Често, когато пишем съхранена процедура, искаме тя да се държи по различен начин въз основа на въведеното от потребителя. Нека разгледаме следния пример:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Тази съхранена процедура, която създадох в базата данни AdventureWorks2017, има два параметъра:@CustomerID и @SortOrder. Първият параметър, @CustomerID, засяга редовете, които трябва да бъдат върнати. Ако конкретен клиентски идентификатор се предаде на съхранената процедура, тогава тя връща всички поръчки (топ 10) за този клиент. В противен случай, ако е NULL, тогава съхранената процедура връща всички поръчки (топ 10), независимо от клиента. Вторият параметър, @SortOrder, определя как ще бъдат сортирани данните – по OrderDate или по SalesOrderID. Забележете, че само първите 10 реда ще бъдат върнати според реда на сортиране.
Така потребителите могат да повлияят на поведението на заявката по два начина — кои редове да върнат и как да ги сортират. За да бъдем по-точни, има 4 различни поведения за тази заявка:
- Връщане на първите 10 реда за всички клиенти, сортирани по OrderDate (поведение по подразбиране)
- Върнете първите 10 реда за конкретен клиент, сортирани по Дата на поръчка
- Връщане на първите 10 реда за всички клиенти, сортирани по SalesOrderID
- Връщане на първите 10 реда за конкретен клиент, сортирани по SalesOrderID
Нека да тестваме съхранената процедура с всичките 4 опции и да разгледаме плана за изпълнение и IO на статистиката.
Връщане на първите 10 реда за всички клиенти, сортирани по дата на поръчка
Следва кодът за изпълнение на съхранената процедура:
EXECUTE Sales.GetOrders; GO
Ето плана за изпълнение:
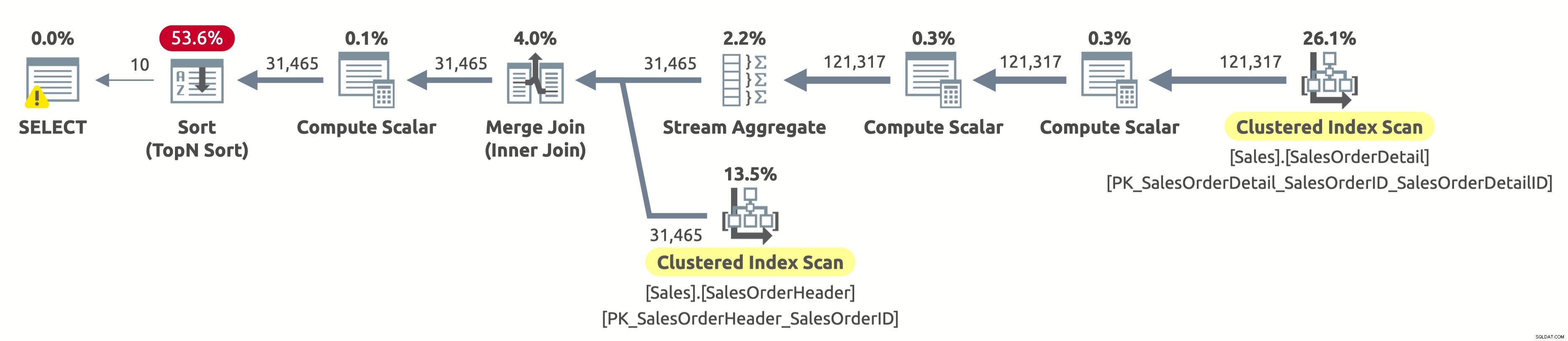
Тъй като не сме филтрирали по клиент, трябва да сканираме цялата таблица. Оптимизаторът избра да сканира и двете таблици, използвайки индекси на SalesOrderID, което позволява ефективен Stream Aggregate, както и ефективно Merge Join.
Ако проверите свойствата на оператора Clustered Index Scan в таблицата Sales.SalesOrderHeader, ще намерите следния предикат:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] като [SalesOrders].[CustomerID]=[ @CustomerID] ИЛИ [@CustomerID] Е NULL. Процесорът на заявки трябва да оцени този предикат за всеки ред в таблицата, което не е много ефективно, защото винаги ще се оценява като истина.
Все още трябва да сортираме всички данни по OrderDate, за да върнем първите 10 реда. Ако имаше индекс на OrderDate, тогава оптимизаторът вероятно щеше да го използва, за да сканира само първите 10 реда от Sales.SalesOrderHeader, но няма такъв индекс, така че планът изглежда добре, като се имат предвид наличните индекси.
Ето изхода от IO на статистиката:
- Таблица „SalesOrderHeader“. Брой на сканирането 1, логически отчита 689
- Таблица „SalesOrderDetail“. Брой сканиране 1, логически четения 1248
Ако питате защо има предупреждение в оператора SELECT, тогава това е предупреждение за прекомерно предоставяне. В този случай това не е защото има проблем в плана за изпълнение, а по-скоро защото процесорът на заявки е поискал 1024 КБ (което е минимумът по подразбиране) и е използвал само 16 КБ.
Понякога плановото кеширане не е толкова добра идея
След това искаме да тестваме сценария за връщане на първите 10 реда за конкретен клиент, сортиран по OrderDate. По-долу е кодът:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Планът за изпълнение е абсолютно същият като преди. Този път планът е много неефективен, защото сканира и двете таблици само за да върне 3 поръчки. Има много по-добри начини за изпълнение на тази заявка.
Причината в този случай е кеширането на плана. Планът за изпълнение е генериран при първото изпълнение въз основа на стойностите на параметрите в това конкретно изпълнение - метод, известен като подслушване на параметри. Този план беше съхранен в кеша на плана за повторна употреба и отсега нататък всяко извикване към тази съхранена процедура ще използва повторно същия план.
Това е пример, когато кеширането на план не е толкова добра идея. Поради естеството на тази съхранена процедура, която има 4 различни поведения, очакваме да получим различен план за всяко поведение. Но ние сме останали с един план, който е добър само за една от 4-те опции, въз основа на опцията, използвана при първото изпълнение.
Нека деактивираме кеширането на планове за тази съхранена процедура, само за да можем да видим най-добрия план, който оптимизаторът може да измисли за всяко едно от другите 3 поведения. Ще направим това, като добавим WITH RECOMPILE към командата EXECUTE.
Връщане на първите 10 реда за конкретен клиент, сортирани по дата на поръчка
Следва кодът за връщане на първите 10 реда за конкретен клиент, сортиран по OrderDate:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Следва планът за изпълнение:
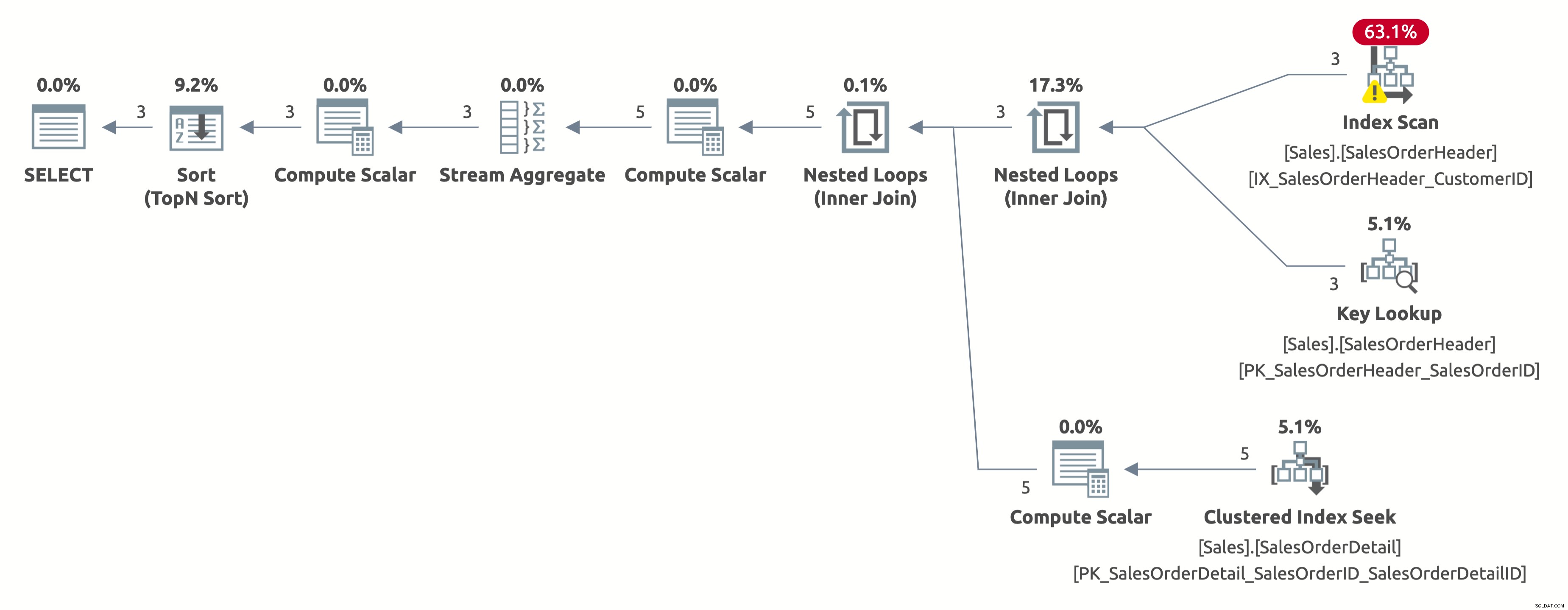
Този път получаваме по-добър план, който използва индекс на CustomerID. Оптимизаторът оценява правилно 2,6 реда за CustomerID =11006 (действителното число е 3). Но забележете, че той извършва сканиране на индекс вместо търсене на индекс. Той не може да извърши търсене на индекс, защото трябва да оцени следния предикат за всеки ред в таблицата:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] като [SalesOrders].[CustomerID]=[@CustomerID].[@CustomerID] ] ИЛИ [@CustomerID] Е NULL.
Ето изхода от IO на статистиката:
- Таблица „SalesOrderDetail“. Брой на сканирането 3, логически показания 9
- Таблица „SalesOrderHeader“. Сканиране 1, логически отчитания 66
Връщане на първите 10 реда за всички клиенти, сортирани по SalesOrderID
Следва кодът за връщане на първите 10 реда за всички клиенти, сортирани по SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Следва планът за изпълнение:
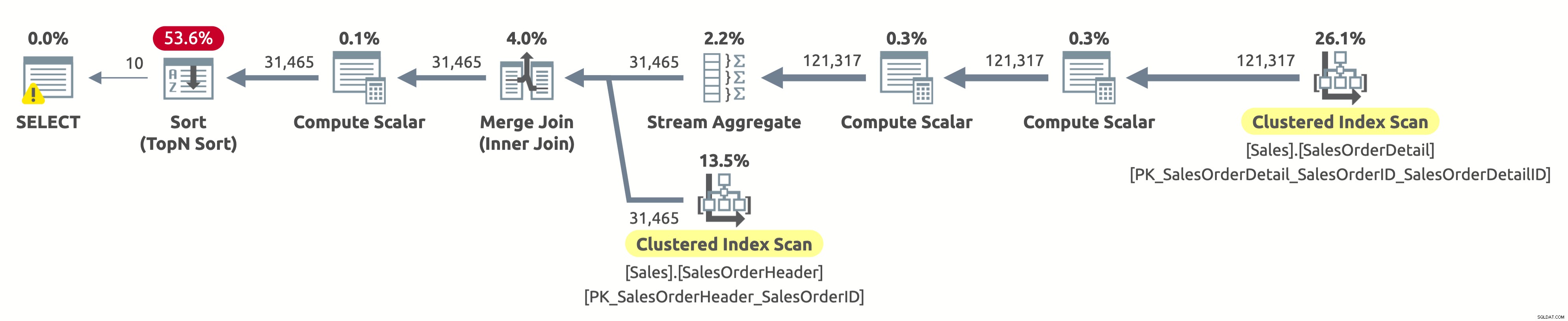
Хей, това е същият план за изпълнение като в първия вариант. Но този път нещо не е наред. Вече знаем, че клъстерираните индекси на двете таблици са сортирани по SalesOrderID. Знаем също, че планът сканира и двете в логическия ред, за да запази реда на сортиране (свойството Ordered е настроено на True). Операторът Merge Join също запазва реда на сортиране. Тъй като сега искаме да сортираме резултата по SalesOrderID и той вече е сортиран по този начин, тогава защо трябва да плащаме за скъп оператор за сортиране?
Е, ако проверите оператора Sort, ще забележите, че сортира данните според Expr1004. И ако проверите оператора Compute Scalar вдясно от оператора Sort, тогава ще откриете, че Expr1004 е както следва:

Не е хубава гледка, знам. Това е изразът, който имаме в клаузата ORDER BY на нашата заявка. Проблемът е, че оптимизаторът не може да оцени този израз по време на компилиране, така че трябва да го изчисли за всеки ред по време на изпълнение и след това да сортира целия набор от записи въз основа на това.
Резултатът от IO на статистиката е точно като при първото изпълнение:
- Таблица „SalesOrderHeader“. Брой на сканирането 1, логически отчита 689
- Таблица „SalesOrderDetail“. Брой сканиране 1, логически четения 1248
Връщане на първите 10 реда за конкретен клиент, сортиран по SalesOrderID
Следва кодът за връщане на първите 10 реда за конкретен клиент, сортиран по SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Планът за изпълнение е същият като при втората опция (връщане на първите 10 реда за конкретен клиент, сортирани по Дата на поръчка). Планът има същите два проблема, които вече споменахме. Първият проблем е извършването на сканиране на индекс, а не на търсене на индекс поради израза в клаузата WHERE. Вторият проблем е извършването на скъпо сортиране поради израза в клаузата ORDER BY.
И така, какво да правим?
Нека първо си припомним с какво си имаме работа. Имаме параметри, които определят структурата на заявката. За всяка комбинация от стойности на параметрите получаваме различна структура на заявката. В случай на параметър @CustomerID, двете различни поведения са NULL или NOT NULL и засягат клаузата WHERE. В случая на параметъра @SortOrder има две възможни стойности и те засягат клаузата ORDER BY. Резултатът е 4 възможни структури на заявки и бихме искали да получим различен план за всяка от тях.
Тогава имаме два различни проблема. Първият е кеширане на планове. Има само един план за съхранената процедура и той ще бъде генериран въз основа на стойностите на параметрите при първото изпълнение. Вторият проблем е, че дори когато се генерира нов план, той не е ефективен, защото оптимизаторът не може да оцени „динамичните“ изрази в клаузата WHERE и в клаузата ORDER BY по време на компилиране.
Можем да се опитаме да решим тези проблеми по няколко начина:
- Използвайте серия от оператори IF-ELSE
- Разделете процедурата на отделни съхранени процедури
- Използвайте ОПЦИЯ (ПРЕКОМПИЛИРАНЕ)
- Генерирайте заявката динамично
Използвайте серия от оператори IF-ELSE
Идеята е проста:вместо „динамичните“ изрази в клаузата WHERE и в клаузата ORDER BY, можем да разделим изпълнението на 4 клона с помощта на оператори IF-ELSE – по един клон за всяко възможно поведение.
Например, следният е кодът за първия клон:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Този подход може да помогне за генерирането на по-добри планове, но има някои ограничения.
Първо, съхранената процедура става доста дълга и е по-трудно да се пише, чете и поддържа. И това е, когато имаме само два параметъра. Ако имахме 3 параметъра, щяхме да имаме 8 клона. Представете си, че трябва да добавите колона към клаузата SELECT. Ще трябва да добавите колоната в 8 различни заявки. Това се превръща в кошмар за поддръжка с висок риск от човешка грешка.
Второ, все още имаме проблема с кеширането на планове и подслушването на параметри до известна степен. Това е така, защото при първото изпълнение оптимизаторът ще генерира план за всичките 4 заявки въз основа на стойностите на параметрите в това изпълнение. Да кажем, че първото изпълнение ще използва стойностите по подразбиране за параметрите. По-конкретно, стойността на @CustomerID ще бъде NULL. Всички заявки ще бъдат оптимизирани въз основа на тази стойност, включително заявката с клаузата WHERE (SalesOrders.CustomerID =@CustomerID). Оптимизаторът ще изчисли 0 реда за тези заявки. Сега да кажем, че второто изпълнение ще използва стойност, различна от нула за @CustomerID. Кешираният план, който изчислява 0 реда, ще бъде използван, въпреки че клиентът може да има много поръчки в таблицата.
Разделете процедурата на отделни съхранени процедури
Вместо 4 клона в рамките на една и съща съхранена процедура, можем да създадем 4 отделни съхранени процедури, всяка със съответните параметри и съответната заявка. След това можем или да пренапишем приложението, за да решим коя съхранена процедура да изпълни според желаното поведение. Или, ако искаме тя да бъде прозрачна за приложението, можем да пренапишем оригиналната съхранена процедура, за да решим коя процедура да изпълним въз основа на стойностите на параметрите. Ще използваме същите оператори IF-ELSE, но вместо да изпълняваме заявка във всеки клон, ще изпълним отделна съхранена процедура.
Предимството е, че решаваме проблема с кеширането на плана, защото всяка съхранена процедура вече има собствен план и планът за всяка съхранена процедура ще бъде генериран при първото й изпълнение въз основа на подслушване на параметри.
Но все още имаме проблем с поддръжката. Някои хора може да кажат, че сега е още по-лошо, защото трябва да поддържаме множество съхранени процедури. Отново, ако увеличим броя на параметрите до 3, ще получим 8 отделни съхранени процедури.
Използвайте OPTION (ПРЕКОМПИЛИРАНЕ)
OPTION (RECOMPILE) работи като магия. Просто трябва да кажете думите (или да ги добавите към заявката) и се случва магия. Наистина, той решава толкова много проблеми, защото компилира заявката по време на изпълнение и го прави за всяко изпълнение.
Но трябва да внимавате, защото знаете какво казват:„С голяма сила идва и голяма отговорност“. Ако използвате OPTION (RECOMPILE) в заявка, която се изпълнява много често в натоварена OLTP система, тогава може да убиете системата, защото сървърът трябва да компилира и генерира нов план при всяко изпълнение, като използва много ресурси на процесора. Това е наистина опасно. Ако обаче заявката се изпълнява само от време на време, да речем веднъж на няколко минути, тогава вероятно е безопасно. Но винаги тествайте въздействието във вашата конкретна среда.
В нашия случай, ако приемем, че можем безопасно да използваме OPTION (RECOMPILE), всичко, което трябва да направим, е да добавим вълшебните думи в края на нашата заявка, както е показано по-долу:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Сега, нека видим магията в действие. Например, следното е планът за второто поведение:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
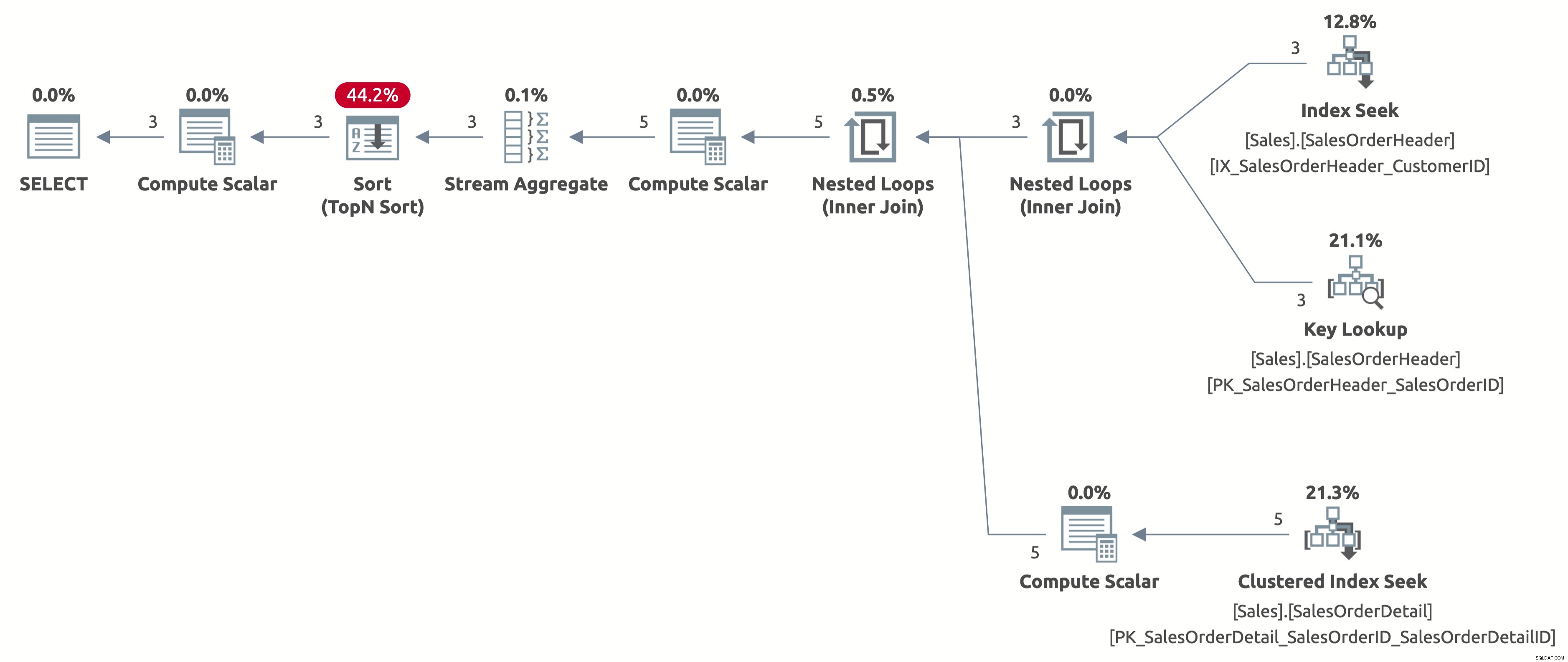
Сега получаваме ефективно търсене на индекс с правилна оценка от 2,6 реда. Все още трябва да сортираме по OrderDate, но сега сортирането е директно по Дата на поръчка и вече не е нужно да изчисляваме израза CASE в клаузата ORDER BY. Това е най-добрият възможен план за това поведение на заявката въз основа на наличните индекси.
Ето изхода от IO на статистиката:
- Таблица „SalesOrderDetail“. Брой на сканирането 3, логически показания 9
- Таблица „SalesOrderHeader“. Сканиране 1, логически показания 11
Причината OPTION (RECOMPILE) да е толкова ефективна в този случай е, че решава точно двата проблема, които имаме тук. Не забравяйте, че първият проблем е кеширането на планове. OPTION (RECOMPILE) елиминира този проблем напълно, защото прекомпилира заявката всеки път. Вторият проблем е невъзможността на оптимизатора да оцени сложния израз в клаузата WHERE и в клаузата ORDER BY по време на компилиране. Тъй като OPTION (RECOMPILE) се случва по време на изпълнение, това решава проблема. Тъй като по време на изпълнение оптимизаторът има много повече информация в сравнение с времето за компилиране и това прави цялата разлика.
Сега, нека видим какво се случва, когато опитаме третото поведение:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
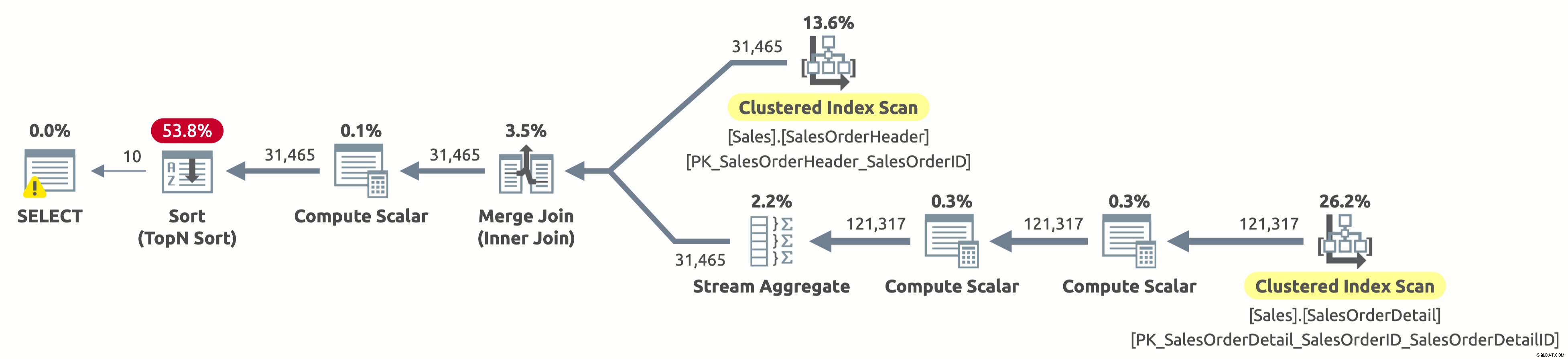
Хюстън имаме проблем. Планът все още сканира и двете таблици изцяло и след това сортира всичко, вместо да сканира само първите 10 реда от Sales.SalesOrderHeader и да избягва сортирането като цяло. Какво се случи?
Това е интересен "случай" и е свързан с израза CASE в клаузата ORDER BY. Изразът CASE оценява списък с условия и връща един от изразите на резултата. Но резултатните изрази може да имат различни типове данни. И така, какъв би бил типът данни на целия израз CASE? Е, изразът CASE винаги връща тип данни с най-висок приоритет. В нашия случай колоната OrderDate има тип данни DATETIME, докато колоната SalesOrderID има тип данни INT. Типът данни DATETIME има по-висок приоритет, така че изразът CASE винаги връща DATETIME.
Това означава, че ако искаме да сортираме по SalesOrderID, изразът CASE трябва първо имплицитно да преобразува стойността на SalesOrderID в DATETIME за всеки ред, преди да го сортира. Вижте оператора Compute Scalar вдясно от оператора Sort в плана по-горе? Точно това прави.
Това е проблем сам по себе си и показва колко опасно може да бъде смесването на различни типове данни в един CASE израз.
Можем да заобиколим този проблем, като пренапишем клаузата ORDER BY по други начини, но това би направило кода още по-грозен и труден за четене и поддържане. Така че няма да вървя в тази посока.
Вместо това, нека опитаме следващия метод...
Динамично генериране на заявката
Тъй като нашата цел е да генерираме 4 различни структури на заявка в рамките на една заявка, динамичният SQL може да бъде много удобен в този случай. Идеята е да се изгради заявката динамично въз основа на стойностите на параметрите. По този начин можем да изградим 4 различни структури на заявка в един код, без да се налага да поддържаме 4 копия на заявката. Всяка структура на заявката ще се компилира веднъж, когато бъде изпълнена за първи път, и ще получи най-добрия план, защото не съдържа никакви сложни изрази.
Това решение е много подобно на решението с множеството съхранени процедури, но вместо да поддържаме 8 съхранени процедури за 3 параметъра, ние поддържаме само един код, който изгражда заявката динамично.
Знам, че динамичният SQL също е грозен и понякога може да бъде доста труден за поддръжка, но мисля, че все още е по-лесно от поддържането на множество съхранени процедури и не се мащабира експоненциално с увеличаване на броя на параметрите.
Следва кодът:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Имайте предвид, че все още използвам вътрешен параметър за идентификатора на клиента и изпълнявам динамичния код, използвайки sys.sp_executesql за да предаде стойността на параметъра. Това е важно по две причини. Първо, за да избегнете множество компилации на една и съща структура на заявка за различни стойности на @CustomerID. Второ, за да избегнете SQL инжектиране.
Ако се опитате да изпълните съхранената процедура сега, като използвате различни стойности на параметрите, ще видите, че всяко поведение на заявка или структура на заявка получава най-добрия план за изпълнение и всеки един от 4-те плана се компилира само веднъж.
Като пример, следното е планът за третото поведение:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
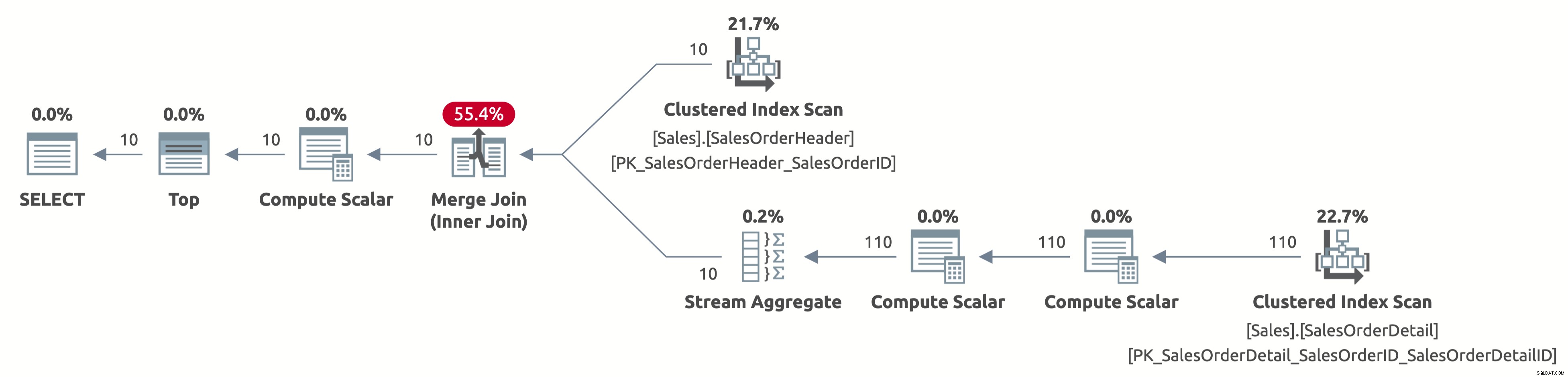
Сега сканираме само първите 10 реда от таблицата Sales.SalesOrderHeader и също така сканираме само първите 110 реда от таблицата Sales.SalesOrderDetail. Освен това няма оператор за сортиране, тъй като данните вече са сортирани по SalesOrderID.
Ето изхода от IO на статистиката:
- Таблица „SalesOrderDetail“. Брой сканиране 1, логически показания 4
- Таблица „SalesOrderHeader“. Сканиране 1, логически показания 3
Заключение
Когато използвате параметри, за да промените структурата на вашата заявка, не използвайте сложни изрази в заявката, за да извлечете очакваното поведение. В повечето случаи това ще доведе до лошо представяне и по основателни причини. Първата причина е, че планът ще бъде генериран въз основа на първото изпълнение, а след това всички следващи изпълнения ще използват повторно същия план, който е подходящ само за една структура на заявка. Втората причина е, че оптимизаторът е ограничен в способността си да оценява тези сложни изрази по време на компилиране.
Има няколко начина за преодоляване на тези проблеми и ние ги разгледахме в тази статия. В повечето случаи най-добрият метод би бил да се изгради заявката динамично въз основа на стойностите на параметрите. По този начин всяка структура на заявката ще бъде компилирана веднъж с възможно най-добрия план.
Когато създавате заявката с помощта на динамичен SQL, уверете се, че използвате параметри, където е уместно, и се уверете, че кодът ви е безопасен.