За този месец T-SQL вторник, Стив Джоунс (@way0utwest) ни помоли да говорим за най-добрите или най-лошите ни тригери. Въпреки че е вярно, че тригерите често не се гледат с недоволство и дори се страхуват, те имат няколко валидни случая на употреба, включително:
- Одит (преди 2016 SP1, когато тази функция стана безплатна във всички издания)
- Прилагане на бизнес правила и целостта на данните, когато те не могат лесно да бъдат внедрени в ограничения и не искате те да зависят от кода на приложението или самите DML заявки
- Поддържане на исторически версии на данните (преди улавянето на промените, проследяването на промените и временните таблици)
- Поставяне на опашка на сигнали или асинхронна обработка в отговор на конкретна промяна
- Разрешаване на модификации на изгледи (чрез тригери INSTEAD OF)
Това не е изчерпателен списък, а само кратко обобщение на няколко сценария, които преживях, при които тригерите бяха правилният отговор по това време.
Когато са необходими задействания, винаги обичам да изследвам използването на тригери ВМЕСТО, а не на задействания AFTER. Да, те са малко по-предварителни*, но имат някои доста важни предимства. Поне на теория перспективата да се предотврати извършването на действие (и последствията от него) изглежда много по-ефективна, отколкото да оставим всичко да се случи и след това да го отмени.
*Казвам това, защото трябва да кодирате DML израза отново в тригера; ето защо те не се наричат преди тригери. Тук разграничението е важно, тъй като някои системи прилагат тригери true BEFORE, които просто се изпълняват първи. В SQL Server тригер INSTEAD OF ефективно отменя израза, който го е причинил да се задейства.
Нека се преструваме, че имаме проста таблица за съхраняване на имена на акаунти. В този пример ще създадем две таблици, за да можем да сравним две различни задействания и тяхното въздействие върху продължителността на заявката и използването на журнала. Концепцията е, че имаме бизнес правило:името на акаунта не присъства в друга таблица, която представлява „лоши“ имена и тригерът се използва за прилагане на това правило. Ето базата данни:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO И таблиците:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
И накрая, тригерите. За простота, ние се занимаваме само с вмъквания и както в следния, така и в случая вместо, просто ще прекратим цялата партида, ако някое едно име нарушава нашето правило:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Сега, за да тестваме производителността, просто ще се опитаме да вмъкнем 100 000 имена във всяка таблица с предвидим процент на отказ от 10%. С други думи, 90 000 са подходящи имена, останалите 10 000 се провалят в теста и карат спусъка да се върне обратно или да не се вмъкне в зависимост от партидата.
Първо, трябва да направим малко почистване преди всяка партида:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Преди да започнем месото на всяка партида, ще преброим редовете в регистъра на транзакциите и ще измерим размера и свободното пространство. След това ще преминем през курсор, за да обработим 100 000 реда в произволен ред, опитвайки се да вмъкнем всяко име в съответната таблица. Когато приключим, ще измерим отново броя на редовете и размера на дневника и ще проверим продължителността.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Резултати (средно за 5 проби от всяка партида):
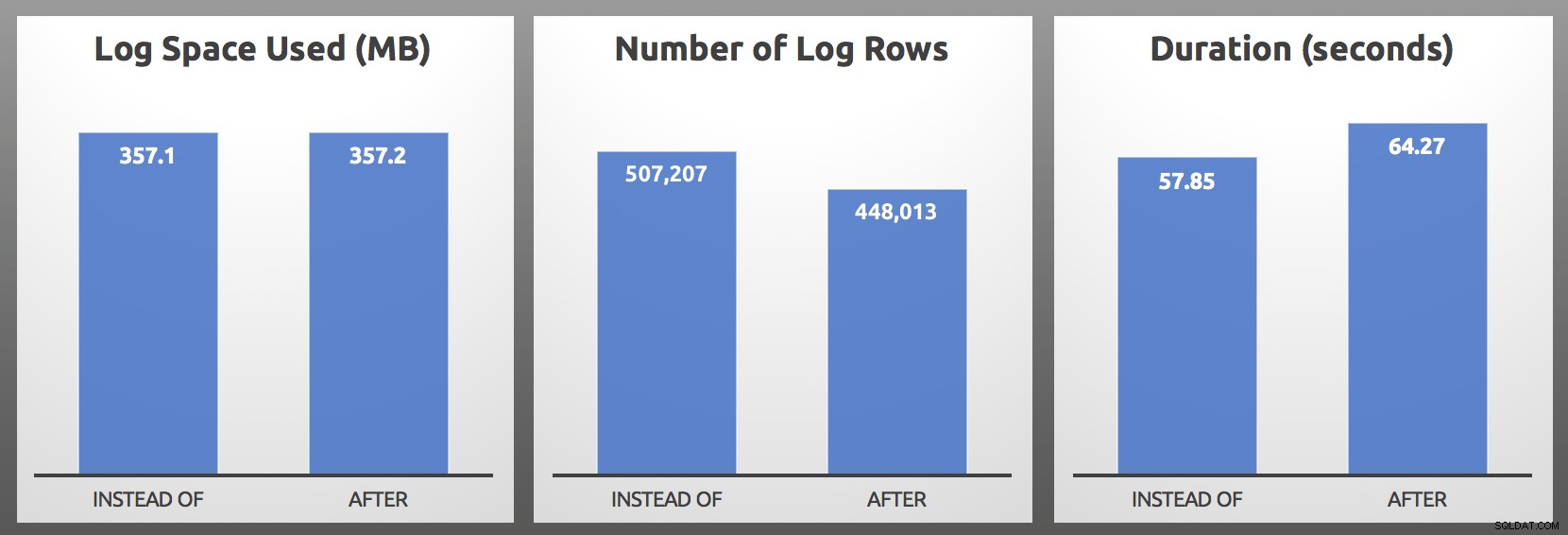 СЛЕД срещу ВМЕСТО :Резултати
СЛЕД срещу ВМЕСТО :Резултати
В моите тестове използването на дневника беше почти идентично по размер, с над 10% повече дневници, генерирани от тригера INSTEAD OF. Направих малко копаене в края на всяка партида:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
И ето един типичен резултат (откроих основните делти):
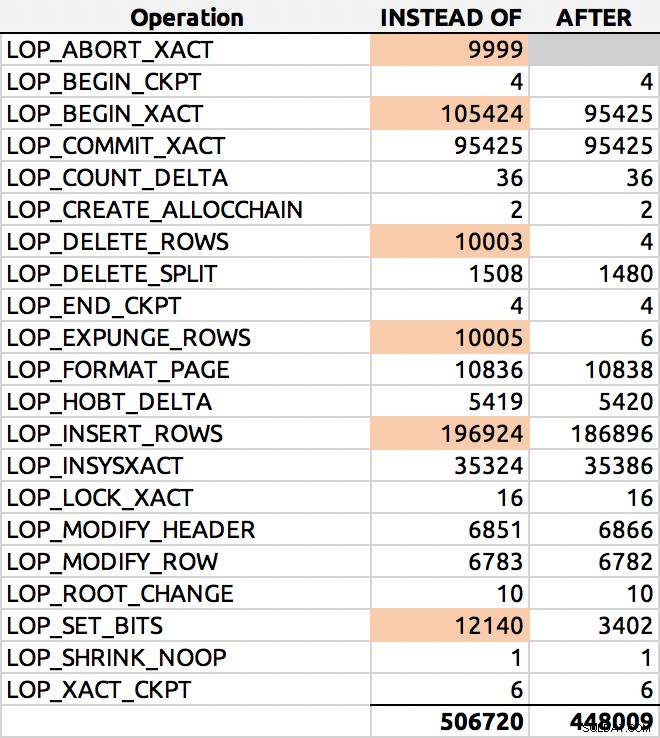 Разпределение на редове в регистрационния файл
Разпределение на редове в регистрационния файл
Ще се поразровя по-задълбочено друг път.
Но когато стигнете до него...
…най-важният показател почти винаги ще бъде продължителност , а в моя случай спусъкът INSTEAD OF се изпълняваше поне с 5 секунди по-бързо при всеки единичен директен тест. В случай, че всичко това звучи познато, да, говорил съм за това и преди, но тогава не наблюдавах същите симптоми с редовете на регистрационните файлове.
Обърнете внимание, че това може да не е точната ви схема или работно натоварване, може да имате много различен хардуер, едновременността ви може да е по-висока и степента на отказ може да е много по-висока (или по-ниска). Тестовете ми бяха извършени на изолирана машина с много памет и много бързи PCIe SSD. Ако вашият дневник е на по-бавно устройство, тогава разликите в използването на регистрационните файлове може да надвишават другите показатели и да променят продължителността значително. Всички тези фактори (и повече!) могат да повлияят на резултатите ви, така че трябва да тествате във вашата среда.
Въпросът обаче е, че ВМЕСТО тригерите може да са по-подходящи. Сега само ако можехме да получим ВМЕСТО DDL тригери...