Важна част от настройката на заявката е разбирането на алгоритмите, които са на разположение на оптимизатора за обработка на различни конструкции на заявка, например филтриране, присъединяване, групиране и агрегиране и как те се мащабират. Тези знания ви помагат да подготвите оптимална физическа среда за вашите заявки, като например създаване на правилните индекси. Той също така ви помага интуитивно да усетите кой алгоритъм трябва да очаквате да видите в плана при определен набор от обстоятелства, въз основа на вашето запознаване с праговете, при които оптимизаторът трябва да превключва от един алгоритъм към друг. След това, когато настройвате лошо представящи се заявки, можете по-лесно да забележите области в плана на заявката, където оптимизаторът може да е направил неоптимален избор, например поради неточни оценки за мощността, и да предприемете действия, за да ги коригирате.
Друга важна част от настройката на заявката е мисленето извън кутията - извън алгоритмите, които са достъпни за оптимизатора, когато използва очевидните инструменти. Бъди креативен. Да речем, че имате заявка, която се представя лошо, въпреки че сте подредили оптималната физическа среда. За конструкциите на заявката, които сте използвали, наличните за оптимизатора алгоритми са x, y и z и оптимизаторът е избрал най-доброто, което е могъл при дадените обстоятелства. Все пак заявката се представя лошо. Можете ли да си представите теоретичен план с алгоритъм, който може да даде много по-ефективна заявка? Ако можете да си го представите, има вероятност да успеете да го постигнете с известно пренаписване на заявка, може би с по-малко очевидни конструкции на заявка за задачата.
В тази серия от статии се фокусирам върху групирането и агрегирането на данни. Ще започна с преглед на алгоритмите, които са достъпни за оптимизатора при използване на групирани заявки. След това ще опиша сценарии, при които нито един от съществуващите алгоритми не се справя добре и ще покажа пренаписвания на заявки, които водят до отлична производителност и мащабиране.
Бих искал да благодаря на Крейг Фридман, Василис Пападимос и Джо Сак, членове на пресечната точка на набора от най-умни хора на планетата и набора от разработчици на SQL Server, за отговорите на въпросите ми относно оптимизацията на заявките!
За примерни данни ще използвам база данни, наречена PerformanceV3. Можете да изтеглите скрипт за създаване и попълване на базата данни от тук. Ще използвам таблица, наречена dbo.Orders, която е попълнена с 1 000 000 реда. Тази таблица има няколко индекса, които не са необходими и могат да попречат на моите примери, така че изпълнете следния код, за да премахнете тези ненужни индекси:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Единствените два индекса, останали в тази таблица, са клъстериран индекс, наречен idx_cl_od в колоната за дата на поръчка, и неклъстериран уникален индекс, наречен PK_Orders в колоната с идентификатор на поръчката, налагащ ограничението на първичния ключ.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Съществуващи алгоритми
SQL Server поддържа два основни алгоритма за агрегиране на данни:Stream Aggregate и Hash Aggregate. При групирани заявки алгоритъмът на Stream Aggregate изисква данните да бъдат подредени по групираните колони, така че трябва да правите разлика между два случая. Единият е предварително поръчан поток Aggregate, например, когато данните се получават предварително поръчани от индекс. Друг е непредварително подреден Stream Aggregate, където се изисква допълнителна стъпка за изрично сортиране на входа. Тези два случая мащабират много различно, така че можете да ги разглеждате като два различни алгоритма.
Алгоритъмът Hash Aggregate организира групите и техните агрегати в хеш таблица. Не е необходимо въвеждането да бъде поръчано.
При достатъчно данни оптимизаторът обмисля паралелизиране на работата, като приложи това, което е известно като локално-глобален агрегат. В такъв случай входът се разделя на множество нишки и всяка нишка прилага един от гореспоменатите алгоритми за локално агрегиране на подмножеството си от редове. След това глобалният агрегат използва един от гореспоменатите алгоритми, за да обобщи резултатите от локалните агрегати.
В тази статия се фокусирам върху предварително поръчания алгоритъм Stream Aggregate и неговото мащабиране. В бъдещи части от тази серия ще разгледам други алгоритми и ще опиша праговете, при които оптимизаторът превключва от един към друг и кога трябва да помислите за пренаписване на заявка.
Предварително поръчан агрегат за поток
Като се има предвид групирана заявка с непразен набор за групиране (наборът от изрази, по които групирате), алгоритъмът на Stream Aggregate изисква входните редове да бъдат подредени според изразите, образуващи групиращия набор. Когато алгоритъмът обработва първия ред в групата, той инициализира член, който държи междинната агрегатна стойност, със съответната стойност (напр. стойността на първия ред за MAX агрегат). Когато обработва непърви ред в групата, той присвоява на този член резултат от изчисление, включващо междинната обобщена стойност и стойността на новия ред (напр. максимумът между междинната обобщена стойност и новата стойност). Веднага щом някой от членовете на групата за групиране промени стойността си или входът бъде изразходван, текущата обобщена стойност се счита за краен резултат за последната група.
Един от начините данните да бъдат подредени, както е необходимо на алгоритъма Stream Aggregate, е да ги получите предварително подредени от индекс. Трябва индексът да бъде дефиниран с колоните на групиращия набор като ключове – в произволен ред между тях. Вие също искате индексът да покрива. Например, помислете за следната заявка (ще я наречем Заявка 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Оптималният индекс на rowstore за поддръжка на тази заявка би бил този, дефиниран с shipperid като водеща ключова колона и orderdate или като включена колона, или като втора ключова колона:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
С този индекс на място получавате прогнозния план, показан на фигура 1 (с помощта на SentryOne Plan Explorer).

Фигура 1:План за заявка 1
Забележете, че операторът Index Scan има свойство Ordered:True, което означава, че е необходимо да достави редовете, подредени от ключа на индекса. След това операторът Stream Aggregate поглъща редовете, подредени според нуждите му. Що се отнася до това как се изчисляват разходите на оператора; преди да стигнем до това, първо кратък предговор...
Както може би вече знаете, когато SQL Server оптимизира заявка, той оценява множество кандидат планове и в крайна сметка избира този с най-ниска прогнозна цена. Прогнозната цена на плана е сумата от прогнозните разходи на всички оператори. От своя страна прогнозната цена на всеки оператор е сумата от прогнозните разходи за вход/изход и прогнозната цена на процесора. Разходната единица е безсмислена сама по себе си. Уместността му е в сравнението, което оптимизаторът прави между кандидат планове. Тоест формулите за изчисляване на разходите са проектирани с цел между плановете на кандидатите, този с най-ниска цена (да се надяваме) да представлява този, който ще завърши по-бързо. Ужасно сложна задача за точно изпълнение!
Колкото повече формулите за изчисляване на разходите отчитат адекватно факторите, които наистина влияят върху производителността и мащабирането на алгоритъма, толкова по-точни са те и толкова по-вероятно е при точни оценки за мощността, оптимизаторът да избере оптималния план. Във всеки случай, ако искате да разберете защо оптимизаторът избира един алгоритъм срещу друг, трябва да разберете две основни неща:едното е как работят и мащабират алгоритмите, а другото е моделът на разходите на SQL Server.
И така, обратно към плана на фигура 1; нека се опитаме да разберем как се изчисляват разходите. Като правило Microsoft няма да разкрива вътрешните формули за изчисляване на разходите, които използват. Когато бях дете, бях очарован да разглобявам нещата. Часовници, радиостанции, касети (да, аз съм толкова стар), каквото и да е. Исках да знам как са направени нещата. По подобен начин виждам стойност в обратното проектиране на формулите, тъй като ако успея да предскажа цената разумно точно, това вероятно означава, че разбирам добре алгоритъма. По време на процеса можете да научите много.
Нашата заявка поглъща 1 000 000 реда. Дори и с този брой редове, цената на I/O изглежда е незначителна в сравнение с цената на процесора, така че вероятно е безопасно да го игнорирате.
Що се отнася до цената на процесора, вие искате да опитате и да разберете кои фактори го влияят и по какъв начин. Теоретично може да има редица фактори:брой входни редове, брой групи, мощност на групиращия набор, тип данни и размер на членовете на групиращия набор. Така че, за да опитате да измерите ефекта на някой от тези фактори, искате да сравните прогнозните разходи за две заявки, които се различават само по фактора, който искате да измерите. Например, за да измерите влиянието на броя на редовете върху цената, имайте две заявки с различен брой входни редове, но с всички други аспекти едни и същи (брой групи, мощност на набора за групиране и т.н.). Освен това е важно да се уверите, че прогнозните числа, а не действителните, са желаните, тъй като оптимизаторът разчита на прогнозните числа, за да изчисли разходите.
Когато правите подобни сравнения, е добре да имате техники, които ви позволяват да контролирате напълно приблизителните числа. Например, прост начин за контролиране на приблизителния брой входни редове е да поискате израз на таблица, който се основава на ТОП заявка, и да приложите агрегатната функция във външната заявка. Ако се притеснявате, че поради използването на ТОП оператор оптимизаторът ще приложи цели на редове и че те ще доведат до коригиране на първоначалните разходи, това се отнася само за оператори, които се появяват в плана под оператора Топ (към вдясно), а не отгоре (вляво). Операторът Stream Aggregate естествено се появява над оператора Top в плана, тъй като поглъща филтрираните редове.
Що се отнася до контролирането на прогнозния брой изходни групи, можете да го направите, като използвате израза за групиране
За да сте сигурни, че получавате алгоритъма Stream Aggregate и сериен план, можете да принудите това със съветите на заявката:OPTION(ORDER GROUP, MAXDOP 1).
Също така искате да разберете дали има някакви начални разходи за оператора, за да можете да ги вземете предвид във вашата формула за обратно проектиране.
Нека започнем, като разберем начина, по който броят на входните редове влияе върху прогнозната цена на процесора на оператора. Ясно е, че този фактор трябва да е от значение за разходите на оператора. Освен това бихте очаквали цената на ред да бъде постоянна. Ето няколко заявки за сравнение, които се различават само по приблизителния брой входни редове (наречете ги съответно Заявка 2 и Заявка 3):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Фигура 2 съдържа съответните части от прогнозните планове за тези заявки:

Фигура 2:Планове за заявка 2 и заявка 3
Ако приемем, че цената на ред е постоянна, можете да я изчислите като разликата между разходите на оператора, разделена на разликата между въведените от оператора мощности:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
За да се уверите, че номерът, който получавате, наистина е постоянен и правилен, можете да опитате да предвидите прогнозните разходи в заявки с друг брой входни редове. Например, прогнозираната цена с 500 000 реда за въвеждане е:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Използвайте следната заявка, за да проверите дали вашата прогноза е точна (наречете я Заявка 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Съответната част от плана за тази заявка е показана на Фигура 3.
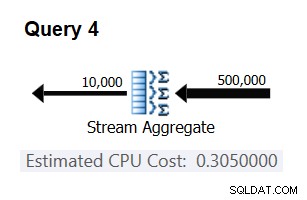
Фигура 3:План за заявка 4
Бинго. Естествено, добра идея е да проверите множество допълнителни входни мощности. С всички тези, които проверих, тезата, че има постоянна цена на входен ред от 0,0000006, беше вярна.
След това нека се опитаме да разберем начина, по който прогнозният брой групи влияе върху цената на процесора на оператора. Очаквате да е необходима известна работа на процесора за обработка на всяка група и също така е разумно да се очаква тя да бъде постоянна за група. За да тествате тази теза и да изчислите цената на група, можете да използвате следните две заявки, които се различават само по броя на групите резултати (наречете ги съответно Заявка 5 и Заявка 6):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
Съответните части от прогнозните планове за заявка са показани на Фигура 4.
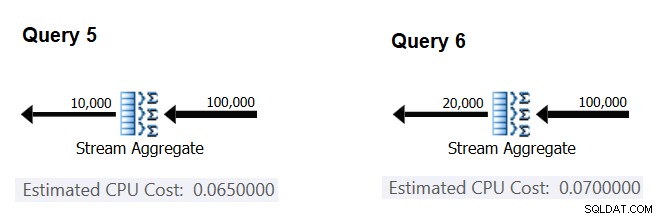
Фигура 4:Планове за заявка 5 и заявка 6
Подобно на начина, по който сте изчислили фиксираната цена на входен ред, можете да изчислите фиксираната цена за изходна група като разликата между разходите на оператора, разделена на разликата между мощностите на изхода на оператора:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
И точно както демонстрирах по-рано, можете да проверите констатациите си, като прогнозирате разходите с друг брой изходни групи и сравнявате вашите прогнозирани числа с тези, произведени от оптимизатора. С всичкия брой групи, които опитах, прогнозираните разходи бяха точни.
Използвайки подобни техники, можете да проверите дали други фактори влияят на разходите на оператора. Моето тестване показва, че мощността на групиращия набор (брой изрази, по които групирате), типовете данни и размерите на групираните изрази нямат влияние върху прогнозната цена.
Това, което остава, е да проверите дали има някакви значими стартови разходи за оператора. Ако има такава, пълната (надявам се) формула за изчисляване на цената на процесора на оператора трябва да бъде:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Така че можете да извлечете началните разходи от останалите:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
Можете да използвате всеки план за заявка от тази статия за тази цел. Например, като използвате числата от плана за заявка 5, показан по-рано на фигура 4, получавате:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Както изглежда, операторът Stream Aggregate няма никакви разходи за стартиране, свързани с процесора, или е толкова ниска, че не се показва с точността на мярката за разходите.
В заключение, формулата за обратно проектиране за операторската цена на Stream Aggregate е:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Фигура 5 изобразява мащабирането на разходите на оператора Stream Aggregate по отношение както на броя на редовете, така и на броя на групите.
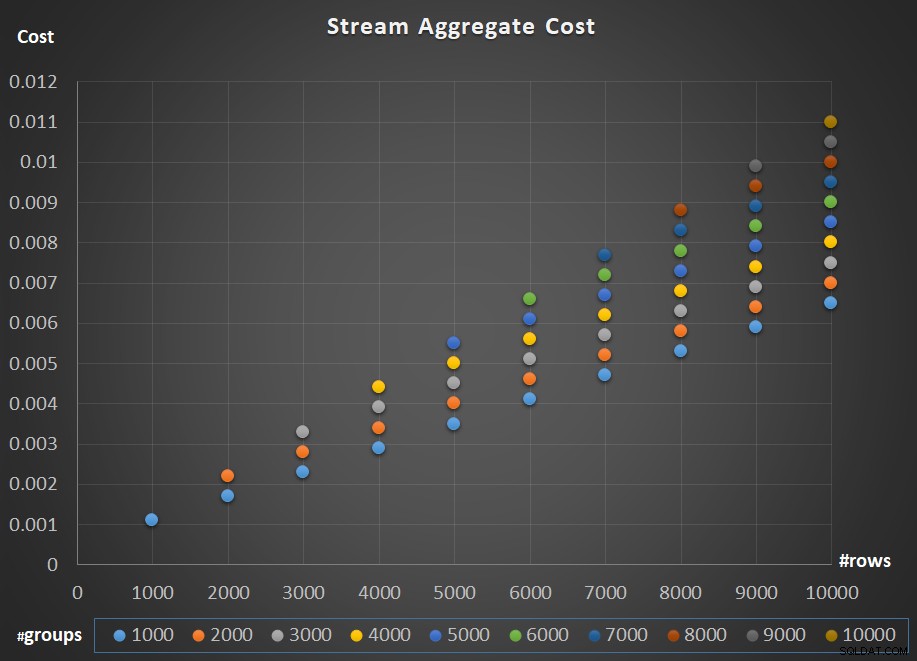
Фигура 5:Диаграма за мащабиране на алгоритъма на потока Aggregate
Що се отнася до мащабирането на оператора; то е линейно. В случаите, когато броят на групите има тенденция да бъде пропорционален на броя на редовете, цялата цена на оператора се увеличава със същия коефициент, с който се увеличават както броят на редовете, така и на групите. Това означава, че удвояването на броя както на входните редове, така и на входните групи води до удвояване на цялата цена на оператора. За да разберете защо, да предположим, че представяме разходите на оператора като:
r * 0.0000006 + g * 0.0000005
Ако увеличите както броя на редовете, така и броя на групите със същия фактор p, получавате:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Така че, ако за даден брой редове и групи цената на оператора Stream Aggregate е C, увеличаването на броя на редовете и групите със същия коефициент p води до операторна цена от pC. Вижте дали можете да потвърдите това, като посочите примери в диаграмата на фигура 5.
В случаите, когато броят на групите остава доста стабилен, дори когато броят на входните редове нараства, все още получавате линейно мащабиране. Вие просто разглеждате разходите, свързани с броя на групите, като константа. Тоест, ако за даден брой редове и групи цената на оператора е C =G (разходи, свързани с броя на групите) плюс R (разходи, свързани с броя на редовете), увеличавайки само броя на редовете с коефициент от p води до G + pR. В такъв случай, естествено, цялата цена на оператора е по-малка от pC. Тоест, удвояването на броя на редовете води до по-малко от удвояване на цялата цена на оператора.
На практика, в много случаи, когато групирате данни, броят на входните редове е значително по-голям от броя на изходните групи. Този факт, съчетан с факта, че разпределената цена на ред и цената на група са почти еднакви, частта от разходите на оператора, която се приписва на броя на групите, става незначителна. Като пример вижте плана за заявка 1, показан по-рано на Фигура 1. В такива случаи е безопасно просто да мислим за цената на оператора като просто линейно мащабиране по отношение на броя на входните редове.
Специални случаи
Има специални случаи, когато операторът Stream Aggregate изобщо не се нуждае от сортиране на данните. Ако се замислите, алгоритъмът на Stream Aggregate има по-спокойно изискване за подреждане от входа в сравнение с това, когато имате нужда от данните, подредени за целите на представянето, например когато заявката има клауза ORDER BY за външна презентация. Алгоритъмът на Stream Aggregate просто се нуждае от всички редове от една и съща група да бъдат подредени заедно. Вземете входния набор {5, 1, 5, 2, 1, 2}. За целите на подреждането на презентацията този набор трябва да бъде подреден така:1, 1, 2, 2, 5, 5. За целите на агрегирането алгоритъмът на Stream Aggregate ще работи добре, ако данните са подредени в следния ред:5, 5, 1, 1, 2, 2. Имайки предвид това, когато изчислявате скаларен агрегат (заявка с агрегатна функция и без клауза GROUP BY) или групирате данните чрез празен набор за групиране, никога няма повече от една група . Независимо от реда на входните редове, може да се приложи алгоритъмът Stream Aggregate. Алгоритъмът Hash Aggregate хешира данните въз основа на изразите на групиращия набор като входни данни и както със скаларни агрегати, така и с празен набор за групиране, няма входни данни за хеширане. Така че, както със скаларни агрегати, така и с агрегати, приложени към празен набор за групиране, оптимизаторът винаги използва алгоритъма Stream Aggregate, без да изисква данните да бъдат предварително подредени. Поне така е в режима на изпълнение на редове, тъй като в момента (от SQL Server 2017 CU4) пакетният режим е наличен само с алгоритъма на Hash Aggregate. Ще използвам следните две заявки, за да демонстрирам това (наречете ги заявка 7 и заявка 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
Плановете за тези заявки са показани на фигура 6.
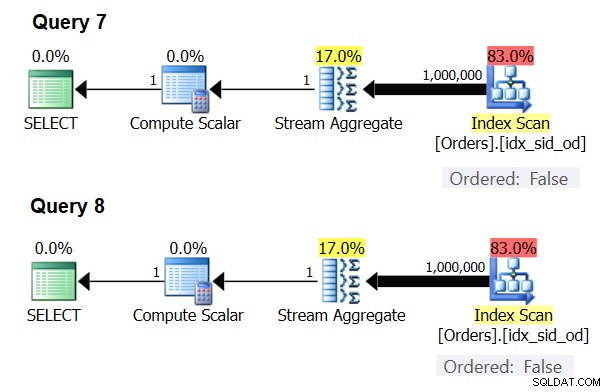
Фигура 6:Планове за заявка 7 и заявка 8
Опитайте да наложите алгоритъм за хеш агрегат и в двата случая:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
Оптимизаторът игнорира вашата заявка и създава същите планове, показани на фигура 6.
Бърз тест:каква е разликата между скаларен агрегат и агрегат, приложен към празен набор за групиране?
Отговор:с празен входен набор, скаларен агрегат връща резултат с един ред, докато агрегат в заявка с празен набор за групиране връща празен набор от резултати. Опитайте:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Когато приключите, изпълнете следния код за почистване:
DROP INDEX idx_sid_od ON dbo.Orders;
Обобщение и предизвикателство
Обратното инженерство на формулата за изчисляване на разходите за алгоритъма Stream Aggregate е детска игра. Бих могъл просто да ви кажа, че формулата за изчисляване на разходите за предварително поръчан алгоритъм на Stream Aggregate е @numrows * 0,0000006 + @numgroups * 0,0000005 вместо цяла статия, за да обясните как разбирате това. Въпросът обаче беше да се опишат процесът и принципите на обратното инженерство, преди да се премине към по-сложните алгоритми и праговете, при които един алгоритъм става по-оптимален от другите. Да те науча как да ловиш риба, вместо да ти дава риба. Научих толкова много и открих неща, за които дори не съм се замислял, докато се опитвах да преобразувам формули за изчисляване на разходите за различни алгоритми.
Готови ли сте да тествате уменията си? Вашата мисия, ако решите да я приемете, е много по-трудна от обратното проектиране на оператора Stream Aggregate. Обратно инженерство на формулата за изчисляване на разходите на сериен оператор за сортиране. Това е важно за нашето изследване, тъй като алгоритъмът на Stream Aggregate, приложен за заявка с непразен набор за групиране, където входните данни не са предварително подредени, изисква изрично сортиране. В такъв случай цената и мащабирането на агрегираната операция зависят от цената и мащабирането на комбинираните оператори Sort и Stream Aggregate.
Ако успеете да се доближите прилично с прогнозирането на цената на оператора за сортиране, можете да почувствате, че сте спечелили правото да добавите към подписа си „Обратен инженер“. Има много софтуерни инженери; но със сигурност не виждате много обратни инженери! Просто не забравяйте да тествате формулата си както с малки числа, така и с големи; може да се изненадате от това, което откриете.