Наскоро ме смъмриха, че предположих, че в някои случаи неклъстерираният индекс ще се представи по-добре за конкретна заявка от клъстерирания индекс. Този човек заяви, че клъстерираният индекс винаги е най-добрият, защото винаги покрива по дефиниция и че всеки неклъстериран индекс с някои или всички едни и същи ключови колони винаги е бил излишен.
С радост ще се съглася, че клъстерираният индекс винаги покрива (и за да избегнем неясноти тук, ще се придържаме към дискови таблици с традиционни индекси на B-дърво).
 Не съм съгласен обаче, че групираният индекс е винаги по-бързо от неклъстериран индекс. Също така не съм съгласен, че винаги е излишно да се създава неклъстериран индекс или уникално ограничение, състоящо се от същите (или някои от същите) колони в ключа за клъстериране.
Не съм съгласен обаче, че групираният индекс е винаги по-бързо от неклъстериран индекс. Също така не съм съгласен, че винаги е излишно да се създава неклъстериран индекс или уникално ограничение, състоящо се от същите (или някои от същите) колони в ключа за клъстериране.
Да вземем този пример, Warehouse.StockItemTransactions , от WideWorldImporters. Клъстерираният индекс се реализира чрез първичен ключ само на StockItemTransactionID колона (доста типично, когато имате някакъв вид заместващ идентификатор, генериран от IDENTITY или SEQUENCE).
Доста обичайно е да се изисква преброяване на цялата таблица (въпреки че в много случаи има по-добри начини). Това може да бъде за случайна проверка или като част от процедура за пагинация. Повечето хора ще го направят по следния начин:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
С текущата схема това ще използва неклъстериран индекс:
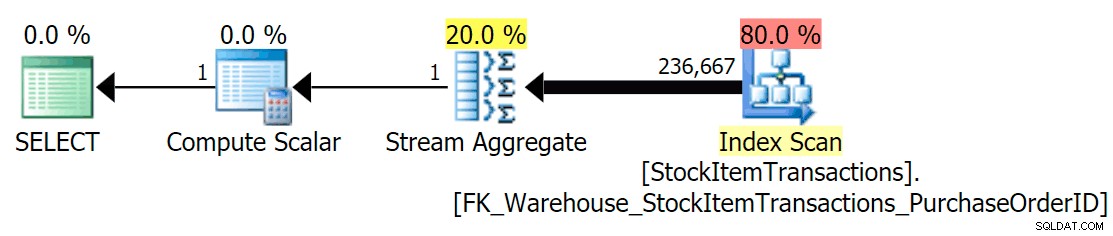
Знаем, че неклъстерираният индекс не съдържа всички колони в клъстерирания индекс. Операцията за броене трябва само да е сигурна, че всички редове са включени, без да се интересува кои колони присъстват, така че SQL Server обикновено избира индекса с най-малък брой страници (в този случай избраният индекс има ~414 страници).
Сега нека стартираме заявката отново, като този път я сравняваме с намекната заявка, която принуждава използването на клъстерирания индекс.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Получаваме почти идентична форма на план, но можем да видим огромна разлика в показанията (414 за избрания индекс срещу 1982 за клъстерирания индекс):
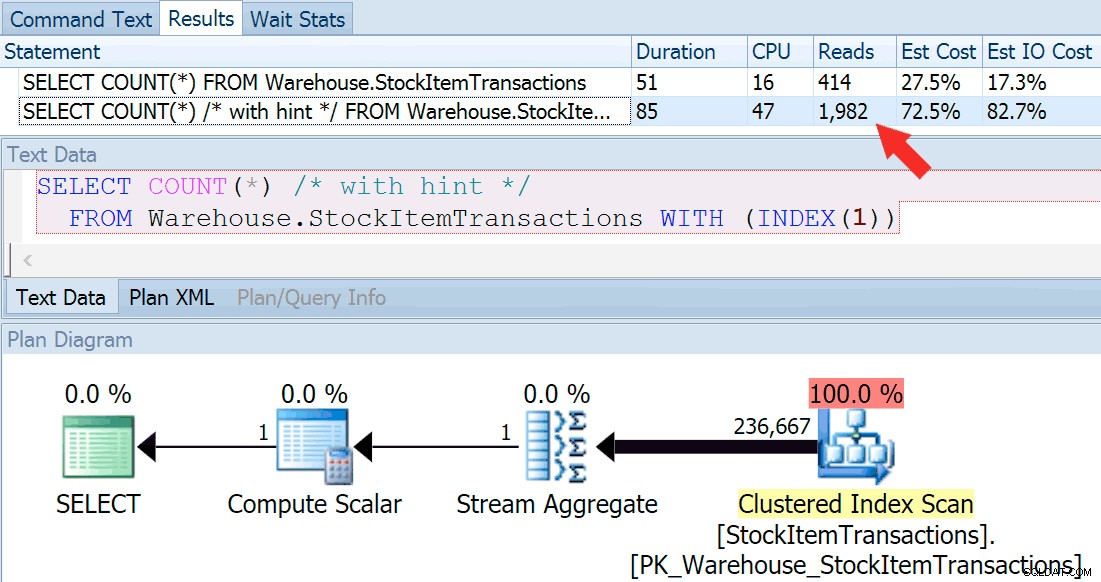
Продължителността е малко по-висока за клъстерирания индекс, но разликата е незначителна, когато имаме работа с малко количество кеширани данни на бърз диск. Това несъответствие би било много по-изразено при повече данни, на бавен диск или на система с напрежение в паметта.
Ако погледнем подсказките за операциите за сканиране, можем да видим, че докато броят на редовете и приблизителните разходи на процесора са идентични, голямата разлика идва от приблизителните I/O разходи (тъй като SQL Server знае, че има повече страници в клъстериран индекс от неклъстерирания индекс):
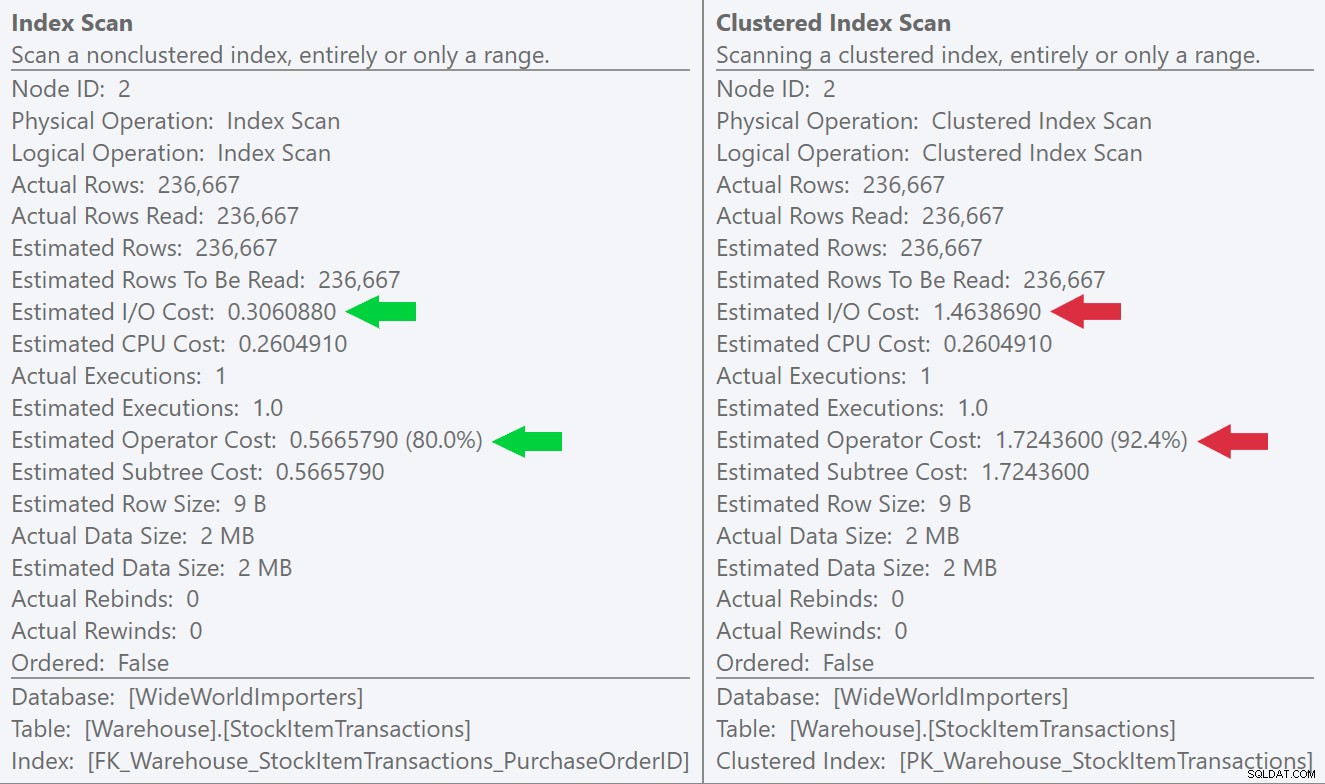
Можем да видим тази разлика още по-ясно, ако създадем нов, уникален индекс само в колоната ID (което го прави „излишен“ с клъстерирания индекс, нали?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
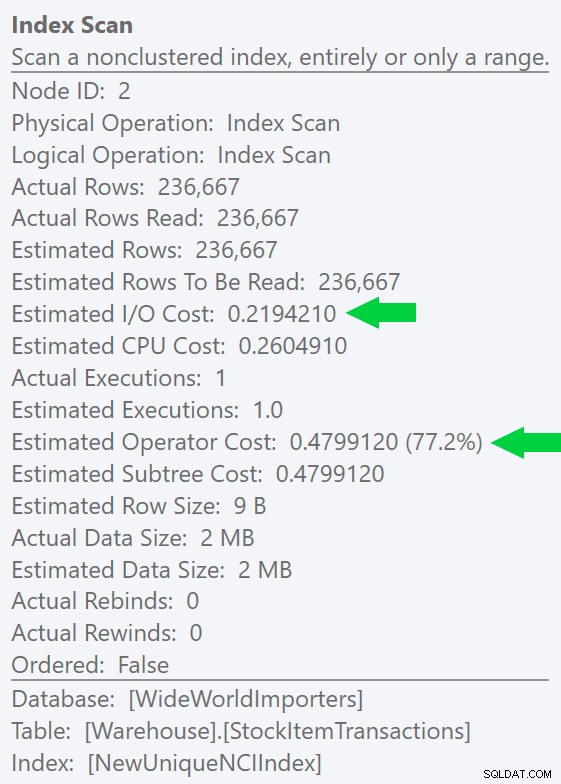 Изпълнението на подобна заявка с изричен намек за индекс произвежда същата форма на плана, но дори по-ниска прогнозирана I/O цена (и дори по-ниска продължителност) – вижте изображението вдясно. И ако изпълните оригиналната заявка без намек, ще видите, че SQL Server вече избира и този индекс.
Изпълнението на подобна заявка с изричен намек за индекс произвежда същата форма на плана, но дори по-ниска прогнозирана I/O цена (и дори по-ниска продължителност) – вижте изображението вдясно. И ако изпълните оригиналната заявка без намек, ще видите, че SQL Server вече избира и този индекс.
Може да изглежда очевидно, но много хора биха повярвали, че клъстерираният индекс е най-добрият избор тук. SQL Server почти винаги ще предпочита метода, който ще осигури най-евтиния начин за извършване на цялото I/O, а в случай на пълно сканиране, това ще бъде най-слабият индекс. Това може да се случи и при двата типа търсения (единично и диапазонно сканиране), поне когато индексът покрива.
Сега, както винаги, това не по някакъв начин означава, че трябва да отидете и да създадете допълнителни индекси за всичките си таблици, за да удовлетворите заявките за броене. Това не само е неефективен начин за проверка на размера на таблицата (отново вижте тази статия), но и индекс за поддръжка, който би трябвало да означава, че изпълнявате тази заявка по-често, отколкото актуализирате данните. Не забравяйте, че всеки индекс изисква място на диска, място в паметта и всички записи в таблицата трябва също да докосват всеки индекс (филтрираните индекси настрана).
Резюме
Бих могъл да измисля много други примери, които показват кога неклъстериран може да бъде полезен и да си струва разходите за поддръжка, дори когато се дублират ключовите колони на клъстерирания индекс. Неклъстерираните индекси могат да бъдат създадени със същите ключови колони, но в различен ключов ред, или с различен ASC/DESC на самите колони, за да поддържат по-добре алтернативен ред на представяне. Можете също да имате неклъстерирани индекси, които носят само малка подмножество от редове чрез използването на филтър. И накрая, ако можете да удовлетворите най-често срещаните си заявки с по-слаби, неклъстерирани индекси, това е по-добре и за консумация на памет.
Но всъщност моята цел на тази поредица е просто да покажа контрапример, който илюстрира глупостта да се правят общи изявления като това. Ще ви оставя с обяснение от Пол Уайт, който в отговор на DBA.SE обяснява защо такъв неклъстериран индекс всъщност може да работи много по-добре от клъстериран индекс. Това е вярно дори когато и двете използват всеки тип търсене:
- Разлика между клъстерирано търсене на индекс и неклъстерирано търсене на индекс