В днешно време репликацията е дадена в среда с висока наличност и толерантност към грешки за почти всяка технология на базата данни, която използвате. Това е тема, която сме виждали отново и отново, но тя никога не остарява.
Ако използвате TimescaleDB, най-често срещаният тип репликация е стрийминг репликация, но как работи?
В този блог ще прегледаме някои концепции, свързани с репликацията, и ще се съсредоточим върху поточно репликацията за TimescaleDB, която е функционалност, наследена от основния PostgreSQL двигател. След това ще видим как ClusterControl може да ни помогне да го конфигурираме.
Така че репликацията на поточно предаване се основава на изпращане на WAL записите и прилагането им към сървъра в режим на готовност. И така, първо, нека видим какво е WAL.
WAL
Write Ahead Log (WAL) е стандартен метод за гарантиране на целостта на данните, автоматично се активира по подразбиране.
WAL са REDO регистрационните файлове в TimescaleDB. Но какви са REDO регистрационните файлове?
REDO регистрационните файлове съдържат всички промени, които са направени в базата данни и се използват от репликация, възстановяване, онлайн архивиране и възстановяване в точка във времето (PITR). Всички промени, които не са били приложени към страниците с данни, могат да бъдат направени отново от REDO регистрационните файлове.
Използването на WAL води до значително намален брой записвания на диск, тъй като само регистрационният файл трябва да бъде изтрит на диск, за да се гарантира, че транзакцията е ангажиментирана, а не всеки файл с данни, променен от транзакцията.
WAL запис ще посочи, бит по бит, промените, направени в данните. Всеки WAL запис ще бъде добавен към WAL файл. Позицията на вмъкване е пореден номер на регистрационния файл (LSN), който представлява изместване на байт в регистрационните файлове, което се увеличава с всеки нов запис.
WAL се съхраняват в директорията pg_wal, под директорията с данни. Тези файлове имат размер по подразбиране от 16MB (размерът може да бъде променен чрез промяна на опцията за конфигуриране --with-wal-segsize при изграждането на сървъра). Те имат уникално постепенно име в следния формат:„00000001 00000000 00000000“.
Броят на WAL файловете, съдържащи се в pg_wal, ще зависи от стойността, присвоена на параметрите min_wal_size и max_wal_size в конфигурационния файл postgresql.conf.
Един параметър, който трябва да настроим, когато конфигурираме всички наши инсталации на TimescaleDB, е wal_level. Той определя колко информация се записва в WAL. Стойността по подразбиране е минимална, която записва само информацията, необходима за възстановяване след срив или незабавно изключване. Архивът добавя регистрация, необходима за WAL архивиране; hot_standby допълнително добавя информация, необходима за изпълнение на заявки само за четене на сървър в режим на готовност; и накрая logical добавя информация, необходима за поддържане на логическото декодиране. Този параметър изисква рестартиране, така че може да е трудно да се промени при работещи производствени бази данни, ако сме го забравили.
Поточно репликация
Репликацията на поточно предаване се основава на метода за доставка на регистрационни файлове. WAL записите се преместват директно от един сървър на база данни в друг, за да бъдат приложени. Можем да кажем, че е непрекъснат PITR.
Това прехвърляне се извършва по два различни начина, чрез прехвърляне на WAL записи по един файл (WAL сегмент) наведнъж (базирана на файл доставка на дневник) и чрез прехвърляне на WAL записи (WAL файл се състои от WAL записи) в движение (базирано на запис доставка на регистрационни файлове), между главен сървър и един или няколко подчинени сървъра, без да чакате WAL файлът да бъде попълнен.
На практика процес, наречен WAL приемник, изпълняващ се на подчинения сървър, ще се свърже с главния сървър чрез TCP/IP връзка. В главния сървър съществува друг процес, наречен WAL sender, и отговаря за изпращането на WAL регистрите към подчинения сървър, когато се случват.
Поточно репликацията може да бъде представена по следния начин:
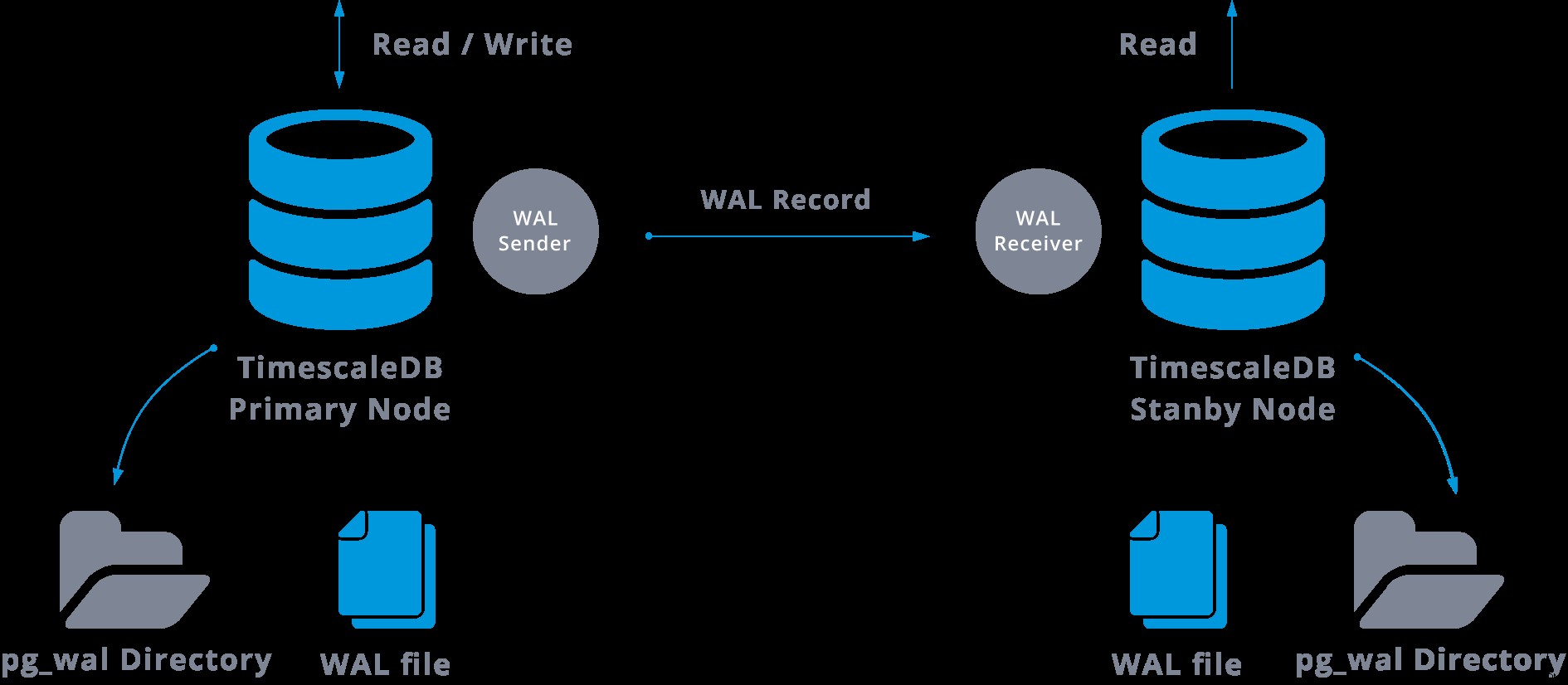
Като разгледаме горната диаграма, можем да си помислим какво се случва, когато комуникацията между подателя на WAL и получателя на WAL се провали?
Когато конфигурираме поточно репликация, имаме опцията да активираме WAL архивиране.
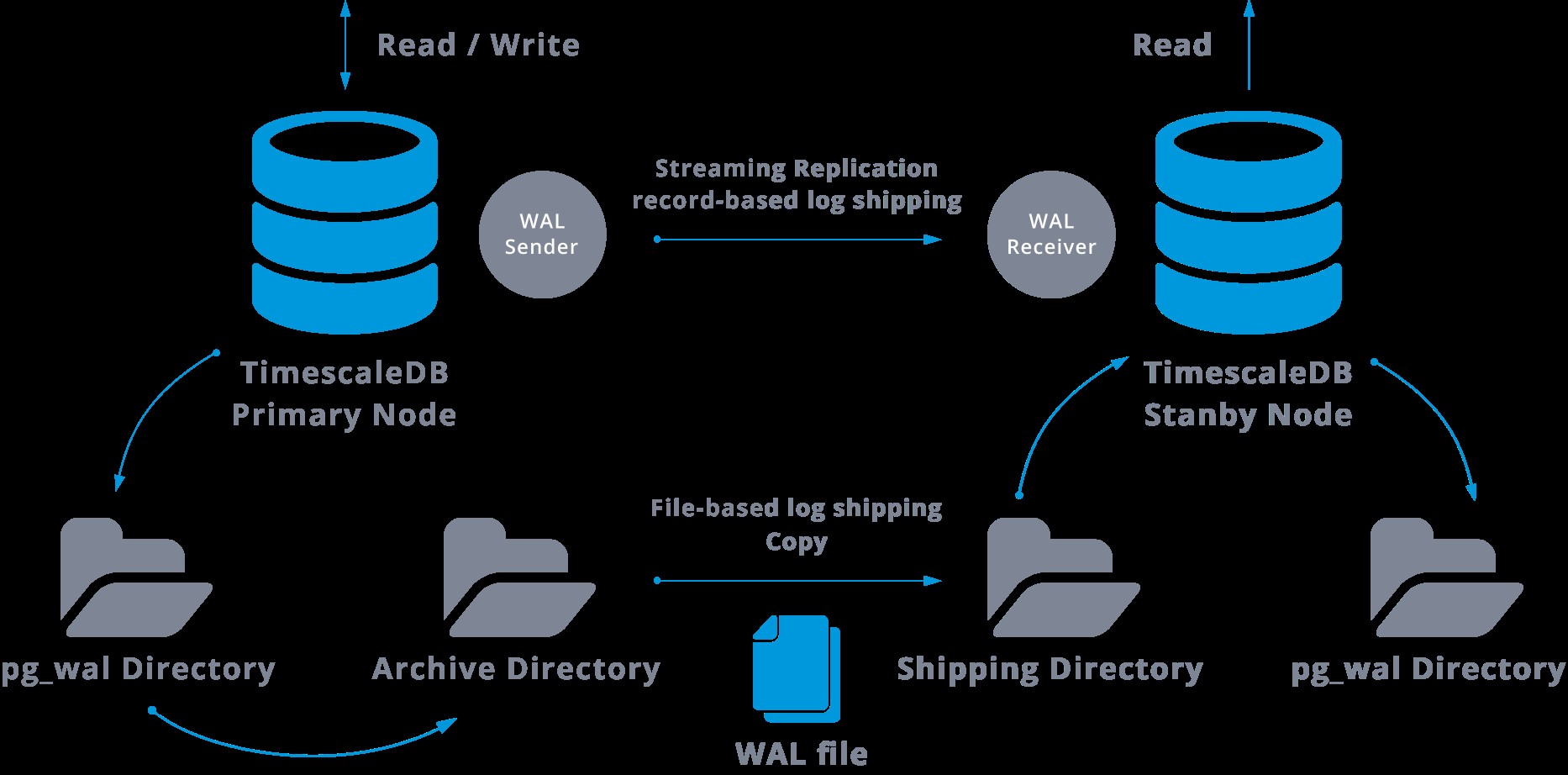
Тази стъпка всъщност не е задължителна, но е изключително важна за стабилна настройка на репликация, тъй като е необходимо да се избягва основният сървър да рециклира стари WAL файлове, които все още не са приложени към подчинения. Ако това се случи, ще трябва да пресъздадем репликата от нулата.
Когато конфигурираме репликация с непрекъснато архивиране, започваме от резервно копие и, за да достигнем състоянието на синхронизиране с главния, трябва да приложим всички промени, хоствани в WAL, които са се случили след архивирането. По време на този процес, режимът на готовност първо ще възстанови всички налични WAL в местоположението на архива (направено чрез извикване на restore_command). Restore_command ще се провали, когато достигнем последния архивиран WAL запис, така че след това режимът на готовност ще търси в директорията pg_wal, за да види дали промяната съществува там (това всъщност се прави, за да се избегне загуба на данни, когато главните сървъри се сринат и някои промените, които вече са преместени в репликата и приложени там, все още не са архивирани).
Ако това не успее и исканият запис не съществува там, той ще започне да комуникира с главната чрез стрийминг репликация.
Всеки път, когато поточно репликацията се провали, тя ще се върне към стъпка 1 и ще възстанови записите от архива отново. Този цикъл на извличане от архива, pg_wal, и чрез стрийминг репликация продължава, докато сървърът не бъде спрян или превключването при отказ се задейства от файл за задействане.
Това ще бъде диаграма на такава конфигурация:
Поточната репликация е асинхронна по подразбиране, така че в даден момент можем да имаме някои транзакции, които могат да бъдат ангажирани в главния и все още не репликирани в резервния сървър. Това предполага известна потенциална загуба на данни.
Предполага се обаче, че това забавяне между записването и въздействието на промените в репликата е наистина малко (няколко милисекунди), като се приеме, разбира се, че сървърът на репликата е достатъчно мощен, за да се справи с натоварването.
В случаите, когато дори рискът от малка загуба на данни не е поносим, можем да използваме функцията за синхронно репликация.
При синхронна репликация всяко записване на транзакция за запис ще изчака, докато бъде получено потвърждение, че записването е било записано в дневника за предварителна запис на диска както на основния, така и на резервния сървър.
Този метод свежда до минимум възможността от загуба на данни, тъй като за да се случи това, ще трябва да се повредят едновременно главният и резервният.
Очевидният недостатък на тази конфигурация е, че времето за отговор за всяка транзакция на запис се увеличава, тъй като трябва да изчакаме, докато всички страни отговорят. Така че времето за комит е най-малкото двупосочно пътуване между главния и репликата. Транзакциите само за четене няма да бъдат засегнати от това.
За да настроим синхронна репликация, трябва за всеки от сървърите в режим на готовност да посочим име на приложение в primary_conninfo на файла recovery.conf:primary_conninfo ='...aplication_name=slaveX' .
Трябва също да посочим списъка на резервните сървъри, които ще участват в синхронната репликация:synchronous_standby_name ='slaveX,slaveY'.
Можем да настроим един или няколко синхронни сървъра и този параметър също така указва кой метод (ПЪРВИ и ВСЕКИ) да изберем синхронен режим на готовност от изброените.
За да разгърнем TimescaleDB с настройки за поточно репликация (синхронни или асинхронни), можем да използваме ClusterControl, както виждаме тук.
След като сме конфигурирали нашата репликация и тя е стартирана и работи, ще трябва да имаме някои допълнителни функции за наблюдение и управление на архивиране. ClusterControl ни позволява да наблюдаваме и управляваме архивиране/задържане на нашия TimescaleDB клъстер от едно и също място без външен инструмент.
Как да конфигурирате поточно репликация на TimescaleDB
Настройването на поточно репликация е задача, която изисква щателно следване на някои стъпки. Ако искате да го конфигурирате ръчно, можете да следвате нашия блог по тази тема.
Можете обаче да разположите или импортирате текущата си TimescaleDB в ClusterControl и след това можете да конфигурирате репликация на поточно предаване с няколко щраквания. Нека видим как можем да го направим.
За тази задача ще приемем, че вашият TimescaleDB клъстер се управлява от ClusterControl. Отидете на ClusterControl -> Изберете Cluster -> Cluster Actions -> Add Replication Slave.
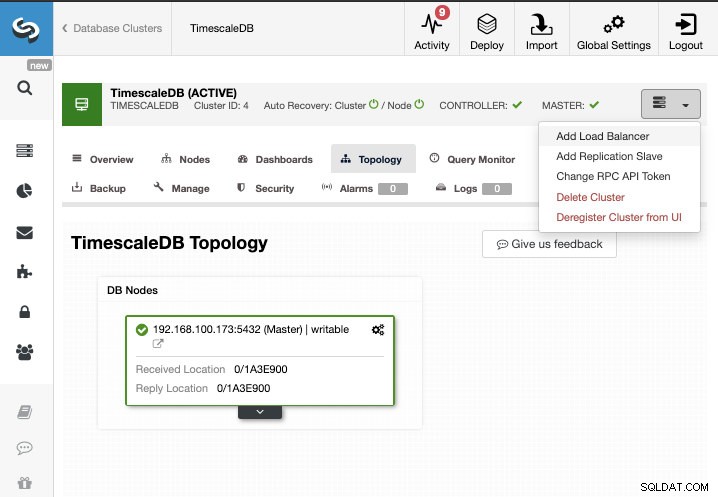
Можем да създадем нов роб за репликация (готовност) или можем да импортираме съществуващ. В този случай ще създадем нов.
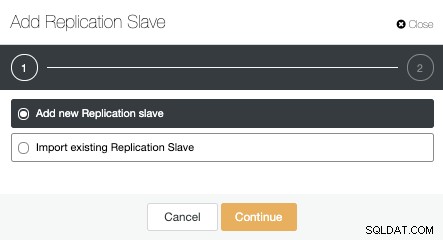
Сега трябва да изберем главния възел, да добавим IP адреса или името на хоста за новия сървър в режим на готовност и порта на базата данни. Можем също да посочим дали искаме ClusterControl да инсталира софтуера и дали искаме да конфигурираме синхронно или асинхронно стрийминг репликация.
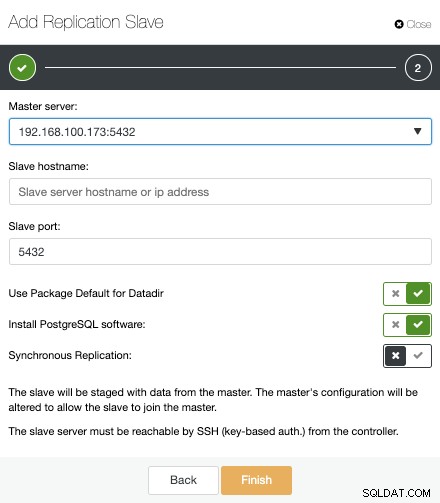
Това е всичко. Трябва само да изчакаме, докато ClusterControl завърши работата. Можем да наблюдаваме състоянието от секцията Активност.
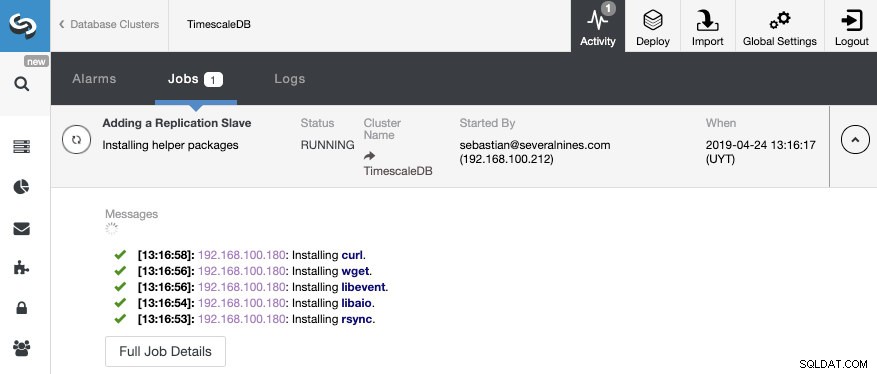
След като задачата приключи, трябва да конфигурираме поточно репликацията и можем да проверим новата топология в секцията ClusterControl Topology View.
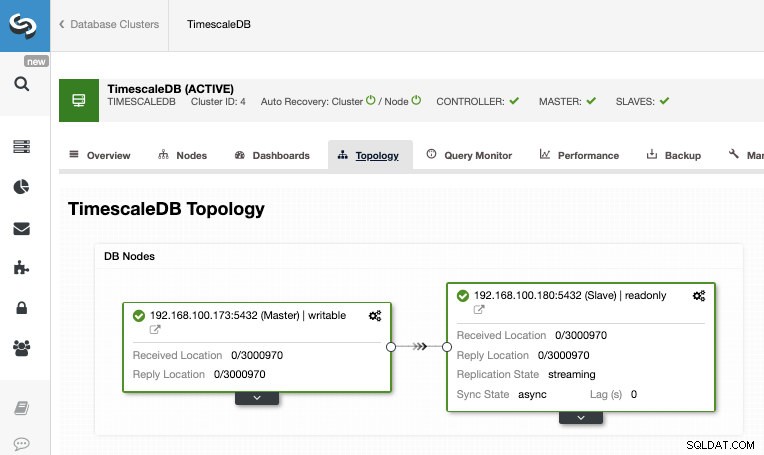
С помощта на ClusterControl можете също да изпълнявате няколко задачи за управление на вашата TimescaleDB като архивиране, наблюдение и предупреждение, автоматично преминаване при отказ, добавяне на възли, добавяне на балансиращи устройства и дори повече.
Отказ при отказ
Както можем да видим, TimescaleDB използва поток от записи на дневник за предварителна запис (WAL), за да поддържа синхронизирани бази данни в готовност. Ако основният сървър се повреди, режимът на готовност съдържа почти всички данни на главния сървър и може бързо да бъде превърнат в нов главен сървър на база данни. Това може да бъде синхронно или асинхронно и може да се направи само за целия сървър на база данни.
За да се осигури ефективно висока наличност, не е достатъчно да имате главна стендбай архитектура. Също така трябва да активираме някаква автоматична форма на отказ, така че ако нещо се провали, можем да имаме възможно най-малко забавяне при възобновяване на нормалната функционалност.
TimescaleDB не включва механизъм за автоматично преминаване при отказ за идентифициране на неизправности в главната база данни и уведомяване на подчинения да поеме собствеността, така че това ще изисква малко работа от страна на DBA. Освен това ще имате само един работещ сървър, така че трябва да се извърши повторно създаване на основната стендбай архитектура, така че да се върнем към същата нормална ситуация, която имахме преди проблема.
ClusterControl включва функция за автоматично преминаване при отказ за TimescaleDB за подобряване на средното време за ремонт (MTTR) във вашата среда с висока наличност. В случай на неуспех, ClusterControl ще повиши най-напредналото подчинено устройство към главен и ще преконфигурира останалите подчинени устройства, за да се свържат с новия главен. HAProxy може също да се разположи автоматично, за да се предложи единна крайна точка на базата данни на приложенията, така че те да не бъдат повлияни от промяна на главния сървър.
Ограничения
Свързани ресурси ClusterControl за TimescaleDB Как лесно да внедрите TimescaleDB Поточно репликация на PostgreSQL – дълбоко гмурканеИмаме някои добре известни ограничения при използване на поточно репликация:
- Не можем да копираме в друга версия или архитектура
- Не можем да променим нищо на сървъра в режим на готовност
- Нямаме много детайлност относно това, което можем да репликираме
Така че, за да преодолеем тези ограничения, имаме функцията за логическа репликация. За да научите повече за този тип репликация, можете да проверите следния блог.
Заключение
Топологията главен режим на готовност има много различни приложения като анализ, архивиране, висока наличност, отказ. Във всеки случай е необходимо да се разбере как работи поточно репликацията на TimescaleDB. Също така е полезно да имате система за управление на целия клъстер и да ви даде възможност да създадете тази топология по лесен начин. В този блог видяхме как да го постигнем с помощта на ClusterControl и прегледахме някои основни концепции за стрийминг репликацията.