Като израснах, обичах игри, които тестваха паметта и уменията за съвпадение на шаблони. Няколко от моите приятели имаха Саймън, докато аз имах копие, наречено Айнщайн. Други имаха Atari Touch Me, което още тогава знаех, че е съмнително решение за име. В наши дни съпоставянето на шаблони означава нещо много различно за мен и може да бъде скъпа част от ежедневните заявки за база данни.
Като израснах, обичах игри, които тестваха паметта и уменията за съвпадение на шаблони. Няколко от моите приятели имаха Саймън, докато аз имах копие, наречено Айнщайн. Други имаха Atari Touch Me, което още тогава знаех, че е съмнително решение за име. В наши дни съпоставянето на шаблони означава нещо много различно за мен и може да бъде скъпа част от ежедневните заявки за база данни.
Наскоро попаднах на няколко коментара за Stack Overflow, където потребител заявяваше, сякаш като факт, че CHARINDEX работи по-добре от LEFT или LIKE . В един случай лицето цитира статия от Дейвид Лозински „SQL:LIKE срещу SUBSTRING срещу LEFT/RIGHT срещу CHARINDEX“. Да, статията показва, че в измисления пример CHARINDEX се представи най-добре. Въпреки това, тъй като винаги съм скептичен относно общите изявления като това и не можах да се сетя за логична причина защо една низова функция винаги се представят по-добре от друг, при равни останали , проведох тестовете му. Разбира се, имах многократно различни резултати на моята машина (щракнете, за да увеличите):
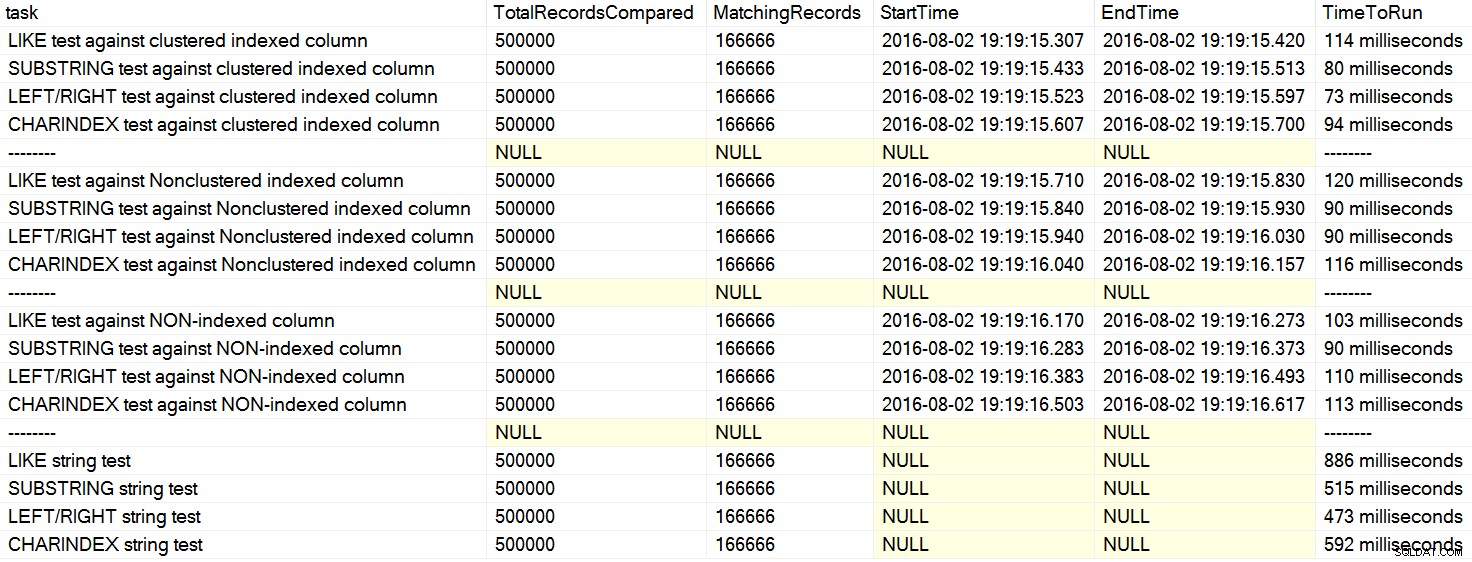 На моята машина CHARINDEX беше по-бавен отколкото НАЛЯВО/ДЯСНО/ПОДНИЗ.
На моята машина CHARINDEX беше по-бавен отколкото НАЛЯВО/ДЯСНО/ПОДНИЗ.
Тестовете на Дейвид основно сравняваха тези структури на заявки – търсейки модел на низ или в началото, или в края на стойността на колона – по отношение на необработената продължителност:
КЪДЕ колона КАТО @pattern + '%' ИЛИ колона LIKE '%' + @pattern; WHERE SUBSTRING(Колона, 1, LEN(@шаблон)) =@шаблон ИЛИ SUBSTRING(Колона, LEN(Колона) - LEN(@модел) + 1, LEN(@шаблон)) =@модел; КЪДЕ НАЛЯВО(Колона, LEN(@шаблон)) =@шаблон ИЛИ НАДЯСНО(Колона, LEN(@шаблон)) =@модел; КЪДЕ CHARINDEX(@модел, SUBSTRING(Колона, 1, LEN(@модел)), 0)> 0 ИЛИ CHARINDEX(@модел, SUBSTRING(Колона, LEN(Колона) - LEN(@модел) + 1, LEN(@модел )), 0)> 0;
Само като погледнете тези клаузи, можете да разберете защо CHARINDEX може да бъде по-малко ефективно – прави множество допълнителни функционални извиквания, които другите подходи не трябва да изпълняват. Защо този подход се представи най-добре на машината на Дейвид, не съм сигурен; може би той е изпълнил кода точно както е публикуван и всъщност не е изпуснал буфери между тестовете, така че последните тестове да се възползват от кеширани данни.
На теория CHARINDEX можеше да се изрази по-просто, напр.:
КЪДЕ CHARINDEX(@pattern, Column) =1 ИЛИ CHARINDEX(@pattern, Column) =LEN(Column) - LEN(@pattern) + 1;
(Но това всъщност се представи още по-зле при моите случайни тестове.)
И защо това са дори OR условия, не съм сигурен. Реално погледнато, през повечето време правите един от двата типа търсене на шаблони:започва с или съдържа (много по-рядко е да търсите крайни с ). И в повечето от тези случаи потребителят е склонен да заяви предварително дали иска започва с или съдържа , поне във всяко приложение, с което съм участвал в кариерата си.
Има смисъл да ги отделите като отделни типове заявки, вместо да използвате ИЛИ условно, тъй като започва с може да използва индекс (ако съществува такъв, който е достатъчно подходящ за търсене или е по-слаб от клъстерирания индекс), докато завършва с не може (и ИЛИ условията са склонни да хвърлят гаечни ключове към оптимизатора като цяло). Ако мога да се доверя на LIKE да използвам индекс, когато може, и да се представя толкова добре или по-добре от другите решения по-горе в повечето или всички случаи, тогава мога да направя тази логика много лесна. Съхранената процедура може да приеме два параметъра – моделът, който се търси, и типа на търсене, което да се извърши (обикновено има четири типа съвпадение на низове – започва с, завършва с, съдържа или точно съвпадение).
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.Search @pattern nvarchar(100), @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains' -- последните две се поддържат, но няма да бъдат тествани тук ЗАПОЧНЕТЕ ЗАДАДЕТЕ NOCOUNT ON; ИЗБЕРЕТЕ ... КЪДЕ Колона LIKE -- ако съдържа или завършва с, се нуждаете от водещ заместващ знак КОГАТО @option IN ('Contains','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- ако съдържа или започва с, нужда от последващ заместващ знак CASE WHEN @option IN ('Contains','StartsWith') THEN N'%' ELSE N'' END OPTION (RECOMPILE); ENDGO
Това обработва всеки потенциален случай без използване на динамичен SQL; OPTION (RECOMPILE) има ли, защото не бихте искали план, оптимизиран за „завършва с“ (който почти сигурно ще трябва да се сканира), да бъде използван повторно за заявка „започва с“ или обратното; също така ще гарантира, че оценките са правилни („започва с S“ вероятно има много по-различна мощност от „започва с QX“). Дори ако имате сценарий, при който потребителите избират един тип търсене в 99% от времето, можете да използвате динамичен SQL тук вместо прекомпилиране, но в този случай пак ще бъдете уязвими за подслушване на параметри. В много условни логически заявки прекомпилирането и/или пълен динамичен SQL често са най-разумният подход (вижте публикацията ми за „Кухненската мивка“).
Тестовете
Тъй като наскоро започнах да разглеждам новата примерна база данни WideWorldImporters, реших да проведа собствени тестове там. Беше трудно да се намери таблица с приличен размер без индекс на ColumnStore или таблица с времева история, но Sales.Invoices , който има 70 510 реда, има прост nvarchar(20) колона, наречена CustomerPurchaseOrderNumber които реших да използвам за тестовете. (Защо е nvarchar(20) когато всяка отделна стойност е 5-цифрено число, нямам представа, но съвпадението на шаблона не се интересува дали байтовете отдолу представляват числа или низове.)
| Продажби.Фактури CustomerPurchaseOrderNumber | ||
|---|---|---|
| Модел | # редове | % от таблицата |
| Започва с "1" | 70 505 | 99,993% |
| Започва с "2" | 5 | 0,007% |
| Завършва с "5" | 6897 | 9,782% |
| Завършва с "30" | 749 | 1,062% |
Разрових стойностите в таблицата, за да намеря множество критерии за търсене, които биха довели до значително различен брой редове, надявам се да разкрия поведението на повратна точка с даден подход. Вдясно са заявките за търсене, на които попаднах.
Исках да докажа на себе си, че горната процедура несъмнено беше по-добра като цяло за всички възможни търсения от която и да е от заявките, които използват OR условни, независимо дали използват LIKE , LEFT/RIGHT , SUBSTRING , или CHARINDEX . Взех основните структури за заявки на Дейвид и ги поставих в съхранени процедури (с уговорката, че не мога да тествам "съдържа" без негово въвеждане и че трябваше да направя неговото OR логиката малко по-гъвкава, за да получите същия брой редове), заедно с версия на моята логика. Планирах също да тествам процедурите със и без индекс, който бих създал в колоната за търсене, както в топъл, така и в студен кеш.
Процедурите:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.David_LIKE @pattern nvarchar(10), @option varchar(10) -- StartsWith или EndsWithASBEGIN SET NOCOUNT ON; ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices WHERE (@option ='StartsWith' И CustomerPurchaseOrderNumber LIKE @pattern + N'%') ИЛИ (@option ='EndsWith' И CustomerPurchaseOrder) OPTION (@CumberPurchaseOrder)pa;ENDGO СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.David_SUBSTRING @pattern nvarchar(10), @option varchar(10) -- StartsWith или EndsWithASBEGIN SET NOCOUNT ON; ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices WHERE (@option ='StartsWith' И SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)) =@pattern) ИЛИ (@option ='EndsOrderChaseWenPumerCauMerCaNumrCumrCaNumrNumrCt - LEN(@pattern) + 1, LEN(@pattern)) =@pattern) ОПЦИЯ (РЕКОМПИЛИРАНЕ);ENDGO СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.David_LEFTRIGHT @pattern nvarchar(10), @option varchar(10) -- StartsWith или EndsWithASBEGIN SET NOCOUNT НА; ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices КЪДЕТО (@option ='StartsWith' И LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern) ИЛИ (@option ='EndsWith(Cupattern) ИЛИ =@pattern) ОПЦИЯ (ПРЕКОМПИЛИРАНЕ);ENDGO СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.David_CHARINDEX @pattern nvarchar(10), @option varchar(10) -- StartsWith или EndsWithASBEGIN SET NOCOUNT ON; ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices WHERE (@option ='StartsWith' И CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)), 0)> 0) ИЛИ' AREXANDsW (@pattern, SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern)), 0)> 0) ОПЦИЯ (РЕКОМПИЛИРАНЕ);ENDGO СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.Achar1n_Con ditional @char1n_Con , @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'ASBEGIN SET NOCOUNT ON; ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE -- ако съдържа или завършва с, се нуждаете от водещ заместващ знак CASE WHEN @option IN ('Contains','EndsWith') THEN N'%' ELSE N''n END + + -- ако съдържа или започва с, се нуждае от последващ заместващ знак CASE WHEN @option IN ('Contains','StartsWith') THEN N'%' ELSE N'' END OPTION (ПРЕКОМПИЛИРАНЕ); ENDGO
Също така направих версии на процедурите на Дейвид, верни на първоначалното му намерение, като приемем, че изискването наистина е да се намерят всички редове, където шаблонът за търсене е в началото *или* края на низа. Направих това просто, за да мога да сравня производителността на различните подходи, точно както ги е написал, за да видя дали на този набор от данни моите резултати ще съвпадат с тестовете ми на оригиналния му скрипт в моята система. В този случай нямаше причина да представя моя собствена версия, тъй като тя просто би съвпадала с неговия LIKE % + @pattern OR LIKE @pattern + % вариация.
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.David_LIKE_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%' ИЛИ CustomerPurchaseOrderNumber LIKE N'%' + @pattern ОПЦИЯ (RECOMPILE);ENDGO CREATE(RECOMPILE);ENDGO CREATE(RECOMPILE). ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)) =@pattern OR SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber), LEN(CustomerPurchaseOrderNumber), LEN(CustomerPurchaseOrderNumber,CustomerPurchaseOrderNumber) шаблон ОПЦИЯ (ПРЕКОМПИЛИРАНЕ);ENDGO СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.David_LEFTRIGHT_Original @pattern nvarchar(10)ASBEGIN ЗАДАДЕТЕ NOCOUNT ON; ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern ИЛИ НАДЯСНО(CustomerPurchaseOrderNumber, LEN(@pattern)) =(CustomerPurchaseOrderNumber, LEN(@pattern)) =@patterPurchaseOrderNumber. (10) КАТО ЗАПОЧНЕТЕ ЗАДАВАТЕ NOCOUNT ON; ИЗБЕРЕТЕ CustomerPurchaseOrderNumber, OrderID ОТ Sales.Invoices WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)), 0)> 0 OR CHARINDEX(@pattern, SUBSTRINGchamber(CustomerPurchaseOrderNumber) ) + 1, LEN(@pattern)), 0)> 0 ОПЦИЯ (ПРЕКОМПИЛИРАНЕ);ENDGO
С наличните процедури бих могъл да генерирам кода за тестване – което често е толкова забавно, колкото и първоначалния проблем. Първо, таблица за регистриране:
ИЗПУСКАНЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА dbo.LoggingTable;GOSET NOCOUNT ON; CREATE TABLE dbo.LoggingTable( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME());След това кодът, който ще изпълнява операции за избор, използвайки различните процедури и аргументи:
ЗАДАДЕТЕ NOCOUNT ON;;WITH prc(name) AS ( SELECT name FROM sys.procedures WHERE LEFT(name,5) IN (N'David', N'Aaron')),args(opt,pattern) AS (SELECT 'StartsWith', N' 1' UNION ALL SELECT 'StartsWith', N'2' UNION ALL SELECT 'EndsWith', N'5' UNION ALL SELECT 'EndsWith', N'30'),frame(w) AS (ИЗБЕРЕТЕ 'BeforeIndex' UNION ALL SELECT 'AfterIndex'),y AS( -- коментирайте редове 2-4 тук, ако искаме топъл кеш SELECT cmd ='GO DBCC FREEPROCCACHE() WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS() С NO_INFOMSGS; GO DECLARE, @d date intime2; SET @d =SYSUTCDATETIME(); EXEC dbo.' + prc.name + ' @pattern =N''' + args.pattern + '''' + CASE WHEN prc.name LIKE N'%_Original' THEN '' ELSE ',@option =''' + args.opt + '''' END + '; SET @delta =DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME()); INSERT dbo.LoggingTable(prc,opt,pattern,frame ,продължителност) SELECT N''' + prc.name + ''',''' + args.opt + ''',N''' + args.pattern + ''',''' + frame.w + ''',@delta; ', *, rn =ROW_NUMBER() НАД (PARTITIO N BY frame.w ORDER BY frame.w DESC, LEN(prc.name), args.opt DESC, args.pattern) FROM prc CROSS JOIN args CROSS JOIN frame)SELECT cmd =cmd + CASE WHEN rn =36 ТОГАВА CASE WHEN w ='BeforeIndex' THEN 'CREATE INDEX testing ON '+ 'Sales.Invoices(CustomerPurchaseOrderNumber); ' ELSE 'DROP INDEX Sales.Invoices.testing;' END ELSE '' END--, име, опция, модел, w, rn ОТ yORDER BY w DESC, rn;Резултати
Проведох тези тестове на виртуална машина, работеща с Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), с 4 процесора и 32 GB RAM. Проведох всеки набор от тестове 11 пъти; за тестовете за топъл кеш изхвърлих първия набор от резултати, защото някои от тях бяха наистина студени кеш тестове.
Борех се с това как да начертая резултатите, за да покажа модели, най-вече защото просто нямаше модели. Почти всеки метод беше най-добрият в един сценарий и най-лошият в друг. В следващите таблици подчертах най-добрата и най-лошата процедура за всяка колона и можете да видите, че резултатите далеч не са убедителни:
В тези тестове понякога CHARINDEX печели, а понякога не.
Това, което научих е, че като цяло, ако ще се сблъскате с много различни ситуации (различни видове съвпадение на шаблони, с поддържащ индекс или не, данните не винаги могат да бъдат в паметта), наистина няма ясен победител, а обхватът на производителност средно е доста малък (всъщност, тъй като топъл кеш не винаги помагаше, бих подозирал, че резултатите са повлияни повече от разходите за изобразяване на резултатите, отколкото от извличането им). За отделни сценарии не разчитайте на моите тестове; стартирайте сами някои сравнителни показатели, като се имат предвид хардуера, конфигурацията, данните и моделите на използване.
Предупреждения
Някои неща, които не взех предвид за тези тестове:
- Клъстер срещу неклъстер . Тъй като е малко вероятно вашият клъстериран индекс да бъде в колона, в която извършвате търсения за съвпадение на шаблон в началото или края на низа, и тъй като търсенето ще бъде до голяма степен еднакво и в двата случая (и разликите между сканиранията до голяма степен ще бъде функция на ширината на индекса спрямо ширината на таблицата), тествах само производителността с помощта на неклъстериран индекс. Ако имате някакви специфични сценарии, при които само тази разлика прави дълбока разлика при съвпадението на шаблоните, моля, уведомете ме.
- MAX типове . Ако търсите низове в
varchar(max)/nvarchar(max), те не могат да бъдат индексирани, така че освен ако не използвате изчислени колони за представяне на части от стойността, ще е необходимо сканиране – независимо дали търсите започва с, завършва с или съдържа. Дали служебните разходи за производителност корелират с размера на низа, или допълнителните допълнителни разходи се въвеждат просто поради типа, не тествах.
- Търсене в пълен текст . Играл съм с тази функция тук и там и мога да я напиша по правопис, но ако разбирам правилно, това може да е полезно само ако търсите цели непрекъснати думи и не се притеснявате къде в низа са били те намерени. Не би било полезно, ако съхранявате абзаци от текст и искате да намерите всички, които започват с „Y“, съдържат думата „the“ или завършват с въпросителен знак.
Резюме
Единственото общо изявление, което мога да направя, излизайки от този тест, е, че няма общи изявления за това кой е най-ефективният начин за извършване на съвпадение на модел на низове. Въпреки че съм пристрастен към моя условен подход за гъвкавост и поддръжка, той не беше победител във всички сценарии. За мен, освен ако не попадна на тесно място в производителността и не преследвам всички пътища, ще продължа да използвам подхода си за последователност. Както предложих по-горе, ако имате много тесен сценарий и сте много чувствителни към малки разлики в продължителността, ще искате да проведете свои собствени тестове, за да определите кой метод е постоянно най-добрият за вас.