[ Част 1 | Част 2 | Част 3 | Част 4 ]
В част 3 от тази серия показах две решения, за да избегна разширяване на IDENTITY колона – една, която просто ви печели време, и друга, която изоставя IDENTITY като цяло. Първият ви предпазва от работа с външни зависимости като външни ключове, но вторият все още не решава този проблем. В тази публикация исках да опиша подробно подхода, който бих предприел, ако абсолютно трябва да премина към bigint , трябваше да минимизира времето за престой и имаше достатъчно време за планиране.
Поради всички потенциални блокери и необходимостта от минимално прекъсване, подходът може да се разглежда като малко сложен и става по-голям само ако се използват допълнителни екзотични функции (да речем, разделяне, OLTP в паметта или репликация) .
На много високо ниво подходът е да се създаде набор от сенчести таблици, където всички вмъквания са насочени към ново копие на таблицата (с по-големия тип данни), а съществуването на двата набора от таблици е толкова прозрачно колкото е възможно за приложението и неговите потребители.
На по-подробно ниво наборът от стъпки ще бъде както следва:
- Създайте сенчести копия на таблиците с правилните типове данни.
- Променете съхранените процедури (или ad hoc код), за да използвате bigint за параметри. (Това може да изисква промяна извън списъка с параметри, като локални променливи, временни таблици и т.н., но случаят тук не е такъв.)
- Преименувайте старите таблици и създайте изгледи с тези имена, които обединяват старите и новите таблици.
- Тези изгледи ще имат вместо тригери за правилно насочване на DML операции към подходящата(ите) таблица(и), така че данните все още да могат да се променят по време на миграцията.
- Това също така изисква SCHEMABINDING да бъде премахнат от всички индексирани изгледи, съществуващите изгледи да имат обединения между нови и стари таблици и процедурите, разчитащи на SCOPE_IDENTITY() да бъдат променени.
- Мигрирайте старите данни към новите таблици на парчета.
- Почистване, състоящо се от:
- Отпадане на временните изгледи (което ще премахне задействанията INSTEAD OF).
- Преименуване на новите таблици обратно към оригиналните имена.
- Коригиране на съхранените процедури за връщане към SCOPE_IDENTITY().
- Изтриване на старите, вече празни таблици.
- Връщане на SCHEMABINDING обратно в индексирани изгледи и повторно създаване на клъстерирани индекси.
Вероятно можете да избегнете голяма част от изгледите и задействанията, ако можете да контролирате целия достъп до данни чрез съхранени процедури, но тъй като този сценарий е рядък (и е невъзможно да се вярва на 100%), ще покажа по-трудния път.
Първоначална схема
В опит да запазим този подход възможно най-прост, като същевременно се обръщаме към много от блокерите, които споменах по-рано в поредицата, нека предположим, че имаме тази схема:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Така че проста таблица с персонал, с клъстерирана колона IDENTITY, неклъстериран индекс, изчислена колона въз основа на колоната IDENTITY, индексиран изглед и отделна таблица HR/dirt, която има външен ключ обратно към таблицата с персонал (I не насърчавам непременно този дизайн, просто го използвам за този пример). Това са всички неща, които правят този проблем по-сложен, отколкото би бил, ако имахме самостоятелна, независима маса.
С тази схема вероятно имаме някои съхранени процедури, които правят неща като CRUD. Те са повече за документация, отколкото за всичко; Ще направя промени в основната схема, така че промяната на тези процедури да е минимална. Това е, за да се симулира факта, че промяната на ad hoc SQL от вашите приложения може да не е възможна и може да не е необходима (е, стига да не използвате ORM, който може да открие таблица спрямо изглед).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Сега нека добавим 5 реда данни към оригиналните таблици:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Стъпка 1 – нови таблици
Тук ще създадем нова двойка таблици, отразяващи оригиналите с изключение на типа данни на колоните EmployeeID, първоначалното начало за колоната IDENTITY и временен суфикс на имената:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Стъпка 2 – коригиране на параметрите на процедурата
Процедурите тук (и евентуално вашият ad hoc код, освен ако вече не използва по-голям целочислен тип) ще се нуждаят от много малка промяна, така че в бъдеще да могат да приемат стойности на EmployeeID извън горните граници на цяло число. Въпреки че бихте могли да спорите, че ако ще промените тези процедури, можете просто да ги насочите към новите таблици, аз се опитвам да твърдя, че можете да постигнете крайната цел с *минимално* проникване в съществуващите, постоянни код.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Стъпка 3 – прегледи и задействания
За съжаление, това не може *всичко* да се направи тихо. Можем да правим повечето от операциите паралелно и без да засягаме едновременното използване, но поради SCHEMABINDING индексираният изглед трябва да бъде променен и индексът по-късно да бъде създаден отново.
Това е вярно за всички други обекти, които използват SCHEMABINDING и препращат към някоя от нашите таблици. Препоръчвам да го промените да бъде неиндексиран изглед в началото на операцията и просто да възстановите индекса веднъж, след като всички данни са мигрирани, вместо няколко пъти в процеса (тъй като таблиците ще бъдат преименувани многократно). Всъщност това, което ще направя, е да променя изгледа, за да обединя новата и старата версия на таблицата „Служители“ за времето на процеса.
Друго нещо, което трябва да направим, е да променим съхранената процедура Employee_Add, за да използваме @@IDENTITY вместо SCOPE_IDENTITY(), временно. Това е така, защото тригерът INSTEAD OF, който ще обработва нови актуализации на „Служители“, няма да има видимост на стойността SCOPE_IDENTITY(). Това, разбира се, предполага, че таблиците нямат след тригери, които ще засегнат @@IDENTITY. Надяваме се, че можете или да промените тези заявки в съхранена процедура (където можете просто да насочите INSERT към новата таблица), или кодът на приложението ви не трябва да разчита на SCOPE_IDENTITY() на първо място.
Ще направим това под SERIALIZABLE, така че никакви транзакции да не се опитват да се промъкнат, докато обектите са в поток. Това е набор от до голяма степен операции само с метаданни, така че трябва да е бърз.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Стъпка 4 – Мигриране на стари данни към нова таблица
Ще мигрираме данните на парчета, за да сведем до минимум въздействието както върху паралелността, така и върху регистъра на транзакциите, като заимстваме основната техника от една стара моя публикация, „Разбиване на големи операции за изтриване на парчета“. Ще изпълним и тези партиди в SERIALIZABLE, което означава, че ще искате да внимавате с размера на партидата, а за краткост съм пропуснал обработката на грешки.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Резултати:
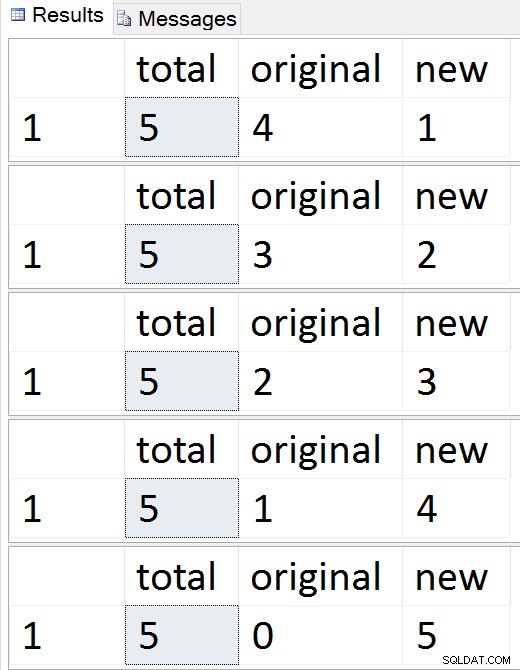 Вижте как редовете мигрират един по един
Вижте как редовете мигрират един по един
По всяко време по време на тази последователност можете да тествате вмъквания, актуализации и изтривания и те трябва да се обработват по подходящ начин. След като миграцията приключи, можете да преминете към останалата част от процеса.
Стъпка 5 – Почистване
Необходими са поредица от стъпки за почистване на обектите, които са били създадени временно, и за възстановяване на Employees / EmployeeFile като правилни, първокласни граждани. Голяма част от тези команди са просто операции с метаданни – с изключение на създаването на клъстерирания индекс в индексирания изглед, всички те трябва да са мигновени.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO В този момент всичко трябва да се върне към нормална работа, въпреки че може да искате да помислите за типични дейности по поддръжка след големи промени в схемата, като актуализиране на статистика, възстановяване на индекси или изваждане на планове от кеша.
Заключение
Това е доста сложно решение на това, което би трябвало да бъде прост проблем. Надявам се, че в един момент SQL Server дава възможност да се правят неща като добавяне/премахване на свойството IDENTITY, възстановяване на индекси с нови целеви типове данни и промяна на колони от двете страни на връзката, без да се жертва връзката. Междувременно ще ми е интересно да чуя дали това решение ви помага, или имате различен подход.
Голямо поздравление към Джеймс Луполт (@jlupoltsql) за това, че помогна на здравия разум да провери подхода ми и да го подложи на най-добрия тест на една от неговите собствени истински маси. (Мина добре. Благодаря Джеймс!)
—
[ Част 1 | Част 2 | Част 3 | Част 4 ]