Този месец T-SQL вторник се води от Майк Донъли (@SQLMD) и той обобщава темата по следния начин:
Темата този месец е директна, но много отворена. Трябва да научите нещо ново и след това да напишете публикация в блог, обясняваща го.Е, от момента, в който Майк обяви темата, аз всъщност нямах намерение да научавам нищо ново и тъй като уикендът наближаваше и знаех, че понеделник ще ме нападне със съдебни заседатели, реших, че ще трябва да седна това месец.
Тогава Мартин Смит ме научи на нещо, което или никога не съм знаел, или знаех отдавна, но съм забравил (понякога не знаеш какво не знаеш, а понякога не можеш да си спомниш какво никога не знаеш и какво не можеш помня). Споменът ми беше, че промяната на колона от NOT NULL до NULL трябва да бъде операция само с метаданни, като записите към всяка страница се отлагат, докато тази страница не бъде актуализирана по други причини, тъй като NULL растерното изображение не би трябвало да съществува, докато поне един ред не стане NULL .
В същата публикация @ypercube също ми напомни за този уместен цитат от Books Online (печатна грешка и всичко останало):
Промяната на колона от NOT NULL на NULL не се поддържа като онлайн операция, когато променената колона е препратка от неклъстерирани индекси.„Не е онлайн операция“ може да се тълкува като „операция, която не включва само метаданни“ – което означава, че всъщност ще бъде операция с размер на данни (колкото по-голям е вашият индекс, толкова повече време ще отнеме).
Зададох се да докажа това с доста прост (но продължителен) експеримент срещу конкретна целева колона за конвертиране от NOT NULL до NULL . Бих създал 3 таблици, всички с клъстериран първичен ключ, но всяка с различен неклъстериран индекс. Единият ще има целевата колона като ключова колона, а вторият като INCLUDE колона, а третата изобщо няма да се позовава на целевата колона.
Ето моите таблици и как ги попълних:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Всяка таблица имаше 100 000 реда, клъстерираните индекси имаха 310 страници, а неклъстерираните индекси имаха или 272 страници (test1 и test2 ) или 174 страници (test3 ). (Тези стойности са лесни за получаване от sys.dm_db_index_physical_stats .)
След това имах нужда от прост начин за заснемане на операции, които бяха регистрирани на ниво страница – избрах sys.fn_dblog() , въпреки че можех да разровя по-дълбоко и да гледам страниците директно. Не си направих труда да се забърквам със стойностите на LSN, за да предам на функцията, тъй като не изпълнявах това в производството и не се интересувах много от производителността, така че след тестовете просто изхвърлих резултатите от функцията, изключвайки всички данни, които е регистриран преди ALTER TABLE операции.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Сега можех да пусна тестовете си, които бяха много по-прости от настройката.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Сега можех да разгледам операциите, които бяха регистрирани във всеки случай:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Резултатите изглежда предполагат, че всяка листова страница на неклъстерирания индекс се докосва за случаите, когато целевата колона е била спомената в индекса по какъвто и да е начин, но не се извършват такива операции в случаите, когато целевата колона не е спомената в никакъв неклъстериран индекс:
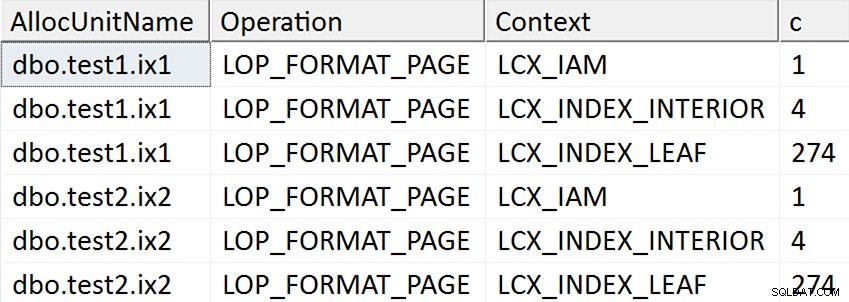
Всъщност в първите два случая се разпределят нови страници (можете да потвърдите това с DBCC IND , както направи Spörri в своя отговор), така че операцията може да се извърши онлайн, но това не означава, че е бърза (тъй като все пак трябва да изпише копие на всички тези данни и да направи NULL промяна на растерното изображение като част от изписването на всяка нова страница и регистрирайте цялата тази дейност).
Мисля, че повечето хора биха заподозрели, че промяната на колона от NOT NULL до NULL ще бъде само с метаданни във всички сценарии, но тук показах, че това не е вярно, ако колоната е посочена от неклъстериран индекс (и подобни неща се случват независимо дали е ключ или INCLUDE колона). Може би тази операция може също да бъде принудена да бъде ONLINE в Azure SQL база данни днес, или ще бъде възможно в следващата основна версия? Това няма непременно да направи действителните физически операции по-бързи, но ще предотврати блокирането в резултат.
Не тествах този сценарий (а анализът дали наистина е онлайн е по-труден в Azure така или иначе), нито го тествах на купчина. Нещо, което мога да преразгледам в бъдеща публикация. Междувременно внимавайте с всякакви предположения, които може да направите за операции само с метаданни.