Специалистите по данни не винаги могат да използват бази данни с оптимален дизайн. Понякога нещата, които те карат да плачеш, са неща, които сме си направили, защото тогава изглеждаха като добри идеи. Понякога те се дължат на приложения на трети страни. Понякога те просто ви предхождат.
Това, за което си мисля в тази публикация, е когато вашата колона datetime (или datetime2, или още по-добре, datetimeoffset) всъщност е две колони – една за датата и една за часа. (Ако отново имате отделна колона за компенсацията, тогава ще ви прегърна следващия път, когато ви видя, защото вероятно ви се е налагало да се справяте с всякакви наранявания.)
Направих проучване в Twitter и открих, че това е много реален проблем, с който около половината от вас трябва да се справят с дата и час от време на време.
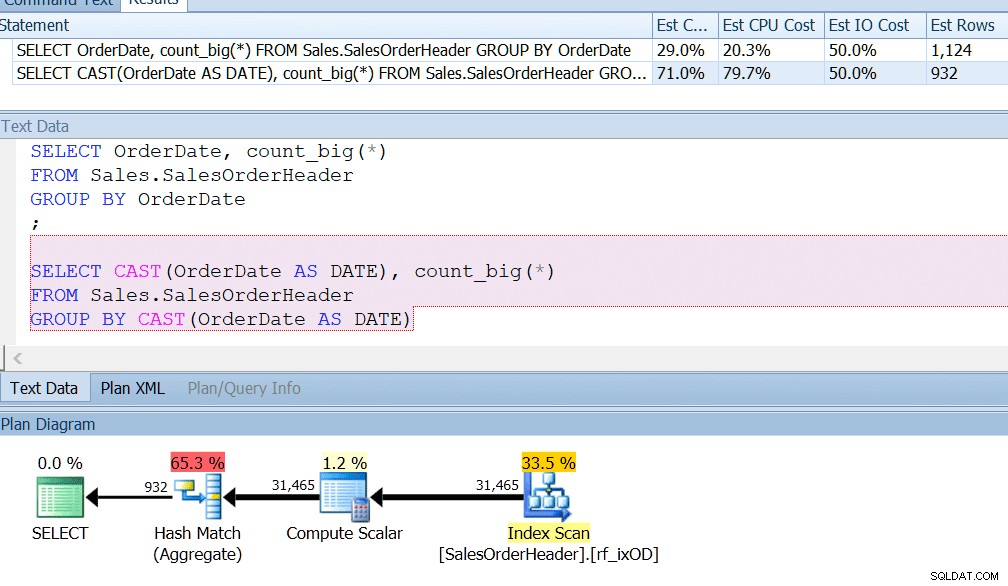
AdventureWorks почти прави това – ако погледнете в таблицата Sales.SalesOrderHeader, ще видите колона за дата и час, наречена OrderDate, която винаги има точни дати в нея. Обзалагам се, че ако сте разработчик на отчети в AdventureWorks, вероятно сте писали заявки, които търсят броя на поръчките в определен ден, като използвате GROUP BY OrderDate или нещо подобно. Дори и да знаехте, че това е колона за дата и час и има потенциал тя да съхранява и час извън полунощ, пак ще кажете ГРУПА ПО РЪДДАТ за дата само за да използвате правилно индекса. GROUP BY CAST (Дата на поръчката КАТО ДАТА) просто не го отрязва.
Имам индекс на OrderDate, както бихте направили, ако редовно задавате заявки за тази колона, и мога да видя, че групирането по CAST(OrderDate AS DATE) е около четири пъти по-лошо от гледна точка на процесора.
Така че разбирам защо бихте се радвали да запитате колоната си, сякаш е дата, просто знаейки, че ще изпитате цяла болка, ако използването на тази колона се промени. Може би решавате това, като имате ограничение на масата. Може би просто си сложихте главата в пясъка.
И когато някой дойде и каже „Знаеш ли, трябва да съхраняваме и времето, когато поръчките се случват“, добре, мислиш за целия код, който приема, че OrderDate е просто дата и смяташ, че има отделна колона, наречена OrderTime (тип данни време, моля) ще бъде най-разумният вариант. Разбирам. Не е идеално, но работи, без да чупи твърде много неща.
В този момент ви препоръчвам също да направите OrderDateTime, което би било изчислена колона, свързваща двете (което трябва да направите, като добавите броя на дните от ден 0 към CAST(OrderDate като datetime2), вместо да се опитвате да добавите часа към дата, която обикновено е много по-объркана). И след това индексирайте OrderDateTime, защото това би било разумно.
Но доста често ще се окажете с дата и час като отделни колони, като по същество нищо не можете да направите по въпроса. Не можете да добавите изчислена колона, защото това е приложение на трета страна и не знаете какво може да се счупи. Сигурни ли сте, че никога не правят SELECT *? Един ден се надявам, че ще ни позволят да добавим колони и да ги скрием, но за момента със сигурност рискувате да разбиете неща.
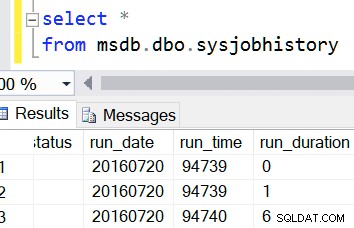
И, знаете, дори msdb прави това. И двете са цели числа. И това е заради обратната съвместимост, предполагам. Но се съмнявам, че обмисляте да добавите изчислена колона към таблица в msdb.
И така, как да запитаме това? Да предположим, че искаме да намерим записите, които са били в определен диапазон от време и време?
Нека да експериментираме.
Първо, нека създадем таблица с 3 милиона реда и да индексираме колоните, които ни интересуват.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Бих могъл да направя това клъстериран индекс, но смятам, че неклъстеризираният индекс е по-типичен за вашата среда.)
Данните ни изглеждат така и искам да намеря редове между, да речем, 2 август 2011 г. в 8:30 ч. и 5 август 2011 г. в 21:30 ч.
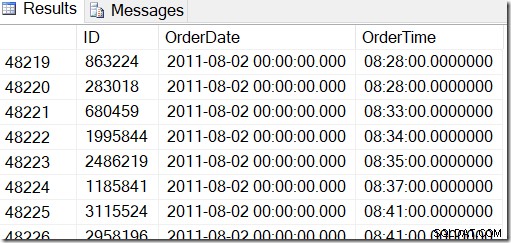
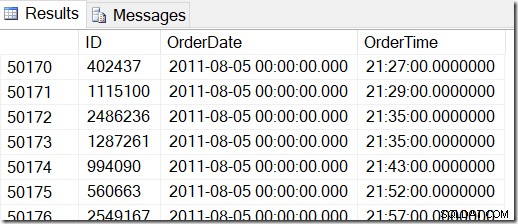
Преглеждайки данните, мога да видя, че искам всички редове между 48221 и 50171. Това са 50171-48221+1=1951 реда (+1 е, защото е включващ диапазон). Това ми помага да съм уверен, че резултатите ми са правилни. Вероятно бихте имали подобно на вашата машина, но не точно, защото използвах произволни стойности, когато генерирах моята таблица.
Знам, че не мога просто да направя нещо подобно:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
...защото това няма да включва нещо, което се е случило през нощта на 4-ти. Това ми дава 1268 реда - очевидно не е правилно.
Една от опциите е да комбинирате колоните:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Това дава правилните резултати. Това е така. Просто това не подлежи на саргиране и ни дава сканиране на всички редове в нашата таблица. На нашите 3 милиона реда може да отнеме секунди, за да изпълним това.
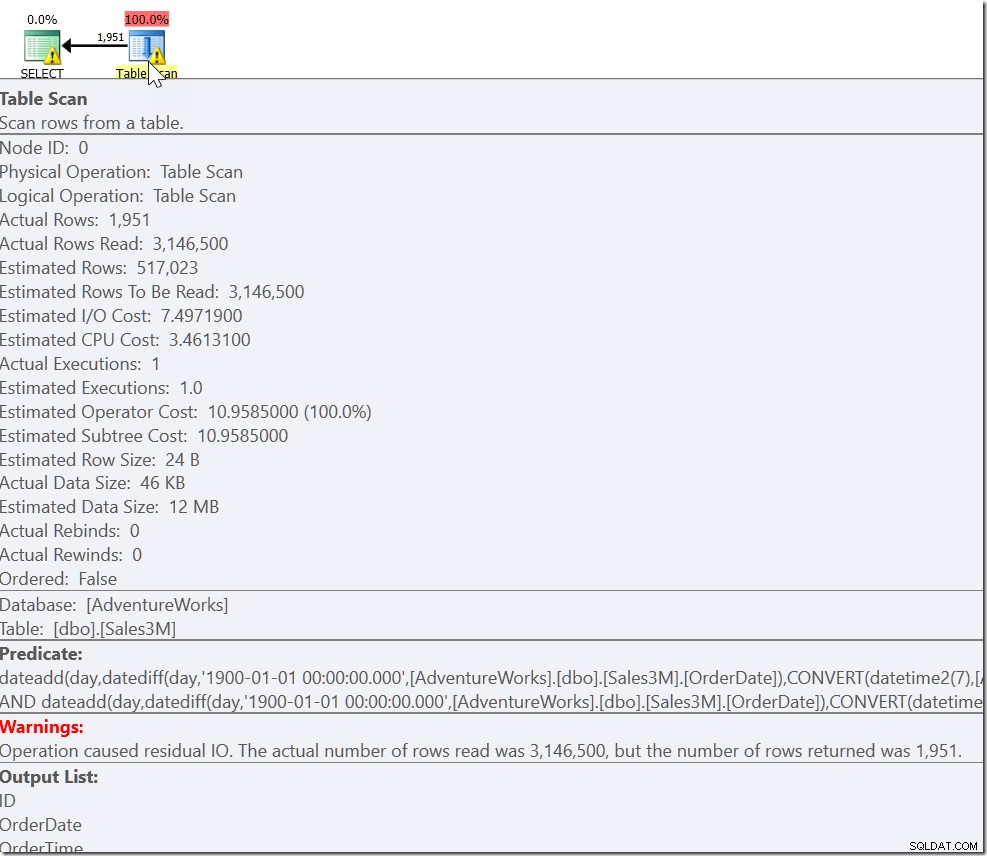
Проблемът ни е, че имаме обикновен случай и два специални случая. Знаем, че всеки ред, който отговаря на OrderDate> ‘20110802’ И OrderDate <‘20110805’ е този, който искаме. Но също така се нуждаем от всеки ред, който е на или след 8:30 на 20110802 и на или преди 21:30 на 20110805. И това ни води до:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
ИЛИ е ужасно, знам. Това също може да доведе до сканиране, макар и не непременно. Тук виждам три търсене на индекси, които се свързват и след това се проверяват за уникалност. Оптимизаторът на заявки очевидно осъзнава, че не трябва да връща един и същ ред два пъти, но не осъзнава, че трите условия са взаимно изключващи се. И всъщност, ако правите това на диапазон в рамките на един ден, ще получите грешни резултати.
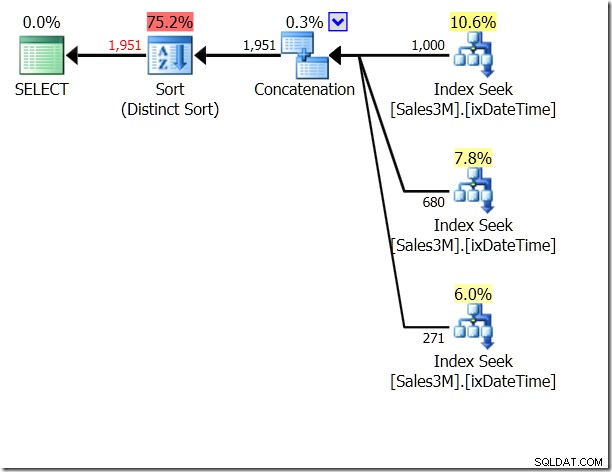
Бихме могли да използваме UNION ALL за това, което би означавало, че QO няма да се интересува дали условията са взаимно изключващи се. Това ни дава три търсения, които са свързани – това е доста добре.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Но все пак са три търсения. Статистиката IO ми казва, че е 20 четения на моята машина.

Сега, когато мисля за sargability, не мисля само за избягване на поставянето на колони на индекси вътре в изрази, но също така мисля за това какво може да помогне на нещо изглежда sargable.
Вземете например WHERE LastName LIKE 'Far%'. Когато гледам плана за това, виждам Seek, с предикат Seek търси всяко име от Far до (но без) FaS. И тогава има Остатъчен предикат, който проверява условието LIKE. Това не е така, защото QO счита, че LIKE може да се sargable. Ако беше, щеше да може да използва LIKE в предиката за търсене. Това е, защото знае, че всичко, което е удовлетворено от това LIKE условие, трябва да бъде в този диапазон.
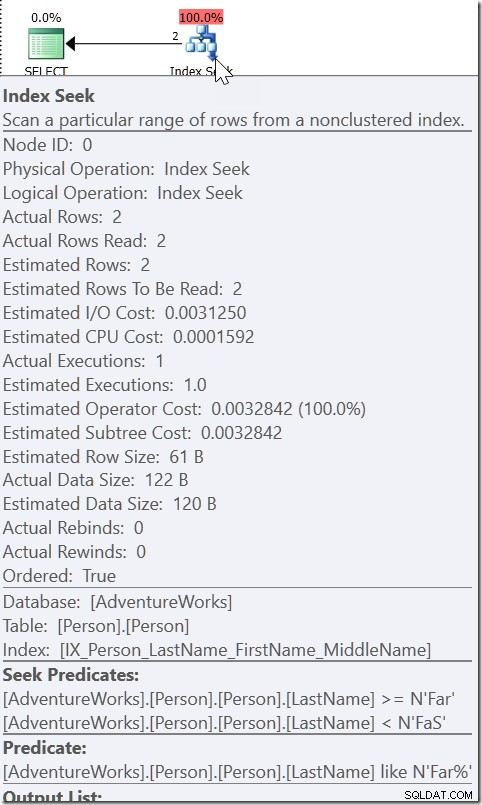
Вземете WHERE CAST(OrderDate AS DATE) ='20110805'
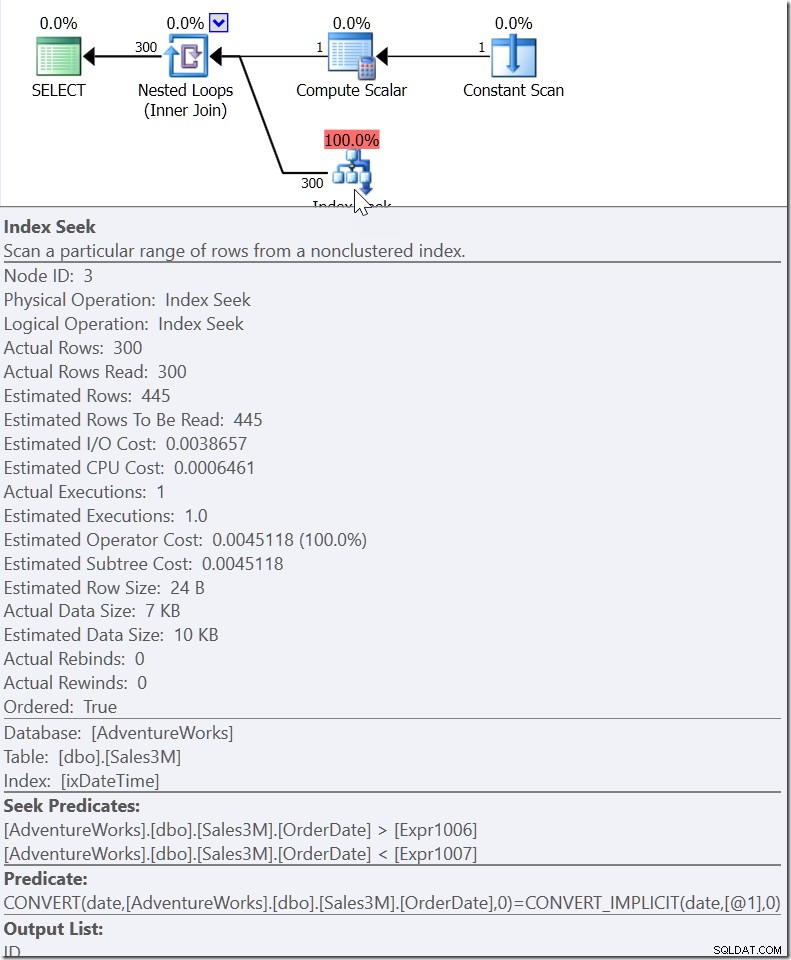
Тук виждаме предикат за търсене, който търси стойности на OrderDate между две стойности, които са били разработени другаде в плана, но създава диапазон, в който трябва да съществуват правилните стойности. Това не е>=20110805 00:00 и <20110806 00:00 (което щях да го направя), а е нещо друго. Стойността за начало на този диапазон трябва да е по-малка от 20110805 00:00, защото е>, а не>=. Всичко, което наистина можем да кажем, е, че когато някой в Microsoft внедри как QO трябва да реагира на този вид предикат, той му даде достатъчно информация, за да излезе с това, което аз наричам „предикат за помощник“.
Сега бих искал Microsoft да направи повече функции за sargable, но тази конкретна заявка беше затворена много преди да оттеглят Connect.
Но може би това, което имам предвид, е да направят повече помощни предикати.
Проблемът с помощните предикати е, че те почти сигурно четат повече редове, отколкото искате. Но все пак е много по-добре, отколкото да преглеждате целия индекс.
Знам, че всички редове, които искам да върна, ще имат OrderDate между 20110802 и 20110805. Просто има някои, които не искам.
Мога просто да ги премахна и това ще е валидно:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
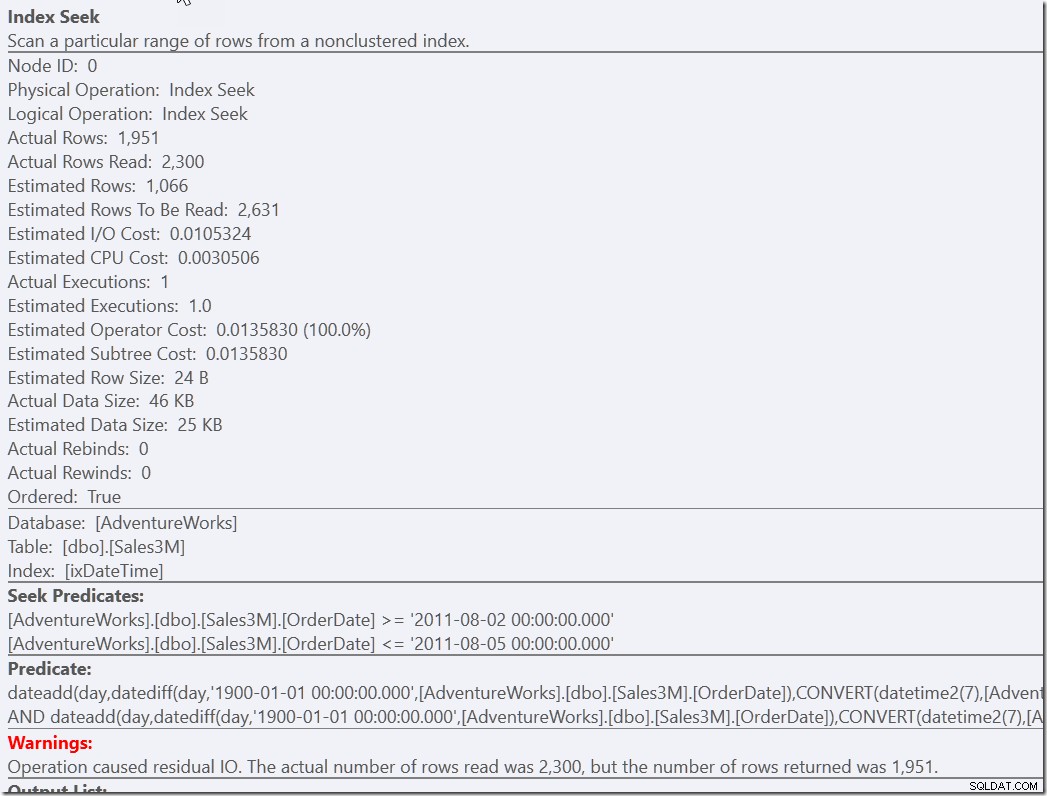
Но имам чувството, че това е решение, което изисква известно усилие на мисълта, за да се намери. По-малко усилия от страна на разработчика е просто да предоставим помощен предикат на нашата правилна, но бавна версия.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
И двете от тези заявки намират 2300 реда, които са в правилните дни, и след това трябва да проверят всички тези редове спрямо другите предикати. Единият трябва да провери двете условия НЕ, другият трябва да направи преобразуване на типове и математика. Но и двете са много по-бързи от това, което имахме преди, и правят едно търсене (13 четения). Разбира се, получавам предупреждения за неефективен RangeScan, но това е моето предпочитание пред три ефективни.
В известен смисъл най-големият проблем с този последен пример е, че някой добронамерен човек ще види, че помощният предикат е излишен и може да го изтрие. Такъв е случаят с всички помощни предикати. Така че сложете коментар.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Ако имате нещо, което не се вписва в хубав предикат за sargable, изработете такъв и след това разберете какво трябва да изключите от него. Може просто да измислите по-добро решение.
@rob_farley