Свързали ли сте се някога с Microsoft или партньор на Microsoft и обсъждали ли сте с тях колко би струвало преминаването към облака? Ако е така, може да сте чували за DTU калкулатора на Azure SQL Database DTU и може да сте чели за това как е бил обратно проектиран от Анди Малън. DTU калкулаторът е безплатен инструмент, който можете да използвате, за да качвате показатели за производителност от вашия сървър и да използвате данните, за да определите подходящото ниво на услугата, ако трябва да мигрирате този сървър към Azure SQL база данни (или към еластичен пул на SQL база данни).
За да направите това, трябва или да планирате, или ръчно да стартирате скрипт (команден ред или Powershell, достъпни за изтегляне на уебсайта на DTU калкулатора) по време на период на типично производствено натоварване.
Ако се опитвате да анализирате голяма среда или искате да анализирате данни от конкретни моменти във времето, това може да се превърне в скучна работа. В много случаи много DBA имат някакъв вкус на инструмент за наблюдение, който вече улавя данни за производителността за тях. В много случаи вероятно или вече улавя необходимите показатели, или може лесно да бъде конфигуриран да улавя данните, от които се нуждаете. Днес ще разгледаме как да се възползваме от SentryOne, за да можем да предоставим подходящите данни на DTU калкулатора.
За да започнем, нека разгледаме информацията, извлечена от помощната програма на командния ред и скрипта PowerShell, достъпна на уебсайта на DTU калкулатора; има 4 брояча на монитора на производителността, които улавя:
- Процесор – % процесорно време
- Логически диск – четене на диск/сек
- Логически диск – запис на диск/сек
- База данни – регистрационни байтове, изчистени/сек.
Първата стъпка е да се определи дали тези показатели вече са уловени като част от събирането на данни в SQL Sentry. За откриване предлагам да прочетете тази публикация в блога на Джейсън Хол, където той говори за това как са подредени данните и как можете да ги потърсите. Няма да минавам през всяка стъпка от това тук, но ви насърчавам да прочетете и маркирате цялата поредица от блогове.
Когато прегледах базата данни на SentryOne, открих, че 3 от 4 броя броячи вече се улавят по подразбиране. Единственото, което липсваше, беше [Database – Log Bytes Flushed/sec] , така че трябваше да мога да го включа. Имаше друга публикация в блога на Джъстин Рандал, която обяснява как да направите това.
Накратко, можете да направите заявка за [PerformanceAnalysisCounter] таблица.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Ще забележите, че по подразбиране [PerformanceAnalysisSampleIntervalID] е настроен на 0 – това означава, че е деактивиран. Ще трябва да изпълните следната команда, за да активирате това. Просто изтеглете идентификатора от заявката SELECT, която току-що изпълнихте, и го използвайте в тази АКТУАЛИЗАЦИЯ:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
След като стартирате актуализацията, ще трябва да рестартирате услугата(ите) за наблюдение на SentryOne, свързани с тази цел, за да могат да бъдат събрани новите данни за брояча.
Имайте предвид, че задавам [PerformanceAnalysisSampleIntervalID] до 1, така че данните да се улавят на всеки 10 секунди, но можете да улавяте тези данни по-рядко, за да сведете до минимум размера на събраните данни с цената на по-ниска точност. Вижте [PerformanceAnalysisSampleInterval] таблица за списък със стойности, които можете да използвате.
Не очаквайте данните да започнат да се вливат в таблиците веднага; това ще отнеме време, за да си проправи път през системата. Можете да проверите за население със следната заявка:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
След като потвърдите, че данните се показват, трябва да имате данни за всеки от показателите, изисквани от калкулатора на DTU, въпреки че може да искате да изчакате да ги извлечете отгоре, докато имате представителна извадка от пълен натовареност или бизнес цикъл.
Ако прочетете публикацията в блога на Джейсън, ще видите, че данните се съхраняват в различни сборни таблици и че всяка от тези сборни таблици има различни нива на задържане. Много от тях са по-ниски от това, което бих искал, ако анализирам натоварванията за определен период от време. Въпреки че може да е възможно да ги промените, може да не е най-мъдрото. Тъй като това, което ви показвам, не се поддържа, може да искате да избягвате да бърникате твърде много с настройките на SentryOne, тъй като това може да има отрицателно въздействие върху производителността, растежа или и двете.
За да компенсирам това, създадох скрипт, който ми позволява да извличам нужните ми данни за различните сборни таблици и да съхранява тези данни на свое собствено местоположение, за да мога да контролирам собственото си запазване и да не се намесвам във функционалността на SentryOne.
ТАБЛИЦА:dbo.AzureDatabaseDTUData
Създадох таблица, наречена [AzureDatabaseDTUData] и го съхранява в базата данни SentryOne. Процедурата, която създадох, автоматично ще генерира тази таблица, ако тя не съществува, така че няма нужда да правите това ръчно, освен ако не искате да персонализирате къде се съхранява. Можете да съхраните това в отделна база данни, ако желаете, просто ще трябва да редактирате скрипта, за да го направите. Таблицата изглежда така:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Процедура:dbo.Custom_CollectDTUDataForDevice
Това е съхранената процедура, която можете да използвате, за да изтеглите всички специфични за DTU данни наведнъж (при условие, че сте събирали брояча на регистрационните байтове за достатъчно време) или да планирате периодично да добавяте към събраните данни, докато сте готови да подадете изхода на DTU калкулатора. Подобно на таблицата по-горе, процедурата се създава в базата данни SentryOne, но можете лесно да я създадете другаде, просто добавете имена от три или четири части към препратки към обекти. Интерфейсът на процедурата е както следва:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Забележка :Цялата процедура е малко дълга, така че е прикачена към тази публикация (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Има няколко параметъра, които можете да използвате. Всеки има стойност по подразбиране, така че не е нужно да ги указвате, ако сте добре със стойностите по подразбиране.
- @DeviceID – Това ви позволява да укажете дали искате да събирате данни за конкретен SQL сървър или всичко. По подразбиране е -1, което означава копиране на всички наблюдавани SQL сървъри. Ако искате да експортирате информация само за конкретен екземпляр, намерете
DeviceIDсъответстващ на хоста в[dbo].[Device]таблица и предайте тази стойност. Можете да подадете само един@DeviceIDв даден момент, така че ако искате да преминете през набор от сървъри, можете да извикате процедурата няколко пъти или да промените процедурата, за да поддържа набор от устройства. - @DaysToPurge – Това представлява възрастта, на която искате да премахнете данни. По подразбиране е 14 дни, което означава, че ще изтегляте данни само на възраст до 14 дни, а всички данни, по-стари от 14 дни във вашата персонализирана таблица, ще бъдат изтрити.
Останалите четири параметъра са там за защита в бъдеще, в случай че SentryOne изброява идентификаторите на брояча някога се промени.
Няколко бележки за скрипта:
- Когато данните се изтеглят, те вземат максималната стойност от съкратената минута и я експортират. Това означава, че има една стойност на показател на минута, но това е максималната уловена стойност. Това е важно поради начина, по който данните трябва да бъдат представени на DTU калкулатора.
- Първият път, когато стартирате експортирането, може да отнеме малко повече време. Това е така, защото извлича всички данни, които може, въз основа на стойностите на вашите параметри. При всяко допълнително изпълнение единствените извлечени данни са всичко, което е ново от последното изпълнение, така че трябва да е много по-бързо.
- Ще трябва да насрочите тази процедура да се изпълнява по времеви график, който остава преди процеса на изчистване на SentryOne. Това, което направих, току-що създадох задание на SQL агент, което да се изпълнява всяка нощ, което събира всички нови данни от предната вечер.
- Тъй като процесът на изчистване в SentryOne може да варира в зависимост от показател, може да се окажете с редове във вашето копие, които не съдържат всичките 4 брояча за определен период от време. Може да искате да започнете да анализирате данните си едва от момента, в който стартирате процеса на извличане.
- Използвах блок код от съществуващите процедури на SentryOne, за да определя сборната таблица за всеки брояч. Бих могъл да кодирам твърдо текущите имена на таблиците, но като използвам метода SentryOne, той трябва да е съвместим с всички промени във вградените процеси на сбор.
След като данните ви бъдат преместени в самостоятелна таблица, можете да използвате PIVOT заявка, за да ги трансформирате във формата, която DTU калкулаторът очаква.
Процедура:dbo.Custom_ExportDataForDTUCalculator
Създадох друга процедура за извличане на данните във формат CSV. Кодът за тази процедура също е приложен (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Има три параметъра:
- @DeviceID – Smallint, съответстващ на едно от устройствата, които събирате и което искате да подадете на калкулатора.
- @BeginTime – Дата и час, представляващ началния час, в местно време; например
'2018-12-04 05:47:00.000'. Процедурата ще се преведе в UTC. Ако се пропусне, ще се събира от най-ранната стойност в таблицата. - @EndTime – Дата и час, представляващ крайния час, отново в местно време; например
'2018-12-06 12:54:00.000'. Ако се пропусне, той ще събере до последната стойност в таблицата.
Примерно изпълнение, за да получите всички данни, събрани за SQLInstanceA между 4 декември в 5:47 ч. и 6 декември в 12:54 ч.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Данните ще трябва да бъдат експортирани в CSV файл. Не се притеснявайте за самите данни; Уверих се, че извеждам резултатите, така че в csv файла да няма идентифицираща информация за вашия сървър, а само дати и показатели.
Ако стартирате заявката в SSMS, можете да щракнете с десния бутон и да експортирате резултатите; тук обаче имате ограничени опции и ще трябва да манипулирате изхода, за да получите формата, очакван от DTU калкулатора. (Чувствайте се свободни да опитате и да ме уведомите, ако намерите начин да направите това.)
Препоръчвам просто да използвате съветника за експортиране, изпечен в SSMS. Щракнете с десния бутон върху базата данни и отидете на Задачи -> Експортиране на данни. За своя източник на данни използвайте „SQL Server Native Client“ и го насочете към вашата база данни SentryOne (или където имате копие на данните, съхранено). За вашата дестинация ще искате да изберете „Плоска цел на файл“. Прегледайте до местоположение, дайте име на файла и запазете файла като CSV.
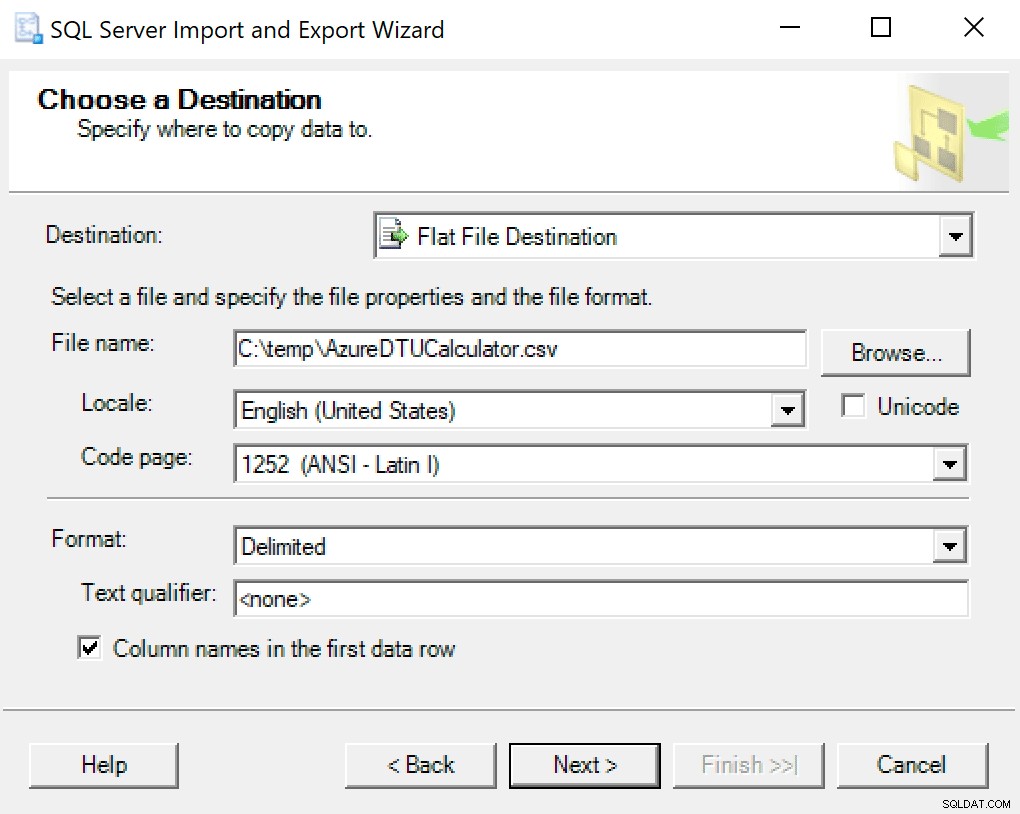
Внимавайте да оставите кодовата страница на мира; някои може да връщат грешки. Знам, че 1252 работи добре. Останалите стойности се оставят по подразбиране.
На следващия екран изберете опцията Напишете заявка, за да посочите данните за прехвърляне .
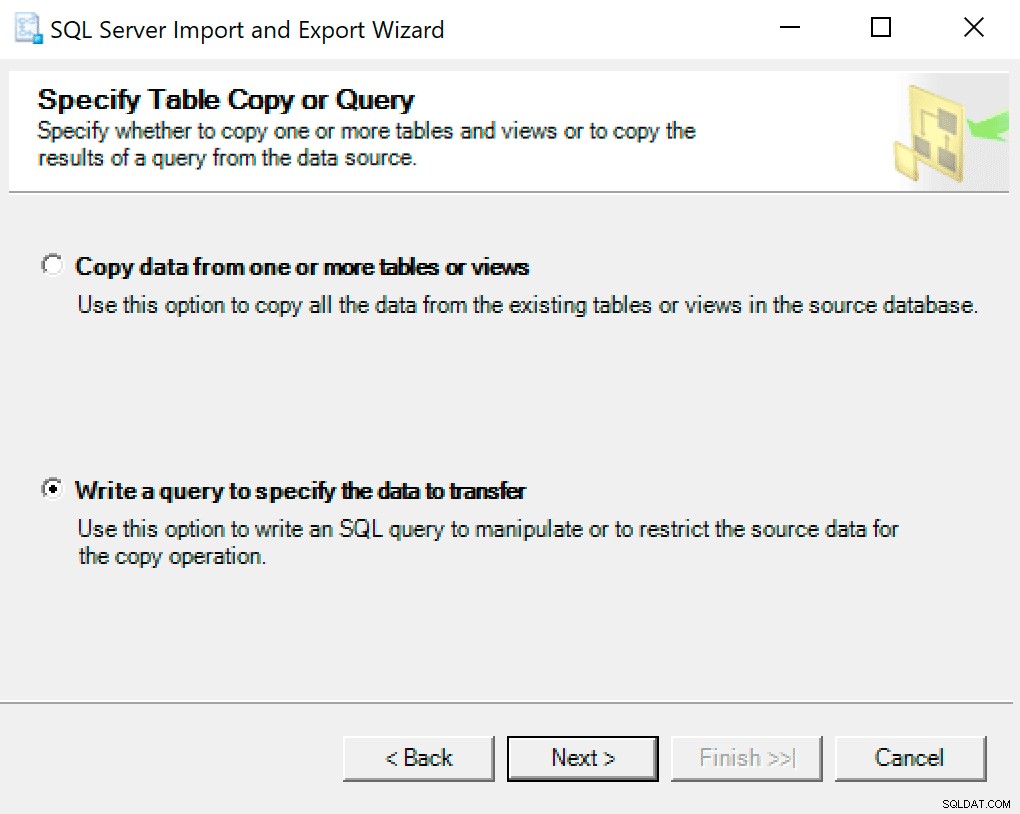
В следващия прозорец копирайте извикването на процедурата с вашите параметри, зададени в него. Натиснете следващия.
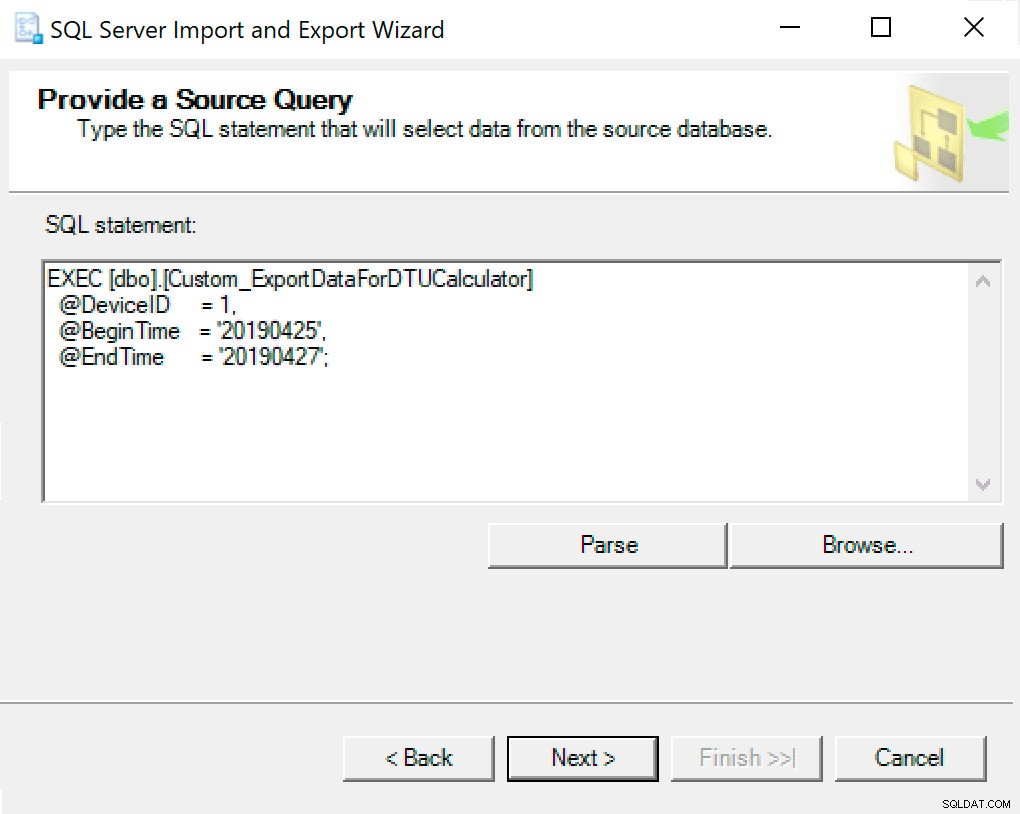
Когато стигнете до Configure Flat File Destination, оставям опциите по подразбиране. Ето екранна снимка, в случай че вашите са различни:
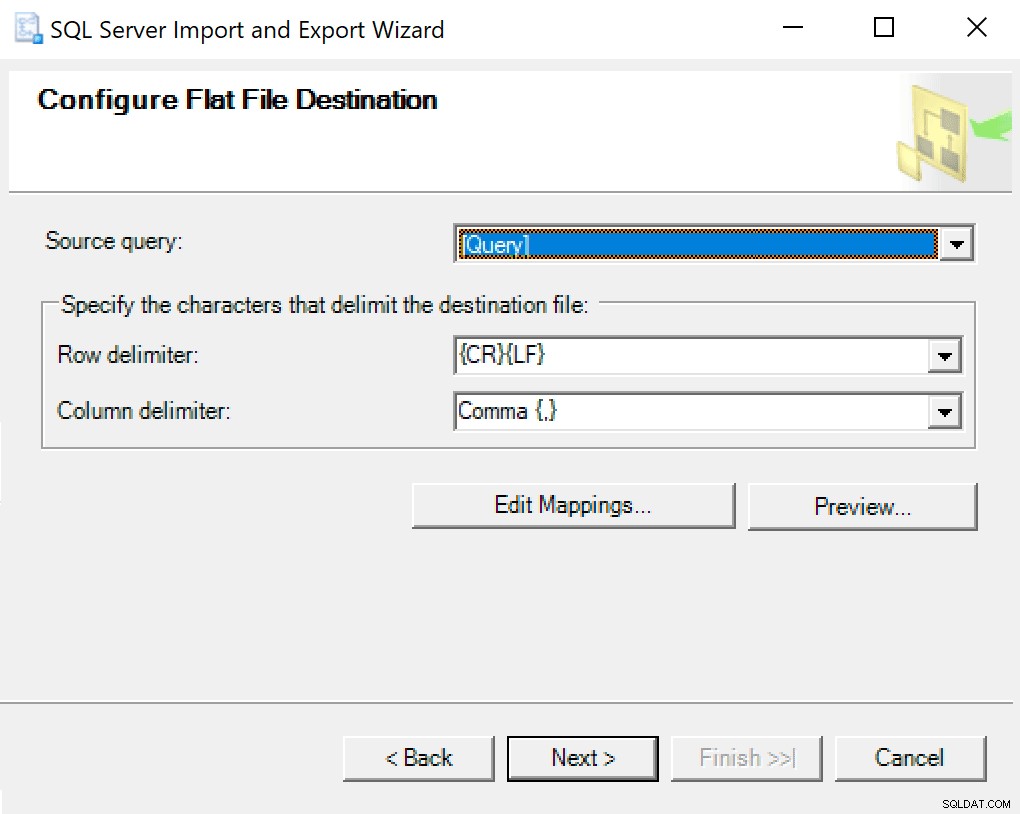
Натиснете следващия и бягайте незабавно. Ще бъде създаден файл, който ще използвате в последната стъпка.
ЗАБЕЛЕЖКА :Можете да създадете SSIS пакет, който да използвате за това и след това да преминете през стойностите на вашите параметри към пакета SSIS, ако ще правите това често. Това би ви попречило да преминавате през съветника всеки път.
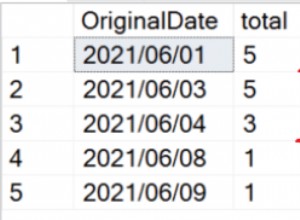
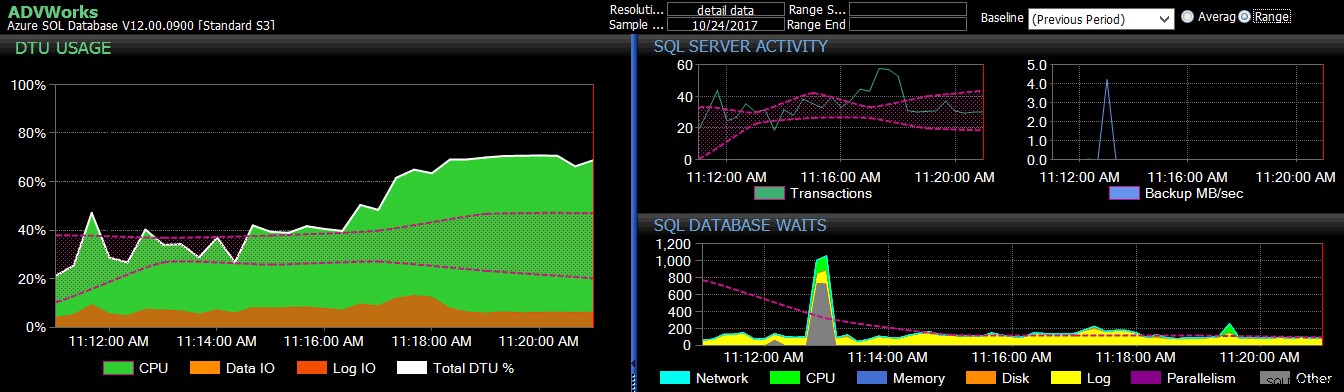
Придвижете се до мястото, където сте запазили файла, и се уверете, че е там. Когато го отворите, трябва да изглежда така:
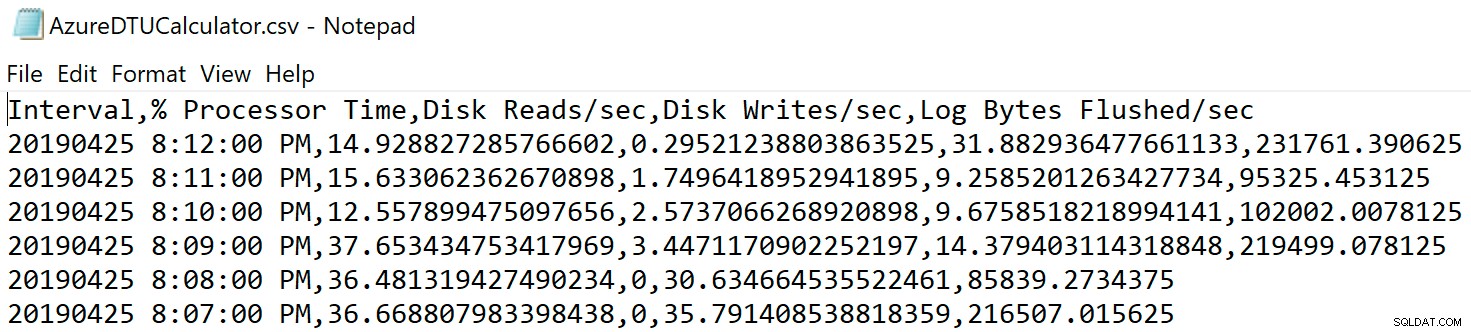
Отворете уеб сайта на DTU калкулатора и превъртете надолу до частта, която гласи „Качете CSV файла и изчислете“. Въведете броя на ядрата, които сървърът има, качете CSV файла и щракнете върху Изчисляване. Ще получите набор от резултати като този (щракнете върху произволно изображение, за да го увеличите):
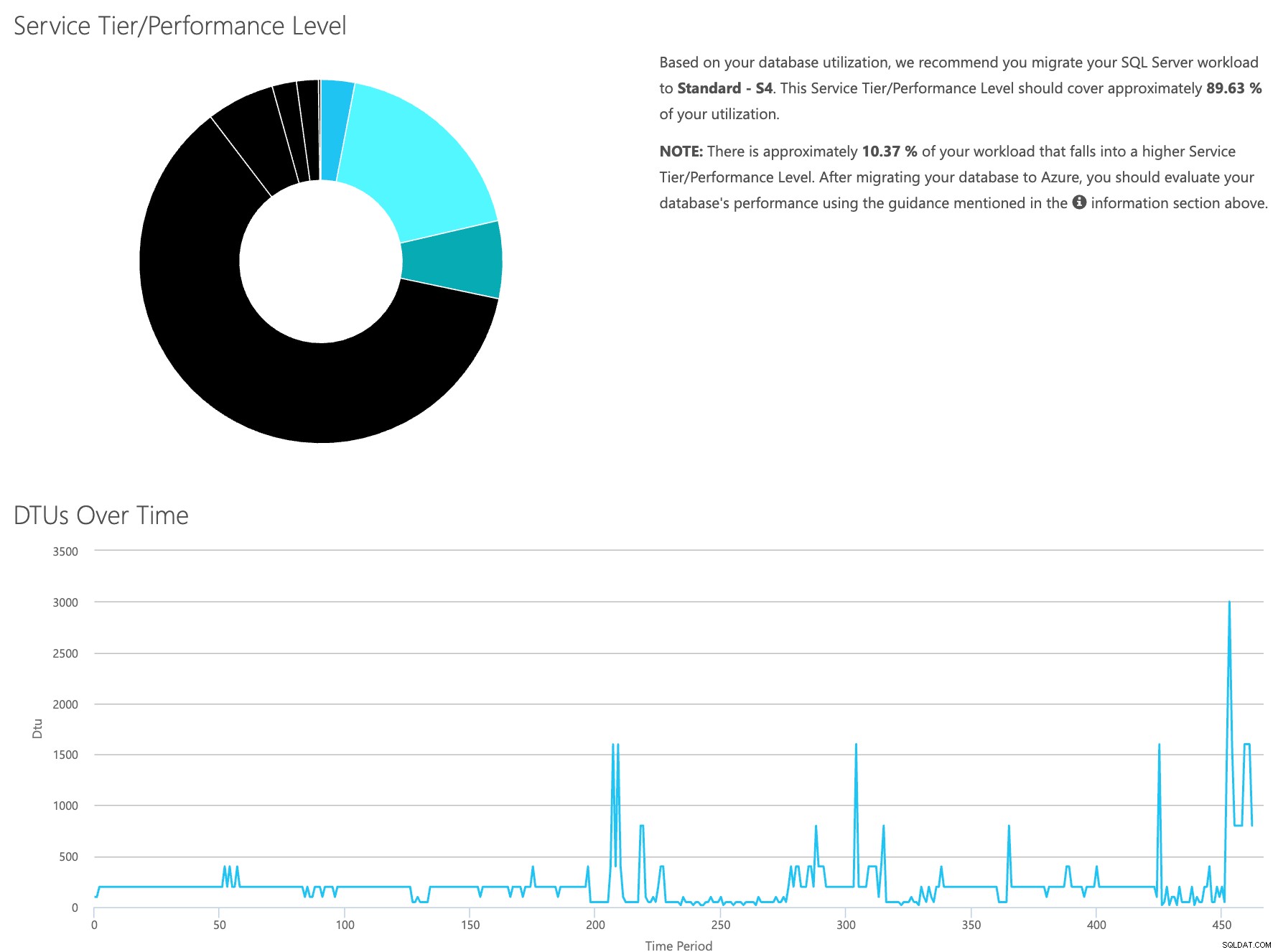
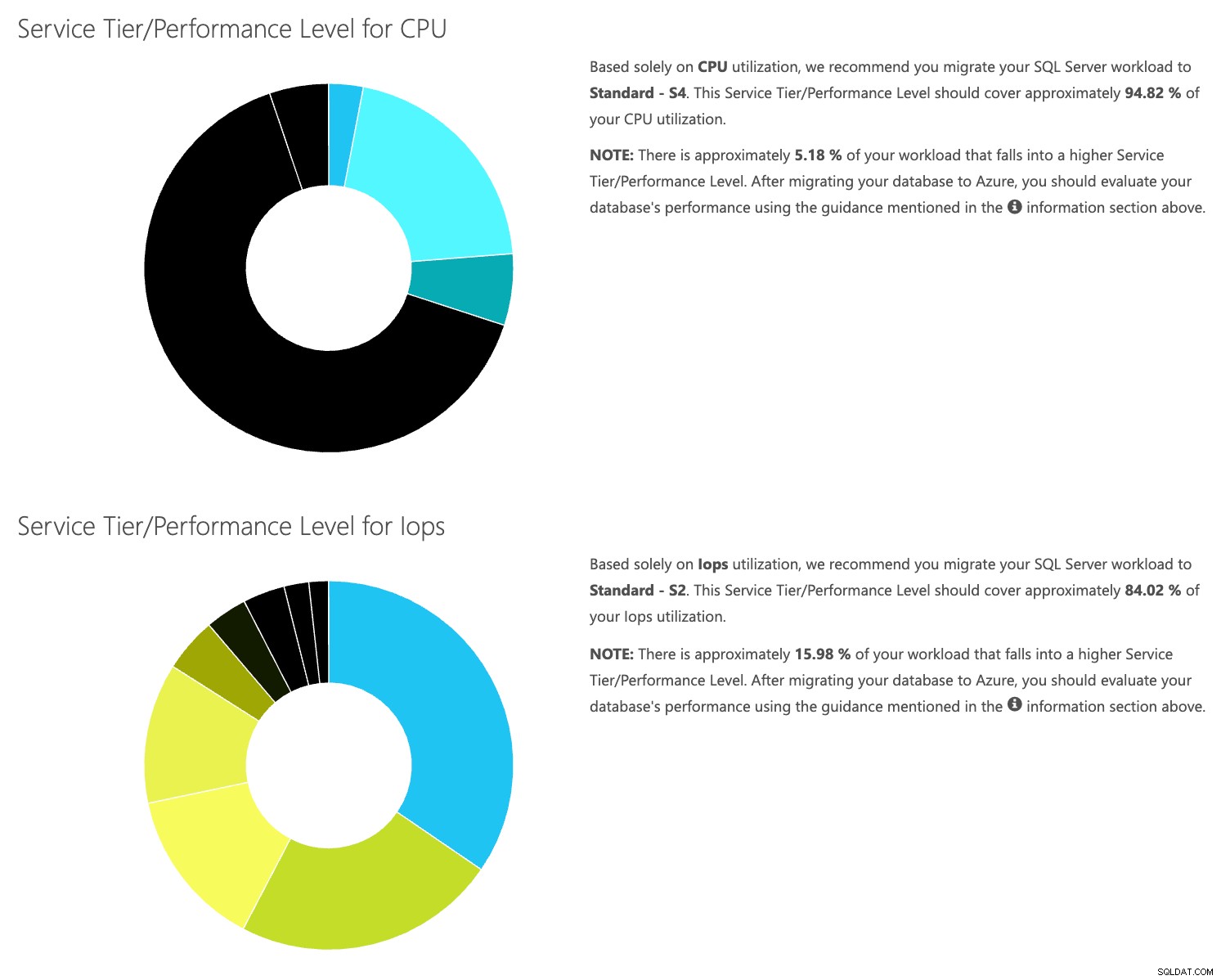
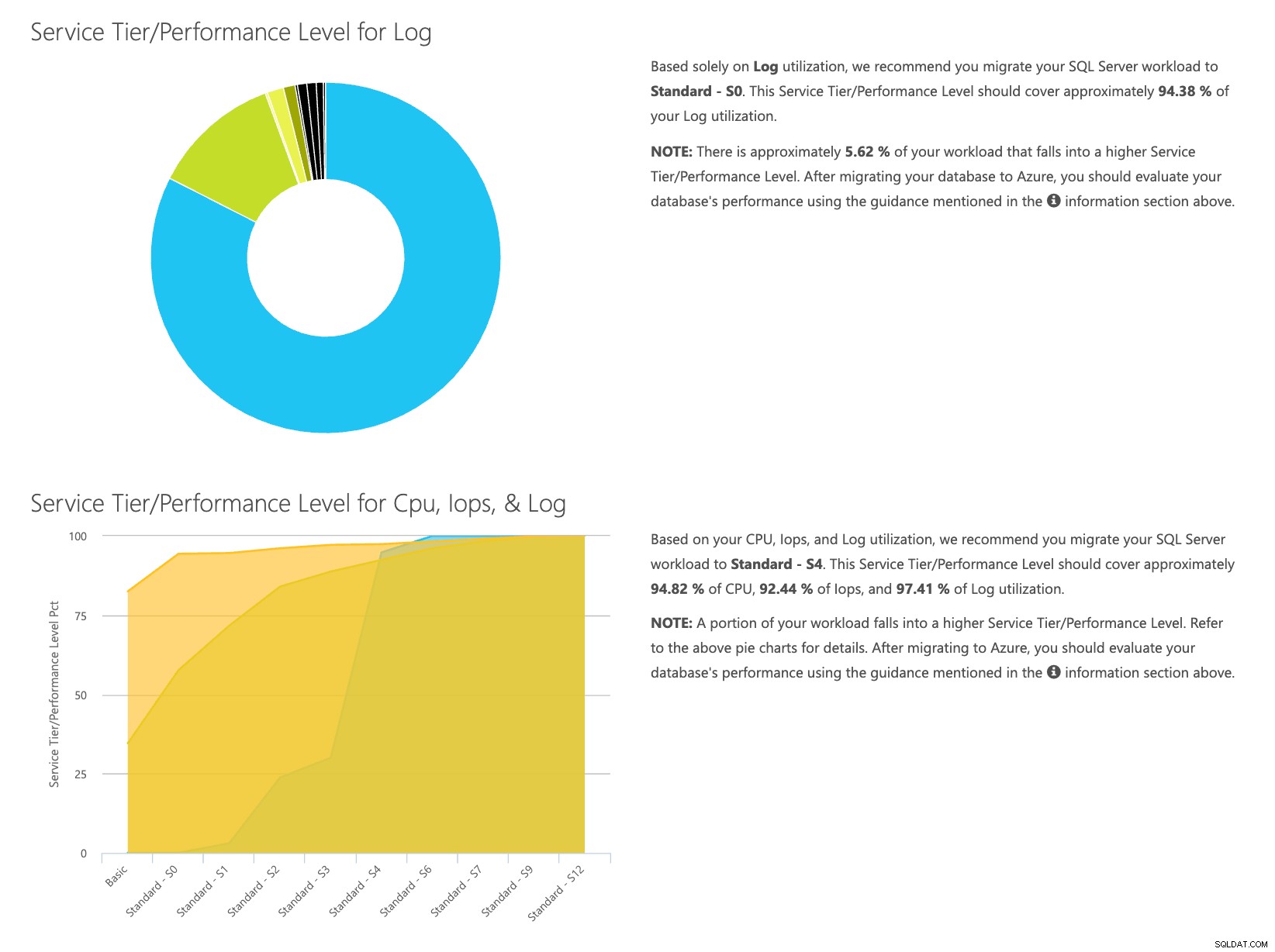
Тъй като данните се съхраняват отделно, можете да анализирате работните натоварвания от различно време и можете да направите това, без да се налага ръчно да стартирате\планирате командната помощна програма\powershell скрипт за всеки сървър, който вече използвате SentryOne за наблюдение.
За да обобщим накратко стъпките, ето какво трябва да направите:
- Активирайте брояча [База данни – регистрационни байтове изчистени/сек] и проверете, че данните се събират
- Копирайте данните от таблиците SentryOne във вашата собствена таблица (и насрочете това, където е уместно).
- Експортирайте данните от нова таблица в правилния формат за DTU калкулатора
- Качете CSV файла в DTU калкулатора
За всеки сървър/екземпляр, който обмисляте да мигрирате към облака и който в момента наблюдавате с SQL Sentry, това е относително безболезнен начин да прецените какъв тип услуга ще ви трябва и колко ще струва това. Все пак ще трябва да го наблюдавате, след като е там горе; за това вижте SentryOne DB Sentry.
За автора
 Дъстин Дорси в момента е Инженер по управление на бази данни за LifePoint Health, в който ръководи екип, отговорен за управлението и инженерните решения в технологии за бази данни за 90 болници. Той работи със и поддържа SQL Server предимно в здравеопазването от 2008 г. в областта на администрацията, архитектурата, разработката и BI капацитет. Той е страстен в намирането на начини за решаване на проблеми, които тормозят ежедневния DBA и обича да споделя това с другите. Той може да бъде намерен да говори на събития в общността на SQL, както и да води блог в DustinDorsey.com.
Дъстин Дорси в момента е Инженер по управление на бази данни за LifePoint Health, в който ръководи екип, отговорен за управлението и инженерните решения в технологии за бази данни за 90 болници. Той работи със и поддържа SQL Server предимно в здравеопазването от 2008 г. в областта на администрацията, архитектурата, разработката и BI капацитет. Той е страстен в намирането на начини за решаване на проблеми, които тормозят ежедневния DBA и обича да споделя това с другите. Той може да бъде намерен да говори на събития в общността на SQL, както и да води блог в DustinDorsey.com.