Гост автор:Анди Малън (@AMtwo)
Не, сериозно. Какво е DTU?
Когато разгръщате някое приложение, един от първите въпроси, които се появяват, е „Какво ще струва това?“ Повечето от нас са преминали през този вид упражнение за оразмеряване на инсталация на SQL Server в даден момент, но какво ще стане, ако внедрявате в облака? С внедряването на Azure IaaS не се е променило много – вие все още изграждате сървър въз основа на броя на процесорите, известно количество памет и конфигурирате съхранение, за да ви осигури достатъчно IOPS за вашето работно натоварване. Въпреки това, когато преминете към PaaS, Azure SQL база данни е оразмерена с различни нива на услуги, където производителността се измерва в DTU. Какво, по дяволите, е DTU?
Знам какво е BTU. Може би DTU означава Термална единица на базата данни? Това ли е количеството процесорна мощност, необходима за повишаване на температурата на центъра за данни с един градус? Вместо да гадаем, нека проверим документацията и да видим какво има да каже Microsoft:
[Единица за транзакции на база данни] е смесена мярка за вход/изход на процесора, паметта и данни и вход/изход на регистрационния файл на транзакции в съотношение, определено от работно натоварване на OLTP, предназначено да бъде типично за реалните OLTP работни натоварвания. Удвояването на DTU чрез увеличаване на нивото на производителност на база данни се равнява на удвояване на набора от налични ресурси за тази база данни.Добре, това беше второто ми предположение – но каква е „смесената мярка“? Как мога да преведа това, което знам за оразмеряването на сървър в оразмеряване на Azure SQL база данни? За съжаление, няма лесен начин да преведете „2 ядра на процесора и 4GB памет“ в измерване на DTU.
Няма ли DTU калкулатор?
Да! Microsoft ни предоставя DTU калкулатор за оценка правилното ниво на услугата на Azure SQL база данни. За да го използвате, изтегляте и стартирате скрипт на PowerShell (sql-perfmon.ps1) на сървъра, докато изпълнявате работно натоварване в SQL Server. Скриптът извежда CSV, който съдържа четири perfmon брояча:(1) общо % време на процесора, (2) общо четене на диск/секунда, (3) общо записване на диск в секунда и (4) общ брой изчистени лог байтове/секунда. След това този CSV изход се качва в DTU калкулатора, който изчислява кое ниво на услугата ще отговори най-добре на вашите нужди. Единствените данни, които DTU калкулаторът взема в допълнение към CSV, е броят на процесорните ядра на сървъра, който е генерирал файла. DTU калкулаторът все още е малко черна кутия – не е лесно да картографираме това, което знаем от нашите локални бази данни в Azure.
Бих искал да отбележа, че определението за DTU е, че това е „смесена мярка за процесор, памет , и I/O данни и I/O дневник на транзакциите…“ Нито един от perfmon броячите, използвани от DTU калкулатора, не взема предвид паметта, но тя е ясно посочена в дефиницията като част от изчислението. Това не е непременно проблем, но това е доказателство, че DTU калкулаторът няма да бъде перфектен.
Ще кача малко синтетично натоварване в DTU калкулатора и ще видя дали мога да разбера как работи тази черна кутия. Всъщност ще изработя напълно CSV файловете, така че да мога напълно да контролирам числата на perfmon, които зареждаме в DTU калкулатора. Нека преминем през един показател. За всеки показател ще качим измислени данни за 25 минути (1500 секунди – харесвам кръгли числа) и ще видим как тези perfmon данни се преобразуват в DTU.
ЦП
Ще създам CSV, който симулира 16-ядрен сървър, бавно увеличавайки използването на процесора, докато не бъде фиксиран на 100%. Тъй като ще симулирам нарастването на 16-ядрен сървър, ще създам моя CSV, за да засили 1/16-та наведнъж – по същество симулирам едно ядро на максимизиране, след това второ изключване, след това трето, и т.н. През цялото време CSV ще показва нула четения, записвания и изтривания в регистрационни файлове. Сървърът никога не би генерирал такова натоварване – но това е смисълът. Изолирам напълно използването на процесора, за да мога да видя как процесорът влияе на DTU.
Ще създам CSV файл, който има един ред в секунда и на всеки 94 секунди ще увеличавам брояча на общото % процесорно време с ~6%. Останалите три броячи ще бъдат нула във всички случаи. Сега качвам този файл в DTU калкулатора (и казвам на DTU калкулатора да разгледа 16 ядра) и ето изхода:
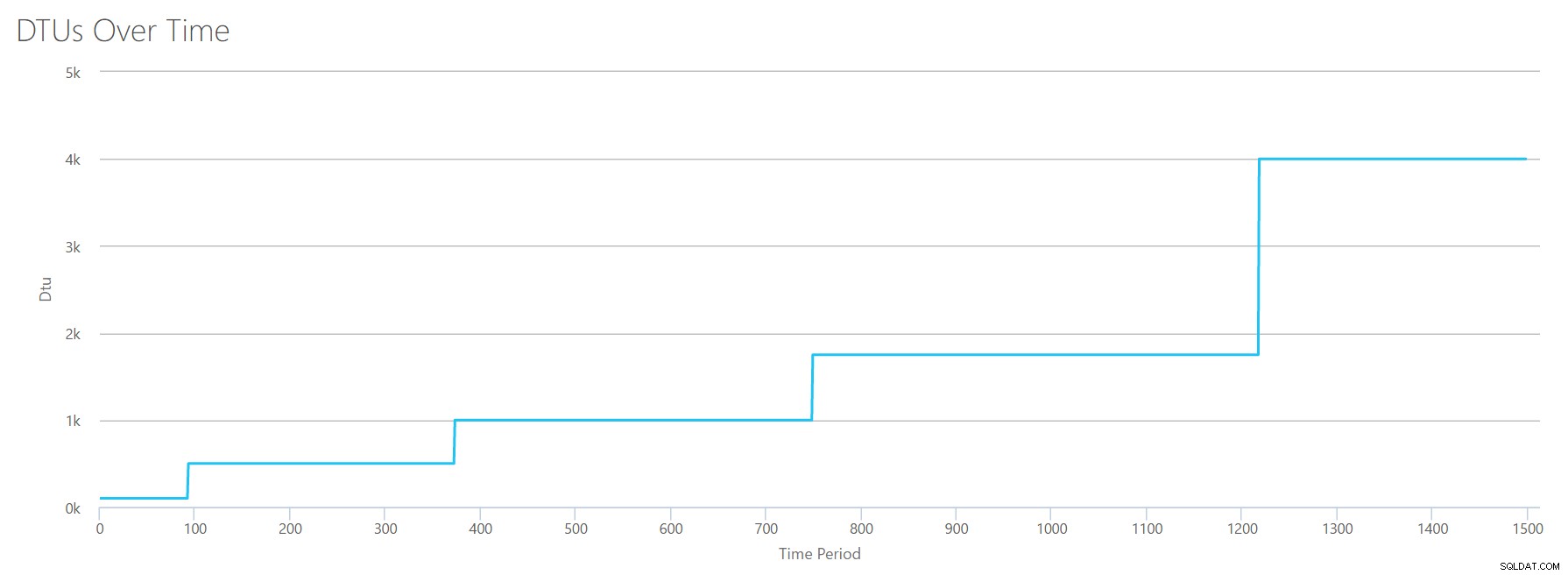
Изчакайте? Не повиших ли използването на процесора в 16 четни стъпки? Тази DTU графика показва само пет стъпки. Сигурно съм се объркал. Не – моят CSV имаше 16 четни стъпки, но това (очевидно) не се превежда равномерно в DTU. Поне не според калкулатора на DTU. Въз основа на нашия тест за максимален CPU, нашето картографиране на ниво CPU-to-DTU-to-Service би изглеждало така:
| Брой ядра | DTUs | Сервизно ниво |
|---|---|---|
| 1 | 100 | Стандартно – S3 |
| 2-4 | 500 | Премиум – P4 |
| 5-8 | 1000 | Премиум – P6 |
| 9-13 | 1750 | Премиум – P11 |
| 14-16 | 4000 | Премиум – P15 |
Разглеждането на тези данни ни казва няколко неща:
- Едно ядро на процесора, 100% използвано се равнява на 100 DTU.
- DTU се увеличават донякъде линейно с нарастването на процесора, но привидно на пристъпи и тласъци.
- Основните и стандартните нива на услуги са равни на по-малко от едно ядро на процесора.
- Всеки многоядрен сървър ще се преведе до някакъв размер в рамките на ниво на услугата Premium.
Четене
Този път ще използвам същата методология. Ще генерирам CSV с нарастващи числа за брояча на четене/секунди, като другите perfmon броячи са на нула. С течение на времето бавно ще увеличавам броя. Този път нека се увеличаваме на парчета от 2000, на всеки 100 секунди, докато достигнем 30 000. Това ни дава същото общо време от 25 минути – обаче този път имам 15 стъпки вместо 16. (Харесвам кръгли числа.)
Когато качим този CSV в калкулатора на DTU, той ни дава следната DTU графика:
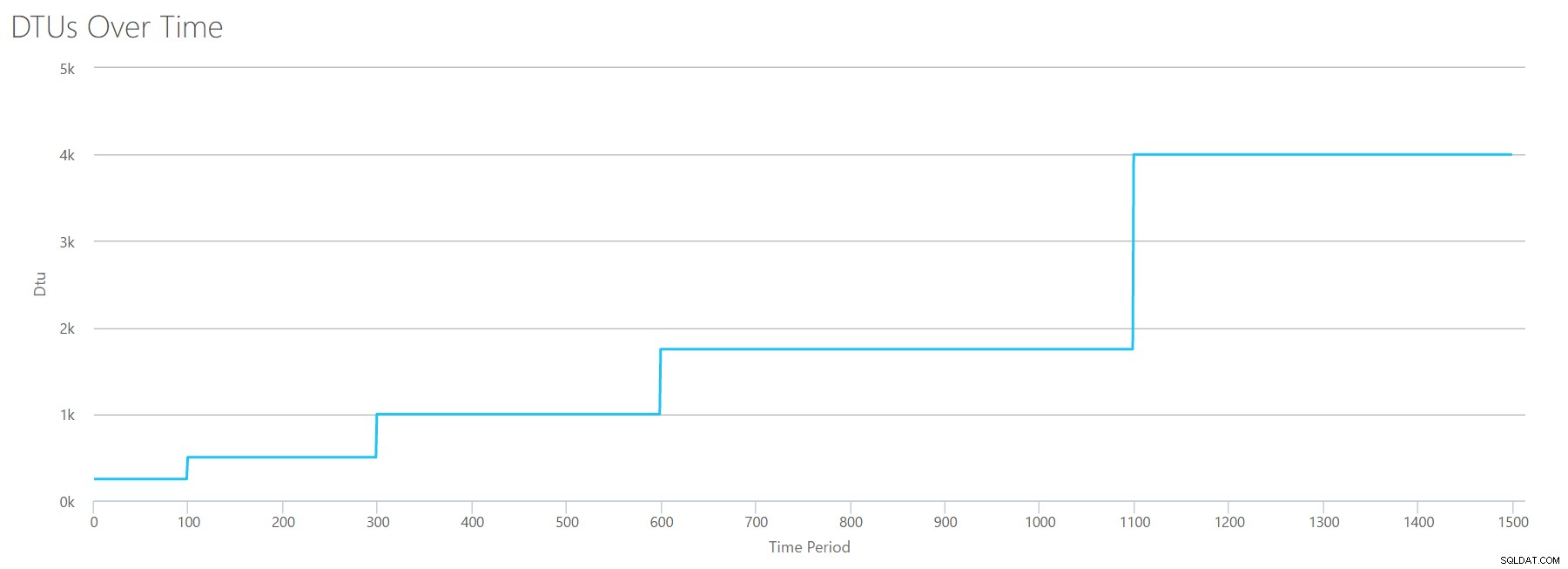
Изчакайте малко... това изглежда доста подобно на първата графика. Отново се засилва на 5 неравномерни стъпки, въпреки че имах 15 четни стъпки в моя файл. Нека го разгледаме в табличен формат:
| Четене/сек | DTUs | Сервизно ниво |
|---|---|---|
| 2000 | 250 | Премиум – P2 |
| 4000-6000 | 500 | Премиум – P4 |
| 8000-12000 | 1000 | Премиум – P6 |
| 14000-22000 | 1750 | Премиум – P11 |
| 24000-30000 | 4000 | Премиум – P15 |
Отново виждаме, че базовите и стандартните нива се прескачат доста бързо (по-малко от 2000 четения/сек), но тогава нивото Premium е доста широко, обхващайки 2000 до 30000 четения в секунда. В горната таблица „четения/сек“ вероятно може да се счита за „IOPS“... Или технически просто „OPS“, тъй като няма записи, които да съставляват „входната“ част на IOPS.
Пише
Ако създадем CSV, използвайки същата формула, която използвахме за Reads, и качим този CSV в DTU калкулатора, ще получим графика, която е идентична с графиката за Reads:
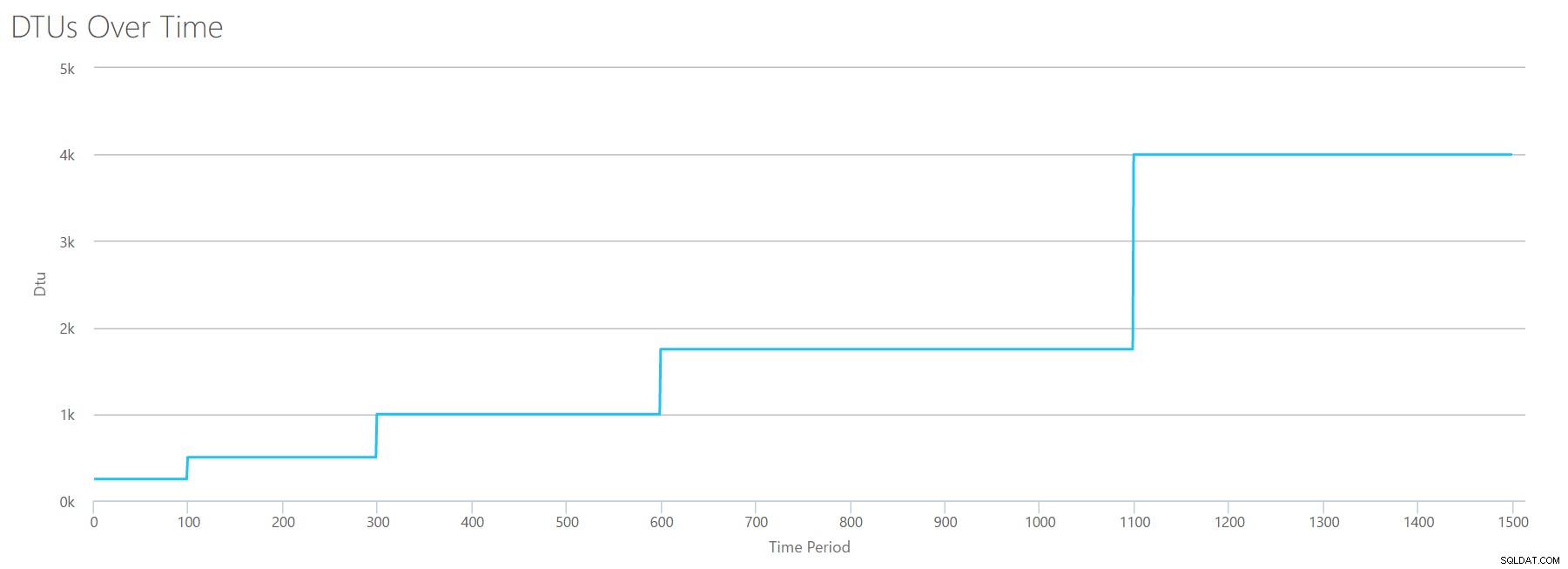
IOPS са IOPS, така че независимо дали става въпрос за четене или запис, изглежда, че изчислението на DTU го отчита еднакво. Всичко, което знаем (или смятаме, че знаем) за четенията изглежда се отнася еднакво и за записванията.
Регистрационните байтове са изчистени
Стигнахме до последния perfmon брояч:регистрационни байтове, изчистени в секунда. Това е друга мярка за IO, но специфична за регистъра на транзакциите на SQL Server. В случай, че не сте се схванали досега, създавам тези CSV файлове, така че високите стойности да се изчисляват като P15 Azure DB, след което просто разделям стойността, за да я разделя на четни стъпки. Този път ще преминем от 5 милиона до 75 милиона, на стъпки от 5 милиона. Както направихме при всички предишни тестове, другите perfmon броячи ще бъдат нула. Тъй като този perfmon брояч е в байтове в секунда, а ние измерваме в милиони, можем да мислим за това в единицата, която ни е по-удобна:мегабайти в секунда.
Качваме този CSV в DTU калкулатора и получаваме следната графика:
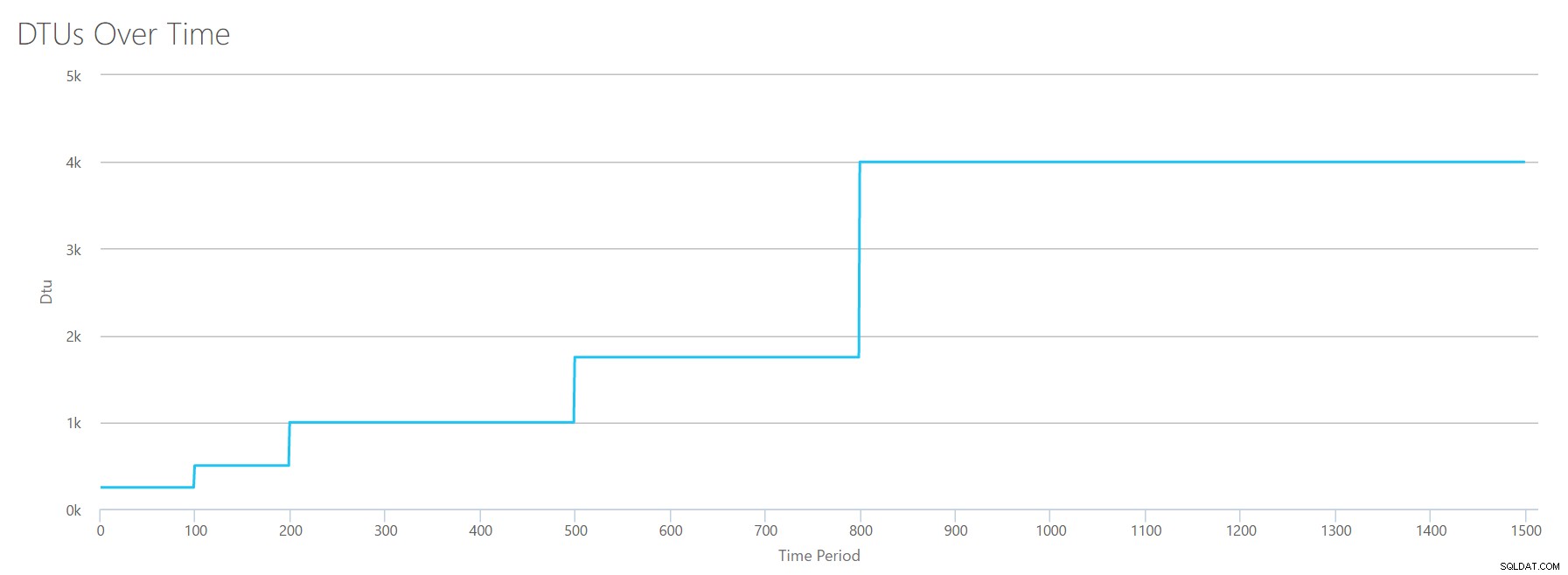
| Регистриране на мегабайти прочистени/сек | DTUs | Сервизно ниво |
|---|---|---|
| 5 | 250 | Премиум – P2 |
| 10 | 500 | Премиум – P4 |
| 15-25 | 1000 | Премиум – P6 |
| 30-40 | 1750 | Премиум – P11 |
| 45-75 | 4000 | Премиум – P15 |
Формата на тази графика става доста предсказуема. Освен този път, ние се издигаме през нивата малко по-бързо, достигайки P15 само след 8 стъпки (в сравнение с 11 за IO и 12 за CPU). Това може да ви накара да си помислите:"Това ще бъде най-тясното ми препятствие!" но не бих бил толкова сигурен в това. Колко често генерирате 75MB регистрационен файл за секунда ? Това е 4,5 GB на минута . Това е много дейност в базата данни. Моето синтетично натоварване не е непременно реалистично.
Комбиниране на всичко
Добре, сега, когато видяхме къде са някои от горните граници в изолация, ще комбинирам данните и ще видя как се сравняват, когато процесорът, I/O и IO на транзакциите се случват наведнъж – в края на краищата , нали така се случват нещата всъщност?
За да създам този CSV, просто взех съществуващите стойности, които използвахме за всеки отделен тест по-горе, и комбинирах тези стойности в един CSV, което дава тази прекрасна графика:
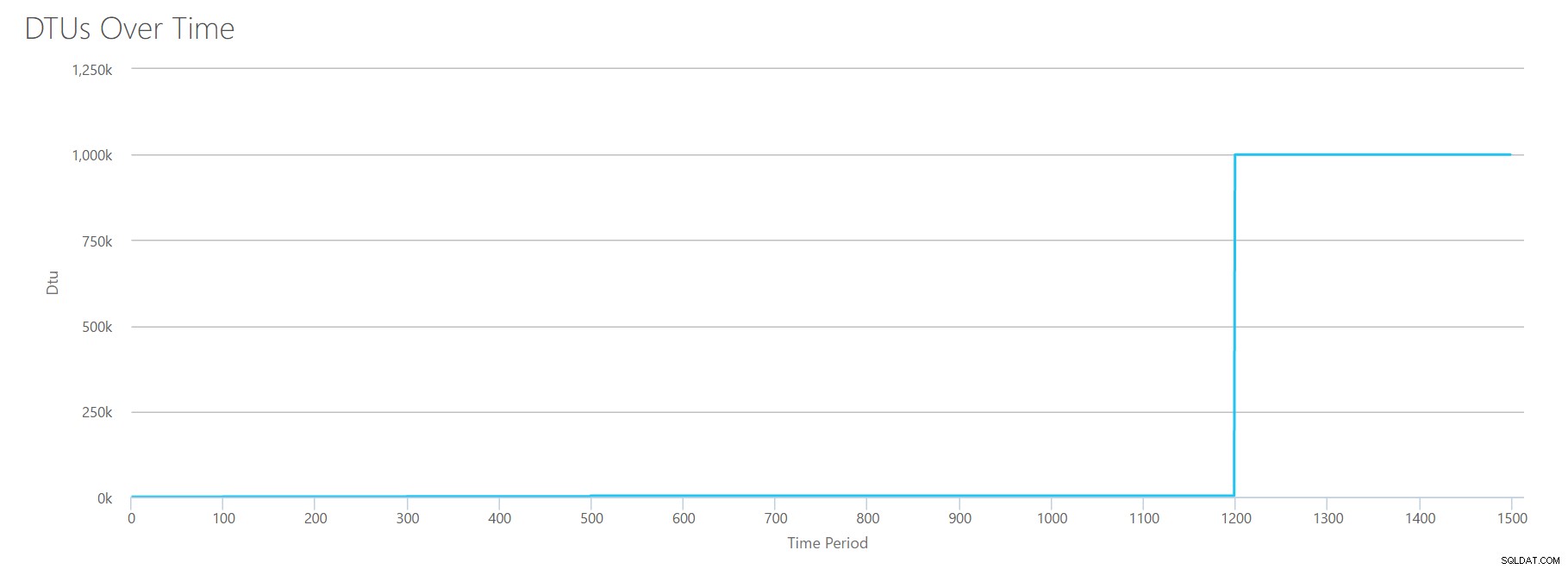
Той също така дава съобщението:
Въз основа на използването на вашата база данни, вашето работно натоварване на SQL Server е Извън обхват . Понастоящем няма ниво на услуга/ниво на производителност, което да покрие вашето използване.Ако погледнете оста Y, ще видите, че сме достигнали "1000k" (т.е. 1 милион) DTUs на 1200 секунди. Това изглежда… ъъъъ… грешно? Ако погледнем горните тестове, оценката от 1200 секунди беше, когато всичките 4 индивидуални показателя достигнаха марката за 4000 DTU, ниво P15. Има смисъл да сме извън обхвата, но формата на графиката няма смисъл за мен – мисля, че калкулаторът на DTU просто повърна ръцете си и каза:„Каквото и да е, Анди. Много е. Твърде е много. Това е милион DTU. Това работно натоварване не е подходящо за Azure SQL база данни."
Добре, какво се случва преди марката от 1200 секунди? Нека да намалим CSV-то и да го изпратим отново на калкулатора само с първите 1200 секунди. Максималните стойности за всяка колона са:81% CPU (или apx 13 ядра при 100%), 24000 четения/сек, 24000 записа/сек и 60MB изчистен дневник/сек.
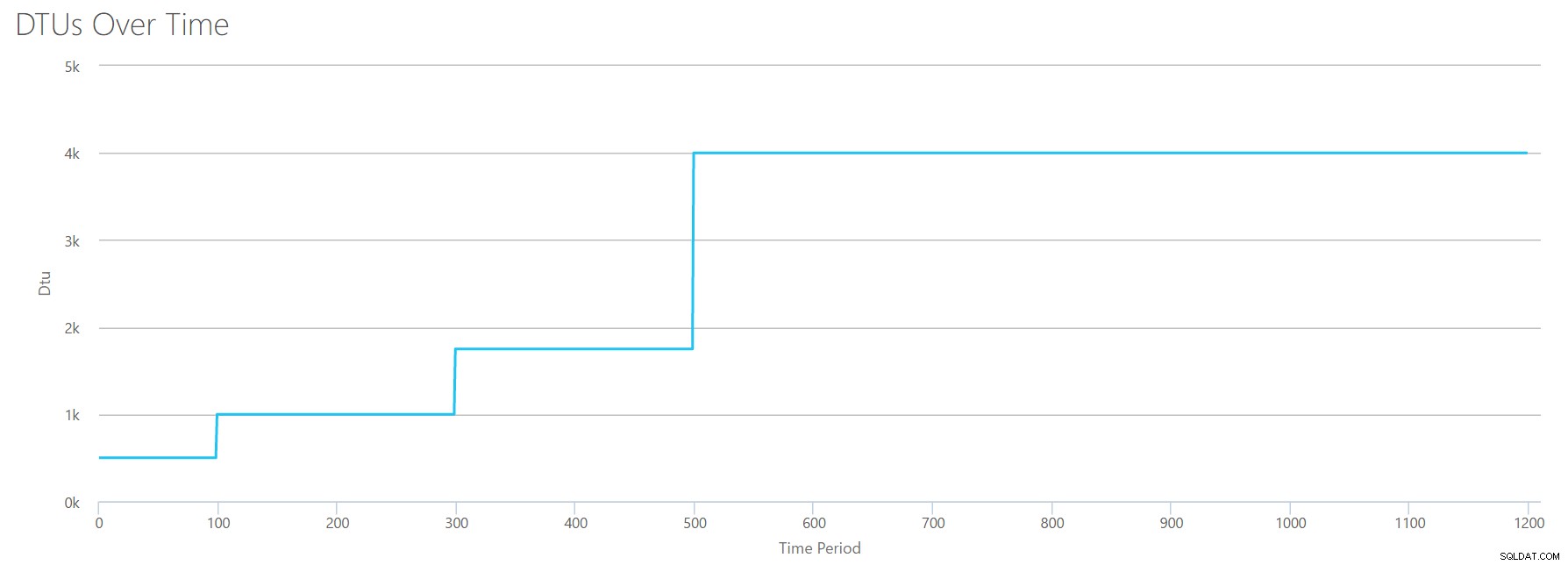
Здравей, стар приятел... Тази позната форма се завръща отново. Ето обобщение на данните от CSV и това, което калкулаторът на DTU изчислява за общото използване на DTU и ниво на услугата.
| Брой ядра | Четене/сек | Записва/сек | Регистриране на мегабайти прочистени/сек | DTUs | Сервизно ниво |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Премиум – P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | Премиум – P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | Премиум – P11 |
| 6-13 | 12000-24000 | 12000-24000 | 30-40 | 4000 | Премиум – P15 |
Сега нека да разгледаме как отделните изчисления на DTU (когато ги оценявахме изолирано) се сравняват с изчисленията на DTU от тази последна проверка:
| CPU DTUs | Прочетете DTUs | Напишете DTUs | DTU за изтриване на регистрационни файлове | Общо DTUs | Прогноза на DTU калкулатора | Сервизно ниво |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Премиум – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Премиум – P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | Премиум – P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | Премиум – P15 |
Ще забележите, че изчисляването на DTU не е толкова просто, колкото добавянето на вашите отделни DTU. Както се посочва в определението, което цитирах в началото, това е „смесена мярка“ на тези отделни показатели. Формулата, използвана за "блендиране", е сложна и ние всъщност нямаме тази формула. Това, което можем да видим, е, че оценките на DTU калкулатора са по-ниски отколкото сумата от отделните изчисления на DTU.
Съпоставяне на DTU към традиционния хардуер
Нека вземем данните от калкулатора на DTU и се опитаме да съставим някои предположения за това как традиционният хардуер може да се съпостави с някои нива на Azure SQL база данни.
Първо, нека предположим, че „четене/сек“ и „записване/сек“ се превеждат директно в IOPS, без да е необходим превод. Второ, нека приемем, че добавянето на тези два брояча ще ни даде общия ни IOPS. Трето, нека признаем, че нямаме представа какво е използване на паметта и нямаме начин да направим каквито и да било заключения в този аспект.
Докато оценявам хардуерните спецификации, ще избера и възможен размер на Azure VM, който би паснал на всяка хардуерна конфигурация. Има много подобни размери на Azure VM, всеки оптимизиран за различни показатели за производителност, но аз продължих и ограничих избора си до A-Series и DSv2-Series.
| Брой ядра | IOPS | Памет | DTUs | Сервизно ниво | Сравним размер на Azure VM |
|---|---|---|---|---|---|
| 1 ядро, 5% използване | 10 | ??? | 5 | Основни | Стандарт_A0, почти не се използва |
| <1 ядро | 150 | ??? | 100 | Стандарт S0-S3 | Стандарт_A0, не се използва напълно |
| 1 ядро | до 4000 | ??? | 500 | Премиум – P4 | Standard_DS1_v2 |
| 2-3 ядра | до 12000 | ??? | 1000 | Премиум – P6 | Standard_DS3_v2 |
| 4-5 ядра | до 20000 | ??? | 1750 | Премиум – P11 | Standard_DS4_v2 |
| 6-13 | до 48000 | ??? | 4000 | Премиум – P15 | Standard_DS5_v2 |
Основното ниво е невероятно ограничено. Добър е за случайна/ежедневна употреба и е евтин начин да „паркираш“ базата си данни, когато не я използвате. Но ако използвате някое истинско приложение, базовият слой няма да работи за вас.
Стандартното ниво също е доста ограничено, но за малки приложения е в състояние да отговори на вашите нужди. Ако имате 2-ядрен сървър, работещ с шепа бази данни, тогава тези бази данни поотделно може да се впишат в стандартното ниво. По същия начин, ако имате сървър само с една база данни, работещ с 1 CPU ядро на 100% (или 2 ядра, работещи на 50%), вероятно е достатъчно конски сили, за да насочите скалата към нивото на услугата Premium-P1.
Ако използвате многоядрен сървър в локален сървър (или IaaS), тогава ще търсите в нивото на услугата Premium в базата данни на Azure SQL. Въпросът е само да определите колко конски сили на процесора и I/O са ви необходими за вашето работно натоварване. Вашият 2-ядрен, 4GB сървър вероятно ви отвежда някъде около P6 Azure SQL DB. При чисто процесорно натоварване (с нулев I/O) база данни P15 може да се справи с обработка на 16 ядра, но след като добавите IO към микса, всичко по-голямо от ~12 ядра не се вписва в Azure SQL база данни.
Следващия път ще взема някои действителни натоварвания и ще сравня производителността на различните нива на услуги. Ще бъдат ли точни оценките на DTU калкулатора? Ще разберем.
За автора
 Анди Малън е SQL Server DBA и MVP на платформата за данни на Microsoft, който управлява бази данни в здравеопазването, финансите, e. -търговски и нестопански сектори. От 2003 г. Andy поддържа големи обеми, високодостъпни OLTP среди с взискателни нужди от производителност. Анди е основател на BostonSQL, съорганизатор на SQLSaturday Boston и блогове в am2.co.
Анди Малън е SQL Server DBA и MVP на платформата за данни на Microsoft, който управлява бази данни в здравеопазването, финансите, e. -търговски и нестопански сектори. От 2003 г. Andy поддържа големи обеми, високодостъпни OLTP среди с взискателни нужди от производителност. Анди е основател на BostonSQL, съорганизатор на SQLSaturday Boston и блогове в am2.co.