Това е част от серията проблемни оператори за вътрешните оператори на SQL. Не пропускайте да прочетете първата и втората публикация на Kalen по тази тема.
SQL Server съществува повече от 30 години и аз работя със SQL Server почти толкова дълго. Виждал съм много промени през годините (и десетилетия!) и версии на този невероятен продукт. В тези публикации ще споделя с вас как гледам на някои от функциите или аспектите на SQL Server, понякога заедно с малко историческа перспектива.
Последния път говорих за хеширане в план за заявки на SQL Server като потенциално проблематичен оператор в диагностиката на SQL сървър. Хеширането често се използва за обединяване и агрегиране, когато няма полезен индекс. И подобно на сканирането (за което говорих в първата публикация от тази серия), има моменти, когато хеширането всъщност е по-добър избор от алтернативите. За хеш свързвания една от алтернативите е LOOP JOIN, за която също ви казах миналия път.
В тази публикация ще ви разкажа за друга алтернатива за хеширане. Повечето от алтернативите на хеширането изискват данните да бъдат сортирани, така че или планът трябва да включва SORT оператор, или необходимите данни трябва да са вече сортирани поради съществуващи индекси.
Различни типове обединения за диагностика на SQL Server
За операции JOIN най-често срещаният и полезен тип JOIN е LOOP JOIN. Описах алгоритъма за LOOP JOIN в предишната публикация. Въпреки че самите данни не трябва да се сортират за LOOP JOIN, наличието на индекс във вътрешната таблица прави присъединяването много по-ефективно и както трябва да знаете, наличието на индекс предполага известно сортиране. Докато клъстерираният индекс сортира самите данни, неклъстерираният индекс сортира ключовите колони на индекса. Всъщност в повечето случаи, без индекса, оптимизаторът на SQL Server ще избере да използва алгоритъма HASH JOIN. Видяхме това в примера последния път, че без индекси беше избран HASH JOIN, а с индекси получихме LOOP JOIN.
Третият тип присъединяване е MERGE JOIN. Този алгоритъм работи върху два вече сортирани набора от данни. Ако се опитваме да комбинираме (или ПРИСЪЕДИНИМ) два набора данни, които вече са сортирани, е необходимо само едно преминаване през всеки набор, за да намерим съвпадащите редове. Ето псевдокода за алгоритъма за присъединяване при сливане:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Въпреки че MERGE JOIN е много ефективен алгоритъм, той изисква и двата входни набора от данни да бъдат сортирани по ключа за присъединяване, което обикновено означава наличието на клъстериран индекс на ключа за присъединяване и за двете таблици. Тъй като получавате само един клъстериран индекс на таблица, изборът на колоната с клъстерен ключ само за да позволи да се осъществят MERGE JOINS, може да не е най-добрият цялостен избор за клъстерен ключ.
Така че обикновено не ви препоръчвам да се опитвате да създавате индекси само с цел MERGE JOINS, но ако в крайна сметка получите MERGE JOIN поради вече съществуващи индекси, това обикновено е добре. В допълнение към изискването и двата входни набора от данни да бъдат сортирани, MERGE JOIN също изисква поне един от наборите от данни да има уникални стойности за ключа за присъединяване.
Нека разгледаме един пример. Първо, ще пресъздадем Заглавките и Подробности таблици:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
След това вижте плана за свързване между тези таблици:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Ето плана:

Имайте предвид, че дори и с клъстериран индекс на двете таблици, получаваме HASH JOIN. Можем да възстановим един от индексите, за да бъде УНИКАЛЕН. В този случай това трябва да е индексът на Заглавките таблица, защото тя е единствената, която има уникални стойности за SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Сега изпълнете заявката отново и забележете, че планът действа по начина, по който MERGE JOIN.

Тези планове се възползват от това, че данните вече са сортирани в индекс, тъй като планът за изпълнение може да се възползва от сортирането. Но понякога SQL Server трябва да извършва сортиране като част от изпълнението на заявката си. Понякога може да видите оператор SORT да се показва в план, дори ако не поискате сортиран изход. Ако SQL Server смята, че MERGE JOIN може да е добър вариант, но една от таблиците няма подходящия клъстериран индекс и е достатъчно малка, за да направи сортирането много евтино, може да се извърши SORT, за да се позволи MERGE JOIN да бъде използван.
Но обикновено операторът SORT се показва в заявки, където сме поискали сортирани данни с ORDER BY, както е в следващия пример.
SELECT * FROM Details
ORDER BY ProductID;
GO

Клъстерираният индекс се сканира (което е същото като сканирането на таблицата) и след това редовете се сортират, както е поискано.
Справяне с вече сортиран клъстериран индекс
Но какво ще стане, ако данните вече са сортирани в клъстериран индекс и заявката включва ORDER BY в колоната с клъстерен ключ? В примера по-горе изградихме клъстериран индекс на SalesOrderID в таблицата с подробности. Вижте следните две заявки:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Ако изпълним тези заявки заедно, прозорецът за анализ на пакета за настройка на Quest Spotlight показва, че двата плана са с еднаква цена; всеки е 50% от общия брой. И така, каква всъщност е разликата между тях?
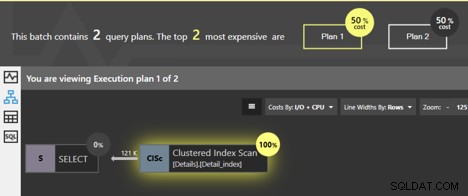
И двете заявки сканират клъстерирания индекс и SQL Server знае, че ако страниците на ниво лист се следват по ред, данните ще се върнат в клъстериран ключов ред. Не е необходимо да се извършва допълнително сортиране, така че към плана не се добавя SORT оператор. Но ИМА РАЗЛИКА. Можем да щракнем върху оператора Clustered Index Scan и ще получим подробна информация.
Първо, вижте подробната информация за първия план, за заявката без ПОРЪЧАЙТЕ.

Подробностите ни казват, че свойството „Поръчано“ е False. Тук няма изискване данните да се връщат в сортиран ред. Оказва се, че в повечето случаи най-лесният начин за извличане на данните е да следвате страниците на клъстерирания индекс, така че данните в крайна сметка ще бъдат върнати по ред, но няма гаранция. Свойството False означава, че няма изискване SQL Server да следва подредените страници, за да върне резултата. Всъщност има и други начини, по които SQL Server може да получи всички редове за таблицата, без да следва клъстерирания индекс. Ако по време на изпълнение SQL Server избере да използва различен метод за получаване на редовете, няма да видим подредени резултати.
За втората заявка подробностите изглеждат така:
 Тъй като заявката включваше ORDER BY, има изискване данните да се връщат в сортиран ред и SQL Server ще следва страниците на клъстерирания индекс в ред.
Тъй като заявката включваше ORDER BY, има изискване данните да се връщат в сортиран ред и SQL Server ще следва страниците на клъстерирания индекс в ред.
Най-важното нещо, което трябва да запомните тук, е, че НЯМА гаранция за сортирани данни, ако не включите ORDER BY в заявката си. Само защото имате клъстериран индекс, все още няма гаранция! Дори ако всеки път за миналата година, когато сте изпълнили заявката, сте връщали данните в ред без ORDER BY, няма гаранция, че ще продължите да получавате данните обратно в ред. Използването на ORDER BY е единственият начин да гарантирате реда, в който се връщат резултатите ви.
Съвети за използване на операции за сортиране
И така, SORT е операция, която трябва да се избягва в диагностиката на SQL сървър? Точно като сканирането и хеш операциите, отговорът, разбира се, е „зависи“. Сортирането може да бъде много скъпо, особено при големи масиви от данни. Правилното индексиране помага на SQL Server да избягва извършването на SORT операции, защото индексът по същество означава, че вашите данни са предварително сортирани. Но индексирането идва с цена. За всеки индекс има разходи за съхранение, в допълнение към разходите за поддръжка. Ако данните ви са силно актуализирани, трябва да поддържате броя на индексите до минимум.
Ако установите, че някои от вашите бавно изпълнявани заявки показват SORT операции в своите планове и ако тези SORT са сред най-скъпите оператори в плана, можете да помислите за изграждане на индекси, които позволяват на SQL Server да избягва сортирането. Но ще трябва да направите задълбочено тестване, за да сте сигурни, че допълнителните индекси не забавят други заявки, които са от решаващо значение за цялостната производителност на вашето приложение.