Миналото лято, след като SP2 за SQL Server 2014 беше пуснат, писах за използването на DBCC CLONEDATABASE за повече от просто разследване на проблем с производителността на заявката. Скорошен коментар към публикацията от читател ме накара да се замисля, че трябва да разширя какво имах предвид как да използвам клонираната база данни за тестване. Петър написа:
„Основно съм разработчик на C# и докато пиша и се занимавам с T-SQL през цялото време, когато става въпрос за надхвърляне на този SQL Server (почти всички DBA неща, статистика и други подобни), всъщност не знам много . Дори не знам как бих използвал клонирана DB като тази за настройка на производителността”Е, Питър, ето. Надявам се това да помогне!
Настройка
DBCC CLONEDATABASE беше наличен в SQL Server 2016 SP1, така че това ще използваме за тестване, тъй като е текущата версия и защото мога да използвам Query Store, за да заснема данните си. За да улесня живота, създавам база данни за тестване, вместо да възстановявам проба от Microsoft.
USE [master]; GO DROP DATABASE IF EXISTS [CustomerDB], [CustomerDB_CLONE]; GO /* Change file locations as appropriate */ CREATE DATABASE [CustomerDB] ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 512MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 512MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE;
Сега създайте таблица и добавете малко данни:
USE [CustomerDB];
GO
CREATE TABLE [dbo].[Customers]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID])
);
GO
/*
This adds 1,000,000 rows to the table; feel free to add less
*/
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO
CREATE NONCLUSTERED INDEX [PhoneBook_Customers]
ON [dbo].[Customers]([LastName],[FirstName])
INCLUDE ([EMail]); Сега ще активираме хранилището на заявки:
USE [master]; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200);
След като създадем и попълним базата данни и сме конфигурирали хранилището на заявки, ще създадем съхранена процедура за тестване:
USE [CustomerDB];
GO
DROP PROCEDURE IF EXISTS [dbo].[usp_GetCustomerInfo];
GO
CREATE OR ALTER PROCEDURE [dbo].[usp_GetCustomerInfo] (@LastName [nvarchar](64))
AS
SELECT
[CustomerID],
[FirstName],
[LastName],
[Email],
CASE WHEN [Active] = 1 THEN 'Active'
ELSE 'Inactive' END [Status]
FROM [dbo].[Customers]
WHERE [LastName] = @LastName; Обърнете внимание:използвах страхотния нов синтаксис CREATE OR ALTER PROCEDURE, който е наличен в SP1.
Ще стартираме нашата съхранена процедура няколко пъти, за да получим някои данни в хранилището на заявки. Добавих WITH RECOMPILE, защото знам, че тези две входни стойности ще генерират различни планове и искам да се уверя, че ги заснема и двата.
EXEC [dbo].[usp_GetCustomerInfo] 'name' WITH RECOMPILE; GO EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;
Ако погледнем в хранилището на заявки, виждаме една заявка от нашата съхранена процедура и два различни плана (всеки със собствен план_id). Ако това беше производствена среда, щяхме да имаме значително повече данни по отношение на статистиката по време на изпълнение (продължителност, IO, информация за процесора) и повече изпълнения. Въпреки че нашата демонстрация има по-малко данни, теорията е същата.
SELECT [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], DATEADD(MINUTE, -(DATEDIFF(MINUTE, GETDATE(), GETUTCDATE())), [qsp].[last_execution_time]) AS [LocalLastExecutionTime], [qst].[query_sql_text], ConvertedPlan = TRY_CONVERT(XML, [qsp].[query_plan]) FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE [qsq].[object_id] = OBJECT_ID(N'usp_GetCustomerInfo');
 Заявка Съхраняване на данни от съхранена процедура заявка Запитване Съхраняване на данни след изпълнение на съхранена процедура (query_id =1) с два различни плана (plan_id =1, plan_id =2)
Заявка Съхраняване на данни от съхранена процедура заявка Запитване Съхраняване на данни след изпълнение на съхранена процедура (query_id =1) с два различни плана (plan_id =1, plan_id =2)
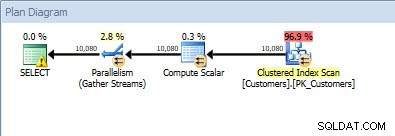 План на заявката за plan_id =1 (входна стойност ='name')
План на заявката за plan_id =1 (входна стойност ='name') 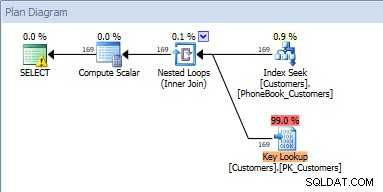 План за заявка за plan_id =2 (входна стойност ='query_cost')
План за заявка за plan_id =2 (входна стойност ='query_cost') След като имаме необходимата информация в Query Store, можем да клонираме базата данни (данните от Query Store ще бъдат включени в клонинга по подразбиране):
DBCC CLONEDATABASE (N'CustomerDB', N'CustomerDB_CLONE');
Както споменах в предишната си публикация за CLONEDATABASE, клонираната база данни е предназначена да се използва за поддръжка на продукти за тестване на проблеми с производителността на заявките. Като такъв, той е само за четене, след като е клониран. Ще надхвърлим това, за което DBCC CLONEDATABASE е предназначена в момента, така че отново искам да ви напомня за тази бележка от документацията на Microsoft:
Новогенерираната база данни, генерирана от DBCC CLONEDATABASE, не се поддържа за използване като производствена база данни и е предназначена основно за отстраняване на неизправности и диагностични цели.За да направя някакви промени за тестване, трябва да извадя базата данни от режим само за четене. И съм ок с това, защото не смятам да използвам това за производствени цели. Ако тази клонирана база данни е в производствена среда, препоръчвам ви да я архивирате и да я възстановите на dev или тестов сървър и да направите вашето тестване там. Не препоръчвам тестване в производството, нито тестване срещу производствения екземпляр (дори и с различна база данни).
/* Make it read write (back it up and restore it somewhere else so you're not working in production) */ ALTER DATABASE [CustomerDB_CLONE] SET READ_WRITE WITH NO_WAIT;
Сега, когато съм в състояние на четене и запис, мога да правя промени, да направя някои тестове и да заснема показатели. Ще започна с проверка, че получавам същия план, който направих преди (напомняне, тук няма да видите никакъв изход, защото няма данни в клонираната база данни):
/* verify we get the same plan */ USE [CustomerDB_CLONE]; GO EXEC [dbo].[usp_GetCustomerInfo] 'name'; GO EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;
При проверка на хранилището на заявки ще видите същата стойност на plan_id като преди. Има множество реда за комбинацията query_id/plan_id поради различните интервали от време, през които данните са били заснети (определени от настройката INTERVAL_LENGTH_MINUTES, която сме задали на 5).
SELECT [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], DATEADD(MINUTE, -(DATEDIFF(MINUTE, GETDATE(), GETUTCDATE())), [qsp].[last_execution_time]) AS [LocalLastExecutionTime], [rsi].[runtime_stats_interval_id], [rsi].[start_time], [rsi].[end_time], [qst].[query_sql_text], ConvertedPlan = TRY_CONVERT(XML, [qsp].[query_plan]) FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] JOIN [sys].[query_store_runtime_stats_interval] [rsi] ON [rs].[runtime_stats_interval_id] = [rsi].[runtime_stats_interval_id] WHERE [qsq].[object_id] = OBJECT_ID(N'usp_GetCustomerInfo'); GO
 Запитване за съхранение на данни след изпълнение на съхранената процедура срещу клонираната база данни
Запитване за съхранение на данни след изпълнение на съхранената процедура срещу клонираната база данни
Тестване на промени в кода
За първия ни тест нека разгледаме как бихме могли да тестваме промяна в нашия код – по-конкретно, ще модифицираме нашата съхранена процедура, за да премахнем колоната [Активна] от списъка SELECT.
/*
Change procedure using CREATE OR ALTER
(remove [Active] from query)
*/
CREATE OR ALTER PROCEDURE [dbo].[usp_GetCustomerInfo] (@LastName [nvarchar](64))
AS
SELECT
[CustomerID],
[FirstName],
[LastName],
[Email]
FROM [dbo].[Customers]
WHERE [LastName] = @LastName; Стартирайте отново съхранената процедура:
EXEC [dbo].[usp_GetCustomerInfo] 'name' WITH RECOMPILE; GO EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;
Ако случайно покажете действителния план за изпълнение, ще забележите, че и двете заявки вече използват един и същ план, тъй като заявката е покрита от неклъстерирания индекс, който създадохме първоначално.
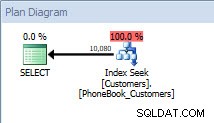 План за изпълнение след промяна на съхранената процедура за премахване на [Active]
План за изпълнение след промяна на съхранената процедура за премахване на [Active]
Можем да потвърдим с Query Store, новият ни план има plan_id от 41:
SELECT [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], DATEADD(MINUTE, -(DATEDIFF(MINUTE, GETDATE(), GETUTCDATE())), [qsp].[last_execution_time]) AS [LocalLastExecutionTime], [rsi].[runtime_stats_interval_id], [rsi].[start_time], [rsi].[end_time], [qst].[query_sql_text], ConvertedPlan = TRY_CONVERT(XML, [qsp].[query_plan]) FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] JOIN [sys].[query_store_runtime_stats_interval] [rsi] ON [rs].[runtime_stats_interval_id] = [rsi].[runtime_stats_interval_id] WHERE [qsq].[object_id] = OBJECT_ID(N'usp_GetCustomerInfo');
 Запитване Съхраняване на данни след промяна на съхранената процедура
Запитване Съхраняване на данни след промяна на съхранената процедура
Тук също ще забележите, че има нов query_id (40). Query Store извършва текстово съвпадение и ние променихме текста на заявката, като по този начин се генерира нов query_id. Също така имайте предвид, че object_id остава същият, тъй като use използва синтаксиса CREATE OR ALTER. Нека направим друга промяна, но използвайте DROP и след това CREATE OR ALTER.
/* Change procedure using DROP and then CREATE OR ALTER (concatenate [FirstName] and [LastName]) */ DROP PROCEDURE IF EXISTS [dbo].[usp_GetCustomerInfo]; GO CREATE OR ALTER PROCEDURE [dbo].[usp_GetCustomerInfo] (@LastName [nvarchar](64)) AS SELECT [CustomerID], RTRIM([FirstName]) + ' ' + RTRIM([LastName]), [Email] FROM [dbo].[Customers] WHERE [LastName] = @LastName;
Сега стартираме отново процедурата:
EXEC [dbo].[usp_GetCustomerInfo] 'name'; GO EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;
Сега изходът от Query Store става по-интересен и имайте предвид, че моят предикат на хранилището на заявки се промени на WHERE [qsq].[object_id] <> 0.
SELECT [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], DATEADD(MINUTE, -(DATEDIFF(MINUTE, GETDATE(), GETUTCDATE())), [qsp].[last_execution_time]) AS [LocalLastExecutionTime], [rsi].[runtime_stats_interval_id], [rsi].[start_time], [rsi].[end_time], [qst].[query_sql_text], ConvertedPlan = TRY_CONVERT(XML, [qsp].[query_plan]) FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] JOIN [sys].[query_store_runtime_stats_interval] [rsi] ON [rs].[runtime_stats_interval_id] = [rsi].[runtime_stats_interval_id] WHERE [qsq].[object_id] <> 0;
 Запитване Съхраняване на данни след промяна на съхранената процедура с помощта на DROP и след това CREATE OR ALTER
Запитване Съхраняване на данни след промяна на съхранената процедура с помощта на DROP и след това CREATE OR ALTER
object_id се промени на 661577395 и имам нов query_id (42), тъй като текстът на заявката се промени, и нов plan_id (43). Въпреки че този план все още е търсене на индекс на моя неклъстериран индекс, той все още е различен план в хранилището на заявки. Разберете, че препоръчителният метод за промяна на обекти, когато използвате Query Store, е да използвате ALTER, а не шаблон DROP и CREATE. Това е вярно в производството и за тестване като това, тъй като искате да запазите object_id същият, за да улесните намирането на промените.
Тестване на промените в индекса
За част II от нашето тестване, вместо да променяме заявката, искаме да видим дали можем да подобрим производителността чрез промяна на индекса. Така че ще променим съхранената процедура обратно към оригиналната заявка, след което ще променим индекса.
CREATE OR ALTER PROCEDURE [dbo].[usp_GetCustomerInfo] (@LastName [nvarchar](64)) AS SELECT [CustomerID], [FirstName], [LastName], [Email], CASE WHEN [Active] = 1 THEN 'Active' ELSE 'Inactive' END [Status] FROM [dbo].[Customers] WHERE [LastName] = @LastName; GO /* Modify existing index to add [Active] to cover the query */ CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail], [Active]) WITH (DROP_EXISTING=ON);
Тъй като изпуснах оригиналната съхранена процедура, оригиналният план вече не е в кеша. Ако първо бях направил тази промяна на индекса, като част от тестването, не забравяйте, че заявката няма да използва автоматично новия индекс, освен ако не наложа прекомпилация. Бих могъл да използвам sp_recompile върху обекта или мога да продължа да използвам опцията WITH RECOMPILE в процедурата, за да видя, че имам същия план с двете различни стойности (не забравяйте, че първоначално имах два различни плана). Нямам нужда от WITH RECOMPILE, тъй като планът не е в кеша, но го оставям включен за последователност.
EXEC [dbo].[usp_GetCustomerInfo] 'name' WITH RECOMPILE; GO EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;
В магазина на заявки виждам друг нов query_id (защото object_id е различен от първоначалния!) и нов plan_id:
 Запитване за съхраняване на данни след добавяне на нов индекс
Запитване за съхраняване на данни след добавяне на нов индекс
Ако проверя плана, мога да видя, че се използва модифицираният индекс.
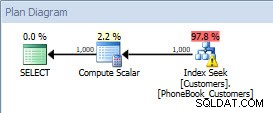 План за заявка след добавяне на [Активно] към индекса (plan_id =50)
План за заявка след добавяне на [Активно] към индекса (plan_id =50)
И сега, когато имам различен план, бих могъл да направя крачка напред и да се опитам да симулирам производствено натоварване, за да проверя, че с различни входни параметри тази съхранена процедура генерира същия план и използва новия индекс. Тук обаче има едно предупреждение. Може да сте забелязали предупреждението в оператора Index Seek – това се случва, защото в колоната [LastName] няма статистика. Когато създадохме индекса с [Active] като включена колона, таблицата беше прочетена, за да се актуализират статистическите данни. В таблицата няма данни, оттук и липсата на статистика. Това определено е нещо, което трябва да имате предвид при тестването на индекси. Когато липсват статистически данни, оптимизаторът ще използва евристични методи, които могат или не могат да убедят оптимизатора да използва плана, който очаквате.
Резюме
Аз съм голям фен на DBCC CLONEDATABASE. Аз съм още по-голям фен на Query Store. Когато ги съберете заедно, имате страхотни възможности за бързо тестване на промените в индекса и кода. С този метод разглеждате предимно планове за изпълнение, за да потвърдите подобренията. Тъй като в клонирана база данни няма данни, не можете да заснемате статистически данни за използването на ресурси и по време на изпълнение, за да докажете или опровергаете възприемана полза в план за изпълнение. Все още трябва да възстановите базата данни и да тествате с пълен набор от данни – и Query Store все още може да бъде огромна помощ при улавянето на количествени данни. Въпреки това, за случаите, когато валидирането на плана е достатъчно, или за тези от вас, които в момента не правят никакви тестове, DBCC CLONEDATABASE предоставя този лесен бутон, който търсите. Query Store прави процеса още по-лесен.
Няколко бележки:
Не препоръчвам да използвате WITH RECOMPILE при извикване на съхранени процедури (или да ги декларирате по този начин – вижте публикацията на Пол Уайт). Използвах тази опция за тази демонстрация, защото създадох съхранена процедура, чувствителна към параметри, и исках да се уверя, че различните стойности генерират различни планове и не използват план от кеша.
Изпълнението на тези тестове в SQL Server 2014 SP2 с DBCC CLONEDATABASE е напълно възможно, но очевидно има различен подход за улавяне на заявки и показатели, както и за разглеждане на производителността. Ако искате да видите същата методология за тестване, без Query Store, оставете коментар и ме уведомете!