Задачите за пропуски и острови са класически предизвикателства за заявки, при които трябва да идентифицирате диапазони от липсващи стойности и диапазони от съществуващи стойности в последователност. Последователността често се основава на някаква дата или стойности за дата и час, които обикновено трябва да се появяват на редовни интервали, но някои записи липсват. Задачата за пропуски търси липсващите периоди, а задачата за острови търси съществуващите периоди. Покрих много решения на задачи за пропуски и острови в моите книги и статии в миналото. Наскоро ми беше представено ново специално предизвикателство за острови от моя приятел Адам Мачаник и решаването му изискваше малко креативност. В тази статия представям предизвикателството и решението, което измислих.
Предизвикателството
Във вашата база данни вие следите услугите, които вашата компания поддържа в таблица, наречена CompanyServices, и всяка услуга обикновено отчита около веднъж в минута, че е онлайн в таблица, наречена EventLog. Следният код създава тези таблици и ги попълва с малки набори от примерни данни:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
В момента таблицата EventLog е попълнена със следните данни:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
Специалната задача на островите е да идентифицира периодите на наличност (обслужен, начален, краен час). Една уловка е, че няма гаранция, че дадена услуга ще докладва, че е онлайн точно всяка минута; трябва да толерирате интервал до, да речем, 66 секунди от предишния запис в дневника и все пак да го считате за част от същия период на наличност (остров). След 66 секунди, новият запис в дневника започва нов период на наличност. И така, за входните примерни данни по-горе, вашето решение трябва да върне следния набор от резултати (не непременно в този ред):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Забележете, например, как запис в дневника 5 започва нов остров, тъй като интервалът от предишния запис в дневника е 120 секунди (> 66), докато запис в дневника 6 не започва нов остров, тъй като интервалът от предишния запис е 62 секунди ( <=66). Друга уловка е, че Адам искаше решението да бъде съвместимо с пред-SQL Server 2012 среди, което го прави много по-трудно предизвикателство, тъй като не можете да използвате агрегатни функции на прозореца с рамка за изчисляване на текущи суми и функции на прозореца за изместване като LAG и LEAD. Както обикновено, предлагам да опитате сами да решите предизвикателството, преди да разгледате моите решения. Използвайте малките набори от примерни данни, за да проверите валидността на вашите решения. Използвайте следния код, за да попълните таблиците си с големи набори от примерни данни (500 услуги, ~10 милиона записи в регистрационния файл, за да тествате производителността на вашите решения):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Резултатите, които ще предоставя за стъпките на моите решения, ще приемат малките набори от примерни данни, а числата за производителност, които ще предоставя, ще приемат големите набори.
Всички решения, които ще представя, се възползват от следния индекс:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Успех!
Решение 1 за SQL Server 2012+
Преди да разгледам решение, което е съвместимо със среди преди SQL Server 2012, ще разгледам едно, което изисква минимум SQL Server 2012. Ще го нарека Решение 1.
Първата стъпка в решението е да се изчисли флаг, наречен isstart, който е 0, ако събитието не стартира нов остров, и 1 в противен случай. Това може да се постигне чрез използване на функцията LAG за получаване на регистрационния час на предишното събитие и проверка дали времевата разлика в секунди между предишното и текущото събитие е по-малка или равна на позволената разлика. Ето кода, който изпълнява тази стъпка:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Този код генерира следния изход:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
След това обикновена текуща сума на флага isstart произвежда идентификатор на острова (ще го нарека grp). Ето кода, който изпълнява тази стъпка:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Този код генерира следния изход:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
И накрая, вие групирате редовете по идентификатор на услугата и идентификатора на острова и връщате минималните и максималните регистрационни времена като начален и краен час на всеки остров. Ето пълното решение:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Завършването на това решение отне 41 секунди в моята система и създаде плана, показан на фигура 1.
 Фигура 1:План за решение 1
Фигура 1:План за решение 1
Както можете да видите, и двете функции на прозореца се изчисляват въз основа на реда на индексите, без да е необходимо изрично сортиране.
Ако използвате SQL Server 2016 или по-нова версия, можете да използвате трика, който разглеждам тук, за да активирате оператора Window Aggregate в пакетен режим, като създадете празен филтриран индекс на columnstore, както следва:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Завършването на същото решение сега отнема само 5 секунди в моята система, като се получава планът, показан на фигура 2.
 Фигура 2:Планиране на решение 1 с помощта на оператора Window Aggregate в пакетния режим
Фигура 2:Планиране на решение 1 с помощта на оператора Window Aggregate в пакетния режим
Всичко това е страхотно, но както споменахме, Адам търсеше решение, което може да работи в среди преди 2012 г.
Преди да продължите, уверете се, че сте изхвърлили индекса на columnstore за почистване:
DROP INDEX idx_cs ON dbo.EventLog;
Решение 2 за среди преди SQL Server 2012
За съжаление, преди SQL Server 2012, нямахме поддръжка за функции на офсетни прозорци като LAG, нито пък имахме поддръжка за изчисляване на текущи суми с агрегатни функции на прозореца с рамка. Това означава, че ще трябва да работите много повече, за да намерите разумно решение.
Трикът, който използвах, е да превърна всеки запис в дневника в изкуствен интервал, чийто начален час е времето на записа и чийто крайен час е времето на записа плюс разрешената празнина. След това можете да третирате задачата като класическа задача за пакетиране на интервали.
Първата стъпка в решението изчислява изкуствените ограничители на интервали и номерата на редове, маркиращи позициите на всеки от видовете събития (counteach). Ето кода, който изпълнява тази стъпка:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Този код генерира следния изход:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Следващата стъпка е да развъртите интервалите в хронологична последователност от начални и крайни събития, идентифицирани като типове събития „s“ и „e“, съответно. Имайте предвид, че изборът на букви s и e е важен ('s' > 'e' ). Тази стъпка изчислява номерата на редове, маркиращи правилния хронологичен ред на двата вида събития, които сега се преплитат (броят и двете). В случай, че един интервал завършва точно там, където започва друг, като позиционирате стартовото събитие преди крайното събитие, вие ще ги опаковате заедно. Ето кода, който изпълнява тази стъпка:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Този код генерира следния изход:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Както бе споменато, counteach маркира позицията на събитието само сред събития от един и същи вид, а countboth маркира позицията на събитието сред комбинираните, преплетени събития от двата вида.
След това магията се обработва от следващата стъпка – изчисляване на броя на активните интервали след всяко събитие въз основа на counteach и countboth. Броят на активните интервали е броят на началните събития, които са се случили досега, минус броя на крайните събития, които са се случили досега. За начални събития counteach ви казва колко начални събития са се случили досега и можете да разберете колко са приключили досега, като извадите counteach от countboth. И така, пълният израз, който ви казва колко интервала са активни, тогава е:
counteach - (countboth - counteach)
За крайни събития counteach ви казва колко крайни събития са се случили досега и можете да разберете колко са започнали досега, като извадите counteach от countboth. И така, пълният израз, който ви казва колко интервала са активни, тогава е:
(countboth - counteach) - counteach
Използвайки следния CASE израз, изчислявате колоната с активен брой на базата на типа събитие:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END В същата стъпка филтрирате само събития, представляващи началото и края на пакетирани интервали. Началите на пакетирани интервали имат тип „s“ и countactive 1. Краищата на пакетирани интервали имат тип „e“ и countactive 0.
След филтриране оставате с двойки събития в началото и края на пакетирани интервали, но всяка двойка е разделена на два реда – един за началното събитие и друг за крайното събитие. Следователно същата стъпка изчислява идентификатор на двойка, като използва номера на редове с формулата (rownum – 1) / 2 + 1.
Ето кода, който изпълнява тази стъпка:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Този код генерира следния изход:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
Последната стъпка завърта двойките събития в ред за интервал и изважда позволената празнина от крайното време, за да възстанови правилното време за събитие. Ето пълния код на решението:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Завършването на това решение отне 43 секунди в моята система и генерира плана, показан на фигура 3.
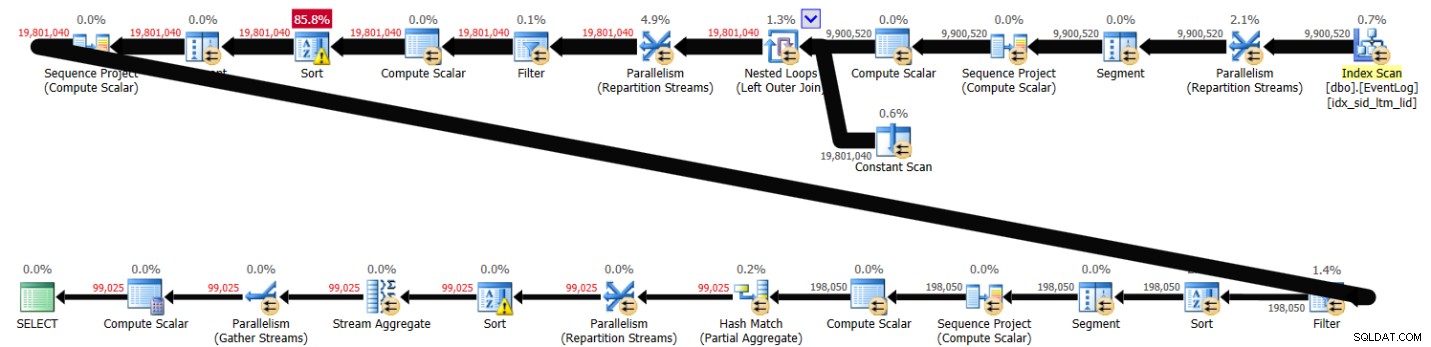 Фигура 3:План за решение 2
Фигура 3:План за решение 2
Както можете да видите, изчисляването на номера на първия ред се изчислява въз основа на реда на индекса, но следващите два включват изрично сортиране. И все пак производителността не е толкова лоша, като се има предвид, че има около 10 000 000 замесени реда.
Въпреки че целта на това решение е да се използва среда преди SQL Server 2012, само за забавление, тествах неговата производителност, след като създадох филтриран индекс на columnstore, за да видя как се справя с активирана пакетна обработка:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
С активирана пакетна обработка това решение отне 29 секунди, за да завърши в моята система, създавайки плана, показан на фигура 4.
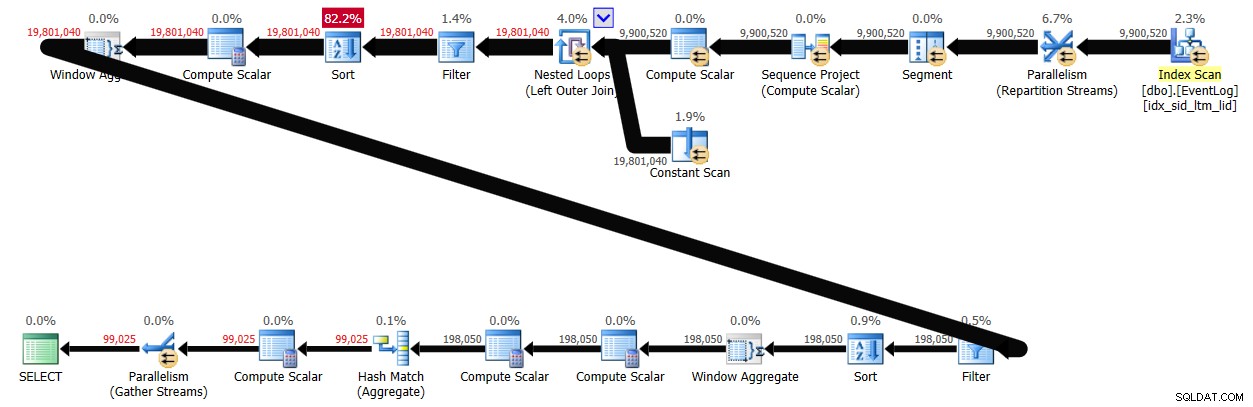
Заключение
Естествено е, че колкото по-ограничена е вашата среда, толкова по-предизвикателно става решаването на задачи за запитване. Специалното предизвикателство на Адам е много по-лесно за решаване на по-нови версии на SQL Server, отколкото на по-стари. Но след това се принуждавате да използвате по-креативни техники. Така че като упражнение, за да подобрите уменията си за запитване, можете да се справите с предизвикателства, с които вече сте запознати, но умишлено да наложите определени ограничения. Никога не знаеш в какви интересни идеи може да се натъкнеш!