В скорошен съвет описах сценарий, при който екземпляр на SQL Server 2016 изглежда се бори с времето за контролни точки. Регистърът на грешките беше попълнен с тревожен брой FlushCache записи като този:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Бях малко объркан от този проблем, тъй като системата със сигурност не беше мързелива - много ядра, 3TB памет и съхранение на XtremIO. И нито едно от тези съобщения на FlushCache никога не е било сдвоено с издайническите 15-секундни I/O предупреждения в регистъра за грешки. Все пак, ако подредите куп бази данни с високи транзакции, обработката на контролни точки може да стане доста бавна. Не толкова заради директното I/O, а повече съгласуване, което трябва да се направи с огромен брой мръсни страници (не само от извършени транзакции), разпръснати в толкова голям обем памет и потенциално чакащи от мързеливия писател (тъй като има само една за целия екземпляр).
Направих малко "освежаване" на някои много ценни публикации:
- Как работят контролните точки и какво се регистрира
- Проверка на базата данни (SQL сървър)
- Какво прави контролната точка за tempdb?
- Мит за DBA на SQL Server на ден:(15/30) контролна точка записва само страници от извършени транзакции
- Съобщенията на FlushCache може да не са действително спиране на IO
- Непряка контролна точка и tempdb – добрият, лошият и неподатливият планировчик
- Променете целевото време за възстановяване на база данни
- Как работи:Кога съобщението FlushCache се добавя към регистъра за грешки на SQL Server?
- Промени в поведението на контролната точка на SQL Server 2016
- Целеви интервал за възстановяване и непряка контролна точка – нова по подразбиране от 60 секунди в SQL Server 2016
- SQL 2016 – Просто работи по-бързо:Непряка контролна точка по подразбиране
- SQL сървър:голяма RAM и DB контролна точка
Бързо реших, че искам да проследя продължителността на контролните точки за няколко от тези по-обезпокоителни бази данни, преди и след промяна на целевия им интервал за възстановяване от 0 (по стария начин) на 60 секунди (новият начин). Още през януари взех назаем сесия за разширени събития от приятелка и колега канадка Хана Върнън:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; STATE; Отбелязах времето, в което промених всяка база данни, и след това анализирах резултатите от данните за разширени събития с помощта на заявка, публикувана в оригиналния съвет. Резултатите показаха, че след преминаване към непреки контролни точки, всяка база данни преминава от контролни точки със средно 30 секунди до контролни точки със средно по-малко от една десета от секундата (и много по-малко контролни точки в повечето случаи също). Има много за разопаковане от тази графика, но това са необработените данни, които използвах, за да представя аргумента си (щракнете за уголемяване):
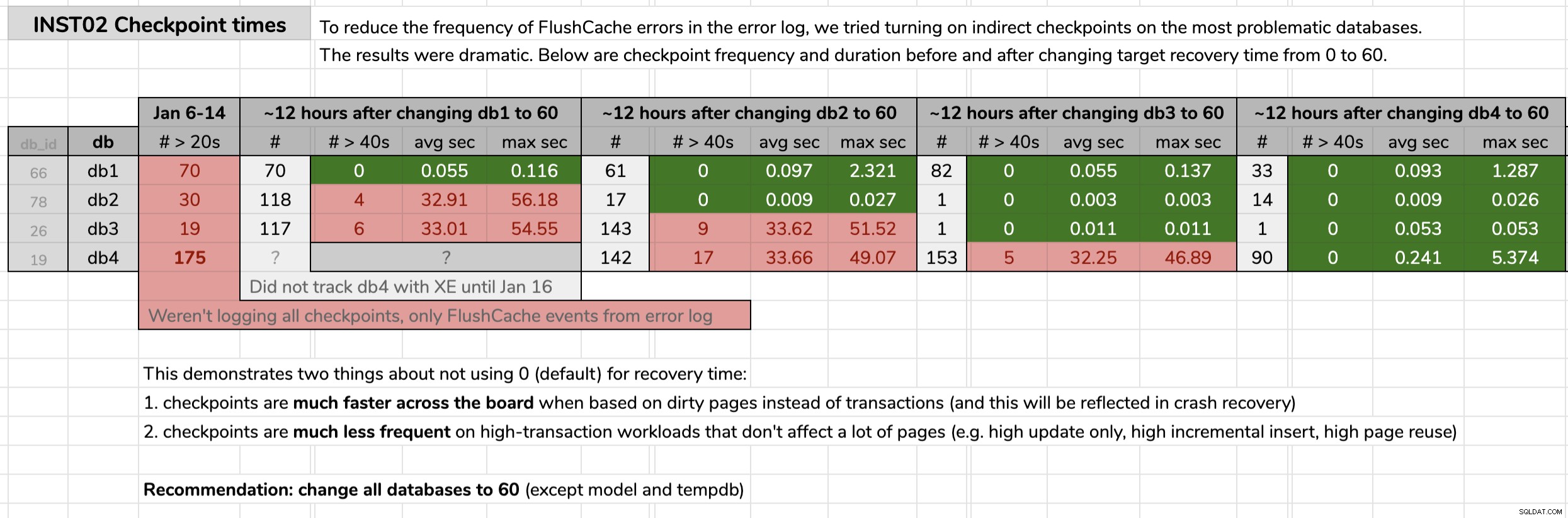 Моите доказателства
Моите доказателства
След като доказах моя случай в тези проблемни бази данни, получих зелена светлина да внедря това във всички наши потребителски бази данни в нашата среда. Първо в dev, а след това в производството, изпълних следното чрез CMS заявка, за да преценя за колко бази данни говорим:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Някои бележки относно заявката:
database_id > 4
Не исках да докосвамmasterизобщо и не исках да променямtempdbвсе пак, защото не сме на най-новия SQL Server 2017 CU (вижте KB #4497928 поради една причина, че подробностите са важни). Последното изключваmodel, също защото промяната на модела би засегналаtempdbпри следващото превключване/рестартиране. Можех да променяmsdb, и може да се върна, за да направя това в някакъв момент, но фокусът ми тук беше върху потребителските бази данни.
[state] / is_read_only / is_in_standby
Трябва да се уверим, че базите данни, които се опитваме да променим, са онлайн, а не само за четене (натиснах една, която в момента е настроена за само четене и ще трябва да се върна към тази по-късно).
OUTER APPLY (...)
Искаме да ограничим нашите действия до бази данни, които са или първични в AG, или изобщо не са в AG (и също така трябва да отчетем разпределените AG, където можем да бъдем първични и локални, но все още не можем да записваме) . Ако случайно стартирате проверката на вторичен, не можете да отстраните проблема там, но все пак трябва да получите предупреждение за него. Благодаря на Ерик Дарлинг за помощта с тази логика и на Тейлър Мартел за мотивирането на подобренията.
- Ако имате екземпляри, работещи с по-стари версии като SQL Server 2008 R2 (намерих такъв!), ще трябва да настроите това малко, тъй като
target_recovery_time_in_secondsколона не съществува там. Трябваше да използвам динамичен SQL, за да заобиколя това в един случай, но можете също така временно да преместите или премахнете къде попадат тези екземпляри във вашата CMS йерархия. Също така не бихте могли да бъдете мързеливи като мен и да стартирате кода в Powershell вместо прозорец за заявка на CMS, където лесно бихте могли да филтрирате бази данни, като се имат предвид произволен брой свойства, преди да срещнете проблеми по време на компилиране.
В производството имаше 102 екземпляра (около половината) и общо 1590 бази данни, използващи старата настройка. Всичко беше на SQL Server 2017, така че защо тази настройка беше толкова разпространена? Тъй като те са създадени преди индиректните контролни точки да станат по подразбиране в SQL Server 2016. Ето извадка от резултатите:
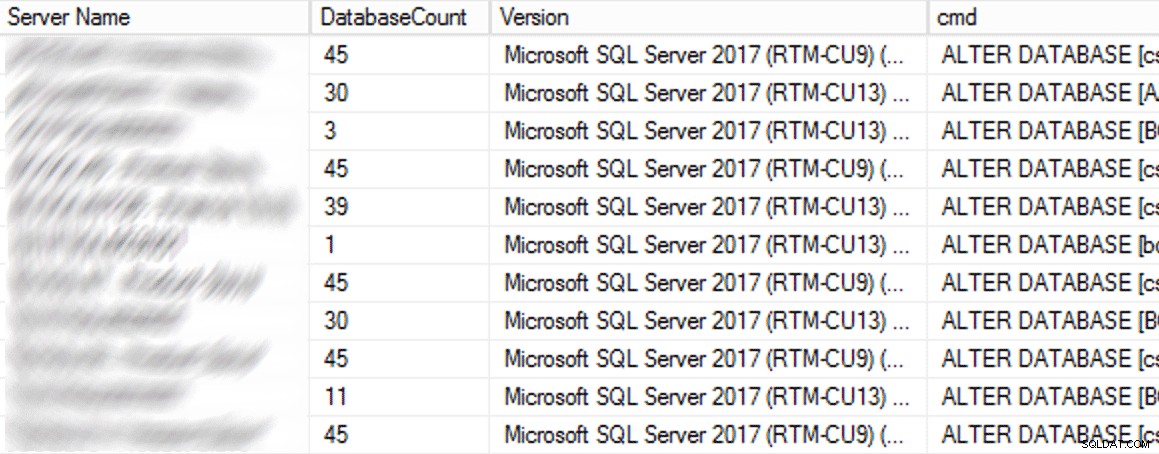 Частични резултати от CMS заявка.
Частични резултати от CMS заявка.
След това изпълних отново CMS заявката, този път с sys.sp_executesql без коментар. Отне около 12 минути, за да се изпълни това във всички 1590 бази данни. В рамките на един час вече получавах съобщения за хора, които наблюдават значителен спад в процесора в някои от по-натоварените случаи.
Имам още какво да правя. Например, трябва да тествам потенциалното въздействие върху tempdb , и дали има някаква тежест в нашия случай на използване на историите на ужасите, които съм чувал. И трябва да се уверим, че настройката за 60 секунди е част от нашата автоматизация и всички заявки за създаване на база данни, особено тези, които са скриптирани или възстановени от резервни копия.