През февруари написах публикация в блога за автоматичната корекция на плана в SQL Server и в тази публикация искам да говоря за автоматичното управление на индексите, вторият компонент на функцията за автоматична настройка. Автоматичното управление на индексите е достъпно само в базата данни на Azure SQL и в момента не е в плана да бъде налично в следващата версия на SQL Server на място. Тази опция е активирана независимо от автоматичната корекция на плана и както подсказва името, тя ще управлява индекси във вашата база данни. По-конкретно, той може да създава индекси, които липсват, и може да премахва индекси, които не се използват, и тези, които са дублирани. Нека да разгледаме как се случва това.
Под завивките
Автоматичното управление на индексите разчита на данни, за да вземе своето решение. За потенциално създаване на индекс той използва информацията за липсващия индекс DMV и го проследява във времето и комбинира тези данни с вътрешен модел, за да определи ползата от индекса. Той също така използва Query Store, за да определи дали индексът предоставя полза, така че трябва да бъде активиран за базата данни, точно както при автоматичната корекция на плана. По отношение на отпадането на индекси се използват данни от DMV за използване на индекса (sys.dm_db_index_usage_stats), както и метаданни на индекса (например брой колони, типове данни за колони).
Активиране на автоматичното управление на индексите
Както споменахме, Query Store трябва да е активиран за базата данни. Това може да се направи в SSMS, с T-SQL и с REST API за Azure SQL база данни. Имайте предвид, че хранилището на заявки е активирано по подразбиране за бази данни в Azure и е от четвъртото тримесечие на 2016 г.
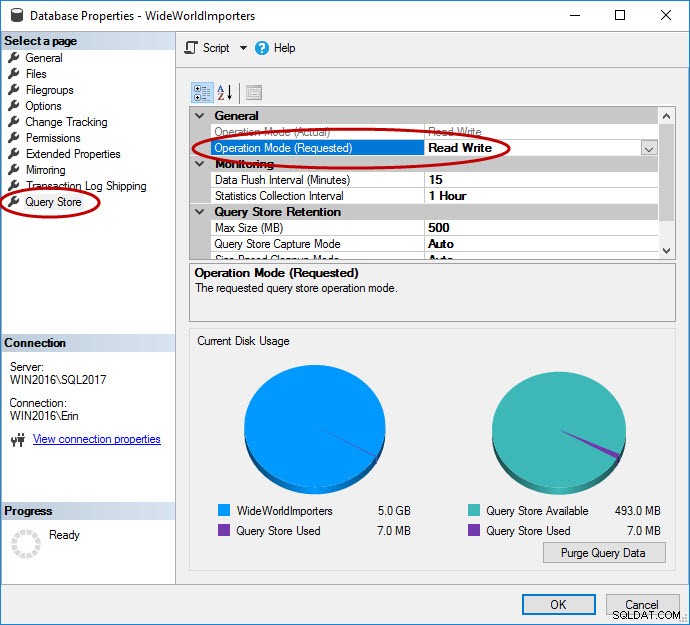
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
След като Query Store е активиран, можете да използвате Azure Portal, T-SQL или EST API, за да активирате автоматичното управление на индексите в Azure SQL база данни (C# и PowerShell са в процес на работа).
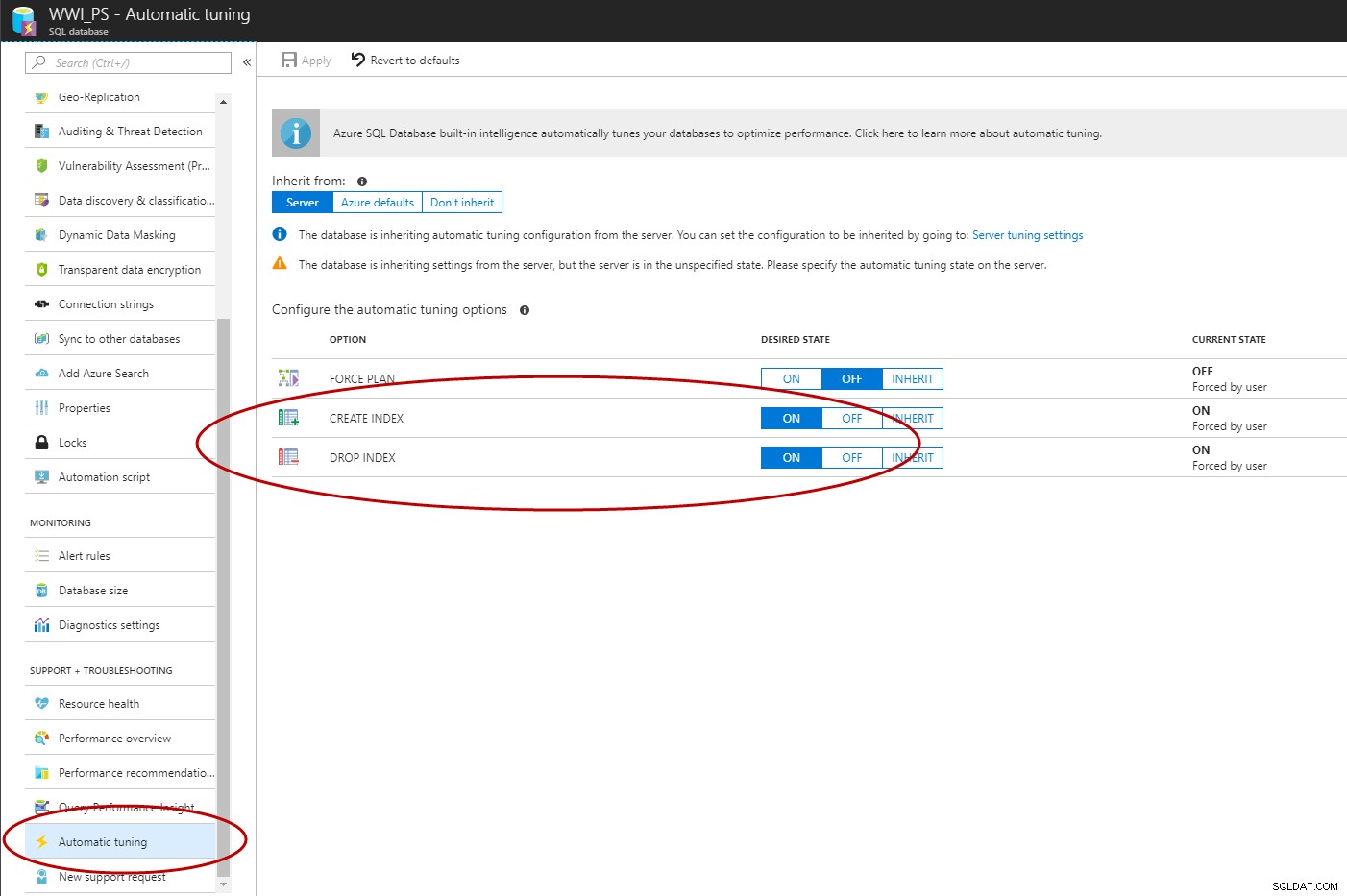
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON); GO
Автоматичното управление на индекси ще бъде активирано по подразбиране за нови бази данни в Azure (https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/) в близко бъдеще. Започвайки през януари 2018 г., Microsoft стартира внедряването, за да активира автоматична настройка за Azure SQL бази данни, които все още не са го активирали, с известия, изпратени до администраторите, така че опцията може да бъде деактивирана, ако желаете. Този процес отнема няколко месеца, така че ако все още не сте получили известие, не се паникьосвайте!
Как работи
За създаване на индекс понастоящем има непрекъснат прозорец от седем (7) дни*, през който данните се проследяват, и моделът се нуждае най-малко от девет (9) часа* данни, за да препоръча индекс, заедно с 12 часа* данни в Query Store, които ще бъдат използвани като базова линия. Ако се установи, че даден индекс ще осигури значителна полза, тогава SQL Server ще създаде индекса.
*Тези стойности могат да се променят в бъдеще, докато моделът се развива.
Забележка:в момента моделът обединява препоръките. Тоест, ако се препоръчват множество индекси за таблица, но може да се създаде един индекс, който да покрива всички опции, той може да създаде този индекс в момента. Моделът обаче в момента не е достатъчно интелигентен, за да обедини препоръчан индекс с такъв, който вече съществува.
След като се създаде индекс, SQL Server проверява дали предоставя полза, като използва Query Store (по този начин трябва да бъде активиран за базата данни). Той следи производителността на всяка заявка, която използва новия индекс и сравнява CPU на заявката преди добавянето на индекса и при използване на индекса. Ако има регресия в производителността на заявката в резултат на индекса, тогава той ще върне (отпусне) индекса. SQL Server следи производителността на заявките до три (3) дни или докато не бъде анализирано 100% от съответното работно натоварване. След този период от време, ако индексът не показва никакви признаци на регресия, той няма да прави преглед на ефективността за него отново.
Разберете, че ако автоматичното управление на индекси създаде индекс, а след това два месеца по-късно вашето работно натоварване се промени и той ще се възползва от същия индекс, автоматично създаден по-рано, но с една допълнителна колона, тогава SQL Server в момента ще създаде нов индекс. Понастоящем няма логика за промяна на съществуващ автоматично създаден индекс, но тази функционалност е в пътната карта за функцията.
По отношение на изтриването на индекси, ако индексът няма търсене или сканиране в продължение на 90 дни, но има разходи за поддръжка (което означава, че има вмъквания, актуализации или изтривания), тогава той ще бъде отхвърлен. Дублиращи се индекси също ще бъдат премахнати, като се приеме, че са точен дубликат (и схемата се използва, за да се определи дали индексите са абсолютно еднакви). Ако има дублиращи се индекси по отношение на ключови колони и включени колони (ако е уместно), но един или повече от тях имат филтър, тогава те не са наистина дублирани и няма да бъдат отхвърлени индекси.
За справка, има два пъти повече препоръки DROP INDEX в Azure SQL база данни, отколкото препоръки CREATE INDEX.
Когато активирате опцията DROP INDEX, SQL Server ще изпусне създадените от потребителя индекси. Когато активирате опцията CREATE INDEX, SQL Server има способността да създава индекси автоматично и може също да махне тези индекси (но няма да изпусне създадени от потребителя индекси). И накрая, индексите се създават и отпадат по време на непиково натоварване, както е определено от DTU. Ако работното натоварване е над 80% DTU, тогава SQL Server ще изчака да създаде или изпусне индекса, докато натоварването на системата намалее.
Наистина ли ще позволя на SQL Server да има контрол?
Може би. Моята препоръка за тази функция първоначално изисква подход „доверете се, но проверявайте“.
Както при автоматичната корекция на плана, автоматичното управление на индексите е разработено със значително количество данни, уловени от почти два милиона Azure SQL бази данни. Функцията за автоматично управление на индекси е налична в Azure SQL база данни от Q1 на 2016 г. като част от Index Advisor.
Алгоритмите, използвани от функцията, се развиват и продължават да се развиват с течение на времето, тъй като повече бази данни го използват и повече данни се улавят и анализират. В момента обаче има някои ограничения.
- Препоръките за индекси не се оценяват спрямо съществуващи индекси, поради което консолидирането на индекси между нови и съществуващи индекси в момента не е налично.
- Ако индексът би осигурил предимства за SELECT, режийните разходи за модификации, дължащи се на INSERT, UPDATE и DELETE, не са известни преди създаването. SQL Server наблюдава тези допълнителни разходи по време на процеса на проверка, след като индексът е внедрен.
Има предимства за автоматичното управление на индексите, които си струва да посочите:
- За всеки, който трябва да управлява база данни на SQL Server, но не е DBA, препоръките за индекси могат да бъдат изключително полезни.
- Препоръките за индекси се записват в sys.dm_db_tuning_recommendations DMV, дори ако опциите CREATE и DROP не са активирани. Ето защо, ако не сте сигурни относно промените, които SQL Server може да направи, можете да прегледате какво е записано в DMV и след това да вземете решение да приложите ръчно препоръката.
Забележка:Ако ръчно приложите препоръката, SQL Server не извършва никаква проверка. Ако приложите препоръката чрез портала (с помощта на бутона Прилагане) или REST API, тогава тя ще бъде изпълнена, сякаш е автоматично действие и ще се извърши валидиране (и индексът може да бъде автоматично върнат, ако има регресия).
- Функцията продължава да се подобрява. Както казах преди, Microsoft не се опитва да кодира DBA или разработчиците без работа, а се опитва да се справи с ниско висящите плодове, така че да имате повече време за задачи и проекти, които не могат да бъдат интелигентно автоматизирани.
Резюме
Ако не сте готови да прехвърлите юздите на управлението на индекси, разбирам. Но ако имате минимум база данни на Azure SQL, трябва редовно да проверявате sys.dm_db_tuning_recommendations DMV, за да видите какво препоръчва SQL Server и да ги сравнявате с данните, които вие или инструментът за наблюдение на трета страна може да улавя за използването на индекси. В крайна сметка, кога за последен път направихте пълен и задълбочен преглед на вашите индекси, за да разберете какво липсва, какво наистина се използва и какво просто генерира допълнителни разходи в базата данни?