Репликацията на MariaDB е едно от най-популярните решения с висока наличност за MariaDB и се използва широко от водещи компании като Booking.com и Google. Много е лесно да се настрои, с някои компромиси с текущата поддръжка, като надстройки на софтуера, промени в схемата, промени в топологията, преминаване при отказ и възстановяване, които винаги са били трудни. Независимо от това, с правилния набор от инструменти, трябва да можете да се справяте с топологията с лекота. В тази публикация в блога ще разгледаме някои съвети за ефективно наблюдение на репликацията на MariaDB с помощта на ClusterControl.
Използване на инструмента за преглед на топология
Настройката за репликация се състои от няколко роли. Възел в настройката за репликация може да бъде:
- Master – Основният писател/четец.
- Главно резервно копие – Подчинено устройство само за четене с полусинхронизирана репликация, единствено за резервиране на главния.
- Междинен главен – Репликация от главен, докато други подчинени устройства се репликират от този възел.
- Binlog сървър – Събира/съхранява само binlogs, без да обслужва данни.
- Slave – Репликация от главен и обикновено се задава като само за четене.
- Подчинен с множество източници – Репликация от множество главни.
Всяка роля има своя собствена отговорност и ограничение и човек трябва да разбере правилната топология, когато работи с възлите на базата данни. Това важи и за приложението, където приложението трябва да пише само до главния възел във всеки даден момент. По този начин е важно да имаме общ поглед върху това кой възел каква роля изпълнява, за да не прецакаме нашата база данни.
В ClusterControl, Topology Viewer може да ви даде общ преглед на топологията на репликация и нейното състояние, както е показано на следната екранна снимка:
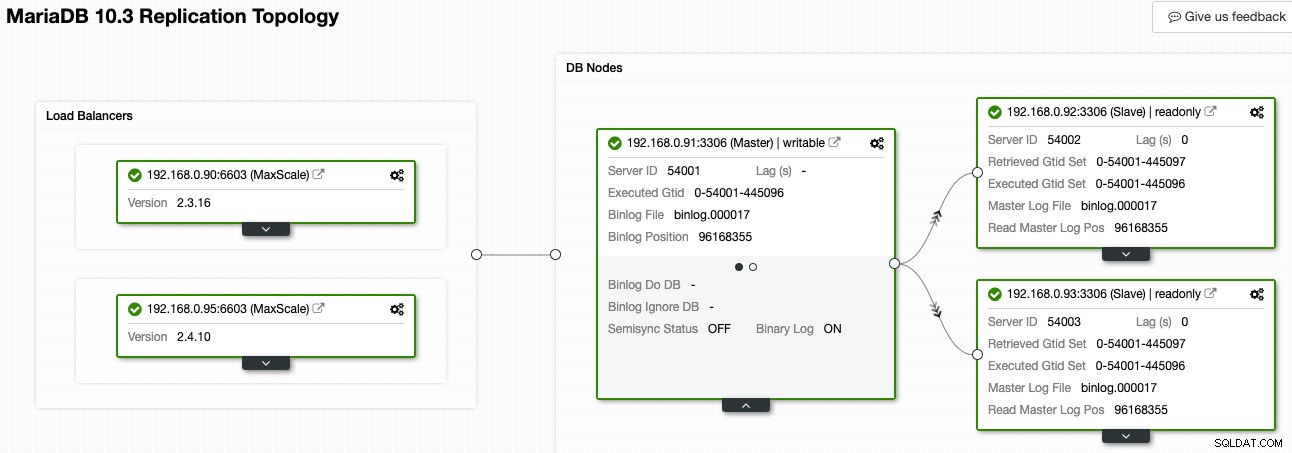
ClusterControl разбира репликацията на MariaDB и е в състояние да визуализира топологията с правилния поток от данни за репликация, както е представено от стрелките, насочени към подчинените възли. Можем лесно да различим кой възел е главен, подчинен и балансьор на натоварване (MaxScale) в нашата настройка за репликация. Зеленото поле показва, че всички важни услуги работят според очакванията с присвоената роля.
Помислете за следната екранна снимка, където редица от нашите възли имат проблеми:
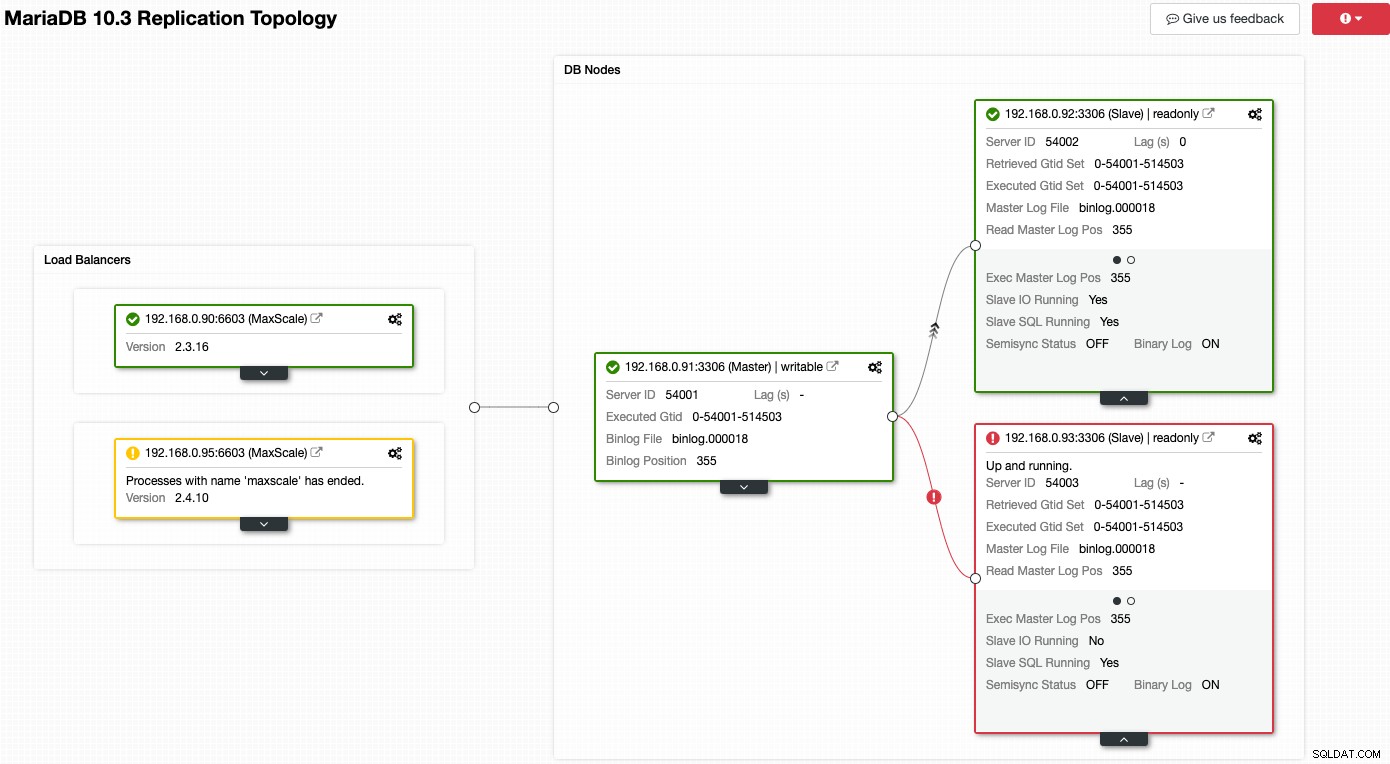
ClusterControl веднага ще ви каже какво не е наред с текущата топология. Един от подчинените (червено поле) показва "Slave IO Running" като Не, за да посочи някакъв проблем със свързаността, който да се репликира от главния. Докато жълтото поле показва, че нашата услуга MaxScale не работи. Можем също да кажем, че версиите на MaxScale не са идентични и за двата възела. Можете също да изпълнявате задачи за управление, като щракнете директно върху иконата на зъбно колело (горе вдясно във всяко поле), което намалява рисковете от вдигане на грешен възел.
Закъснение при репликация
Това е най-важното нещо, ако разчитате на последователността на репликацията на данни. Закъснение при репликация възниква, когато подчинените не могат да се справят с актуализациите, случващи се на главния. Неприложените промени се натрупват в релейните регистри на подчинените и версията на базата данни на подчинените става все по-различна от основната.
В ClusterControl можете да намерите хистограмата на забавяне на репликацията под Общ преглед -> Закъснение на репликация, където ClusterControl постоянно взема проби за стойността Seconds_Behind_Master от изхода "SHOW SLAVE STATUS":
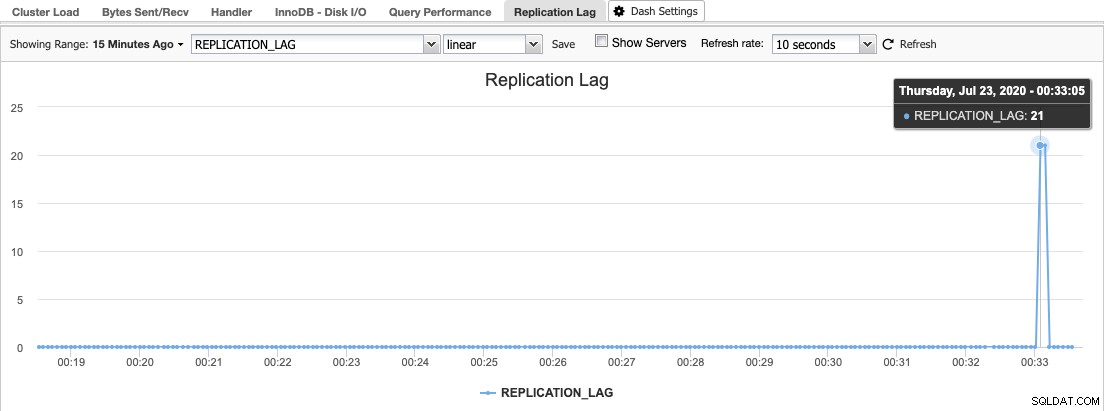
Закъснение при репликация се случва, когато или I/O нишката, или SQL нишката не могат да се справят с изискванията, поставени пред нея. Ако I/O Thread страда, това означава, че мрежовата връзка между главния и неговите подчинени е бавна или има проблеми. Може да помислите да разрешите на slave_compressed_protocol да компресира мрежовия трафик или да докладвате на вашия мрежов администратор.
Ако това е SQL нишката, тогава проблемът вероятно се дължи на лошо оптимизирани заявки, които отнемат на подчинения твърде много време за прилагане. Възможно е да има продължителни транзакции или твърде много I/O активност. Липсата на първичен ключ в подчинените таблици при използване на формат за репликация ROW или MIXED също е често срещана причина за изоставане в тази нишка. Проверете дали главната и подчинената версии на таблиците имат първичен ключ.
Още някои съвети и трикове са обхванати в тази публикация в блога, Как да намалите забавянето на репликацията при многооблачни внедрявания.
Размер на двоичен/релейен регистрационен файл
Важно е да наблюдавате размера на диска с двоични и релейни регистрационни файлове, тъй като той може да консумира значително количество място за съхранение на всеки възел в клъстер за репликация. Обикновено човек би настроил системната променлива expire_logs_days да изтича автоматично двоичните регистрационни файлове след определен брой дни, например expire_logs_days=7. Размерът на двоичните регистрационни файлове зависи изцяло от броя на създадените двоични събития (входящи записи) и малко, че знаем колко дисково пространство ще заеме, преди регистрационните файлове да изтекат от MariaDB. Имайте предвид, че ако активирате log_slave_updates на подчинените, размерът на регистрационните файлове ще бъде почти удвоен поради съществуването както на двоични, така и на релейни регистрационни файлове на един и същ сървър.
За ClusterControl можем да зададем праг за използване на дисковото пространство под ClusterControl -> Настройки -> Прагове, за да получим предупреждение и критични известия, както е посочено по-долу:
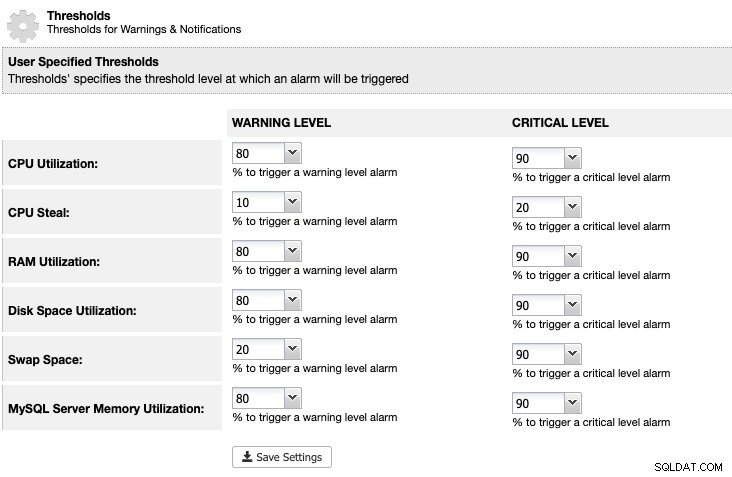
ClusterControl наблюдава цялото дисково пространство, свързано с услугите на MariaDB, като местоположението на данните на MariaDB директория, директорията с двоични регистрационни файлове, както и основния дял. Ако сте достигнали прага, помислете за ръчно изчистване на двоичните регистрационни файлове, като използвате командата PURGE BINARY LOGS, както е обяснено и обсъдено в тази статия.
Активиране на таблата за наблюдение
ClusterControl предоставя две опции за наблюдение за вземане на проби от възлите на базата данни - без агент или базиран на агент. По подразбиране е без агент, когато извадката се случва чрез SSH в механизъм само за изтегляне. Мониторингът, базиран на агенти, изисква сървър Prometheus да работи и всички наблюдавани възли да бъдат конфигурирани с най-малко три експортера:
- Износител на процеси (порт 9011)
- Експортиране на показатели за възел/система (порт 9100)
- MySQL/MariaDB експортер (порт 9104)
За да активирате таблото за мониторинг, базирано на агенти, трябва да отидете на ClusterControl -> Dashboards -> Enable Agent Based Monitoring. Веднъж активирани, ще видите набор от табла за управление, конфигурирани за нашата репликация на MariaDB, което ни дава много по-добра представа за нашата настройка за репликация. Следната екранна снимка показва какво ще видите за главния възел:
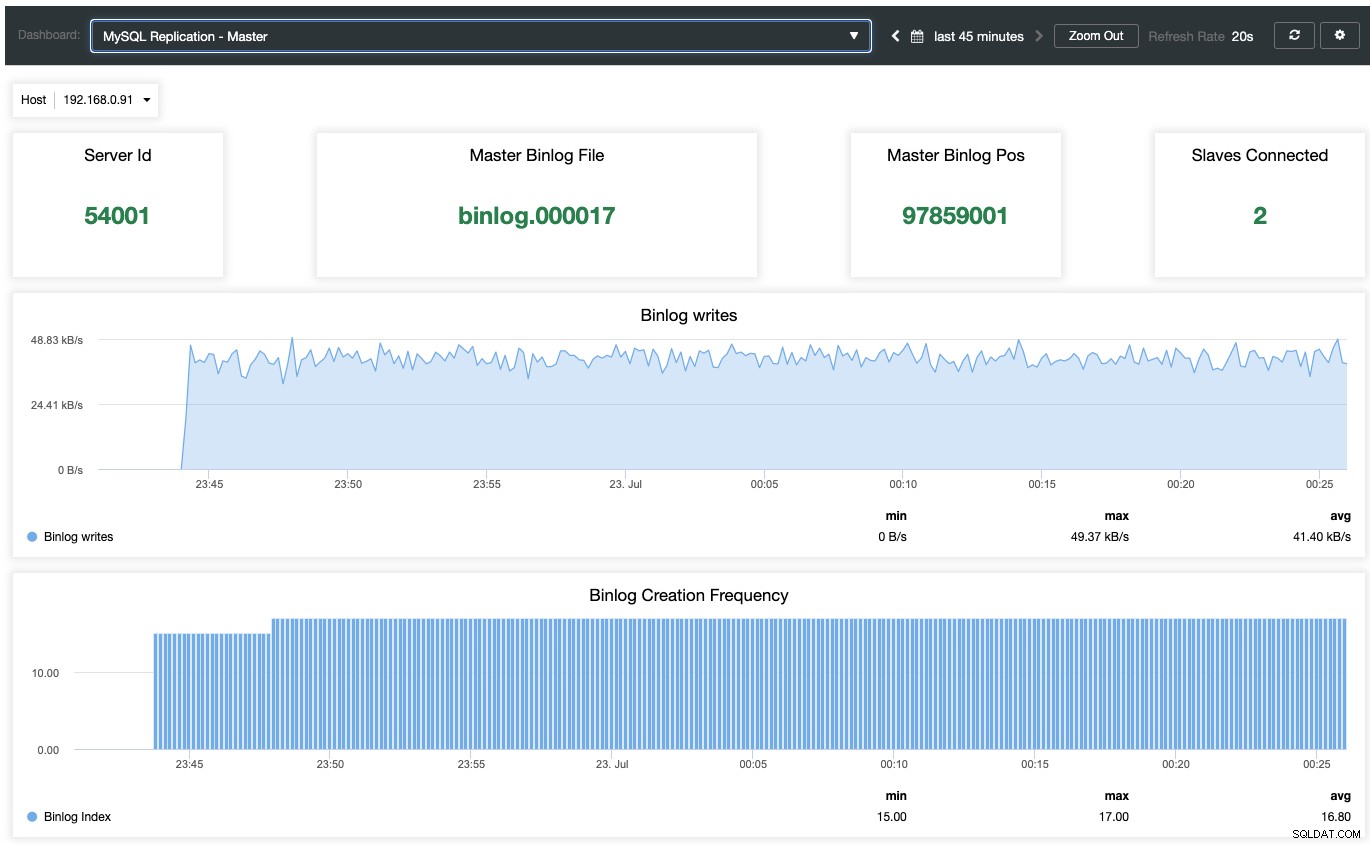
Освен стандартните табла за наблюдение на MariaDB като общи, кешове и метрики на InnoDB, вие ще бъде представен с репликационно табло. За главния възел можем да получим много полезна информация относно състоянието на главния, пропускателната способност на запис и честотата на създаване на binlog.
Докато за подчинените, всички важни състояния са извадени и обобщени като следната екранна снимка. ако всичко е зелено, вие сте в добри ръце:
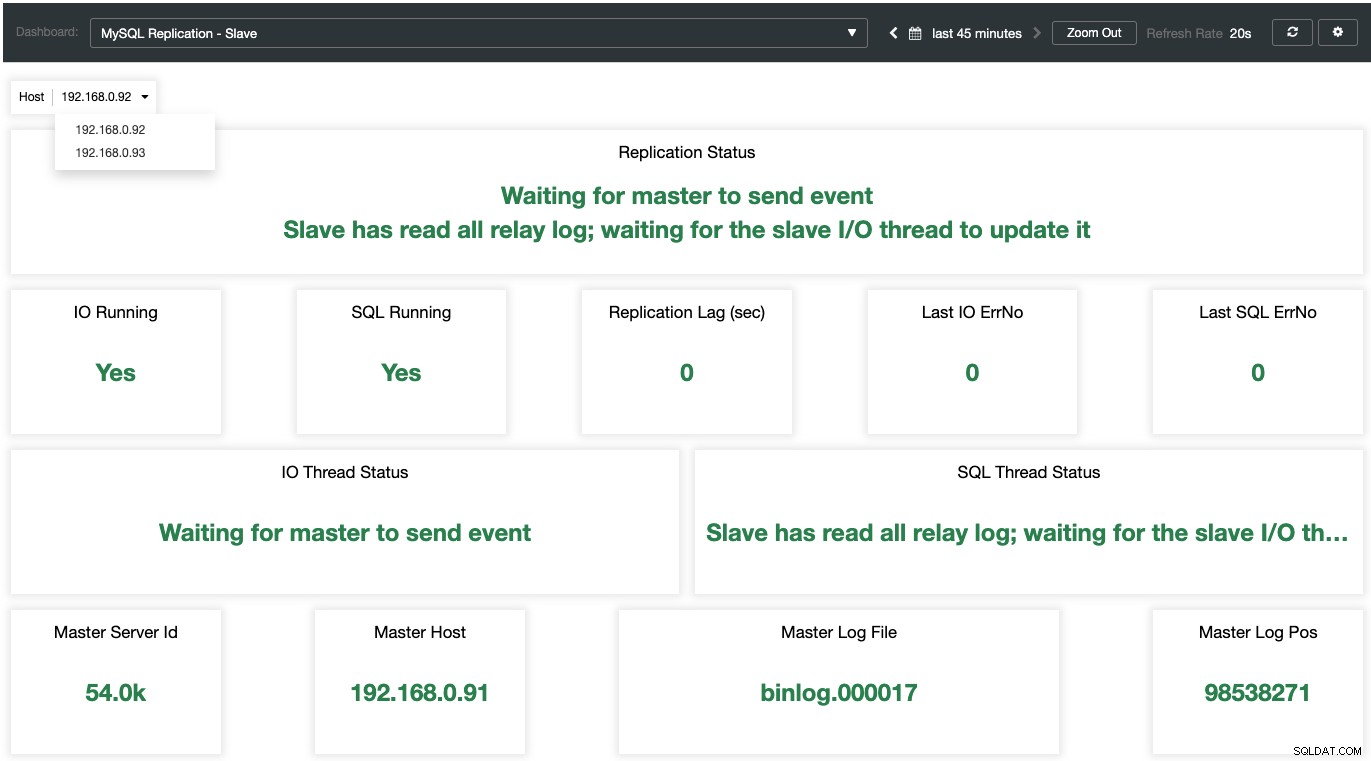
Разбиране на журнала за грешки в MariaDB
MariaDB регистрира своите важни събития в регистъра за грешки, което е полезно, за да разберете какво се е случвало със сървъра, особено преди, по време и след промяна на топологията. ClusterControl предоставя централизиран изглед на регистрационните файлове за грешки под ClusterControl -> Logs -> System Logs, като ги изтегля от всеки възел на базата данни. Щракнете върху „Обновяване на регистрационните файлове“, за да задействате задание за изтегляне на най-новите регистрационни файлове от сървъра.
Събраните файлове са представени в структура на навигационно дърво и текстова област с подчертаване на синтаксиса за по-добра четливост:
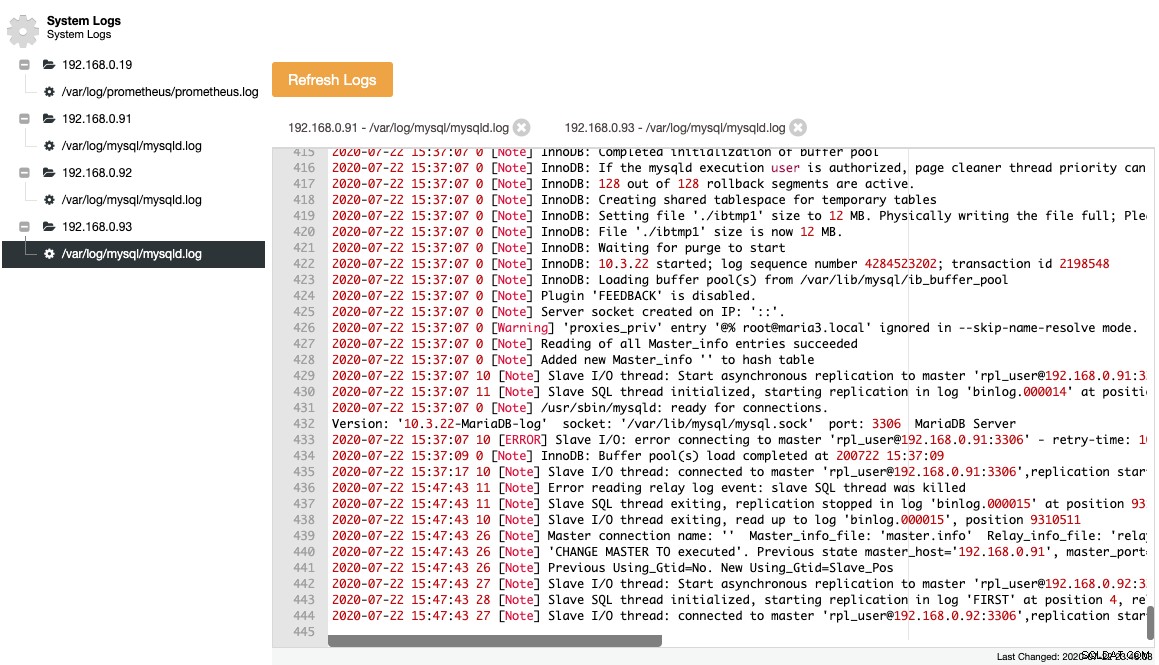
От горната екранна снимка можем да разберем последователността от събития и какво се е случило с този възел по време на събитие за промяна на топологията. От последните 12 реда на дневника за грешки по-горе, подчиненият има грешка, след като се свърже с главния и последният двоичен регистрационен файл и позиция бяха записани в дневника, преди да спре. След това беше изпълнена по-нова команда CHANGE MASTER с информация за GTID, както е показано в реда „Previous Using_Gtid=No. New Using_Gtid=Slave_Pos“ и след това репликацията се възобновява, както искахме.
Сигнали и известия за MariaDB
Наблюдението е непълно без сигнали и известия. Всички събития и аларми, генерирани от ClusterControl, могат да бъдат изпращани на имейл или други поддържани инструменти на трети страни. За известия по имейл можете да конфигурирате дали типът на събитията ще бъде доставен незабавно, игнориран или усвоен (ежедневен обобщен отчет):

За всички събития с критична тежест се препоръчва да зададете всичко на „Достави“, така че да получавате известията възможно най-скоро. Задайте „Дайджест“ на предупредителни събития, за да сте добре наясно със здравето и състоянието на клъстера.
Можете да интегрирате предпочитаните от вас инструменти за комуникация и съобщения с ClusterControl, като използвате функцията за управление на известията под ClusterControl -> Интеграции -> Известия на трети страни. ClusterControl може да изпраща аларми и събития до PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow или всеки регистриран потребител за уеб кукички.
Следната екранна снимка показва, че всички критични събития ще бъдат пренасочени към конфигурирания телеграм канал за нашия MariaDB 10.3 репликационен клъстер:

ClusterControl също така поддържа интеграция на чатбот, където можете да взаимодействате с услугата на контролера чрез s9s клиент направо от вашия инструмент за съобщения, както е показано в тази публикация в блога, Автоматизиране на вашата база данни с CCBot:ClusterControl Hubot Integration.
Заключение
ClusterControl предлага пълен набор от инструменти за проактивно наблюдение за клъстерите на вашите бази данни. Използвайте ClusterControl, за да наблюдавате вашата настройка за репликация на MariaDB, защото повечето от функциите за наблюдение са достъпни безплатно в изданието на общността. Не ги пропускайте!