Когато SQL Server оптимизира заявка, по време на фаза на проучване той произвежда планове за кандидати и избира измежду тях този, който има най-ниска цена. Предполага се, че избраният план има най-ниско време за изпълнение сред изследваните планове. Работата е там, че оптимизаторът може да избира само между стратегиите, които са били кодирани в него. Например, когато оптимизира групирането и агрегирането, към датата на това писане, оптимизаторът може да избира само между стратегиите Stream Aggregate и Hash Aggregate. Разгледах наличните стратегии в по-ранните части на тази серия. В част 1 обхванах предварително поръчаната стратегия Stream Aggregate, в част 2 стратегията Sort + Stream Aggregate, в част 3 стратегията Hash Aggregate и в част 4 съображенията за паралелизъм.
Това, което оптимизаторът на SQL Server в момента не поддържа, е персонализирането и изкуствения интелект. Тоест, ако можете да разберете стратегия, която при определени условия е по-оптимална от тези, които оптимизаторът поддържа, не можете да подобрите оптимизатора, за да го поддържа, и оптимизаторът не може да се научи да го използва. Това, което можете да направите обаче, е да пренапишете заявката, като използвате алтернативни елементи на заявка, които могат да бъдат оптимизирани според стратегията, която имате предвид. В тази пета и последна част от поредицата демонстрирам тази техника за настройка на заявката с помощта на ревизии на заявка.
Големи благодарности на Пол Уайт (@SQL_Kiwi) за помощта с някои от изчисленията на разходите, представени в тази статия!
Както в предишните части от поредицата, ще използвам примерната база данни PerformanceV3. Използвайте следния код, за да премахнете ненужните индекси от таблицата с поръчки:
ОТПУСКАНЕ ИНДЕКС idx_nc_sid_od_cid НА dbo.Orders; ИЗПУСКАНЕ ИНДЕКС idx_unc_od_oid_i_cid_eid НА dbo.Orders;
Стратегия за оптимизация по подразбиране
Помислете за следните основни задачи за групиране и агрегиране:
Върнете максималната дата на поръчка за всеки изпращач, служител и клиент.
За оптимална производителност създавате следните поддържащи индекси:
СЪЗДАЙТЕ ИНДЕКС idx_sid_od НА dbo.Orders(shipperid, orderdate);СЪЗРАВЕТЕ ИНДЕКС idx_eid_od НА dbo.Orders(empid, orderdate);СЪЗРАВЕТЕ ИНДЕКС idx_cid_od НА dbo.Orders(custid, orderdate);
Следват трите заявки, които бихте използвали, за да се справите с тези задачи, заедно с прогнозните разходи за поддърво, както и статистически данни за I/O, CPU и изминалото време:
-- Заявка 1-- Приблизителна цена на поддървото:3,5344-- логически показания:2484, време на процесора:281 ms, изминало време:279 ms ИЗБЕРЕТЕ shipperid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY shipperid; -- Заявка 2-- Приблизителна цена на поддървото:3,62798-- логически показания:2610, време на процесора:250 ms, изминало време:283 ms SELECT empid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY empid; -- Заявка 3-- Приблизителна цена на поддървото:4,27624-- логически показания:3479, време на процесора:406 ms, изминало време:506 ms SELECT custid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY custid;
Фигура 1 показва плановете за тези заявки:
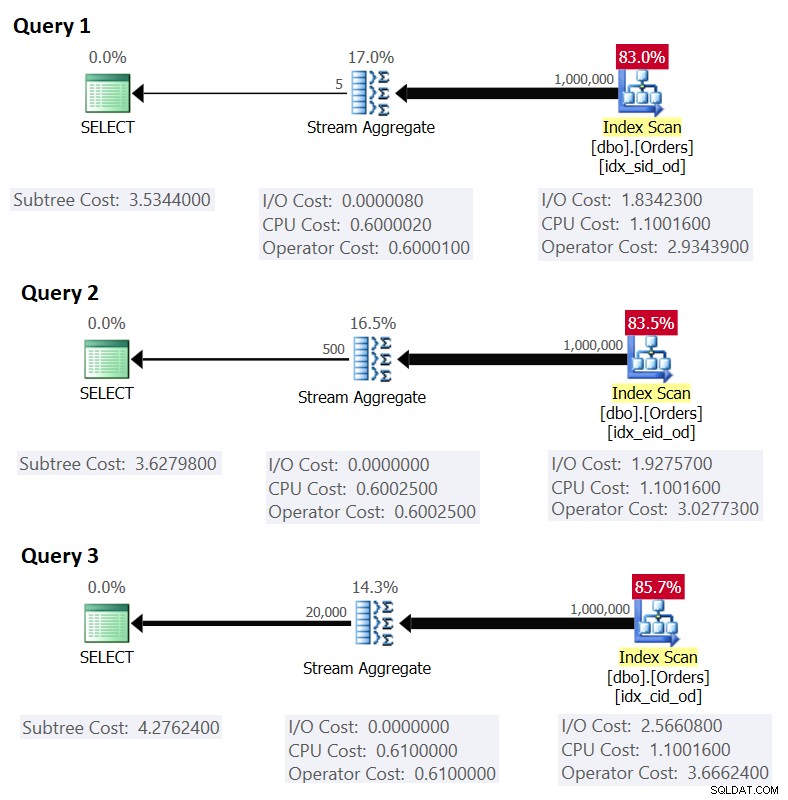 Фигура 1:Планове за групирани заявки
Фигура 1:Планове за групирани заявки
Припомнете си, че ако имате въведен индекс за покриване, като колоните за групиране са зададени като водещи ключови колони, последвани от колоната за агрегиране, SQL Server вероятно ще избере план, който извършва подредено сканиране на покриващия индекс, поддържащ стратегията Stream Aggregate . Както е видно от плановете на фигура 1, операторът Index Scan е отговорен за по-голямата част от разходите на плана, а в него I/O частта е най-забележима.
Преди да представя алтернативна стратегия и да обясня обстоятелствата, при които тя е по-оптимална от стратегията по подразбиране, нека оценим цената на съществуващата стратегия. Тъй като I/O частта е най-доминиращата при определяне на цената на плана на тази стратегия по подразбиране, нека първо просто да преценим колко логически четения на страници ще са необходими. По-късно ще изчислим и цената на плана.
За да оцените броя на логическите четения, които ще изисква операторът за сканиране на индекса, трябва да знаете колко реда имате в таблицата и колко реда се побират в страница въз основа на размера на реда. След като имате тези два операнда, вашата формула за необходимия брой страници в нивото на листа на индекса е CEILING(1e0 * @numrows / @rowsperpage). Ако всичко, което имате, е само структурата на таблицата и няма съществуващи примерни данни, с които да работите, можете да използвате тази статия, за да оцените броя на страниците, които бихте имали в нивото на листа на поддържащия индекс. Ако имате добри представителни примерни данни, дори и да не са в същия мащаб като в производствената среда, можете да изчислите средния брой редове, които се вписват в една страница, като зададете заявка за обекти за каталог и динамично управление, както следва:
SELECT I.name, row_count, in_row_data_page_count, CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) КАТО avgrowsperpage FROM sys.indexes КАТО INNER JOIN sys.dm_db_partition_stats =Pobject_id_ P. И I.index_id =P.index_id WHERE I.object_id =OBJECT_ID('dbo.Orders') И I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Тази заявка генерира следния изход в нашата примерна база данни:
име row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Сега, когато имате броя на редовете, които се вписват в листовата страница на индекса, можете да оцените общия брой листни страници в индекса въз основа на броя на редовете, които очаквате да има вашата производствена таблица. Това също ще бъде очакваният брой логически четения, които ще бъдат приложени от оператора Index Scan. На практика броят на четенията, които биха могли да се осъществят, е повече от броя на страниците в нивото на листа на индекса, като допълнителни четения, произведени от механизма за четене напред, но ще ги игнорирам, за да опростя нашата дискусия .
Например, прогнозният брой логически четения за заявка 1 по отношение на очаквания брой редове е CEILING(1e0 * @numorws / 404). При 1 000 000 реда очакваният брой логически четения е 2476. Разликата между 2476 и отчетения брой страници на редове от 2473 може да се припише на закръгляването, което направих при изчисляването на средния брой редове на страница.
Що се отнася до цената на плана, обясних как да се направи обратен инженеринг на разходите на оператора Stream Aggregate в част 1 от поредицата. По подобен начин можете да конструирате обратното инженерство на цената на оператора Index Scan. Тогава цената на плана е сумата от разходите на операторите Index Scan и Stream Aggregate.
За да изчислите цената на оператора Index Scan, искате да започнете с обратното проектиране на някои от важните константи на модела на разходите:
@randomio =0,003125 -- Random I/O cost@seqio =0,000740740740741 -- Sequential I/O cost@cpubase =0,000157 -- CPU base cost@cpurow =0,0000011 -- CPU цена на CPU>След като измислихте горните константи на модела на разходите, можете да продължите с обратното проектиране на формулите за входно/изходната цена, цената на процесора и общата операторска цена за оператора за индексно сканиране:
Разходи за I/O:@randomio + (@numpages - 1e0) * @seqio =0,003125 + (@numpages - 1e0) * 0,000740740740741 Разходи на процесора:@cpubase + @numrows * @cpurow1O15s на 0,00 +0.00 цена:0,002541259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000011Например, цената на оператора за индексно сканиране за заявка 1, с 2473 страници и 1 000 000 реда, е:
0,002541259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000011 =2,93439Следва формулата за обратно проектиране за операторската цена на Stream Aggregate:
0,000008 + @numrows * 0,0000006 + @numgroups * 0,0000005Като пример за заявка 1 имаме 1 000 000 реда и 5 групи, следователно прогнозната цена е 0,6000105.
Комбинирайки разходите на двата оператора, ето формулата за цялата цена на плана:
0,002549259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005За заявка 1, с 2473 страници, 1 000 000 реда и 5 групи, получавате:
0,002549259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,0000005 =3,5344Това съвпада с това, което фигура 1 показва като прогнозна цена за заявка 1.
Ако разчитате на приблизителен брой редове на страница, вашата формула ще бъде:
0,002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0,000740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005Като пример, за заявка 1, с 1 000 000 реда, 404 реда на страница и 5 групи, прогнозната цена е:
0,002549259259259 + ТАВАН(1e0 * 1000000 / 404) * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,000000 / 404.Като упражнение можете да приложите числата за заявка 2 (1 000 000 реда, 385 реда на страница, 500 групи) и заявка 3 (1 000 000 реда, 289 реда на страница, 20 000 групи) в нашата формула и да видите, че резултатите съответстват на това, което Фигура 1 показва.
Настройка на заявка с пренаписване на заявка
Предварително поръчаната стратегия Stream Aggregate за изчисляване на MIN/MAX агрегат за група разчита на подредено сканиране на поддържащ покриващ индекс (или някаква друга предварителна дейност, която излъчва подредените редове). Алтернативна стратегия, с наличен поддържащ покриващ индекс, би била да се извърши търсене на индекс за група. Ето описание на псевдоплан, базиран на такава стратегия за заявка, която се групира по grpcol и прилага MAX(aggcol):
set @curgrpcol =grpcol от първия ред, получен чрез сканиране на индекса, подредено напред; докато края на индекса не е достигнат, начало set @curagg =aggcol от ред, получен чрез търсене до последната точка, където grpcol =@curgrpcol, подреден назад; емитен ред (@curgrpcol, @curagg); set @curgrpcol =grpcol от ред вдясно от последния ред за текущата група;end;Ако се замислите, стратегията по подразбиране, базирана на сканиране, е оптимална, когато групиращият набор има ниска плътност (голям брой групи, средно малък брой редове на група). Стратегията, базирана на търсене, е оптимална, когато групиращият набор има висока плътност (малък брой групи, средно голям брой редове на група). Фигура 2 илюстрира и двете стратегии, показвайки кога всяка е оптимална.
Фигура 2:Оптимална стратегия въз основа на плътност на групирането на набора
Докато пишете решението под формата на групирана заявка, в момента SQL Server ще вземе предвид само стратегията за сканиране. Това ще работи добре за вас, когато наборът за групиране е с ниска плътност. Когато имате висока плътност, за да получите стратегия за търсене, ще трябва да приложите пренаписване на заявка. Един от начините да се постигне това е да се направи заявка към таблицата, която съдържа групите, и да се използва скаларна обобщена подзаявка срещу основната таблица, за да се получи агрегатът. Например, за да изчислите максималната дата на поръчка за всеки изпращач, ще използвате следния код:
ИЗБЕРЕТЕ shipperid, ( SELECT TOP (1) O.orderdate ОТ dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC ) КАТО maxod ОТ dbo.Shippers AS S;Насоките за индексиране за основната таблица са същите като тези, които поддържат стратегията по подразбиране. Вече разполагаме с тези индекси за трите гореспоменати задачи. Вероятно бихте искали и поддържащ индекс за колоните на групиращия набор в таблицата, съдържаща групите, за да сведете до минимум разходите за I/O спрямо тази таблица. Използвайте следния код, за да създадете такива поддържащи индекси за нашите три задачи:
СЪЗДАЙТЕ ИНДЕКС idx_sid НА dbo.Shippers(shipperid);СЪЗДАЙТЕ ИНДЕКС idx_eid НА dbo.Employees(empid);СЪЗДАЙТЕ ИНДЕКС idx_cid НА dbo.Customers(custid);Един малък проблем обаче е, че решението, базирано на подзаявката, не е точен логически еквивалент на решението, базирано на групираната заявка. Ако имате група без присъствие в основната таблица, първата ще върне групата с NULL като агрегат, докато втората изобщо няма да върне групата. Един прост начин за постигане на истински логически еквивалент на групираната заявка е да извикате подзаявката с помощта на оператора CROSS APPLY в клаузата FROM вместо да използвате скаларна подзаявка в клаузата SELECT. Не забравяйте, че CROSS APPLY няма да върне ляв ред, ако приложената заявка върне празен набор. Ето трите заявки за решения, прилагащи тази стратегия за нашите три задачи, заедно със статистическите данни за ефективността им:
-- Заявка 4 -- Приблизителна цена на поддървото:0,0072299 -- логически показания:2 + 15, време на процесора:0 ms, изминало време:43 ms ИЗБЕРЕТЕ S.shipperid, A.orderdate AS maxod ОТ dbo.Shippers AS S КРЪСТНО ПРИЛАГАНЕ ( ИЗБЕРЕТЕ ВЪРХУ (1) O.orderdate ОТ dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC ) КАТО A; -- Заявка 5 -- Приблизителна цена на поддървото:0,089694 -- логически четения:2 + 1620, време на процесора:0 ms, изминало време:148 ms ИЗБЕРЕТЕ E.empid, A.orderdate КАТО maxod ОТ dbo.Employees AS E CROSS APPLY ( ИЗБЕРЕТЕ ВЪРХУ (1) O.orderdate ОТ dbo.Orders AS O WHERE O.empid =E.empid ORDER BY O.orderdate DESC ) КАТО A; -- Заявка 6 -- Приблизителна цена на поддървото:3,5227 -- логически четения:45 + 63777, време на процесора:171 ms, изминало време:306 ms ИЗБЕРЕТЕ C.custid, A.orderdate КАТО maxod ОТ dbo.Customers КАТО C CROSS APPLY ( ИЗБЕРЕТЕ ВЪРХА (1) O.orderdate ОТ dbo.Orders КАТО КЪДЕТО O.custid =C.custid ORDER BY O.orderdate DESC ) КАТО A;Плановете за тези заявки са показани на фигура 3.
Фигура 3:Планове за заявки с пренаписване
Както можете да видите, групите се получават чрез сканиране на индекса в таблицата с групи, а агрегатът се получава чрез прилагане на търсене в индекса на основната таблица. Колкото по-висока е плътността на групирането, толкова по-оптимален е този план в сравнение със стратегията по подразбиране за групираната заявка.
Точно както направихме по-рано за стратегията за сканиране по подразбиране, нека да изчислим броя на логическите четения и да планираме разходите за стратегията за търсене. Прогнозният брой логически четения е броят четения за еднократно изпълнение на оператора Index Scan, който извлича групите, плюс четенията за всички изпълнения на оператора Index Seek.
Прогнозният брой логически четения за оператора Index Scan е незначителен в сравнение с търсенията; все пак е CEILING(1e0 * @numgroups / @rowsperpage). Вземете заявка 4 като пример; да кажем, че индексът idx_sid се побира на около 600 реда на листова страница (действителният брой зависи от действителните стойности на shipperid, тъй като типът данни е VARCHAR(5)). С 5 групи всички редове се побират в една листова страница. Ако имате 5000 групи, те щяха да се поберат в 9 страници.
Прогнозният брой логически четения за всички изпълнения на оператора Index Seek е @numgroups * @indexdepth. Дълбочината на индекса може да се изчисли като:
ТАВАН(LOG(ТАВАН(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1Използвайки заявка 4 като пример, кажете, че можем да поберем около 404 реда на листова страница на индекса idx_sid_od и около 352 реда на нелистова страница. Отново действителните числа ще зависят от действителните стойности, съхранени в колоната shipperid, тъй като нейният тип данни е VARCHAR(5)). За приблизителни оценки не забравяйте, че можете да използвате изчисленията, описани тук. С наличните добри представителни примерни данни, можете да използвате следната заявка, за да разберете броя на редовете, които могат да се поберат в листните и нелистовите страници на дадения индекс:
SELECT CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END КАТО pagetype, FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage FROM (SELECT * FROM sys.indexes WHERE object_id_ID ('dbo.Orders') И име ='idx_sid_od') КАТО КРЪСТОМ ПРИЛОЖЯВАМ sys.dm_db_index_physical_stats (DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') КАТО P WHEREПолучих следния изход:
pagetype rowsperpage --------- --------------------- лист 404 нелисто 352С тези числа дълбочината на индекса по отношение на броя на редовете в таблицата е:
ТАВАН(LOG(ТАВАН(1e0 * @numrows / 404), 352)) + 1При 1 000 000 реда в таблицата това води до дълбочина на индекса от 3. При около 50 милиона реда дълбочината на индекса се увеличава до 4 нива, а при около 17,62 милиарда реда се увеличава до 5 нива.
Във всеки случай, по отношение на броя на групите и броя на редовете, като се приеме горния брой редове на страница, следната формула изчислява приблизителния брой логически четения за заявка 4:
CEILING(1e0 * @numgroups / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)Например, с 5 групи и 1 000 000 реда, получавате само 16 четения общо! Припомнете си, че базираната на сканиране стратегия по подразбиране за групираната заявка включва толкова логически четения, колкото CEILING(1e0 * @numrows / @rowsperpage). Използвайки заявка 1 като пример и приемайки около 404 реда на листова страница на индекса idx_sid_od, със същия брой редове от 1 000 000, получавате около 2 476 четения. Увеличете броя на редовете в таблицата с коефициент от 1 000 до 1 000 000 000, но запазете броя на групите фиксиран. Броят четения, необходими със стратегията за търсене, се променя много малко до 21, докато броят на четенията, необходими със стратегията за сканиране, нараства линейно до 2 475 248.
Красотата на стратегията за търсене е, че докато броят на групите е малък и фиксиран, тя има почти постоянно мащабиране по отношение на броя на редовете в таблицата. Това е така, защото броят на търсенията се определя от броя на групите, а дълбочината на индекса се отнася до броя на редовете в таблицата по логаритмичен начин, където базата на лога е броят на редовете, които се вписват в нелистовата страница. Обратно, базираната на сканиране стратегия има линейно мащабиране по отношение на броя на участващите редове.
Фигура 4 показва броя на прочитанията, изчислен за двете стратегии, приложени от заявка 1 и заявка 4, като се има предвид фиксиран брой групи от 5 и различен брой редове в основната таблица.
Фигура 4:#reads за стратегии за сканиране срещу търсене (5 групи)
Фигура 5 показва броя на прочитанията, изчислен за двете стратегии, като се има предвид фиксиран брой редове от 1 000 000 в основната таблица и различен брой групи.
Фигура 5:#reads за стратегии за сканиране срещу търсене (1M реда)
Много ясно можете да видите, че колкото по-висока е плътността на групата за групиране (по-малък брой групи) и колкото по-голяма е основната таблица, толкова повече се предпочита стратегията за търсене по отношение на броя на четенията. Ако се чудите за I/O модела, използван от всяка стратегия; разбира се, операциите за търсене на индекс извършват произволен I/O, докато операцията за сканиране на индекс извършва последователно I/O. Все пак е доста ясно коя стратегия е по-оптимална в по-екстремните случаи.
Що се отнася до цената на плана за заявка, отново, като използваме плана за заявка 4 на фигура 3 като пример, нека го разбием на отделните оператори в плана.
Обратно проектираната формула за цената на оператора Index Scan е:
0,002541259259259 + @numpages * 0,000740740740741 + @numgroups * 0,0000011В нашия случай, с 5 групи, всички от които се побират в една страница, цената е:
0,002541259259259 + 1 * 0,000740740740741 + 5 * 0,0000011 =0,0032875Цената, показана в плана, е същата.
Както преди, можете да оцените броя на страниците в нивото на листа на индекса въз основа на прогнозния брой редове на страница, като използвате формулата CEILING(1e0 * @numrows / @rowsperpage), която в нашия случай е CEILING(1e0 * @ numgroups / @groupsperpage). Да кажем, че индексът idx_sid побира около 600 реда на листова страница, с 5 групи, които ще трябва да прочетете една страница. Във всеки случай формулата за изчисляване на разходите за оператора Index Scan тогава става:
0,002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011Обратно проектираната формула за изчисляване на разходите за оператора вложени цикли е:
@executions * 0,00000418В нашия случай това означава:
@numgroups * 0,00000418За заявка 4, с 5 групи, получавате:
5 * 0,00000418 =0,0000209Цената, показана в плана, е същата.
Обратно проектираната формула за изчисляване на разходите за Топ оператор е:
@executions * @toprows * 0,00000001В нашия случай това означава:
@numgroups * 1 * 0,00000001С 5 групи получавате:
5 * 0,0000001 =0,0000005Цената, показана в плана, е същата.
Що се отнася до оператора Index Seek, тук получих голяма помощ от Пол Уайт; Благодаря ти, приятелю! Изчислението е различно за първото изпълнение и за повторното свързване (непърви изпълнения, които не използват повторно резултата от предишното изпълнение). Както направихме с оператора Index Scan, нека започнем с идентифицирането на константите на модела на разходите:
@randomio =0,003125 -- Разходи за произволен I/O @seqio =0,000740740740741 -- Разходи за последователен I/O @cpubase =0,000157 -- Базова цена на CPU @cpurow =0,0000011 -- CPU цена на CPU>За едно изпълнение, без приложена цел за ред, разходите за I/O и CPU са:
Разходи за I/O:@randomio + (@numpages - 1e0) * @seqio =0,002384259259259 + @numpages * 0,000740740740741Цена на процесора:@cpubase + @numrows * @cpurow =0 1 0 0 0 0 0 0 0 0.0Тъй като използваме TOP (1), имаме само една страница и един ред, така че разходите са:
Разходи за I/O:0,002384259259259 + 1 * 0,000740740740741 =0,003125 Цена на процесора:0,000157 + 1 * 0,0000011 =0,0001581Така че цената на първото изпълнение на оператора Index Seek в нашия случай е:
@firstexecution =0,003125 + 0,0001581 =0,0032831Що се отнася до разходите за повторно свързване, както обикновено, тя се състои от разходи за процесор и I/O. Нека ги наречем съответно @rebindcpu и @rebindio. С заявка 4, която има 5 групи, имаме 4 повторни свързвания (наречете го @rebinds). Цената на @rebindcpu е лесната част. Формулата е:
@rebindcpu =@rebinds * (@cpubase + @cpurow)В нашия случай това означава:
@rebindcpu =4 * (0,000157 + 0,0000011) =0,0006324Частта @rebindio е малко по-сложна. Тук формулата за изчисляване на разходите изчислява статистически очаквания брой отделни страници, които се очаква да прочетат повторното свързване, като се използва извадка със замяна. Ще наречем този елемент @pswr (за отделни страници с извадка със замяна). Идеята е, че имаме @indexdatapages брой страници в индекса (в нашия случай 2473) и @rebinds брой повторно свързване (в нашия случай 4). Ако приемем, че имаме еднаква вероятност да прочетем всяка дадена страница при всяко повторно свързване, колко различни страници се очаква да прочетем общо? Това е подобно на това да имаш торба с 2473 топки и четири пъти да теглиш на сляпо топка от торбата и след това да я връщаш в торбата. Статистически, колко различни топки се очаква да изтеглите общо? Формулата за това, използвайки нашите операнди, е:
@pswr =@indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))С нашите номера получавате:
@pswr =2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) =3,99757445099277След това изчислявате броя на редовете и страниците, които имате средно за група:
@grouprows =@cardinality * @density@grouppages =CEILING(@indexdatapages * @density)В нашата заявка 4, мощността е 1 000 000, а плътността е 1/5 =0,2. Така че получавате:
@grouprows =1000000 * 0.2 =200000@numpages =ТАВАН (2473 * 0.2) =495След това изчислявате I/O цената без филтриране (наречете го @io) като:
@io =@randomio + (@seqio * (@grouppages - 1e0))В нашия случай получавате:
@io =0,003125 + (0,000740740740741 * (495 - 1e0)) =0,369050925926054И накрая, тъй като търсенето извлича само един ред при всяко повторно свързване, вие изчислявате @rebindio, използвайки следната формула:
@rebindio =(1e0 / @grouprows) * ((@pswr - 1e0) * @io)В нашия случай получавате:
@rebindio =(1e0 / 200000) * ((3,99757445099277 - 1e0) * 0,369050925926054) =0,000005531288И накрая, цената на оператора е:
Операторска цена:@firstexecution + @rebindcpu + @rebindio =0,0032831 + 0,0006324 + 0,000005531288 =0,003921031288Това е същото като цената на оператора Index Seek, показана в плана за заявка 4.
Вече можете да обобщите разходите на всички оператори, за да получите пълната цена на плана за заявка. Получавате:
Query plan cost:0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011 + @numgroups * 0.00000418 + @numgroups * 0.00000001 + 0.0032831 + (@numgroups - 1e0) * 0.0001581 + (1e0 / (@numrows / @numgroups)) * (ТАВАН(1e0 * @numrows / @rowsperpage) * (1e0 - POWER((ТАВАН(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @) rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0,000740740740741 *) (CEILING((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))След опростяване получавате следната пълна формула за изчисляване на разходите за нашата стратегия за търсене:
0,005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011 + @numgroups * 0,0000011 + @numgroups * numgroups * numgroups * numgroups @num +1 ред @num / ред 162 m ) * (1e0 - POWER((ТАВАН(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0) * (0.003125 + (0.0740704 CEILING((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))Като пример, използвайки T-SQL, ето изчисляването на цената на плана за заявка с нашата стратегия за търсене за заявка 4:
ДЕКЛАРИРАНЕ @numrows КАТО FLOAT =1000000, @numgroups КАТО FLOAT =5, @rowsperpage КАТО FLOAT =404, @groupsperpage КАТО FLOAT =600; SELECT 0,005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011 + @numgroups * @numgroups * 0,00000011 + @numgroups * 0,000000011 + @numgroups * 0,00000011 + @numgroups * numgroups (1e0 - POWER((ТАВАН(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0) * (0.003125 + (0.000744074 * (@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0))) AS seeksplancost;Това изчисление изчислява цената 0,0072295 за заявка 4. Приблизителната цена, показана на фигура 3, е 0,0072299. Това е доста близо! Като упражнение изчислете разходите за заявка 5 и заявка 6, като използвате тази формула и се уверете, че получавате числа, близки до тези, показани на фигура 3.
Припомнете си, че формулата за изчисляване на разходите за стратегията по подразбиране, базирана на сканиране, е (наречете я Сканиране стратегия):
0,002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0,000740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005Използвайки заявка 1 като пример и приемайки 1 000 000 реда в таблицата, 404 реда на страница и 5 групи, прогнозната цена на плана за заявка за стратегията за сканиране е 3,5366.
Фигура 6 показва прогнозните разходи за план за заявка за двете стратегии, приложени от Заявка 1 (сканиране) и Заявка 4 (търсене), като се има предвид фиксиран брой групи от 5 и различен брой редове в основната таблица.
Фигура 6:цена за сканиране срещу стратегии за търсене (5 групи)
Фигура 7 показва прогнозните разходи за план за заявка за двете стратегии, като се има предвид фиксиран брой редове в основната таблица от 1 000 000 и различен брой групи.
Фигура 7:цена за сканиране срещу стратегии за търсене (1M реда)
Както е видно от тези констатации, колкото по-висока е плътността на групирането и колкото повече редове в основната таблица, толкова по-оптимална е стратегията за търсене в сравнение със стратегията за сканиране. Така че, в сценарии с висока плътност, не забравяйте да опитате решението, базирано на APPLY. Междувременно можем да се надяваме, че Microsoft ще добави тази стратегия като вградена опция за групирани заявки.
Заключение
Тази статия завършва серия от пет части за праговете за оптимизиране на заявки за заявки, които групират и обобщават данни. Една от целите на поредицата беше да се обсъдят спецификата на различните алгоритми, които оптимизаторът може да използва, условията, при които всеки алгоритъм е предпочитан и кога трябва да се намесите със собствените си пренаписвания на заявка. Друга цел беше да се обясни процеса на откриване на различните опции и тяхното сравнение. Очевидно същият процес на анализ може да се приложи към филтриране, присъединяване, прозорец и много други аспекти на оптимизирането на заявките. Надяваме се, че сега се чувствате по-подготвени да се справите с настройката на заявки от преди.