В предишните блогове аз и моите колеги ви показахме как можете да наблюдавате производителността, да управлявате и разгръщате клъстери, да изпълнявате резервни копия и дори да активирате автоматично преминаване при отказ за TimescaleDB.
В този блог ще ви покажем как да мащабирате своя единичен TimescaleDB екземпляр в клъстер с множество възли само с няколко прости стъпки.
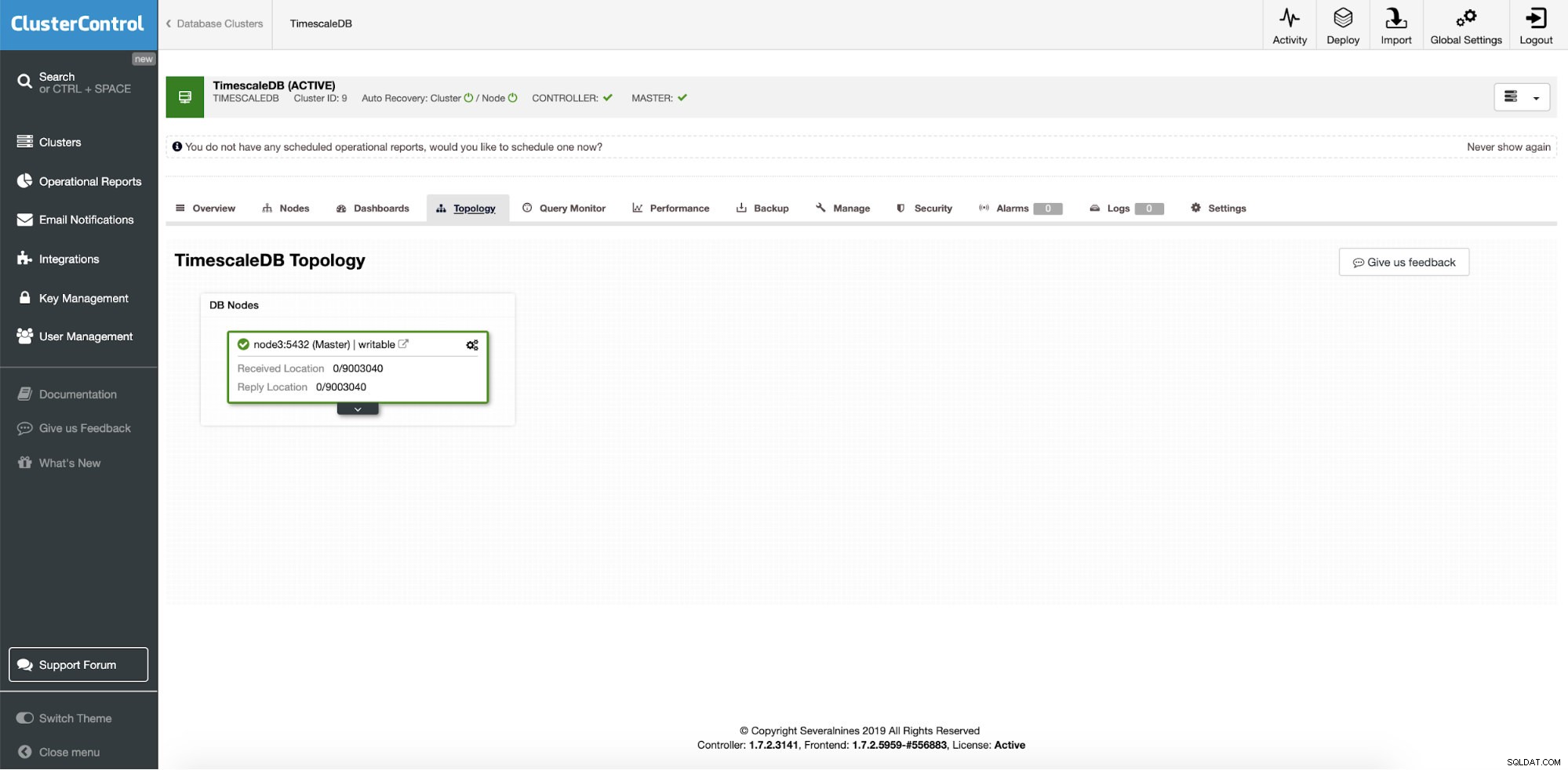
Ще започнем с обща настройка, един екземпляр на възел, работещ на CentosOS. Възелът е готов и вече се наблюдава и управлява от ClusterControl.
Ако искате да научите как да внедрите или импортирате своя екземпляр на TimescaleDB, вижте блога, написан от моя колега Себастиан Инсаусти, „Как да разположите лесно TimescaleDB.
Настройката изглежда по следния начин...
 ClusterControl:Единичен екземпляр TimescaleDB
ClusterControl:Единичен екземпляр TimescaleDB Така че това е единичен производствен екземпляр и ние искаме да го преобразуваме в клъстер без прекъсване. Нашата основна цел е да мащабираме операциите за четене на приложения към други машини с опция да ги използваме като HA сървъри, когато пишем срив на сървъра.
Повече възли също трябва да намалят времето за престой на поддръжката на приложението. Подобно на кръпка, приложена в режим на непрекъснато рестартиране – един възел е закърпен в даден момент, докато други възли обслужват връзки към базата данни.
Последното изискване е да създадем един адрес за нашия нов клъстер, така че новите ни възли да бъдат видими за приложението от едно място.

Можем да обобщим нашия план за действие в две основни стъпки:
- Добавянето на реплика чете
- Инсталирайте и конфигурирайте Haproxy
Добавяне на реплика четения
Ако отидем в действията на клъстера и изберем „Добавяне на подчинен за репликация“, можем или да създадем нова реплика от нулата, или да добавим съществуваща база данни TimescaleDB като реплика.
 ClusterControl:Добавяне на подчинен репликация
ClusterControl:Добавяне на подчинен репликация  ClusterControl:Добавете ново подчинено устройство за репликация, импортирайте съществуващо подчинено устройство за репликация
ClusterControl:Добавете ново подчинено устройство за репликация, импортирайте съществуващо подчинено устройство за репликация Както можете да видите на изображението по-долу, трябва само да изберем нашия главен сървър, да въведете IP адреса за нашия нов подчинен сървър и порта на базата данни.
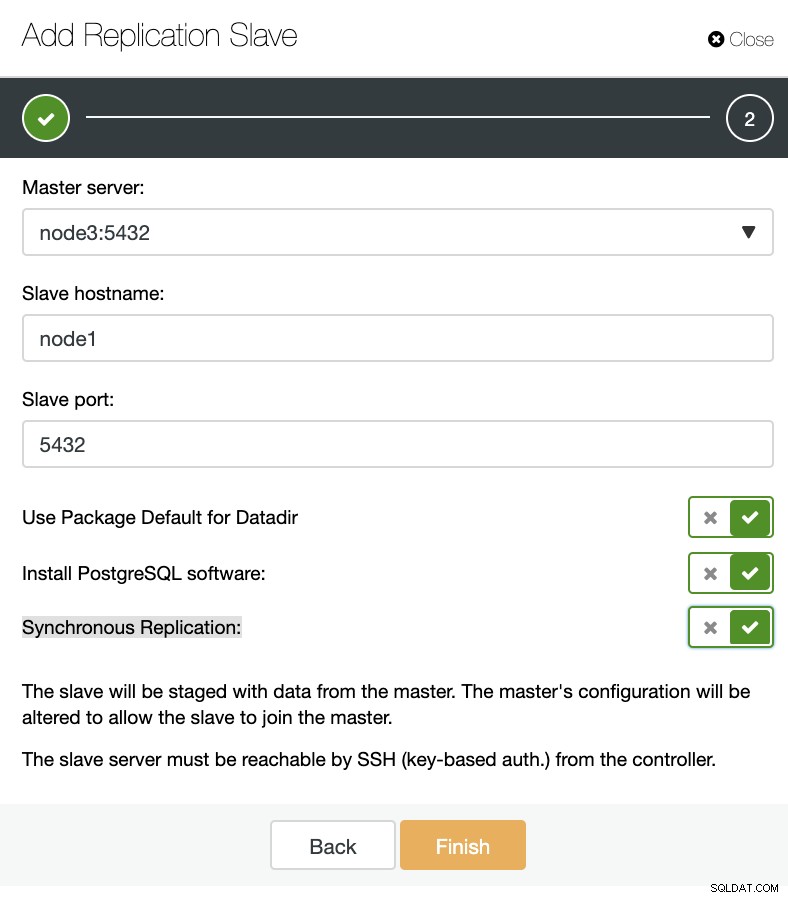 ClusterControl:Добавяне на подчинен елемент за репликация
ClusterControl:Добавяне на подчинен елемент за репликация След това можем да изберем дали искаме ClusterControl да инсталира софтуера вместо нас и дали подчинението за репликация трябва да бъде синхронно или асинхронно. Когато импортирате съществуващ подчинен сървър, можете да използвате опцията за импортиране, както следва:
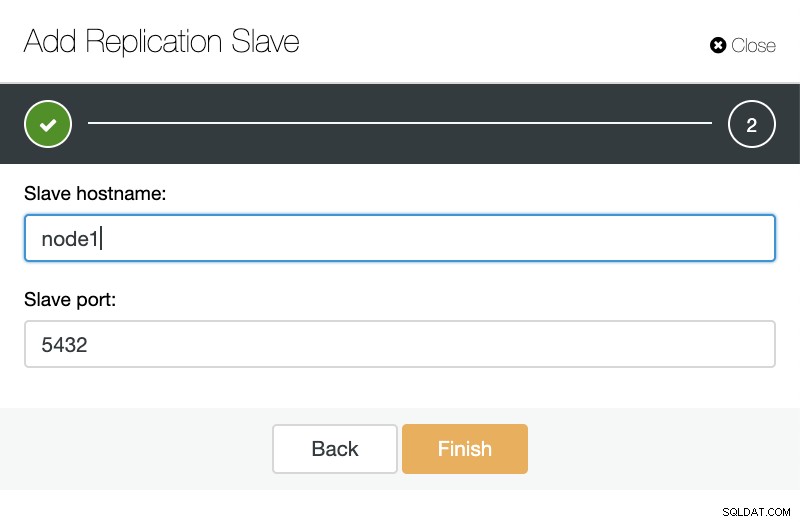 ClusterControl:Импортиране на подчинен репликация за TimescaleDB
ClusterControl:Импортиране на подчинен репликация за TimescaleDB И в двата начина можем да добавим толкова копия, колкото искаме. В нашия примерен случай ще добавим два възела. CusterControl ще създаде вътрешна работа и ще се погрижи за всички необходими стъпки с една по една.
 ClusterControl:добавяне на реплика за четене
ClusterControl:добавяне на реплика за четене Добавяне на Load Balancer към TimescaleDB
В този момент нашите данни се разпределят в множество възли или центрове за данни, ако сте избрали да добавите подчинени възли за репликация на различно място. Клъстерът се мащабира с два допълнителни възела на реплика за четене.
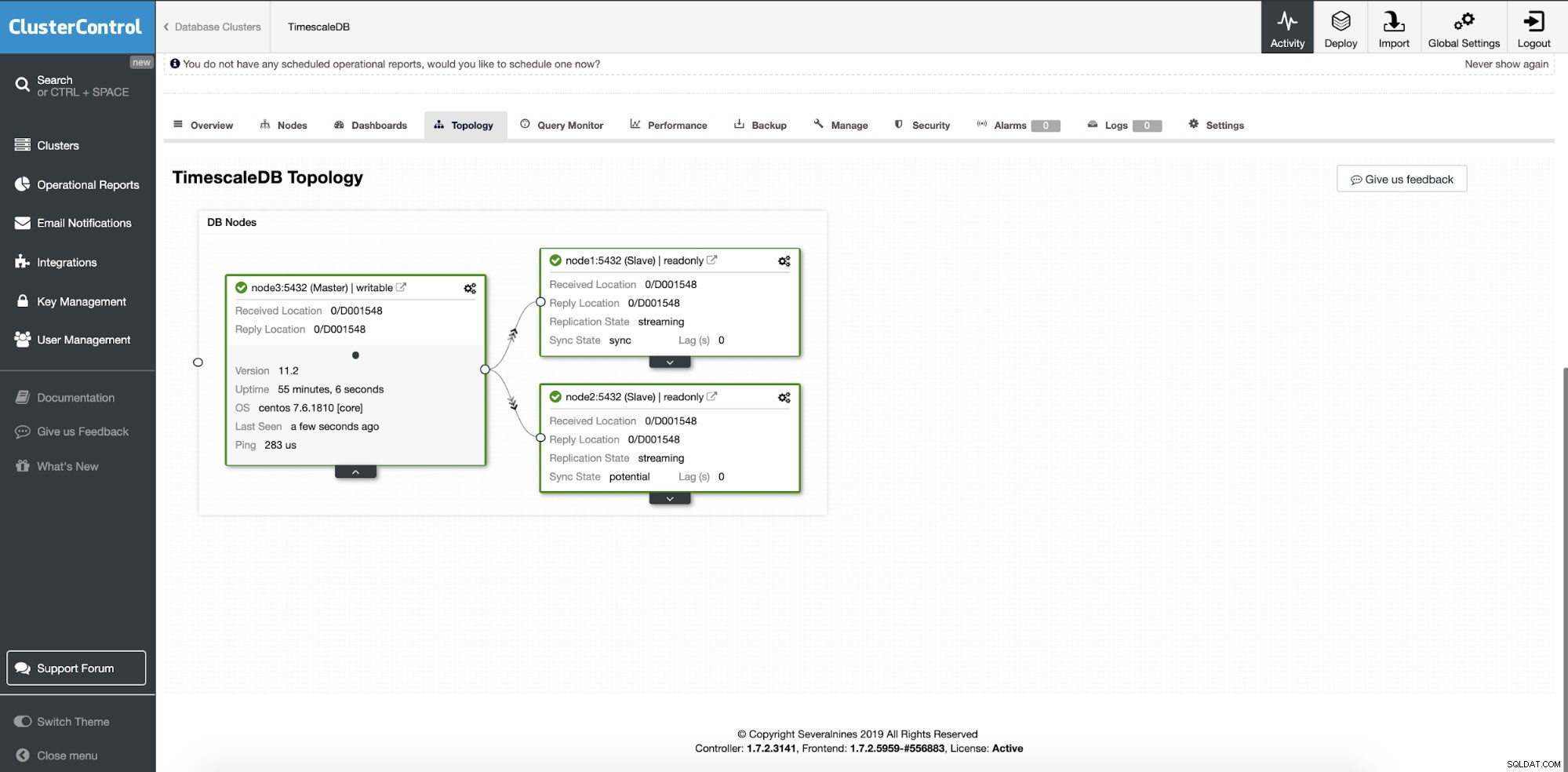 ClusterControl:Добавени са два възела
ClusterControl:Добавени са два възела Въпросът е как приложението знае до кой възел на базата данни да има достъп? Ще използваме HAProxy и различни портове за операции за запис и четене.
От клъстера TimescaleDB, контекстното меню изберете да добавите балансьор на натоварване.

Сега трябва да предоставим местоположението на сървъра, където трябва да се инсталира Haproxy, каква политика искаме да използваме за връзки към базата данни и кои възли вземат част от конфигурацията на Haproxy.
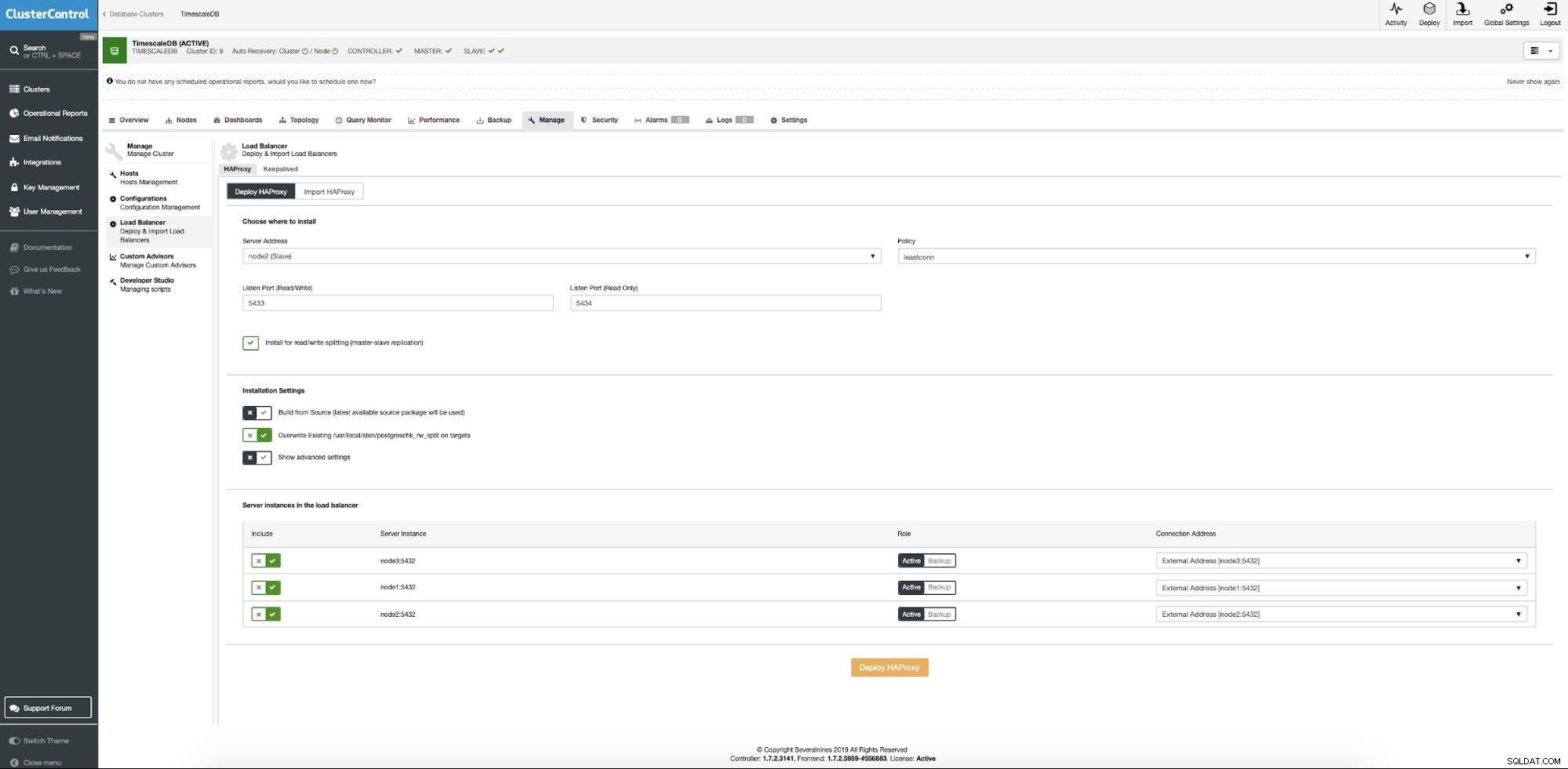
Когато всичко е настроено, натиснете бутона за разгръщане. След няколко минути трябва да подготвим конфигурацията на клъстера. ClusterControl ще се погрижи за всички предпоставки и конфигурации за внедряване на балансиране на натоварването.
След успешно внедряване можем да видим топологията на нашия нов клъстер; с балансиране на натоварването и допълнителни възли за четене. С повече възли на борда, ClusterControl автоматично активира автоматично възстановяване. По този начин, когато главният възел изпадне, операцията по преодоляване на срив ще започне сама.
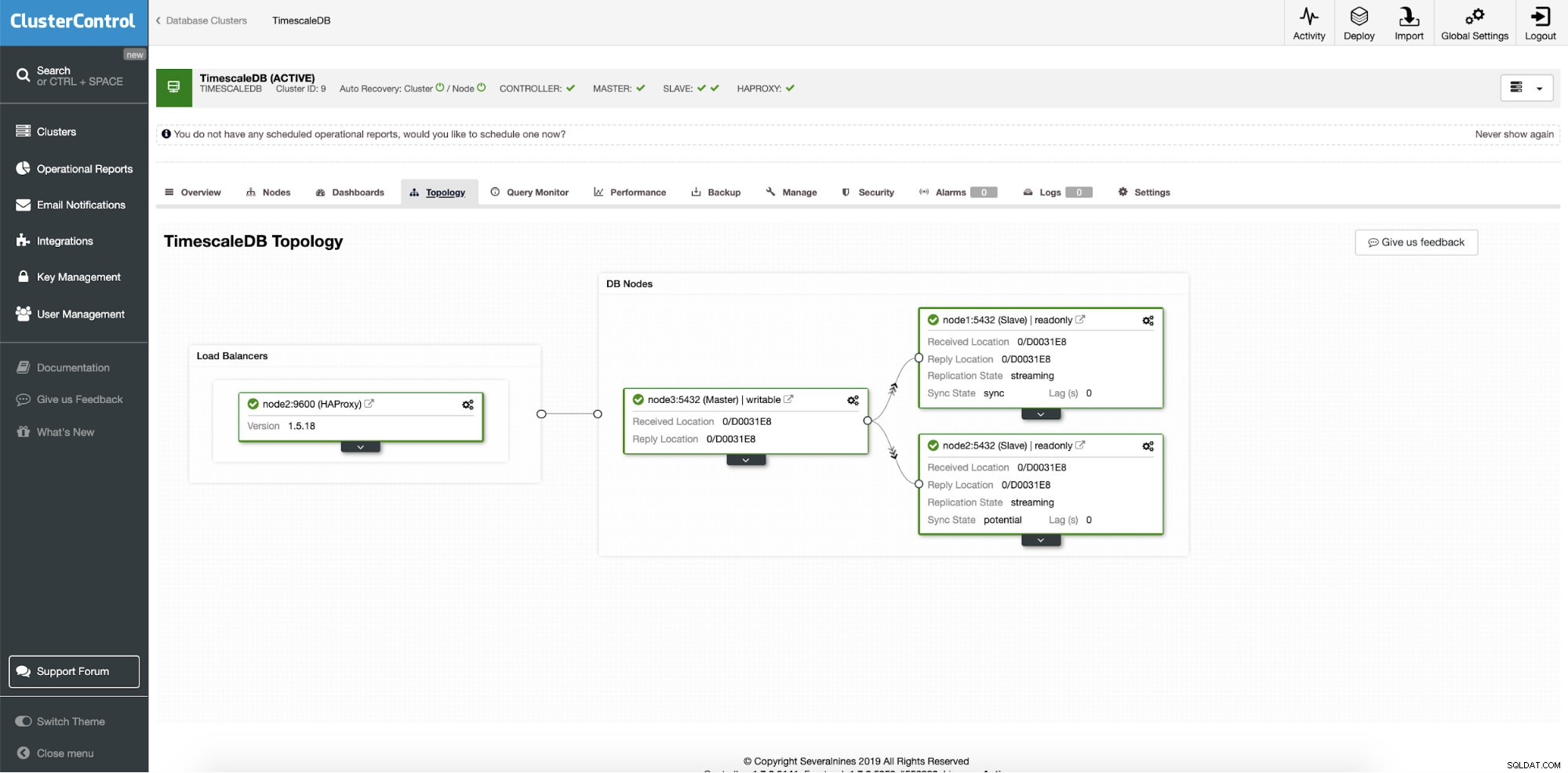 ClusterControl:Крайна топология
ClusterControl:Крайна топология Заключение
TimescaleDB е база данни с отворен код, изобретена, за да направи SQL мащабируем за данни от времеви серии. Наличието на автоматизиран начин за разширяване на техния клъстер е ключът към постигането на производителност и ефективност. Както видяхме по-горе, вече можете да мащабирате TimescaleDB, като използвате ClusterControl с лекота.



