Въведение
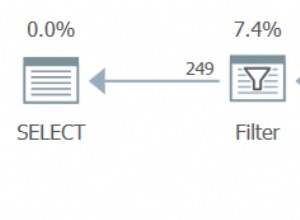
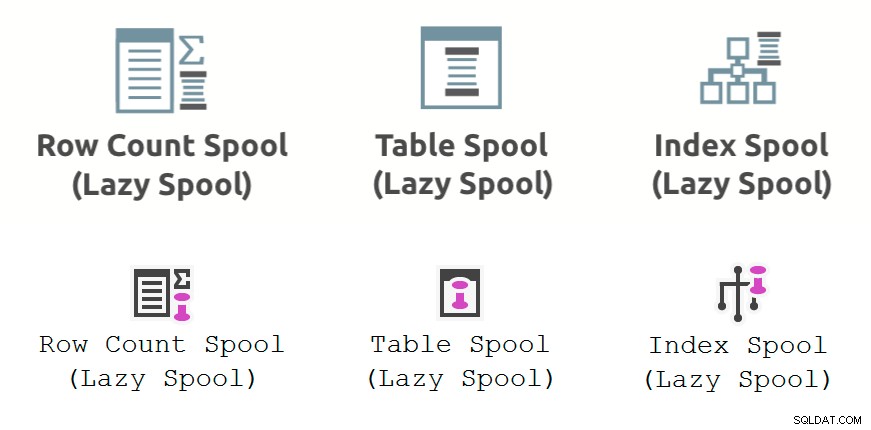
Шпули за производителност са мързеливи шпули, добавени от оптимизатора за намаляване на прогнозната цена на вътрешната страна на съединявания на вложени цикли . Предлагат се в три разновидности:Lazy Table Spool , Lazy Index Spool , и Spool за броене на мързеливи редове . Примерна форма на план, показваща макара за производителност на мързелива маса, е по-долу:
Въпросите, на които реших да отговоря в тази статия, са защо, как и кога оптимизаторът на заявки въвежда всеки тип пул за производителност.
Точно преди да започнем, искам да подчертая един важен момент:има два различни типа присъединяване на вложен цикъл в плановете за изпълнение. Ще се позова на сорта с външни препратки като канат и типа с предикат за присъединяване на самия оператор за свързване като съединяване с вложени цикли . За да бъде ясно, тази разлика е за операторите на план за изпълнение , а не синтаксис на T-SQL заявка. За повече подробности, моля, вижте моята свързана статия.
Спулове за производителност
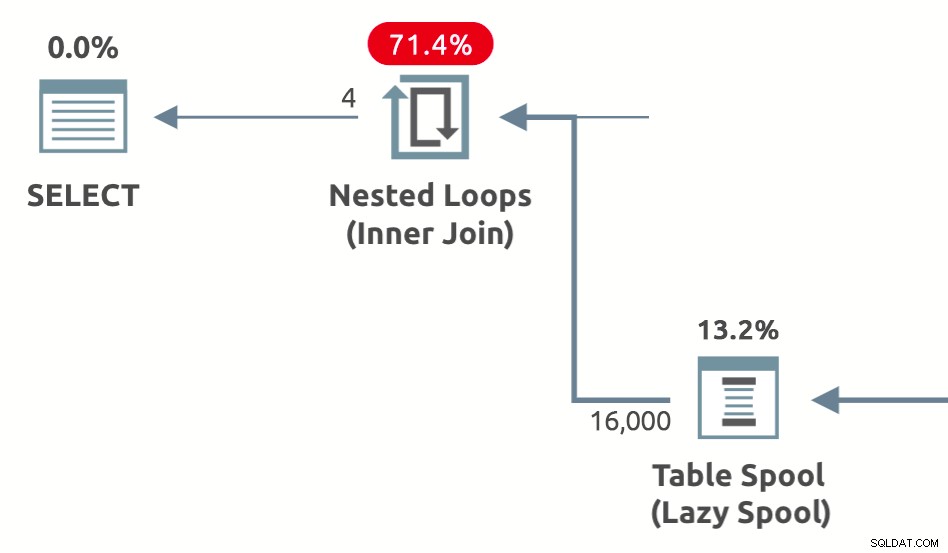
Снимката по-долу показва производителната макара Оператори на план за изпълнение, както е показано в Plan Explorer (горен ред) и SSMS 18.3 (долен ред):
Общи бележки
Всички шпули за производителност самързеливии . Работната маса на макарата се запълва постепенно, ред по ред, докато редовете преминават през макарата. (Нетърпеливите пулове, за разлика от тях, консумират всички входни данни от своя дъщерен оператор, преди да върнат редовете на своя родител).
Шпулите за производителност винаги се появяват отвътрешната страна (долният вход в графичните планове за изпълнение) на вложен оператор за присъединяване или прилагане на цикли. Общата идея е да се кешират и възпроизвеждат резултатите, като се спестяват многократни изпълнения на вътрешни оператори, където е възможно.
Когато една макара е в състояние да възпроизведе отново кеширани резултати, това е известно като превъртане назад . Когато макарата трябва да изпълни своите дъщерни оператори, за да получи правилни данни, превързване се случва.
Може да ви е полезно да помислите за превързване на макара като пропуск в кеша и превъртане назад като удар в кеш паметта.
Lazy Table Spool
Този тип шпула за производителност може да се използва както с apply и съединяване на вложени цикли .
Прилагане
Превързване (пропускане на кеша) се появява всеки път, когато има външна препратка промени в стойността. Мързелива шпула за маса се свързва отново чрез отрязване работната му маса и пълно повторно заселване от неговите дъщерни оператори.
Превъртане назад (попадане в кеша) възниква, когато вътрешната страна се изпълнява със същото външни референтни стойности като непосредствено предходните итерация на цикъл. Превъртането назад възпроизвежда кешираните резултати от работната маса на макарата, спестявайки разходите за повторно изпълнение на операторите на плана под макарата.
Забележка:мързелива таблица с пулове кешира само резултати за един набор от прилагане външна препратка стойности наведнъж.
Присъединяване на вложени цикли
Шпулата на мързелива таблица се попълва веднъж по време на първата итерация на цикъла. Шпулата пренавива съдържанието си за всяка следваща итерация на присъединяването. При присъединяването с вложени цикли вътрешната страна на съединението е статичен набор от редове, тъй като предикатът за присъединяване е върху самото съединение. Следователно статичният набор от редове от вътрешната страна може да се кешира и използва многократно чрез макарата. Вложените цикли се присъединяват към макарата с производителност никога не се свързват повторно.
Капа за броене на мързеливи редове
Шпулата за броене на редове е малко повече от Таблица без колони. Той кешира съществуването на ред, но не проектира данни за колони. Освен че отбелязва съществуването му и споменава, че може да е индикация за грешка в изходната заявка, няма да имам да казвам повече за пуловете за броя на редовете.
От този момент нататък всеки път, когато видите „папула за таблица“ в текста, моля, прочетете го като „папула на таблица (или брой редове)“, защото те са толкова сходни.
Lazy Index Spool
Lazy Index Spool операторът е достъпен само с прилагане .
Индексната макара поддържа работна маса, която не е съкратена когато външна препратка стойностите се променят. Вместо това към съществуващия кеш се добавят нови данни, индексирани от външните референтни стойности. Шпулата с мързеливи индекси се различава от ленивата шпула за маса по това, че може да възпроизвежда резултати от всякак предишна итерация на цикъл, а не само най-новата.
Следващата стъпка в разбирането кога пуловете за ефективност се появяват в плановете за изпълнение изисква разбиране на това как работи оптимизаторът.
Фон на оптимизатора
Изходната заявка се преобразува в представяне на логическо дърво чрез синтактичен анализ, алгебризация, опростяване и нормализиране. Когато полученото дърво не отговаря на изискванията за тривиален план, базираният на разходите оптимизатор търси логически алтернативи, които гарантирано ще дадат същите резултати, но при по-ниска прогнозна цена.
След като оптимизаторът генерира потенциални алтернативи, той прилага всяка от тях, използвайки подходящи физически оператори, и изчислява прогнозните разходи. Окончателният план за изпълнение се изгражда от най-ниската цена, открита за всяка група оператори. Можете да прочетете повече подробности за процеса в моята поредица Deep Dive за оптимизатор на заявки.
Общите условия, необходими за показване на пул за производителност в окончателния план на оптимизатора са:
- Оптимизаторът трябва да проучва логическа алтернатива, която включва логическа шпула в генериран заместител. Това е по-сложно, отколкото звучи, така че ще разопаковам подробностите в следващия основен раздел.
- Логическата шпула трябва да е приложима като физическа макара оператор в машината за изпълнение. За съвременните версии на SQL Server това по същество означава, че всички ключови колони в една индексна спула трябва да са от сравнима тип, не повече от 900 байта* общо, с 64 ключови колони или по-малко.
- Нанай-доброто пълният план след оптимизация на базата на разходи трябва да включва една от алтернативите на макарата. С други думи, всеки базиран на разходите избор, направен между опциите за макара и без макара, трябва да излезе в полза на макарата.
* Тази стойност е твърдо кодирана в SQL Server и не е променена след увеличението до 1700 байта за неклъстерирани индексни ключове от SQL Server 2016 нататък. Това е така, защото индексът на макарата е клъстериран индекс, а не неклъстериран индекс.
Правила за оптимизатор
Не можем да посочим пул, използвайки T-SQL, така че получаването на такава в план за изпълнение означава, че оптимизаторът трябва да избере да я добави. Като първа стъпка това означава, че оптимизаторът трябва да включи логическа шпула в една от алтернативите, които избере да изследва.
Оптимизаторът не прилага изчерпателно всички правила за логическа еквивалентност, които знае, към всяко дърво на заявки. Това би било разточително, като се има предвид целта на оптимизатора да създаде разумен план бързо. Има множество аспекти на това. Първо, оптимизаторът работи на етапи, като първо се изпробват по-евтините и по-често приложими правила. Ако разумен план бъде намерен в ранен етап или заявката не отговаря на изискванията за по-късни етапи, усилията за оптимизация може да бъдат прекратени по-рано с най-ниския план на разходите, намерен досега. Тази стратегия помага да се предотврати прекарването на повече време за оптимизация, отколкото се спестява чрез постепенни подобрения на разходите.
Съвпадение на правила
Всеки логически оператор в дървото на заявката се проверява бързо за съвпадение на шаблон спрямо правилата, налични в текущия етап на оптимизация. Например, всяко правило ще съвпада само с подмножество от логически оператори и може също да изисква определени свойства, като например гарантирано сортирано въвеждане. Едно правило може да съвпада с отделна логическа операция (единична група) или множество последователни групи (подраздел от плана).
След съпоставяне, кандидат правилото се иска да генерира стойност на обещанието . Това е число, което показва колко вероятно е настоящото правило да доведе до полезен резултат, като се има предвид местния контекст. Например, правило може да генерира по-висока стойност на обещанието, когато целта има много дубликати на входа си, голям приблизителен брой редове, гарантирано сортирани входни данни или някакво друго желано свойство.
След като бъдат идентифицирани обещаващи правила за проучване, оптимизаторът ги сортира в реда на стойността на обещанието и започва да ги моли да генерират нови логически заместители. Всяко правило може да генерира един или повече заместители, които по-късно ще бъдат приложени с помощта на физически оператори. Като част от този процес се изчислява прогнозна цена.
Смисълът на всичко това, що се отнася до пуловете за производителност, е, че формата и свойствата на логическия план трябва да са благоприятни за съвпадение на правилата, съвместими с макара, а локалният контекст трябва да произвежда достатъчно висока обещаваща стойност, която оптимизаторът избира да генерира заместители, използвайки правилото .
Правила за спулиране
Има редица правила, които изследват логически присъединяване на вложени цикли или приложете алтернативи. Някои от тези правила могат да произвеждат един или повече заместители с определен тип шпула за изпълнение. Други правила, които съвпадат с вложени цикли, се присъединяват или прилагат, никога не генерират алтернатива на буфера.
Например правилото ApplyToNL прилага логическо прилагане като физически цикли се свързват с външни препратки. Това правило може да генерира няколко алтернативи всеки път, когато работи. В допълнение към оператора за физическо свързване, всеки заместващ може да съдържа макара с мързеливи маси, мързелива индексна шпула или изобщо без макара. Заместителите на логическите макари по-късно се внедряват индивидуално и се оценяват като подходящо въведени физически пулове, чрез друго правило, наречено BuildSpool .
Като втори пример, правилото JNtoIdxLookup прилага логическо присъединяване като физическо прилагане , с индекс за търсене непосредствено от вътрешната страна. Това правилоникога генерира алтернатива с компонент на макарата. JNtoIdxLookup се оценява рано и връща висока обещаваща стойност, когато съвпада, така че прости планове за търсене на индекси се намират бързо.
Когато оптимизаторът открие евтина алтернатива като тази в началото, по-сложните алтернативи могат да бъдат агресивно изрязани или пропуснати изцяло. Мотивът е, че няма смисъл да се търсят опции, които е малко вероятно да се подобрят при вече намерен алтернативен вариант с ниска цена. По същия начин не си струва да проучвате по-нататък, ако текущият най-добър завършен план вече има достатъчно ниска обща цена.
Трети пример за правило:Правилото JNtoNL е подобен на ApplyToNL , но прилага само физическо присъединяване на вложен цикъл , с макара за мързелива маса или изобщо без макара. Това правилоникога генерира индексна шпула, защото този тип шпула изисква прилагане.
Спул Генериране и изчисляване на разходите
Правило, което е способно за генериране на логическа шпула не е задължително да го прави всеки път, когато бъде извикана. Би било разточително да се генерират логични алтернативи, които нямат почти никакъв шанс да бъдат избрани като най-евтини. Съществува и цена за генериране на нови алтернативи, които от своя страна могат да доведат до още повече алтернативи – всяка от които може да се нуждае от внедряване и изчисляване на разходите.
За да управлява това, оптимизаторът внедрява обща логика за всички правила с възможност за пулиране, за да определи кой(ите) тип(ове) алтернатива на буфера да генерира въз основа на условията на местния план.
Присъединяване на вложени цикли
За присъединяване на вложени цикли , шансът да се снабдина шпула за мързелива маса се увеличава в съответствие с:
- Прогнозният брой редове на външния вход на съединението.
- Прогнозна цена на оператори на вътрешния план.
Цената на макарата се изплаща от направени спестявания, като се избягват операциите от вътрешната страна на оператора. Спестяванията се увеличават с повече вътрешни итерации и по-високи вътрешни разходи. Това е особено вярно, тъй като моделът на разходите присвоява относително ниски стойности на I/O и CPU стойности за пренавиване на таблицата (посещения в кеша). Запомнете, че макарата на таблицата при присъединяване на вложени цикли винаги изпитва само пренавиване, тъй като липсата на параметри означава, че наборът от данни от вътрешната страна е статичен.
Една макара може да съхранява данни по-плътно отколкото операторите, които го хранят. Например, клъстериран индекс на основна таблица може да съхранява средно 100 реда на страница. Да речем, че заявката се нуждае само от една стойност на целочислена колона от всеки широк клъстериран индексен ред. Съхраняването само на целочислената стойност в работната таблица на макарата означава, че могат да се съхраняват над 800 такива реда на страница. Това е важно, тъй като оптимизаторът оценява отчасти цената на табличната макара, като използва оценка на броя на страниците на работната таблица необходими. Други фактори за изчисляване на разходите включват цената на процесора на ред, участваща в писането и четенето на макарата, над прогнозния брой повторения на цикъла.
Вероятно оптимизаторът е твърде запален, за да добави мързеливи шпули за маса към вътрешната страна на присъединяване на вложени цикли. Независимо от това, решението на оптимизатора винаги има смисъл от гледна точка на прогнозните разходи. Аз лично считам присъединяването на вложените цикли като висок риск , тъй като те могат бързо да станат бавни, ако оценката за мощност на входа за присъединяване е твърде ниска.
Макара за маса може помага за намаляване на разходите, но не може напълно да скрие производителността в най-лошия случай на присъединяване на наивно вложени цикли. Индексираното прилагане на присъединяване обикновено е за предпочитане и по-устойчиво на грешки при оценката. Също така е добра идея да пишете заявки, които оптимизаторът може да реализира с хеш или обединяване при сливане, когато е подходящо.
Прилагане на Lazy Table Spool
За всречение , шансовете за получаване на шпула за мързелива маса се увеличава с прогнозния брой дублирани присъединете ключови стойности на външния вход на приложението. При повече дубликати има статистически по-голям шанс макарата да пренавие своите текущо съхранени резултати при всяка итерация. Приложна мързелива маса макара с по-ниска прогнозна цена има по-голям шанс да бъде включена в окончателния план за изпълнение.
Когато редовете, пристигащи на външния вход за прилагане, нямат особена подредба, оптимизаторът прави статистическа оценка колко е вероятно всяка итерация да доведе до евтино пренавиване или скъпо превързване. Тази оценка използва данни от стъпките на хистограмата, когато са налични, но дори и този най-добър сценарий е по-скоро обосновано предположение. Без гаранция редът на редовете, пристигащи на външния вход за прилагане, е непредсказуем.
Същите правила за оптимизатор, които генерират алтернативи на логически буфери, могат също укажете, че операторът за прилагане изисква сортирани редове на външния си вход. Това увеличава максимално мързеливото навиване назад защото всички дубликати са гарантирани, че ще бъдат срещнати в блок. Когато външният ред на сортиране е гарантиран, или чрез запазена подредба, или чрез изрично Сортиране , цената на макарата е много намалена. Оптимизаторът взема предвид влиянието на реда на сортиране върху броя на превъртанията и превързванията на макара.
Планове с Сортиране на външния вход за прилагане и Lazy Table Spool на вътрешния вход са доста често срещани. Оптимизацията за сортиране от външната страна все още може да се окаже контрапродуктивна. Например, това може да се случи, когато оценката на външната страна е толкова ниска, че сортирането в крайна сметка се разлива в tempdb .
Прилагане на Lazy Index Spool
За всречение , получаване на мързелива индексна шпула алтернативата зависи от формата на плана, както и от разходите.
Оптимизаторът изисква:
- Някои дублирани обединете стойности на външния вход.
- равенство предикат на присъединяване (или логически еквивалент, който оптимизаторът разбира, като
x <= y AND x >= y). - Гаранция че външните препратки сауникални под предложената макара с мързелив индекс.
В плановете за изпълнение изискваната уникалност често се осигурява от агрегатно групиране по външните препратки или скаларен агрегат (този без група по). Уникалността може да се осигури и по други начини, например чрез съществуването на уникален индекс или ограничение.
Пример за играчка, който показва формата на плана, е по-долу:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
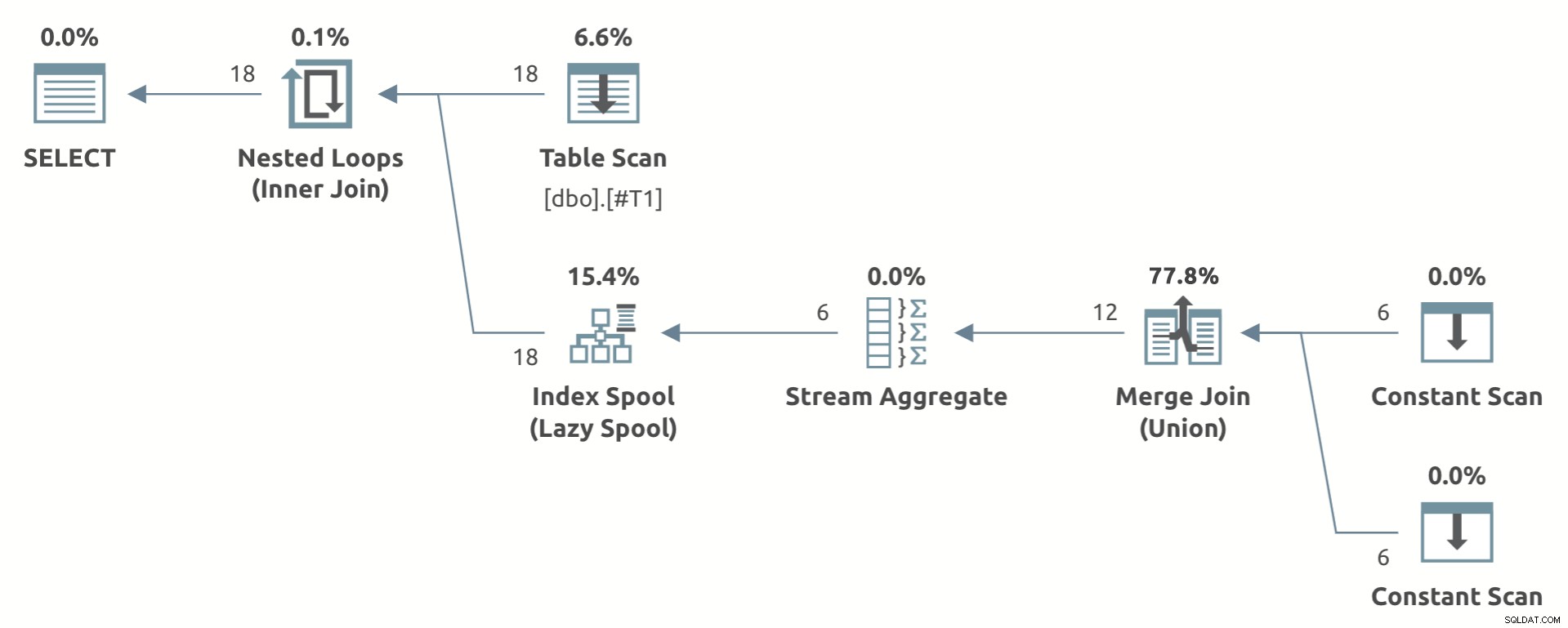
Обърнете внимание на Агрегата на потока под Lazy Index Spool .
Ако изискванията за формата на плана са изпълнени, оптимизаторът често генерира алтернатива на мързелив индекс (при спазване на споменатите по-рано предупреждения). Дали крайният план включва мързелив индекс шпула или не зависи от разходите.
Индексна шпула срещу таблици
Броят на прогнозираните превъртания назад и превързва за мързелива индексна шпула е същото като за мързелива маса макарабез сортирано прилагане на външен вход.
Това може да изглежда като доста жалко състояние на нещата. Основното предимство на индексната шпула е, че тя кешира всички по-рано виждани резултати. Това би трябвало да направи индексната шпула назад по-вероятно, отколкото за шпула за маса (без сортиране по външен вход) при същите обстоятелства. Моето разбиране е, че тази странност съществува, защото без нея оптимизаторът твърде често би избирал индексна шпула.
Независимо от това, моделът на разходите се коригира за горното до известна степен, като използва различни начални и последващи редове за I/O и стойности на CPU за индексни и таблици. Нетният ефект е, че индексната макара обикновено се струва по-ниска от таблицата без сортиран външен вход, но не забравяйте ограничителните изисквания за формата на плана, които правят мързеливите шпули с индекс относително рядко.
И все пак, основният разходен конкурент на индекса на мързелива макара е макарата за маса с сортиран външен вход. Интуицията за това е доста ясна:Сортираният външен вход означава, че макарата на таблицата е гарантирано да вижда всички дублиращи се външни препратки последователно. Това означава, че ще свърже отново само веднъж за отделна стойност и превъртане назад за всички дубликати. Това е същото като очакваното поведение на шпула с индекс (поне логично казано).
На практика е по-вероятно една индексна шпула да бъде предпочетена пред оптимизирана за сортиране таблица за по-малко дублирани стойности на приложим ключ. Наличието на по-малко дублирани клавиши намалява превъртането назад предимство на оптимизираната за сортиране пулпа за таблици в сравнение с отбелязаните по-рано оценки за „неудачна“ индексна шпула.
Опцията за индексна макара също е от полза, тъй като приблизителната цена на Сортиране от външна страна на шпула за маса се увеличава. Това най-често се свързва с повече (или по-широки) редове в тази точка от плана.
Флагове и съвети за проследяване
-
Спулите за производителност могат да бъдатдеактивирани с леко документиран флаг за проследяване 8690 , или документираният намек за заявка
NO_PERFORMANCE_SPOOLна SQL Server 2016 или по-нова версия. -
Недокументиран флаг за проследяване 8691 може да се използва (на тестова система) за винаги добавяне на шпула за производителност когато е възможно. Типът от мързелива шпула, която получавате (брой на редове, таблица или индекс), не може да бъде принудена; все още зависи от оценката на разходите.
-
Недокументиран флаг за проследяване 2363 може да се използва с новия модел за оценка на мощността, за да видите извличането на отличителната оценка на външния вход към приложение и оценката на мощността като цяло.
-
Недокументиран флаг за проследяване 9198 може да се използва за деактивиране на лениви пулове за производителност на индекси конкретно. Вместо това може да получите мързелива таблица или пул за броене на редове (със или без оптимизиране на сортиране), в зависимост от разходите.
-
Недокументиран флаг за проследяване 2387 може да се използва за намаляване на цената на процесора на четене на редове от мързелив индекс шпула . Този флаг засяга общите оценки на разходите на процесора за четене на диапазон от редове от b-дърво. Този флаг има тенденция да прави избора на шпула на индекса по-вероятен поради съображения за цена.
Други флагове за проследяване и методи за определяне кои правила за оптимизатор са били активирани по време на компилацията на заявка могат да бъдат намерени в моята поредица Deep Dive на оптимизатора на заявки.
Последни мисли
Има много вътрешни детайли, които влияят върху това дали крайният план за изпълнение използва макара за производителност или не. Опитах се да обхвана основните съображения в тази статия, без да навлизам твърде далеч в изключително сложните детайли на формулите за изчисляване на разходите за оператор на макара. Надяваме се, че тук има достатъчно общи съвети, които да ви помогнат да определите възможните причини за конкретен тип макара за производителност в план за изпълнение (или липса на такава).
Мисля, че е справедливо да се каже, че макарите с производителност често получават лош рап. Част от това без съмнение е заслужено. Много от вас ще са виждали демонстрация, в която планът се изпълнява по-бързо без „мапула за производителност“, отколкото с нея. До известна степен това не е неочаквано. Съществуват крайни случаи, моделът за изчисляване на разходите не е перфектен и без съмнение демонстрациите често включват планове с лоши оценки за кардиналност или други проблеми, ограничаващи оптимизатора.
Въпреки това, понякога ми се иска SQL Server да предоставя някакво предупреждение или друга обратна връзка, когато прибягва до добавяне на мързелива таблица за пулове към присъединяване на вложени цикли (или приложение без използван поддържащ индекс от вътрешната страна). Както бе споменато в основната част, това са ситуациите, които намирам, че най-често се грешат, когато оценките за кардиналите се оказват ужасно ниски.
Може би един ден оптимизаторът на заявки ще вземе предвид някаква концепция за риск за планиране на избора или ще предостави по-„адаптивни“ възможности. Междувременно си струва да поддържате връзките на вложените цикли с полезни индекси и да избягвате писането на заявки, които могат да бъдат реализирани само с помощта на вложени цикли, където е възможно. Разбира се, обобщавам, но оптимизаторът има тенденция да работи по-добре, когато има повече възможности за избор, разумна схема, добри метаданни и управляеми T-SQL изрази, с които да работи. Както и аз, като се замисля.
Други статии за макара
Непроизводителните пулове се използват за много цели в SQL Server, включително:
- Защита за Хелоуин
- Някои функции на прозорец в режим на ред
- Изчисляване на множество агрегати
- Оптимизиращи изрази, които променят данните