Миналия месец покрих предизвикателство за специални острови. Задачата беше да се идентифицират периоди на активност за всеки идентификатор на услугата, като се толерира интервал от до въведен брой секунди (@allowedgap ). Предупреждението беше, че решението трябваше да е съвместимо преди 2012 г., така че не можете да използвате функции като LAG и LEAD или да обобщавате функциите на прозореца с рамка. Получих редица много интересни решения, публикувани в коментарите от Тоби Овод-Еверет, Питър Ларсон и Камил Косно. Не забравяйте да прегледате техните решения, тъй като всички те са доста креативни.
Любопитно е, че редица решения работеха по-бавно с препоръчания индекс, отколкото без него. В тази статия предлагам обяснение за това.
Въпреки че всички решения бяха интересни, тук исках да се съсредоточа върху решението на Камил Косно, който е ETL разработчик в Zopa. В своето решение Камил използва много креативна техника, за да имитира LAG и LEAD без LAG и LEAD. Вероятно ще намерите техниката за удобна, ако трябва да извършвате изчисления, подобни на LAG/LEAD, като използвате код, който е съвместим преди 2012 г.
Защо някои решения са по-бързи без препоръчания индекс?
Като напомняне, предложих да използвате следния индекс за подкрепа на решенията на предизвикателството:
СЪЗДАЙТЕ ИНДЕКС idx_sid_ltm_lid НА dbo.EventLog(serviceid, logtime, logid);
Моето решение, съвместимо от преди 2012 г., беше следното:
ДЕКЛАРИРАНЕ @allowedgap КАТО INT =66; -- за секунди С C1 AS( ИЗБЕРЕТЕ logid, serviceid, logtime AS s, -- важно, 's'> 'e', за по-късна поръчка DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION ПО serviceid ORDER BY logtime, logid) КАТО counteach FROM dbo.EventLog),C2 AS( SELECT logid, serviceid, logtime, eventtype, counteach, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) КАТО броене и двете ОТ C1 UNPIVOT(време на регистрация ЗА тип събитие IN (s, e)) AS U),C3 AS( SELECT serviceid, eventtype, logtime, (ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 КАТО grp ОТ C2 CROSS APPLY ( СЛУЧАЙ, КОГАТО eventtype ='s' THEN counteach - (countboth - counteach) WHEN eventtype ='e' THEN (countboth - counteach) - counteach END ) ) КАТО A(countactive) WHERE ( eventtype ='s' И countactive =1) ИЛИ (тип на събитие ='e' И countactive =0))ИЗБЕРЕТЕ serviceid, s КАТО начален час, DATEADD(втора, -@allowedgap, e) КАТО крайно времеFROM C3 PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P;
Фигура 1 показва плана за моето решение с препоръчания индекс.
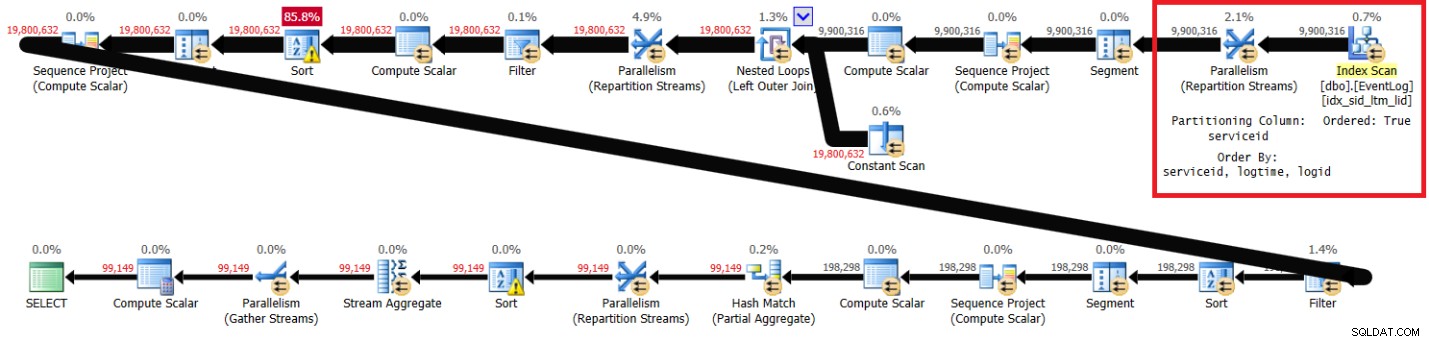 Фигура 1:Планиране на решението на Itzik с препоръчан индекс
Фигура 1:Планиране на решението на Itzik с препоръчан индекс
Забележете, че планът сканира препоръчания индекс в ключов ред (свойството Ordered е True), разделя потоците по serviceid, използвайки обмен, запазващ реда, и след това прилага първоначалното изчисление на номерата на редовете, разчитайки на реда на индекса, без да е необходимо сортиране. Следват статистическите данни за производителността, които получих за изпълнението на тази заявка на моя лаптоп (изминало време, време на процесора и най-голямо изчакване, изразени в секунди):
изтекло:43, CPU:60, логически четения:144 120 , горно изчакване:CXPACKET:166
След това пуснах препоръчания индекс и изпълних отново решението:
ИЗПУСКАНЕ НА ИНДЕКС idx_sid_ltm_lid НА dbo.EventLog;
Получих плана, показан на фигура 2.
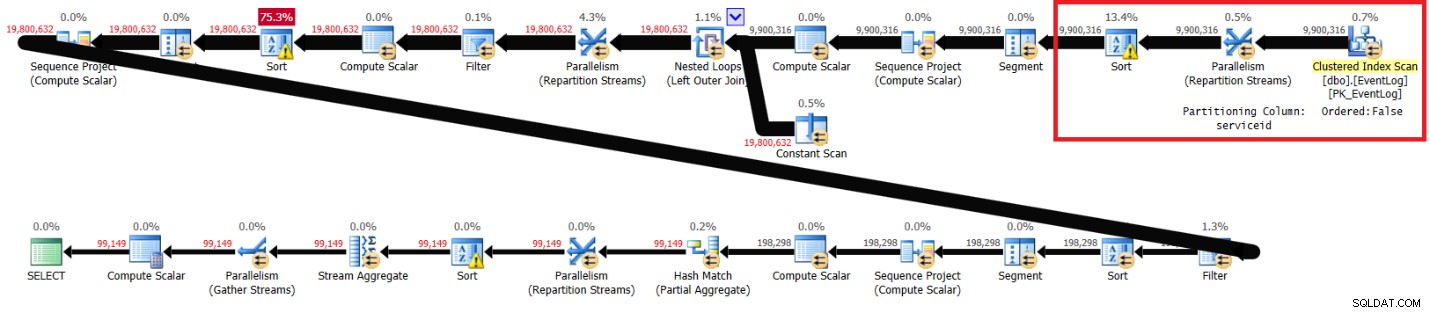 Фигура 2:Планирайте решението на Itzik без препоръчан индекс
Фигура 2:Планирайте решението на Itzik без препоръчан индекс
Маркираните секции в двата плана показват разликата. Планът без препоръчания индекс извършва неподредено сканиране на клъстерирания индекс, разделя потоците по serviceid, използвайки обмен, който не запазва ред, и след това сортира редовете, както се нуждае от функцията на прозореца (по serviceid, logtime, logid). Останалата част от работата изглежда е същата и в двата плана. Бихте си помислили, че планът без препоръчания индекс трябва да е по-бавен, тъй като има допълнителен сорт, който другият план няма. Но ето статистическите данни за производителността, които получих за този план на моя лаптоп:
изтекло:31, CPU:89, логически четения:172 598 , CXPACKET чака:84
Заложено е повече процесорно време, което отчасти се дължи на допълнителното сортиране; има повече замесени I/O, вероятно поради допълнителни разливи на сортиране; обаче изминалото време е с около 30 процента по-бързо. Какво би могло да обясни това? Един от начините да опитате да разберете това е да стартирате заявката в SSMS с активирана опция Live Query Statistics. Когато направих това, най-десният оператор на паралелизъм (потоци на преразпределение) завърши за 6 секунди без препоръчания индекс и за 35 секунди с препоръчания индекс. Ключовата разлика е, че първият получава данните, предварително поръчани от индекс, и е обмен, запазващ реда. Последният получава неподредени данни и не е обмен за запазване на реда. Обмените за запазване на реда обикновено са по-скъпи от тези, които не запазват реда. Освен това, поне в най-дясната част на плана до първото сортиране, първият доставя редовете в същия ред като колоната за разделяне на обмен, така че няма да накарате всички нишки наистина да обработват редовете паралелно. По-късното доставя редовете неподредени, така че получавате всички нишки да обработват редовете наистина паралелно. Можете да видите, че горното изчакване и в двата плана е CXPACKET, но в първия случай времето за изчакване е двойно по-дълго от втория, което ви казва, че обработката на паралелизъм във втория случай е по-оптимална. Може да има някои други фактори, за които не мисля. Ако имате допълнителни идеи, които биха могли да обяснят изненадващата разлика в производителността, моля, споделете.
На моя лаптоп това доведе до изпълнението без препоръчания индекс да е по-бърз от този с препоръчания индекс. И все пак на друга тестова машина беше обратното. В крайна сметка имате допълнителен сорт, с потенциал за разливане.
От любопитство тествах серийно изпълнение (с опция MAXDOP 1) с препоръчания индекс на място и получих следните статистически данни за производителността на моя лаптоп:
изтекло:42, процесор:40, логически показания:143 519
Както можете да видите, времето за изпълнение е подобно на времето за изпълнение на паралелното изпълнение с препоръчания индекс на място. Имам само 4 логически процесора в лаптопа си. Разбира се, вашият пробег може да варира в зависимост от хардуера. Въпросът е, че си струва да тествате различни алтернативи, включително със и без индексиране, което смятате, че трябва да помогне. Резултатите понякога са изненадващи и противоинтуитивни.
Решението на Камил
Бях наистина заинтригуван от решението на Kamil и особено харесах начина, по който той емулира LAG и LEAD с техника, съвместима преди 2012 г.
Ето кода, който реализира първата стъпка в решението:
ИЗБЕРЕТЕ serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) КАТО крайно време, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 КАТО start_timeFROM dbo.EventLog;
Този код генерира следния изход (показва само данни за serviceid 1):
serviceid logtime end_time start_time--------------- -------------------- --------- ---- -------1 2018-09-12 08:00:00 1 01 2018-09-12 08:01:01 2 11 2018-09-12 08:01:59 3 21 2018-09-12 08 :03:00 4 31 2018-09-12 08:05:00 5 41 2018-09-12 08:06:02 6 5...
Тази стъпка изчислява два номера на редове, които са по един за всеки ред, разделени по serviceid и подредени по време на лог. Номерът на текущия ред представлява крайното време (наречете го крайно_време), а номерът на текущия ред минус едно представлява началния час (наречете го начало_време).
Следният код изпълнява втората стъпка от решението:
С RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) КАТО крайно_време, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 КАТО начало_време ОТ dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (начало_време, крайно_време)) AS U;
Тази стъпка генерира следния изход:
serviceid logtime rownum time_type--------- -------------------- ------- ------ -----1 2018-09-12 08:00:00 0 start_time1 2018-09-12 08:00:00 1 end_time1 2018-09-12 08:01:01 1 start_time1 2018-09-12 08:00 :01 2 end_time1 2018-09-12 08:01:59 2 start_time1 2018-09-12 08:01:59 3 end_time1 2018-09-12 08:03:00 3 start_time1 2018-09-09:09 4 end_time1 2018-09-12 08:05:00 4 start_time1 2018-09-12 08:05:00 5 end_time1 2018-09-12 08:06:02 5 start_time1 2018-09-09-16:0 ...
Тази стъпка преобръща всеки ред на два реда, дублирайки всеки запис в дневника – веднъж за тип време начало_време и друг за крайно_време. Както можете да видите, с изключение на минималния и максималния номер на редовете, всеки номер на ред се появява два пъти — веднъж с регистрационния час на текущото събитие (start_time) и друг с времето за регистриране на предишното събитие (end_time).
Следният код изпълнява третата стъпка в решението:
С RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) КАТО крайно_време, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 КАТО начало_време ОТ dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (начало_време, крайно_време)) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P;
Този код генерира следния изход:
serviceid rownum start_time end_time--------------- -------------------- ------------ --------------- ---------------------------1 0 12.09.2018 08 :00:00 NULL1 1 2018-09-12 08:01:01 2018-09-12 08:00:001 2 2018-09-12 08:01:59 2018-09-12 08:31:2011 09-12 08:03:00 2018-09-12 08:01:591 4 2018-09-12 08:05:00 2018-09-12 08:03:001 5 2018-09-12:02:08 2018-09-12 08:05:001 6 NULL 2018-09-12 08:06:02...
Тази стъпка завърта данните, групира двойки редове със същия номер на ред и връща една колона за текущото време на регистър на събития (start_time) и друга за времето на предишния регистър на събития (end_time). Тази част ефективно емулира функция LAG.
Следният код изпълнява четвъртата стъпка в решението:
ДЕКЛАРИРАНЕ @allowedgap КАТО INT =66; С RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) КАТО крайно_време, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 КАТО начало_време ОТ dbo.EventLog)SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 КАТО end_time_grpFROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT MAX(logtime) FOR time_type IN(start_time, end_time)) AS PWHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap;
Този код генерира следния изход:
serviceid rownum start_time end_time start_time_grp end_time_grp---------------- -------------------- ---- ---------------- --------------- -------------1 0 2018-09- 12 08:00:00 NULL 1 01 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 11 6 NULL 2018-09-12 08:06:02 <3 2... /предварително>Тази стъпка филтрира двойки, при които разликата между предишното крайно време и текущото начално време е по-голяма от позволената празнина, и редове само с едно събитие. Сега трябва да свържете началния час на всеки текущ ред с крайния час на следващия ред. Това изисква изчисление, подобно на LEAD. За да постигне това, кодът отново създава номера на редове, които са единични, само че този път номерът на текущия ред представлява началния час (start_time_grp), а номерът на текущия ред минус едно представлява крайния час (end_time_grp).
Както и преди, следващата стъпка (номер 5) е да премахнете завъртането на редовете. Ето кода, който изпълнява тази стъпка:
ДЕКЛАРИРАНЕ @allowedgap КАТО INT =66; С RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Обхвати като ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 КАТО end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start)_time ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT *FROM диапазони UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U;Изход:
serviceid rownum start_time end_time grp grp_type--------- ------- -------------------- ---- ---------------- ---- ---------------1 0 2018-09-12 08:00:00 NULL 0 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp1 0 2018-09-12 08:00:00 NULL 1 start_time_grp1 6 NULL 2018:2018-08 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp1 6 NULL 2018-09-12 08:06:02 3 start_time_grp...Както можете да видите, колоната grp е уникална за всеки остров в рамките на идентификатора на услугата.
Стъпка 6 е последната стъпка в решението. Ето кода, който изпълнява тази стъпка, който също е пълният код на решението:
ДЕКЛАРИРАНЕ @allowedgap КАТО INT =66; С RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Обхвати като ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 КАТО end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start)_time ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT serviceid, MIN(start_time) AS start_time , MAX(end_time) AS end_timeFROM диапазони UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) КАТО UGROUP BY serviceid, grpHAVING (MIN(start_time) НЕ Е NULL И MAX(end_time) НЕ Е NULL);Тази стъпка генерира следния изход:
serviceid start_time end_time---------- --------------------------- ------ ---------------------1 2018-09-12 08:00:00 2018-09-12 08:03:001 2018-09-12 08:05 :00 2018-09-12 08:06:02...Тази стъпка групира редовете по serviceid и grp, филтрира само съответните групи и връща минималното начало_време като начало на острова и максималното крайно време като края на острова.
Фигура 3 показва плана, който получих за това решение с препоръчания индекс:
СЪЗДАЙТЕ ИНДЕКС idx_sid_ltm_lid НА dbo.EventLog(serviceid, logtime, logid);План с препоръчан индекс на фигура 3.
Фигура 3:План за решението на Kamil с препоръчан индекс
Ето статистическите данни за производителността, които получих за това изпълнение на моя лаптоп:
изтекло:44, CPU:66, логически четения:72979, горно изчакване:CXPACKET:148След това пуснах препоръчания индекс и изпълних отново решението:
ИЗПУСКАНЕ НА ИНДЕКС idx_sid_ltm_lid НА dbo.EventLog;Получих плана, показан на фигура 4 за изпълнение без препоръчания индекс.
Фигура 4:План за решението на Kamil без препоръчан индекс
Ето статистическите данни за производителността, които получих за това изпълнение:
изтекло:30, CPU:85, логически показания:94813, горно изчакване:CXPACKET:70Времената на изпълнение, времето на процесора и времето за изчакване на CXPACKET са много подобни на моето решение, въпреки че логическите показания са по-ниски. Решението на Kamil също работи по-бързо на моя лаптоп без препоръчания индекс и изглежда, че се дължи на подобни причини.
Заключение
Аномалиите са хубаво нещо. Те ви правят любопитни и ви карат да отидете и да проучите първопричината за проблема и в резултат на това да научите нови неща. Интересно е да се види, че някои заявки на определени машини се изпълняват по-бързо без препоръчаното индексиране.
Благодаря отново на Тоби, Питър и Камил за вашите решения. В тази статия разгледах решението на Камил, с неговата творческа техника за емулиция на LAG и LEAD с номера на редове, развъртане и завъртане. Ще намерите тази техника за полезна, когато имате нужда от изчисления, подобни на LAG и LEAD, които трябва да се поддържат в среди преди 2012 г.



