Сервизен пакет 2 за SQL Server 2014 беше пуснат миналия месец (прочетете бележките за изданието тук) и включва нов DBCC израз:DBCC CLONEDATABASE . Бях доста развълнуван да видя въведената тази команда, тъй като предоставя много лесно начин за копиране на схема на база данни, включително статистика , който може да се използва за тестване на производителността на заявката, без да се изисква цялото пространство, необходимо за данните в базата данни. Най-накрая намерих време да тествам DBCC CLONEDATABASE и разбирам ограниченията и трябва да кажа, че беше доста забавно.
Основните положения
Започнах, като създадох клонинг на базата данни AdventureWorks2014 и изпълних заявка към изходната база данни и след това към базата данни за клонинги:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE');GO SET STATISTICS IO ON;GOSET STATISTICS TIME ON;GOSET STATISTICS XML ON;GO USE [AdventureWorks2014];GOSET STATISTICS TIME ON;GO ИЗПОЛЗВАЙТЕ [AdventureWorks2014];GOOSArHeSELECT][ROMOSader] [h]Присъединете се към [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] =[d].[SalesOrderID]ORDER BY [SalesOrderDetailID];ИЗПОЛЗВАЙТЕ [AdventureWorks2014_CLONE];ИЗБЕРЕТЕ ИЗБЕРЕТЕ *ОТ [Продажби]. [SalesOrderHeader] [h]JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] =[d].[SalesOrderID]ORDER BY [SalesOrderDetailID];GO SET STATISTICS IO OFF;GOSET STATISTICS TIME OFF; GOSET STATISTICS XML OFF;GO
Ако погледна изхода I/O и TIME, мога да видя, че заявката към изходната база данни отне повече време и генерира много повече I/O, като и двете се очакват, тъй като клонираната база данни няма данни в нея:
/* SOURCE база данни */
Времена за изпълнение на SQL Server:
Време на процесора =0 ms, изминало време =0 ms.
Време за анализиране и компилиране на SQL Server:
Време на процесора =0 ms, изминало време =4 ms.
(засегнати 121317 реда)
Таблица 'SalesOrderHeader'. Брой на сканиране 0, логически четения 371567, физически четения 0, четене напред 0, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Таблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред четене 0.
Таблица 'SalesOrderDetail'. Брой на сканиране 5, логически четения 1361, физически четения 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред четене 0.
Таблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред четене 0.
(1 ред(ове) засегнат)
Времена за изпълнение на SQL Server:
Време на процесора =686 мс, изминало време =2548 мс.
/* CLONE база данни */
Времена за изпълнение на SQL Server:
Време на процесора =0 ms, изминало време =0 ms.
Време за анализиране и компилиране на SQL Server:
Време на процесора =12 ms, изминало време =12 ms.
(0 засегнати редове)
Таблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред четене 0.
Таблица 'SalesOrderHeader'. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред четене 0.
Таблица 'SalesOrderDetail'. Брой на сканиране 5, логически четения 0, физически четения 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред четене 0.
(1 ред(ове) засегнат)
Времена за изпълнение на SQL Server:
Време на процесора =0 ms, изминало време =83 ms.
Ако погледна плановете за изпълнение, те са еднакви и за двете бази данни, с изключение на действителните стойности (количеството данни, което действително премина през плана):
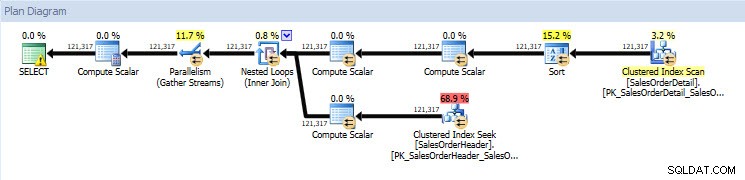 План за заявка за база данни AdventureWorks2014
План за заявка за база данни AdventureWorks2014
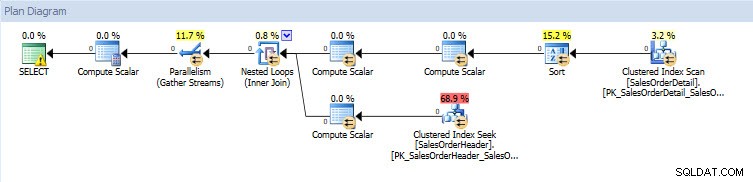 План за заявки за база данни AdventureWorks2014_CLONE
План за заявки за база данни AdventureWorks2014_CLONE
Тук е стойността на DBCC CLONEDATABASE е очевидно – мога да получа празно копие на база данни на всеки (поддръжка на продукти на Microsoft, моя колега DBA и т.н.) и да ги накарам да пресъздадат и проучат проблем и не се нуждаят от потенциално стотици GB дисково пространство, за да направят то. Публикацията на Melissa за юли в T-SQL във вторник съдържа подробна информация за това какво се случва по време на процеса на клониране, така че препоръчвам да прочетете това за повече информация.
Това ли?
Но… мога ли да направя повече с DBCC CLONEDATABASE ? Искам да кажа, това е страхотно, но мисля, че има много други неща, които мога да направя с празно копие на базата данни. Ако прочетете документацията за DBCC CLONEDATABASE , ще видите този ред:
Първата ми мисъл беше „оптимизатор на заявки – хм… мога ли да използвам това като опция за тестване на надстройки ?”
Е, клонираната база данни е само за четене, но все пак реших да се опитам да променя някои опции. Например, ако можех да променя режима на съвместимост, това би било наистина страхотно, тъй като тогава бих могъл да тествам промените на CE както в SQL Server 2014, така и в SQL Server 2016.
ИЗПОЛЗВАЙТЕ [главен]; ИЗПОЛЗВАЙТЕ ПРОМЕНЯТЕ БАЗА ДАННИ [AdventureWorks2014_CLONE] ЗАДАЙТЕ СЪВМЕСТИМОСТ_НИВО =110;
Получавам грешка:
Съобщение 3906, ниво 16, състояние 1Актуализирането на базата данни „AdventureWorks2014_CLONE“ не бе успешно, тъй като базата данни е само за четене.
Съобщение 5069, ниво 16, състояние 1
Изявлението ALTER DATABASE не бе успешно.
хм Мога ли да променя модела за възстановяване?
ПРОМЕНЯ БАЗА ДАННИ [AdventureWorks2014_CLONE] ЗАДАЙТЕ ВЪЗСТАНОВЯВАНЕ ПРОСТО С NO_WAIT;
Аз мога. Това не изглежда справедливо. Е, това е само за четене, мога ли да го променя?
ПРОМЕНЯ БАЗА ДАННИ [AdventureWorks2014_CLONE] НАСТРОЙТЕ ЧЕТЕНЕ_ЗАПИСАНЕ С NO_WAIT;
ДА! Преди да се развълнувате твърде много, позволете ми да оставя тази бележка от документацията тук:
Забележка Новогенерираната база данни, генерирана от DBCC CLONEDATABASE, не се поддържа за използване като производствена база данни и е предназначена основно за отстраняване на неизправности и диагностични цели. Препоръчваме да отделите клонираната база данни след създаването на базата данни.Ще повторя този ред от документацията, ще го удебеля и ще го сложа в червено като приятелско, но изключително важно напомняне:
Новогенерираната база данни, генерирана от DBCC CLONEDATABASE, не се поддържа за използване като производствена база данни и е предназначена основно за отстраняване на неизправности и диагностични цели.Е, това е добре с мен, определено нямаше да използвам това за производство, но сега мога да го използвам за тестване! СЕГА мога да променя режима на съвместимост и СЕГА мога да го архивирам и да го възстановя на друг екземпляр за тестване!
ИЗПОЛЗВАЙТЕ [master];ОТИДЕТЕ БАЗА ДАННИ ЗА РЕЗЕРВНИ КОПИЯ [AdventureWorks2014_CLONE] КЪМ ДИСК =N'C:\Backups\AdventureWorks2014_CLONE.bak' С INIT, NOFORMAT, STATS =10, NAME =N'CLONE_full'; Сървър 2016 */ ВЪЗСТАНОВЯВАНЕ НА БАЗА ДАННИ [AdventureWorks2014_CLONE]ОТ ДИСК =N'C:\Backups\AdventureWorks2014_CLONE.bak' WITHMOVE N'AdventureWorks2014_Data' КЪМ N'C:\Databases2014_Data' КЪМ N'C:\Databases2014_Data' КЪМ N'C:\Databases2014_Data' КЪМ N'C:\Databases2014. :\Databases\AdventureWorks2014_Log_3195542593.ldf',NOUNLOAD, ЗАМЕНЯТЕ, STATS =5;GO ПРОМЕНИ БАЗА ДАННИ [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL =130;ТОВА Е ГОЛЯМО.
В последната си публикация говорих за флаг за проследяване 2389 и тестване с новия Cardinality Estimator, защото, приятели, нуждате се да се тества с новия CE, преди да надстроите. Ако не тествате и ако промените режима на съвместимост на 120 (SQL Server 2014) или 130 (SQL Server 2016) като част от надстройката си, рискувате да работите в противопожарен режим, ако се сблъскате с регресии с новото СЕ. Сега може да сте добре и производителността може да е още по-добра след надграждане. Но... не бихте ли искали да сте сигурни?
Много често, когато споменавам тестване преди надстройка, ми казват, че няма среда, в която да направя тестването. Знам, че някои от вас имат тестова среда. Някои от вас имат Test, Dev, QA, UAT и кой знае какво още. Имате късмет.
За тези от вас, които твърдят, че изобщо нямате тестова среда, в която да тествате, ви давам
DBCC CLONEDATABASE. С тази команда нямате извинение да не стартирате най-често изпълняваните заявки и най-силните удари срещу клонинг на вашата база данни. Дори и да нямате тестова среда, имате своя собствена машина. Архивирайте клонираната база данни от производството, пуснете клонинга, възстановете архива във вашия локален екземпляр и след това тествайте. Клонираната база данни заема много малко място на диска и няма да предизвикате спорове за памет или I/O, тъй като няма данни. Вие ще да можете да валидирате плановете за заявка от клонинга спрямо тези от вашата производствена база данни. Освен това, ако възстановите на SQL Server 2016, можете да включите Query Store във вашето тестване! Активирайте Query Store, извършете тестването си в оригиналния режим на съвместимост, след което надстройте режима на съвместимост и тествайте отново. Можете да използвате Query Store, за да сравнявате заявки една до друга! (Можете ли да кажете, че в момента танцувам на стола си?)Съображения
Отново, това не трябва да е нещо, което бихте използвали в производството, и знам, че не бихте направили това, но си струва да се повтори, защото в текущото си състояние
DBCC CLONEDATABASEне е напълно завършен . Това е отбелязано в статията KB под поддържани обекти; обекти като оптимизирани за памет таблици и файлови таблици не се копират, Пълният текст не се поддържа и т.н.Сега клонираната база данни не е без недостатъци. Ако по невнимание стартирате възстановяване на индекс или актуализация на статистиката в тази база данни, току-що сте изтрили тестовите си данни. Ще загубите оригиналната статистика, което вероятно наистина сте искали на първо място. Например, ако проверя статистиката за клъстерирания индекс на SalesOrderHeader в момента, получавам това:
ИЗПОЛЗВАЙТЕ [AdventureWorks2014_CLONE];GODBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
Оригинални статистически данни за SalesOrderHeader
Сега, ако актуализирам статистиката спрямо тази таблица, получавам това:
АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderHeader] С ПЪЛЕН СКАН; ОТКРИ DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
Актуализирани (празни) статистически данни за SalesOrderHeader
Като допълнителна безопасност вероятно е добра идея да деактивирате автоматичните актуализации на статистиката:
ИЗПОЛЗВАЙТЕ [главен];БАЗА ДАННИ НА GOALTER [AdventureWorks2014_CLONE] ИЗКЛЮЧАЙТЕ AUTO_UPDATE_STATISTICS ИЗКЛЮЧЕНО С NO_WAIT;Ако случайно актуализирате статистиката неволно, изпълнявайки
DBCC CLONEDATABASEи преминаването през процеса на архивиране и възстановяване не е толкова трудно и ще го автоматизирате за нула време.Можете да добавяте данни към базата данни. Това може да е полезно, ако искате да експериментирате със статистически данни (напр. различни честоти на извадка, филтрирани статистически данни) и имате достатъчно място за съхранение, за да съхранявате копие на данните от таблицата.
Без данни в базата данни очевидно няма да получите надеждно представителна продължителност и I/O данни. Това е добре. Ако имате нужда от данни за истинското използване на ресурсите, тогава имате нужда от копие на вашата база данни с всички данни в нея.
DBCC CLONEDATABASEнаистина се отнася за тестване на ефективността на заявката; това е. Това не е заместител на традиционното тестване за надстройка по никакъв начин – но е нова опция за валидиране на това как SQL Server оптимизира заявка с различни версии и режими на съвместимост. Приятно тестване!



