Greenplum Database е SQL база данни с масивна паралелна обработка (MPP), която е изградена и базирана на PostgreSQL. Той може да се мащабира към натоварване на данни на ниво от няколко петабайта без нито един проблем и позволява достъп до клъстер от мощни сървъри, които ще работят заедно в рамките на един SQL интерфейс, където можете да преглеждате всички данни. В тази публикация в блога обясняваме какво представлява Greenplum и разбиваме архитектурата на Greenplum, предимствата, основните случаи на употреба и как да започнете.
Какво точно е Greenplum?
Greenplum Database е MPP база данни с отворен код, независима от хардуера за анализ, базирана на PostgreSQL и разработена от Pivotal, която по-късно беше придобита от VMware. Архитектурата му е специално проектирана за управление на широкомащабни складове за данни и работни натоварвания на бизнес разузнаване, като ви дава възможност да разпространявате данните си в множество сървъри.
Тази пълна с функции база данни предоставя мощни и бързи анализи на данни, които се увеличават до петабайтови обеми.
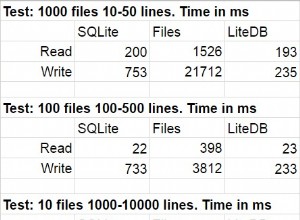
С един поглед – TLDR | ||||||
|---|---|---|---|---|---|---|
|



Архитектурата на Greenplum
За да разберем добре архитектурата на Greenplum, нека първо да разгледаме какво представлява MPP база данни.
Какво е MPP база данни?
Когато боравите с големи количества сложни данни или големи данни, има вероятност основната ви машина да започне да се смачква от всички данни, които трябва да обработи, за да произведе вашите анализи резултати. За да запълнят тази нужда от по-бърза обработка и да позволят по-бързи резултати, много организации обмислят приемането на MPP база данни.
Системата MPP използва архитектура без споделено нищо, за да обработва множество операции паралелно. Той използва няколко различни процесорни единици, които работят независимо, използвайки собствената си специална памет и ресурси, така че натоварването се споделя между множество устройства, вместо само на едно. Обикновено MPP система има един водещ възел и един или много изчислителни възли. Водещият възел, наречен „главен“ в Greenplum, казва на всички останали възли, наречени сегменти в Greenplum, какво да правят и обединява техните отговори, за да създаде окончателния отговор.
MPP бази данни мащабира хоризонтално чрез добавяне на повече изчислителни ресурси (възли), вместо да се налага да се притеснявате за надграждане до все по-скъпи отделни сървъри (вертикално мащабиране).
Архитектурен дизайн на Greenplum
Въз основа на архитектурата на PostgreSQL, Greenplum по същество използва няколко екземпляра на PostgreSQL база данни наведнъж в един единствен Greenplum клъстер. Потребителите на PostgreSQL могат бързо да се запознаят с този тип база данни, тъй като много от функциите, конфигурациите и функционалността са едни и същи в Greenplum и включва функции, предназначени да оптимизират как работи PostgreSQL за задачи и работни натоварвания на бизнес разузнаване (BI).
Greenplum също така въведе много функции, които не са налични в PostgreSQL, като паралелно зареждане на данни, управление на ресурси, подобрения в съхранението и разширена оптимизация на заявките, което го прави привлекателно предложение, когато сравнявате две.
Подобно на PostgreSQL, Greenplum използва един главен сървър или хост, който е входна точка към базата данни, приема връзки и SQL заявки. Въпреки това, когато PostgreSQL използва резервни възли за географско разпространение на тяхното внедряване, Greenplum използва сегментни хостове, които съхраняват и обработват данните. Сегментите на Greenplum са независими и всеки съхранява част от данните, въпреки че обработва по-голямата част от обработката на заявката. Можете да използвате само два сегментни хоста и да мащабирате до неограничен капацитет. Ако сте активирали дублирането, трябва да увеличите хостовете на сегментите на стъпки от поне две.
И така, как е координирано всичко това? Взаимното свързване на Greenplum е мрежовият слой на архитектурата и управлява комуникацията между сегментите на Greenplum и инфраструктурата на основната хост мрежа.

Предимства на Greenplum
Ето някои от ключовите предимства на Greenplum, които могат да ви помогнат да подобрите производителността на вашата база данни:
-
Висока производителност
Greenplum има уникално проектиран тръбопровод за данни, който може ефективно да предава данни от диска към процесора, без да разчита на данните, които се вписват в RAM паметта, както е обяснено в техния Greenplum Next Generation Big Платформа за данни:статия за топ 5 причини. Това осигурява на внедряванията на Greenplum огромно увеличение на производителността спрямо системите в паметта, които се нуждаят от достатъчно памет, за да съхраняват своите данни, или системи, които не са базирани на RDBMS, които са машини за обработка в паметта, които разпределят RAM за всяка едновременна заявка. Високата производителност на Greenplum елиминира предизвикателството, с което повечето RDBMS имат мащабиране до петабти нива на данни, тъй като те са в състояние да мащабират линейно, за да обработват ефективно данни.
-
Оптимизиране на заявки
Greenplum разполага с базиран на разходи оптимизатор на заявки за мащабни натоварвания с големи данни. Използвайки производителността, както разгледахме по-горе, Greenplum мащабира интерактивните и пакетни анализи до петабайтов мащаб, без да влошава производителността на вашата заявка. Това позволява на Greenplum да разпределя натоварването между различните си сегменти и да използва всички ресурси на системата паралелно за обработка на заявка.
Освен това, с подобренията на натоварването на OLTP (онлайн транзакционна обработка) в Greenplum 6, производителността на единична заявка се подобри с 3,5c спрямо Greenplum 5. С тази актуализация Greenplum елиминира много от заключете конкуренцията, така че използването на главния процесор може да надхвърли 90%, което подобрява производителността на заявката чрез подобряване на хардуерната производителност на главния възел.
-
Отворен код
База данни Greenplum е проект за съхранение на данни с отворен код, базиран на ядрото с отворен код на PostgreSQL, което позволява на потребителите да се възползват от десетилетията на експертно развитие зад PostgreSQL, заедно с целенасоченото персонализиране на Greenplum за приложения за големи данни. Greenplum може да работи на всеки Linux сървър, независимо дали се хоства в облака или на място, и може да работи във всяка среда.
Докато Greenplum се поддържа от основен екип от разработчици с права на ангажимент към основното хранилище, те с нетърпение приветстват нови сътрудници, които имат опит с базата данни, за да помогнат за оформянето на бъдещето на Greenplum. Научете повече за участието чрез страницата на Greenplum GitHub.
-
Полиморфно съхранение на данни
Полиморфното съхранение на данни на Greenplum ви позволява да контролирате конфигурацията за вашата таблица и съхранение на дялове със свободата да изпълнявате и компресирате файлове в нея по всяко време. Това ще ви позволи да проектирате вашите таблици въз основа на начина, по който се осъществява достъп до вашите специфични данни и от своя страна да имате йерархия за съхранение, ориентирана към редове или колони.
Когато създавате таблица в Greenplum, можете да контролирате ориентацията с възможността да избирате или ориентирани към колони, или ориентирани към редове данни. Ориентацията по колона обикновено е по-добра за пълно сканиране, докато ориентираната по ред е по-добра за малки сканирания или търсения.
Greenplum дори ви позволява да създавате специфични за домейна типове данни и функции. Чрез използването на полуструктурирани типове данни, които включват XML, Hstore и JSON, имате възможността да съхранявате и анализирате както структурирани, така и неструктурирани данни в база данни.
Какво представлява Greenplum Database? Въведение в базата данни Big DataClick To TweetОсновни случаи на употреба
Greenplum предоставя мощна комбинация от масивна паралелна обработка на бази данни и усъвършенствани анализи на данни, което му позволява да създаде рамка за учени по данни и архитекти, за да вземат бизнес решения въз основа на данни, събрани от изкуствен интелект и машинно обучение. Нека да преминем през най-добрите случаи на използване на Greenplum:
Анализ
Разширените анализи, предоставени от Greenplum, се използват в много вертикали, включително финанси, производство, автомобилостроене, правителство, енергетика, образование, търговия на дребно и т.н., за да се справят с голямо разнообразие на проблеми. Някои от възможностите за анализ на базата данни на Greenplum, подчертани от Pivotal, включват способността да се анализират множество типове данни, да се използват съществуващите SQL знания и да се обучават повече модели за по-малко време чрез използване на MPP архитектура.
Освен това Greenplum предоставя анализи в базата данни, които ви позволяват да изпълнявате анализи директно в базата данни спрямо експортиране и изпълнение на вашите данни във външна машина за анализ. Като база данни, съобразена с работните натоварвания на предприятието, това осигурява възможността, необходима за изследване на големи набори от данни, заедно с високата производителност, постигната чрез паралелиране на анализите във вашите налични хостове на сегменти. Можете също така да използвате широк набор от инструменти за анализ на мощността с Greenplum, включително MADlib, R статистически език, SAS и език за маркиране за предсказуемо моделиране (PMML).
Например, компания за интернет маркетинг в размер на милиард долара използва усъвършенствани анализи на Greenplum, за да извършва профилиране на аудиторията, за да разбере коя е тяхната аудитория, какво купуват, кои мрежи и устройства използват, и къде се намират географски, за да могат по-добре да разбират и обслужват своя пазар.
Машинно обучение
Greenplum е отлична база данни за машинно обучение – изучаването на компютърни алгоритми, които се подобряват автоматично чрез опит. Apache MADlib е базирана на SQL библиотека за машинно обучение с отворен код, която работи в база данни на Greenplum, както и PostgreSQL. Тази комбинация ви помага да подобрите паралелизма, мащабируемостта и точността на прогнозиране на внедряването на вашето машинно обучение на Greenplum. Възможностите за трансформация на данни и инженеринг на функции също са достъпни чрез MADlib за машинно обучение, включително описателна и изводна статистика, завъртане, сесия и кодиране на категорични променливи.
Например, правителствена компания за задържане на приходи от измами използва възможностите за машинно обучение на Greenplum заедно с GemFire, за да извършва широкомащабно откриване на измами за предотвратяване на кражба на самоличност, откриване и задържане на $5B годишно и обработка 8 милиона случая на ден.
AI
Изкуственият интелект (AI), макар и подобен на машинното обучение, се отнася до по-широката идея, при която машините могат да изпълняват задачи интелигентно. Greenplum е чудесен избор за база данни за приложения, които искат да имитират човешките способности чрез интелигентни машини. Със способността на Greenplum да поглъща големи обеми данни с висока скорост, това прави тази база данни мощен инструмент за интелигентни приложения, които трябва да взаимодействат интелигентно въз основа на неограничен брой уникални сценарии.
Например, телекомуникационна компания използва възможности за изкуствен интелект на базата данни на Greenplum за интелигентните сензори на своята IoT оперативна система за отчитане, за да анализира и изпълнява събития, използвани за поддръжка, сигурност и оперативна ефективност.
Кой използва Greenplum днес? Клиентите на Greenplum включват American Express, Walmart, Asurian, Bank of America и много други в банковите, професионалните услуги, медиите, застраховането, здравеопазването, автомобилостроенето и пазарите на дребно.
Как да започнете
Както споменахме в тази публикация, Greenplum е база данни с отворен код, така че версията на общността е абсолютно безплатна за изтегляне и използване. Малката, но активна общност на Greenplum приветства нови сътрудници, приема обратна връзка и си сътрудничи с евангелистите на Greenplum за популяризиране на базата данни с големи данни.
Много организации, които използват Greenplum, търсят допълнителна поддръжка и инструменти, за да помогнат на техните администратори на база данни да управляват внедряванията си. Ето двете различни опции за управление и поддръжка на база данни, налични за Greenplum:
ScaleGrid за Greenplum® база данни – версия с отворен код
ScaleGrid за Greenplum® Database е напълно управлявано решение за версията с отворен код на Greenplum, която стартира през май 2020 г. Многооблачната платформа ви позволява да разгръщате и управлявате в AWS, Облачни платформи Azure или Google Cloud (скоро) или локални среди на VMware. ScaleGrid предоставя на потребителите на Greenplum усъвършенстваните инструменти за управление, от които се нуждаят за внедряване с едно щракване, автоматизиране на архивиране и динамично мащабиране с възможността да поддържат пълни администраторски привилегии на супер потребители спрямо внедряванията им с отворен код.
Pivotal Greenplum – търговска версия
Pivotal Greenplum, сега VMware Tanzu е създателят зад базата данни с отворен код, която предлага комерсиална версия на базата данни, за да ви помогне да внедрите и управлявате Greenplum в облака и на място. Pivotal Greenplum предлага много предимства, като например възможността за максимизиране на времето на работа, защита на целостта на данните и обработка на поточни данни и облачни данни с лекота.
И ScaleGrid, и Pivotal Greenplum предлагат разширени пакети за поддръжка, за да помогнат на вашия DBA да оптимизират своите внедрявания на Greenplum.