величина. Например, стойностите {1100, 1200, 1300} могат да бъдат съхранени като (0, 1, 2), като първо се мащабират с коефициент 0,01, за да се получат {11, 12, 13}, след което се пребазират на 11, за да се даде {0, 1, 2}.
Кодиране на речник се използва, когато има дублиращи се стойности. Може да се използва с нечислови данни. Всяка уникална стойност се съхранява в речник и се присвоява целочислен идентификатор. След това сегментните данни препращат към идентификационните номера в речника вместо към оригиналните стойности.
След кодиране сегментните данни могат да бъдат допълнително компресирани с помощта на кодиране с дължина на изпълнение (RLE) и пакетиране на битове:
RLE заменя повтарящите се елементи с данните и броят на повторенията, например {1, 1, 1, 1, 1, 2, 2, 2} може да бъде заменен с {5×1, 3×2}. Спестяването на място на RLE се увеличава с продължителността на повтарящите се серии. Кратките бягания могат да бъдат контрапродуктивни.
Бит-опаковане съхранява двоичната форма на данните във възможно най-тесен общ прозорец. Например, числата {7, 9, 15} се съхраняват в двоични (еднобайтови за интервал) цели числа като {00000111, 00001001, 00001111}. Пакетирането на тези битове във фиксиран четирибитов прозорец дава потока {011110011111}. Знаейки, че има фиксиран размер на прозореца, означава, че няма нужда от разделител.
Кодирането и компресирането са отделни стъпки, така че RLE и битово пакетиране се прилагат към резултата от кодиране на стойност или речниково кодиране на необработените данни. Освен това данните в рамките на един и същи сегмент на колона могат да имат смесване на RLE и компресиране на битово пакетиране. Компресираните с RLE данни се наричатчисти , а компресираните данни с битове се наричат нечисти . Сегмент на колона може да съдържа както чисти, така и нечисти данни.
Спестяването на пространство, което може да се постигне чрез кодиране и компресиране, може да зависи от поръчката. Всички сегменти на колони в група от редове трябва да бъдат имплицитно сортирани по същия начин, така че SQL Server да може ефективно да реконструира пълни редове от сегментите на колоните. Знаейки, че ред 123 се съхранява на една и съща позиция (123) във всеки сегмент от колона означава, че номерът на реда не трябва да се съхранява.
Един недостатък на това споразумение е, че общ ред на сортиране трябва да бъде избран за всички сегменти на колони в група редове. Конкретна поръчка може да отговаря много добре на една колона, но да пропусне значителни възможности в други колони. Това е най-очевидно случаят с RLE компресията. SQL Server използва технологията Vertipaq, за да определи добър начин за сортиране на колони във всяка група редове, за да даде добър общ резултат за компресиране.
SQL Server понастоящем използва само RLE в рамките на сегмент от колона, когато има минимум 64 последователни повтарящи се стойности. Останалите стойности в сегмента са битово пакетирани. Както бе отбелязано, дали повтарящите се стойности се появяват като последователни в сегмент от колона зависи от подредбата, избрана за групата редове.
SQL Server поддържа специализиран SIMD разопаковане на битове за битови ширини от 1 до 10 включително, 12 и 21 бита. SQL Server може също да използва стандартни цели числа, напр. 16, 32 и 64 бита с битово пакетиране. Тези номера са избрани, защото теприлягат добре в 64-битов модул. Например, едно устройство може да съдържа три 21-битови субединици или 5 12-битови субединици. SQL Server не пресичат 64-битова граница при пакетиране на битове.
SIMD използва 256-битови регистри, когато процесорът поддържа инструкции AVX2, и 128-битови регистри, когато са налични инструкции SSE4.2. В противен случай може да се използва разопаковане без SIMD.
Групирани обобщени условия за изтегляне
Повечето планове с Hash Match Aggregate оператор директно над Сканиране на Columnstore операторът потенциално ще отговаря на изискванията за групирано изтласкване на агрегати, при спазване на общите условия, отбелязани в документацията.
Понякога могат да се добавят допълнителни филтри и изрази, без да се предотвратява групирано избутване на агрегати. Общото правило е, че филтърът или изразът също трябва да могат да се натискат надолу (въпреки че съвместимите изрази все още могат да се появяват в отделен Изчислителен скалар ). Както е отбелязано във въведението, тези аспекти могат да бъдат разгледани подробно в отделни статии.
Понастоящем няма нищо в плановете за изпълнение, което да указва дали даден агрегат се счита за общо съвместим с групиран агрегат натискане или не. Все пак, когато планът по принцип отговаря на условията за групирани обобщени кодови пътища са достъпни както за натискане (бърз), така и без натискане (бавен).
Всяка изходна партида за сканиране (до 900 реда) взема решение по време на изпълнение между бързия и бавния код. Тази гъвкавост позволява на възможно най-много партиди да се възползват от натискането. В най-лошия случай нито една партида няма да използва бързия път по време на изпълнение, въпреки „общо съвместим“ план.
Планът за изпълнение показва резултата от бърза обработка надолу като „локално агрегирани редове“ без съответен изходен ред от сканирането. Партидите с бавен път се появяват като изходни редове от сканирането на columnstore както обикновено, като агрегирането се извършва от отделен оператор вместо при сканирането.
Една-единствена групирана комбинация от агрегат и сканиране може да изпрати някои партиди по бързия път, а други по бавния, така че е напълно възможно да видите някои, но не всички, редове локално агрегирани. Когато избутването на групирания агрегат е успешно, всяка изходна партида от сканирането съдържа групиращи ключове и частичен агрегат, представляващ редовете, които допринасят.
Подробни проверки
Има редица проверки по време на изпълнение, за да се определи дали може да се използва обработката надолу. Сред леко документираните проверки са:
- Не трябва да има възможност за агрегирано препълване .
- Всяко нечисто (напълнени с битове) групиране на ключове трябва да е не по-широко от 10 бита . Чистите (RLE кодирани) ключове за групиране се третират като с нечиста ширина нула, така че те обикновено представляват няколко препятствия.
- Обработката с натискане надолу трябва да продължи да се счита за полезна , като се използва „мярка за полза“, актуализирана в края на всяка изходна партида.
Възможност отагрегатно преливане се оценява консервативно за всяка партида въз основа на типа на агрегата, типа данни за резултата, текущите стойности на частичното агрегиране и информацията за входните данни. Например SQL Server знае минимални и максимални стойности от метаданните на сегмента, както са изложени в DMV sys.column_store_segments . Когато има риск от препълване, партидата ще използва бавна обработка на пътя. Това е най-вече риск за SUM съвкупност.
Ограничението за нечиста ширина на ключа за групиране заслужава да се подчертае. Прилага се само за колони в GROUP BY клауза, които реално се използват в плана за изпълнение като основа за групиране. Тези набори не винаги са напълно еднакви, тъй като оптимизаторът има свободата да премахва излишните колони за групиране или да пренаписва по друг начин агрегати, стига окончателните резултати от заявката да са гарантирани, че съответстват на оригиналната спецификация на заявката. Когато има несъответствие, от значение са групиращите колони, показани в плана за изпълнение.
По-голямата трудност е да се знае дали някоя от колоните за групиране се съхранява чрез битово пакетиране и ако е така, каква ширина е използвана. Също така би било полезно да знаете колко стойности са кодирани с помощта на RLE. Тази информация може да бъде в column_store_segments DMV, но днес не е така. Доколкото знам, в момента няма документиран начин за получаване на информация за битово опаковане и RLE от метаданни. Това ни кара да търсим недокументирани алтернативи.
Намиране на RLE и информация за пакетиране на битове
Недокументираният DBCC CSINDEX може да ни даде необходимата информация. Флагът за проследяване 3604 трябва да е включен, за да може тази команда да произведе изход в раздела SSMS съобщения. Предвид информацията за сегмента на колоната, който ни интересува, тази команда връща:
- Атрибути на сегмента (подобно на
column_store_segments) - информация за RLE
- Отметки към RLE данни
- Информация за Bitpack
Тъй като е недокументиран, има няколко странности (като например да се наложи да добавите един към идентификаторите на колони за клъстерирано columnstore, но не и неклъстерирано columnstore) и дори няколко дребни грешки. Не трябва да го използвате за нищо освен лична тестова система. Надяваме се, че един ден вместо това ще бъде предоставен поддържан метод за достъп до тези данни.
Примери
Най-добрият начин да покажете DBCC CSINDEX и демонстриране на точките, направени досега в този текст, е да работите чрез някои примери. Следващите скриптове предполагат, че има таблица, наречена dbo.Numbers в текущата база данни, която съдържа цели числа от 1 до поне 16 384. Ето скрипт за създаване на моята стандартна версия на тази таблица с десет милиона цели числа:
АКО OBJECT_ID(N'dbo.Numbers', N'U') НЕ Е NULLBEGIN DROP TABLE dbo.Numbers;END;GOWITH Ten(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) SELECT n =IDENTITY(int, 1, 1)INTO dbo.Числа ОТ Десет КАТО T10CROSS ПРИСЪЕДИНЯВАЙТЕ Десет КАТО T100 КРОСНО ПРИСЪЕДИНЕТЕ T1000CROSS JOIN Десет КАТО T10000CROSS JOIN Десет КАТО T100000CROSS JOIN Десет КАТО T1000000CROSS JOIN Десет КАТО T10000000ORDER BY n OFFSET 0 РЕДОВЕ ИЗВЛЕЧВАНЕ ПЪРВИ 10 * 1000 ROWS ИЗВЪРЧВАНЕ НА ПЪРВИ 10 * 1000 ROWS. КЛУСТРИРАН КЛЮЧ (n)С( SORT_IN_TEMPDB =ON, MAXDOP =1, FILLFACTOR =100);
Всички примери използват една и съща основна тестова таблица:Първата колона c1 съдържа уникален номер за всеки ред. Втората колона c2 се попълва с определен брой дубликати за всяка от малък брой различни стойности.
Създава се клъстериран индекс на columnstore след попълване на данни, така че всички тестови данни да завършват в една компресирана група от редове (без делта магазин). Той е изграден като замества клъстериран индекс на b-дърво на колона c2 за да насърчи алгоритъма на VertiPaq да обмисли полезността на сортирането в тази колона в началото. Това е основната настройка на теста:
ИЗПОЛЗВАЙТЕ Sandpit;GODROP TABLE АКО СЪЩЕСТВУВА dbo.Test;GOCREATE TABLE dbo.Test( c1 цяло число НЕ НУЛВО, c2 цяло число НЕ НУЛВО);GODECLARE @values integer =512, @dupes integer =63; INSERT dbo.Test (c1, c2)ИЗБЕРЕТЕ N.n, N.n % @valuesFROM dbo.Numbers КАТО NWHERE N.n МЕЖДУ 1 И @values * @dupes;GO-- Насърчете VertiPaqCREATE CLUSTERED INDEX CCSI ON CLUSTERED C2STERED C2STERED C2. ИНДЕКС CCSI ON dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
Двете променливи са за броя на различни стойности, които да се вмъкнат в колона c2 и броя на дубликатите за всяка от тези стойности.
Тестовата заявка е много проста групирана COUNT_BIG агрегиране с помощта на колона c2 като ключ:
-- Тестовата заявкаSELECT T.c2, numrows =COUNT_BIG(*)FROM dbo.Test AS TGROUP BY T.c2;
Информацията за индекса на Columnstore ще се показва с помощта на DBCC CSINDEX след всяко изпълнение на тестова заявка:
DECLARE @dbname sysname =DB_NAME(), @objectid integer =OBJECT_ID(N'dbo.Test', N'U'); ДЕКЛАРИРАНЕ @rowsetid bigint =( ИЗБЕРЕТЕ P.hobt_id ОТ sys.partitions КАТО P КЪДЕ P.[object_id] =@objectid И P.index_id =1 И P.partition_number =1 ), @rowgroupid цяло число =0, @columnid цяло число =PROPERTY COLUMN (@objectid, N'c2', 'ColumnId') + 1; DBCC CSINDEX( @dbname, @rowsetid, @columnid, @rowgroupid, 1, -- показване на сегментни данни 2, -- опция за печат 0, -- начална единица за битов пакет (включително) 2 -- крайна единица за битпак (изключително));Тестовете бяха проведени на най-новата пусната версия на SQL Server, налична към момента на писане:Microsoft SQL Server 2017 RTM-CU13-ODbuild 14.0.3049 Издание за разработчици (64-битово) на Windows 10 Pro. Нещата трябва да работят добре и в най-новата версия на SQL Server 2016.
Тест 1:Натискане надолу, 9-битови нечисти клавиши
Този тест използва скрипта за популация от тестови данни точно както е написано малко по-горе, като създава таблица с 32 256 реда. Колона
c1съдържа числа от 1 до 32 256.Колона
c2съдържа 512 различни стойности от 0 до 511 включително. Всяка стойност вc2едублиран 63 пъти , но те не се появяват като последователни блокове, когато се гледат вc1поръчка; те преминават 63 пъти през стойности от 0 до 511.Предвид горната дискусия, очакваме SQL Server да съхранява
c2данни в колоната с помощта на:
- Кодиране на речник тъй като има значителен брой дублирани стойности.
- Няма RLE . Броят на дубликатите (63) на стойност не достига прага от 64, изискван за RLE.
- Размер на битовата опаковка 9 . 512 отделни речникови записи ще се поберат точно в 9 бита (2^9 =512). Всяка 64-битова единица ще съдържа до седем 9-битови подединици.
Всичко това се потвърждава като правилно с помощта на DBCC CSINDEX заявка:
Атрибутите на сегмента секцията на изхода показва кодиране на речник (тип 2; стойностите за encodingType са както е документирано в sys.column_store_segments ).
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
eOn =37944 Брой на редове =32256
Разделът RLE показва няма данни за RLE , само указател към битовата област и празен запис за стойност нула:
RLE заглавка:
Тип на лоб =3 Брой на RLE масив (по отношение на собствени единици) =2
Размер на запис на RLE масив =8
Данни RLE:
Индекс =0 Индекс на Bitpack Array =0 Брой =32256
Индекс =1 Стойност =0 Брой =0
Заглавката за данни на Bitpack раздел показва размер на bitpack 9 и 4 608 използвани единици bitpack:
Bitpack Data Header:
Входен размер на Bitpack =9 Брой единици на Bitpack =4608 Bitpack MinId =3
Размер на данни в Bitpack =36864
Данните на Bitpack секцията показва стойностите, съхранени в първите две единици за битов пакет, както е поискано от последните два параметъра към DBCC CSINDEX команда. Припомнете си, че всяка 64-битова единица може да съдържа 7 субединици (номерирани от 0 до 6) от по 9 бита всяка (7 x 9 =63 бита). Общите 4608 единици съдържат 4608 * 7 =32 256 реда:
Unit 0 SubUnit 0 =383
Unit 0 SubUnit 1 =255
Unit 0 SubUnit 2 =127
Unit 0 SubUnit 3 =510
Unit 0 SubUnit 4 =381
Единица 0 Подединица 5 =253
Единица 0 Подединица 6 =125
Unit 1 SubUnit 0 =508
Unit 1 Sub Unit 1 =379
Unit 1 Sub Unit 2 =251
Unit 1 Sub Unit 3 =123
Unit 1 Sub Unit 4 =506
Единица 1 субединица 5 =377
Единица 1 субединица 6 =249
Тъй като ключовете за групиране използват битово пакетиране с размер по-малък или равен на 10 , очакваме групирано съвкупно натискане надолу да работят тук. Всъщност планът за изпълнение показва, че всички редове са били локално обобщени при Сканиране на индекса на Columnstore оператор:

Планът xml съдържа ActualLocallyAggregatedRows="32256" в информацията по време на изпълнение за сканирането на индекса.
Тест 2:Без натискане, 12-битови нечисти клавиши
Този тест променя @values параметър до 1025, запазвайки @dupes на 63. Това дава таблица от 64 575 реда с 1025 различни стойности в колона c2 работи от 0 до 1024 включително. Всяка стойност в c2 едублиран 63 пъти .
SQL Server съхранява c2 данни в колоната с помощта на:
- Кодиране на речник тъй като има значителен брой дублирани стойности.
- Няма RLE . Броят на дубликатите (63) на стойност не достига прага от 64, изискван за RLE.
- Разбити с размер 12 . 1025 отделни речникови записи няма да се поберат съвсем в 10 бита (2^10 =1024). Те биха се побрали в 11 бита, но SQL Server не поддържа този размер на пакетиране на битове, както беше споменато по-горе. Следващият най-малък размер е 12 бита. Използвайки 64-битови единици с твърди граници за битово опаковане, не може да се поберат повече 11-битови подединици в 64 бита, отколкото 12-битовите подединици. Така или иначе, 5 субединици ще се поберат в 64-битов модул.
DBCC CSINDEX изходът потвърждава горния анализ:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024 />eNull On =104400 Брой редове =64575
RLE заглавка:
Тип Lob =3 RLE Array Count (По отношение на собствени единици) =2
Размер на RLE Array Entry =8
RLE данни:
Индекс =0 Индекс на Bitpack Array =0 Брой =64575
Индекс =1 Стойност =0 Брой =0
Bitpack Data Header:
Входен размер на Bitpack =12 Bitpack Unit Count =12915 Bitpack MinId =3
Bitpack DataSize =103320
Данни за Bitpack:
Unit 0 SubUnit 0 =767
Unit 0 SubUnit 1 =510
Unit 0 SubUnit 2 =254
Unit 0 SubUnit 3 =1021
Unit 0 SubUnit 4 =765
Unit 1 SubUnit 0 =507
Unit 1 Sub Unit 1 =250
Unit 1 Sub Unit 2 =1019
Unit 1 Sub Unit 3 =761
Unit 1 Sub Unit 4 =505
Тъй като ест групиращите ключове са сразмер над 10 , очакваме групирано съвкупно натискане надолу да не работи тук. Това се потвърждава от плана за изпълнение, показващ нулеви редове локално агрегирани в Сканиране на индекс на Columnstore оператор:
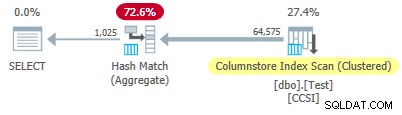
Всички 64 575 реда се излъчват (в партиди) от Сканиране на индекса на Columnstore и се обобщава в пакетен режим от Агрегат на съвпаденията на хеш оператор. ActualLocallyAggregatedRows липсва атрибут в информацията за времетраенето на xml плана за сканирането на индекса.
Тест 3:Pushdown, Pure Keys
Този тест променя @dupes параметър от 63 до 64 за разрешаване на RLE. @values параметърът се променя на 16 384 (максимумът за общия брой редове, които все още се вписват в една група редове). Точният номер, избран за @values не е важно – целта е да се генерират 64 дубликата на всяка уникална стойност, за да може да се използва RLE.
SQL Server съхранява c2 данни в колоната с помощта на:
- Кодиране на речник поради дублираните стойности.
- RLE. Използва се за всяка отделна стойност, тъй като всяка отговаря на прага от 64.
- Без битово пакетирани данни . Ако имаше такива, щеше да използва размер 16. Размер 12 не е достатъчно голям (2^12 =4096 различни стойности) и размер 21 би бил разточителен. 16 384 различни стойности биха се побрали в 14 бита, но както преди, не повече от тях могат да се поберат в 64-битова единица, отколкото 16-битови подединици.
DBCC CSINDEX изходът потвърждава горното (само няколко RLE записа и отметки са показани поради причини за пространство):
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383 On =131648 Брой на редове =1048576
RLE заглавка:
Тип на лоба =3 RLE Array Count (По отношение на собствени единици) =16385
Размер на запис на RLE масив =8
RLE данни:
Индекс =0 Стойност =3 Брой =64
Индекс =1 Стойност =1538 Брой =64
Индекс =2 Стойност =3072 Брой =64
Индекс =3 Стойност =4608 Брой =64
Индекс =4 Стойност =6142 Брой =64
…
Индекс =16381 Стойност =8954 Брой =64
Индекс =16382 Стойност =10489 Брой =64
383 Индекс =1ue =12025 Брой =64
Индекс =16384 Стойност =0 Брой =0
Заглавка на отметка:
Брой на отметките =65 Разстояние на отметките =16384 Размер на отметката =520
Данни за отметки:
Позиция =0 Индекс =64
Позиция =512 Индекс =16448
Позиция =1024 Индекс =32832
…
Позиция =31744 Индекс =1015872
Позиция =Вход =225 1032256
Позиция =32768 Индекс =1048577
Bitpack Data Header:
Входен размер на Bitpack =16 Bitpack Unit Count =0 Bitpack MinId =3
Bitpack DataSize =0
Тъй като ключовете за групиране са чисти (използва се RLE), групирано съвкупно натискане надолу се очаква тук. Планът за изпълнение потвърждава това, като показва всички редове локално агрегирани в Сканиране на индекс на Columnstore оператор:
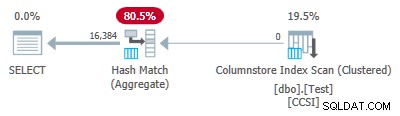
Планът xml съдържа ActualLocallyAggregatedRows="1048576" в информацията по време на изпълнение за сканирането на индекса.
Тест 4:10-битови нечисти ключове
Този тест задава @values до 1024 и @dupes до 63, което дава таблица от 64 512 реда, с 1024 различни стойности в колона c2 със стойности от 0 до 1,023 включително. Всяка стойност в c2 едублиран 63 пъти .
Най-важното , клъстерираният индекс на b-дърво вече е създаден в колона c1 вместо колона c2 . Клъстерираното хранилище за колони все още замества клъстерирания индекс на b-дърво. Това е променената част от скрипта:
-- Забележете колона c1 сега!СЪЗДАЙТЕ КЛУСТРИРАН ИНДЕКС CCSI НА dbo.Test (c1);GOCREATE CLUSTERED COLUMNSTORE INDEX CCSI НА dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
SQL Server съхранява c2 данни в колоната с помощта на:
- Кодиране на речник поради дубликатите.
- Няма RLE . Броят на дубликатите (63) на стойност не достига прага от 64, изискван за RLE.
- Бит-опаковка с размер 10 . 1024 отделни речникови записи се вписват точно в 10 бита (2^10 =1024). Във всяка 64-битова единица могат да се съхраняват шест субединици от по 10 бита.
DBCC CSINDEX изходът е:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023 />eNull On =87096 Брой на редове =64512
RLE заглавка:
Тип Lob =3 RLE Array Count (По отношение на собствени единици) =2
Размер на RLE Array Entry =8
RLE данни:
Индекс =0 Индекс на Bitpack Array =0 Брой =64512
Индекс =1 Стойност =0 Брой =0
Bitpack Data Header:
Входен размер на Bitpack =10 Bitpack Unit Count =10752 Bitpack MinId =3
Bitpack DataSize =86016
Bitpack Data:
Unit 0 SubUnit 0 =766
Unit 0 SubUnit 1 =509
Unit 0 SubUnit 2 =254
Unit 0 SubUnit 3 =1020
Unit 0 SubUnit 4 =764
Единица 0 Подединица 5 =506
Unit 1 SubUnit 0 =250
Unit 1 Sub Unit 1 =1018
Unit 1 Sub Unit 2 =760
Unit 1 Sub Unit 3 =504
Unit 1 Sub Unit 4 =247
Единица 1 Подединица 5 =1014
Тъй като ест групиращите ключове използват размер, по-малък или равен на 10, бихме очаквали групирано съвкупно натискане надолу да работят тук. Но това не се случва . Планът за изпълнение показва, че 54 612 от 64 512 реда са агрегирани в Hash Match Aggregate оператор:
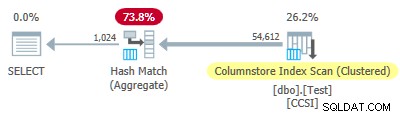
Планът xml съдържа ActualLocallyAggregatedRows="9900" в информацията по време на изпълнение за сканирането на индекса. Това означава групирано съвкупно натискане надолу беше използван за 9 900 реда, но не беше използван за останалите 54 612!
Механизмът за обратна връзка
SQL Server стартира с групирано избутване на агрегати за това изпълнение, тъй като нечистите ключове за групиране отговарят на критериите от 10 бита или по-малко. Това продължи общо 11 партиди (от 900 реда всяка =общо 9900 реда). В този момент механизъм за обратна връзка, измерващ ефективността на групираното изтласкване на агрегати реши, че не работи, иго изключи . Всички останали партиди бяха обработени с деактивирано натискане.
Обратната връзка по същество сравнява броя на агрегираните редове с броя на произведените групи. Започва със стойност от 100 и се коригира в края на всяка изходяща партида за натискане. Ако стойността падне до 10 или по-малко, натискането надолу е забранено за текущата операция за групиране.
„Мярката за полза от натискане надолу“ се намалява повече или по-малко в зависимост от това колко зле върви усилията за изтласкване надолу. Ако има по-малко от 8 реда средно на ключ за групиране в изходната партида, текущата стойност на ползата се намалява с 22%. Ако има повече от 8, но по-малко от 16, показателят се намалява с 11%.
От друга страна, ако нещата се подобрят и впоследствие се срещнат 16 или повече реда на ключ за групиране за изходна партида, показателят се нулира на 100 и продължава да се коригира, тъй като частични обобщени партиди се произвеждат от сканирането.
Данните в този тест бяха представени в особено безполезен ред за избутване поради оригиналния клъстериран индекс на b-дърво в колона c1 . Когато са представени по този начин, стойностите в колона c2 започват от 0 и се увеличават с 1, докато достигнат 1023, след което започват цикъла отново. 1023 различни стойности са повече от достатъчни, за да гарантират, че всяка изходна партида от 900 реда съдържа само един частично агрегиран ред за всеки ключ. Това не е щастливо състояние.
Ако имаше 64 дубликата на стойност вместо 63, SQL Server щеше да обмисли сортиране по c2 докато изгражда индекса на columnstore и така произвежда RLE компресия. Както е така, наказанието от 22% започва след всяка партида. Започвайки от 100 и използвайки същата аритметика за закръглене нагоре, последователността от метрични стойности е:
-- @metric :=FLOOR(@metric * 0,78 + 0,5);-- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Единадесетата партида намалява показателя до 10 или по-малко и натискането надолу е деактивирано. 11-те партиди от 900 реда представляват 9900 локално агрегирани реда, показани в плана за изпълнение.
Вариант с 900 различни стойности
Същото поведение може да се види в тест 4 с най-малко 901 различни стойности, като се приеме, че редовете са представени в един и същ безполезен ред.
Промяна на @values параметър до 900, като същевременно запази всичко останало същото, има драматичен ефект върху плана за изпълнение:
Сега всички 900 групи са обобщени при сканирането! Свойствата на xml плана показват ActualLocallyAggregatedRows="56700" . Това се дължи на факта, че групираните агрегати поддържат 900 групиращи ключа и частични агрегати в една партида. Той никога не среща нова ключова стойност извън партидата, така че няма причина да стартирате нова изходна партида.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Забележка: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.