Как се съхраняват всички тези данни за общественото мнение? Проверяваме модел на данни от проучване на общественото мнение.
Всеки иска да знае какво мисли обществото, от политици и компании до хора, които искат да знаят какво мислят другите по определена тема. Този вид работа обикновено се извършва от агенции, специализирани в този вид изследвания.
Днес ще разгледаме модел на данни, който такава агенция може да използва, за да съхранява всички релевантни данни от анкетата, от въпроси и предварително определени отговори до действителната обратна връзка. Тези данни ще бъдат използвани по-късно за създаване на различни отчети. И така, да започнем.
Идея
Анкети могат да се създават навсякъде. Те могат да бъдат добре планирани и да включват представителна извадка от обществеността (въз основа на демографски данни). Или бихте могли да ги направите на място, напр. ако искате да предвидите изборни резултати въз основа на извадка (като екзитпол), вероятно ще попитате хората в избирателната секция как са гласували.
От друга страна, ако искате да създадете същата анкета преди изборите, вероятно ще изберете извадка и ще се свържете с хора по телефона или лично. Обикновено има само няколко въпроса за този тип анкети – някои за демографски данни, а други за това, което наистина ни интересува.
Анкетите могат да бъдат и много по-сложни, напр. ако искате да разберете общественото мнение за определен продукт, обхващащо всичко от неговата производителност до опаковката.
В тази статия няма да обсъждам как да избера примерен набор от хора; по-скоро ще се съсредоточа върху самата анкета, нейните въпроси и отговорите.
Модел на данни
Модел на данни на агенцията за обществено мнение
Моделът се състои от три предметни области:
PollsQuestions & AnswersResult
Ще опишем всяка тематична област в реда, в който е изброен.
Анкета
Преди да започнем да задаваме въпроси, трябва да дефинираме какво ни интересува. Ще дефинираме анкети и въпросници в този раздел, след което ще добавим въпроси и отговори в следващия.
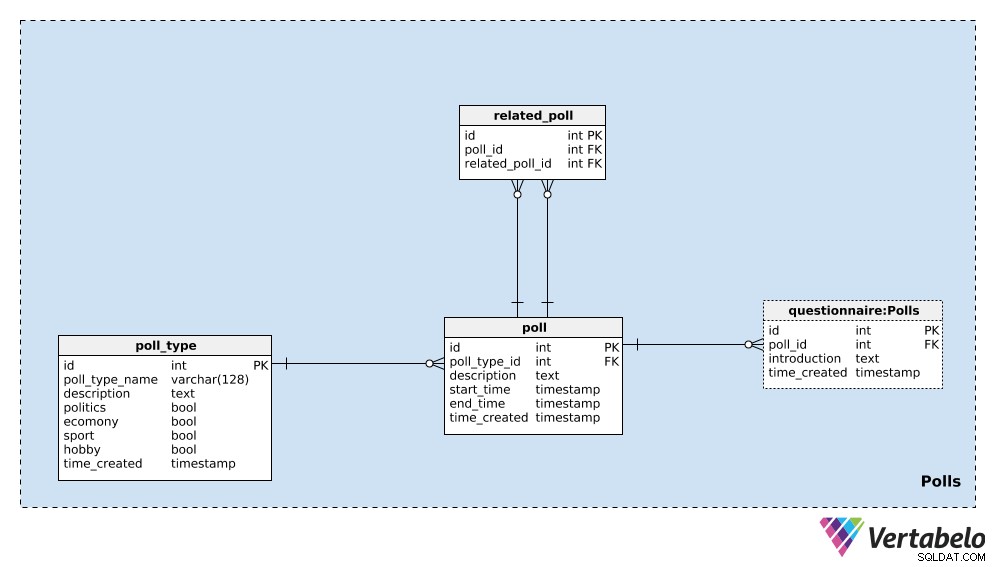
Ще започнем с poll_type речник. Можем да очакваме, че най-вече ще повтаряме анкети от същия тип. Най-често срещаният тип вероятно са изборни анкети, но искаме да можем да добавяме нови типове анкети по пътя. За всеки тип анкета ще съхраняваме УНИКАЛНО poll_type_name и използвайте description атрибут за предоставяне на допълнителни подробности.
Четири знамена – politics , economy , sport и hobby – се използват за обозначаване на типа анкета. Анкета може да обхване една или повече от тези теми; ако е необходимо, бихме могли да разделим тези категории в отделен речник и да имаме връзка много към много между този речник и poll_type таблица.
Последният атрибут в тази таблица е time_created . Той обозначава момента, в който се вмъква ред в тази таблица.
Следващото нещо, което трябва да направим, е да дефинираме единична poll . Това е единичен случай, напр. „Президентски избори в САЩ 2020 г. – Анкета през април 2020 г.“ . За всяка анкета ще съхраняваме следните подробности:
poll_type_id– Препратка къмpoll_type.description– Всички подробности, свързани с тази анкета, в текстов формат.start_timeиend_time– Дефинираните начални и крайни времена, през които се прави тази анкета.time_created– Реалният момент, когато е създадена тази анкета.
Анкети могат да бъдат свързани помежду си. В примера на „Президентските избори в САЩ 2020 – анкета през април 2020 г.“ , можем да направим същата анкета следващия месец, за да видим най-актуалните мнения. Бихме нарекли това „Президентски избори в САЩ 2020 г. – анкета през май 2020 г.“ . Тези две анкети са свързани, защото резултатите им показват тенденции. За да установим тази връзка, ще използваме related_poll таблица в нашия модел. Съдържа само УНИКАЛНАТА двойка poll_id – related_poll_id , обозначавайки анкетата и нейния предшественик.
Имайте предвид, че можем да използваме тази таблица, за да съхраняваме всички анкети, които са свързани по какъвто и да е начин, а не само предшественици/наследници. Ако искаме да дефинираме различни връзки, ще трябва да добавим още един речник – но няма да отидем по този начин в тази статия.
Последната таблица в тази тематична област е questionnaire маса. В повечето случаи всяка анкета ще има точно един въпросник, но искам да оставя опцията да имаме повече от един, ако е необходимо. Затова използвах отделна таблица. В тази таблица ще съхраняваме само идентификатора на свързаната анкета (poll_id ), introduction описващ този въпросник и времевата марка, когато записът е бил вмъкнат (time_created ).
Въпроси и отговори
Сега сме готови да създадем всички детайли на въпросника. Можем също да изброим всички въпроси, които искаме да зададем, както и всички предварително определени отговори.
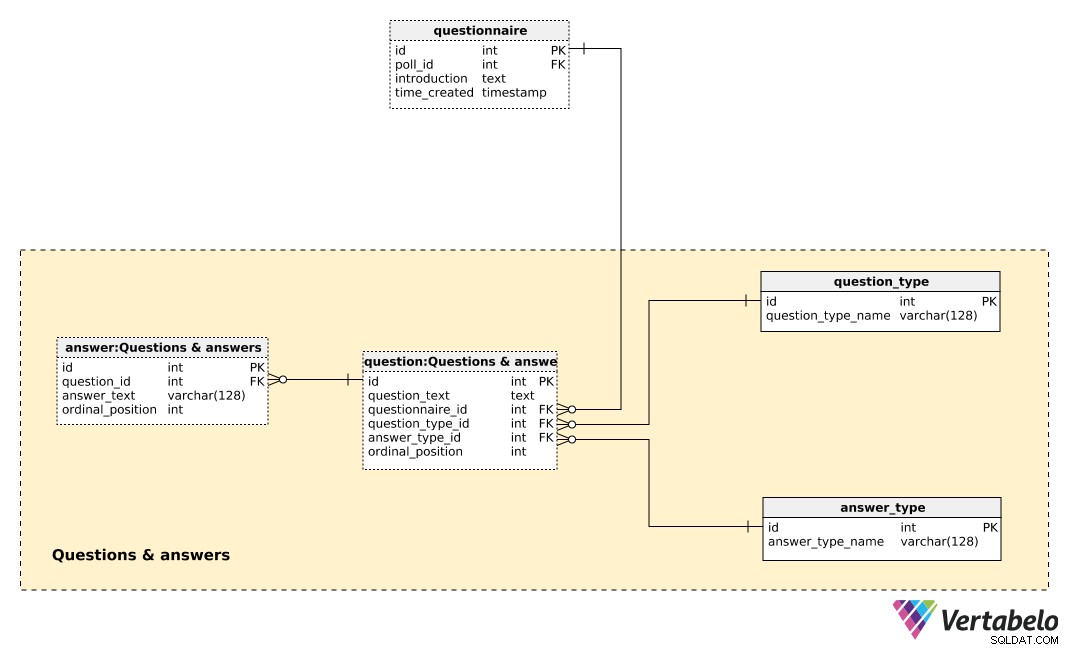
Централната таблица в тази предметна област е question маса. Всеки въпрос се определя от следните подробности:
question_text– Текст, който ще се показва на всеки анкетиран индивид.questionnaire_id– Препратка, обозначаваща въпросника на този въпрос.question_type_id– Препратка, обозначаващаquestion_type, което е УНИКАЛНО обозначено сquestion_type_name. Това са основно категории, напр. „демография“, „мнение“, „контрол“ и т.н. Това ще ни позволи да разделим демографските въпроси и въпросите на мнението и да намерим корелация между тях.answer_type_id– Препратка към типа отговор, който ще се използва за този въпрос. Всекиanswer_typeе УНИКАЛНО дефинирано отanswer_type_nameи обозначава как се показва отговорът. Някои очаквани типове са „отворени“, „списъци“, „кутие за отметка“ и „множество“.ordinal_position– Тази стойност обозначава позицията на този въпрос във въпросника. Заедно сquestionnaire_id, той формира алтернативния ключ на тази таблица.
Списък с всички предварително дефинирани отговори се съхранява в answer маса. Ако типът на въпроса не е отворен (т.е. текстът няма да бъде въведен от лицето), ще имаме набор от предварително дефинирани отговори. За всеки отговор ще дефинираме въпроса, към който принадлежи (question_id ), answer_text , и ordinal_position на този отговор вътре в този въпрос. Още веднъж, УНИКАЛНА двойка – този път question_id – ordinal_position – формира алтернативния ключ на тази таблица.
Резултат
В предишните две тематични области сме дефинирали всичко необходимо, за да създадем анкетата и да започнем да задаваме въпроси. Сега трябва да дефинираме структура от данни за съхраняване на действителните отговори.
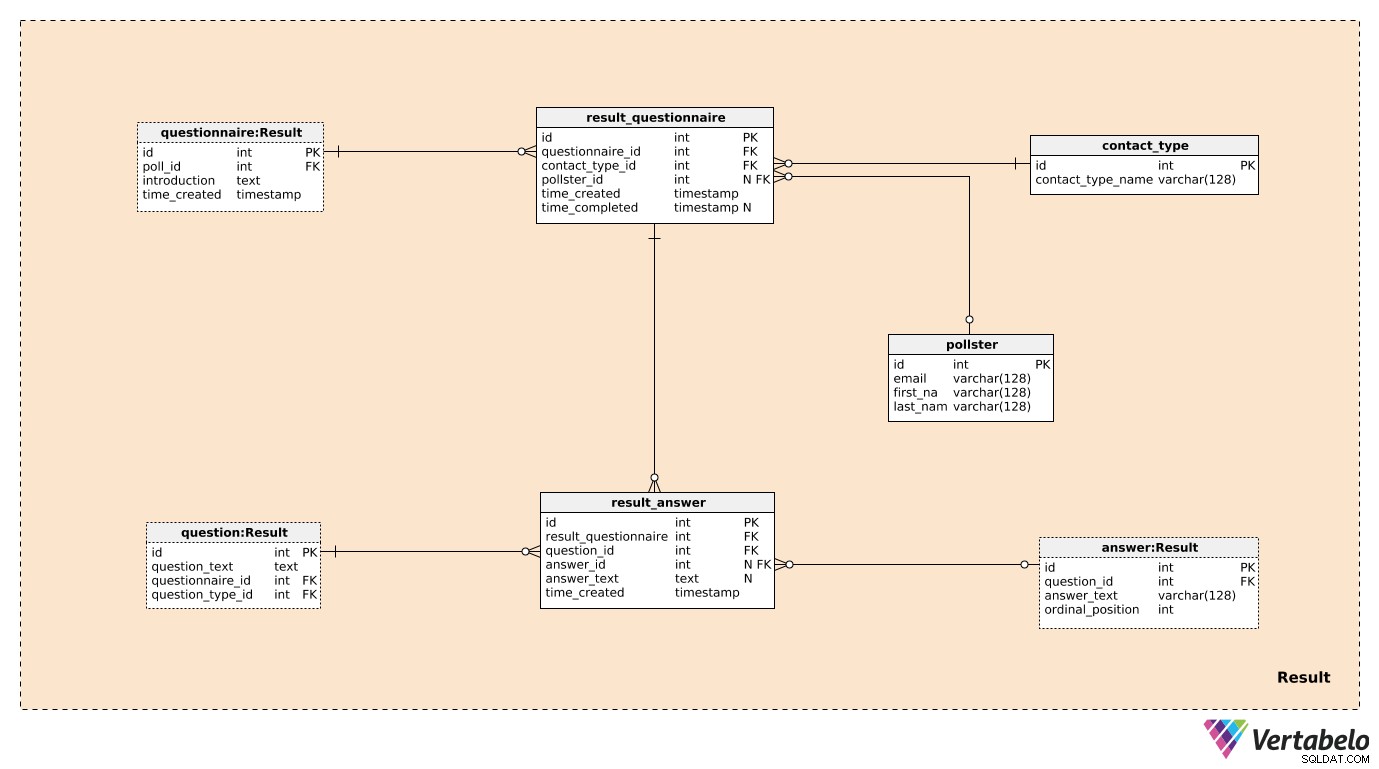
Три от седемте таблици в Result предметната област бяха споменати и описани по-рано. Това са questionnaire , question , и answer . Останалите четири таблици се използват за съхраняване на това, което наистина ни интересува.
Ще създадем един запис в result_questionnaire таблица за всеки участник в анкетата. questionnaire_id предоставя на esus цялата информация за съответната анкета. contact_type_id е препратка към contact_type речник. Стойностите в тази таблица описват начина, по който сме взаимодействали с този човек. Тези стойности са УНИКАЛНО дефинирани от contact_type_name стойност и може да бъде нещо като „телефон“, „лично“, „имейл“, „уеб формуляр“ и т.н.
pollster_id атрибутът е препратка към pollster таблица, която предоставя информация за това кой е провел тази действителна анкета. За всеки pollster , ще съхраняваме само техния УНИКАЛЕН имейл и тяхното first_name и last_name . time_created атрибутът обозначава действителното време, когато този запис е създаден, докато time_completed ще бъде зададен в момента, в който това проучване приключи. (До този момент ще бъде NULL).
Последната таблица в модела е result_answer маса. Както подсказва името му, тук ще съхраняваме действителните отговори, които получихме от анкетираните. За всеки запис в тази таблица ще имаме:
result_questionnaire_id– Препратка към съответния въпросник.question_id– Препратка, обозначаваща въпроса, на който е отговорен този отговор.answer_id– Препратка към отговора, използван за отговор на този въпрос. Този атрибут ще съдържа стойност NULL, когато въпросът е от „отворен“ тип (тъй като нямаше предварително дефинирани отговори, от които да избирате).answer_text– Текстът, който беше вмъкнат, за да отговори на този въпрос. Този атрибут ще съдържа стойност, когато въпросът е бил „отворен“; във всички останали случаи ще бъде NULL.time_created– Действителното време, когато този отговор е бил вмъкнат в нашата система.
Възможни подобрения
Досега разгледахме как можем да съхраняваме данни от анкети. Не сме обсъдили какво ще правим с данните след приключване на анкетата. Можем да очакваме, че няма да се нуждаем от старите данни в бъдеще, поне не в нашата оперативна база данни. Следователно бихме могли да направим две неща:
- Съхранете резюме на анкетата в отделна таблица в оперативната база данни. Това ще запази такава информация на наше разположение, ако искаме да видим какво се е случило с подобна анкета.
- Съхранявайте всички данни от анкетата в резервна база данни, която има същата структура като оперативната база данни. Това ще ни позволи да получим достъп до подробностите, когато имаме нужда от тях.
Бихме могли също да създадем хранилище за данни за съхраняване на резултатите от анкетата, но това не би било необходимо, ако вече бяхме изпълнили задачите, описани в двете точки.
Какво мислите за нашия модел на данни от проучвания на общественото мнение?
Бихме искали да чуем вашето мнение за това какво бихме могли да променим, за да подобрим модела на данни от проучвания на общественото мнение. Имате ли опит в индустрията? Мислите ли, че сме пропуснали нещо? Бихте ли добавили или премахнете нещо? Очаквам с нетърпение вашите мнения.