Търсенето на низови данни за произволно съвпадение на поднизове може да бъде скъпа операция в SQL Server. Заявки от формата Column LIKE '%match%' не може да използва възможностите за търсене на индекс на b-дърво, така че процесорът на заявки трябва да приложи предиката към всеки ред поотделно. Освен това всеки тест трябва правилно да прилага пълния набор от сложни правила за съпоставяне. Комбинирайки всички тези фактори заедно, не е изненада, че тези видове търсения могат да бъдат ресурсоемки и бавни.
Пълнотекстово търсене е мощен инструмент за езиково съвпадение, а по-новото статистическо семантично търсене е чудесно за намиране на документи с подобни значения. Но понякога наистина просто трябва да намерите низове, които съдържат конкретен подниз – подниз, който дори може да не е дума на нито един език.
Ако търсените данни не са големи или изискванията за време за реакция не са критични, използвайте LIKE '%match%' може да бъде подходящо решение. Но в странния случай, когато необходимостта от супер бързо търсене надминава всички други съображения (включително място за съхранение), може да помислите за персонализирано решение, използващо n-grams. Специфичният вариант, разгледан в тази статия, е триграма от три знака.
Търсене с заместващи знаци с помощта на триграми
Основната идея за търсене с триграма е доста проста:
- Запазване на трисимволни поднизове (триграми) на целевите данни.
- Разделете думите за търсене на триграми.
- Свържете триграмите за търсене със съхранените триграми (търсене на равенство)
- Пресечете квалифицираните редове, за да намерите низове, които съответстват на всички триграми
- Приложете оригиналния филтър за търсене към много намаленото кръстовище
Ще работим чрез пример, за да видим как точно работи всичко това и какви са компромисите.
Примерна таблица и данни
Скриптът по-долу създава примерна таблица и я попълва с милион реда низови данни. Всеки низ е дълъг 20 знака, като първите 10 знака са числови. Останалите 10 знака са смесица от цифри и букви от A до F, генерирани с помощта на NEWID() . Няма нищо ужасно специално в тези примерни данни; техниката на триграмата е доста обща.
-- Тестовата таблицаCREATE TABLE dbo.Example ( id цяло число IDENTITY NOT NULL, низ char(20) НЕ NULL, ОГРАНИЧЕНИЕ [PK dbo.Example (id)] PRIMARY KEY CLUSTERED (id));GO-- 1 милион rowsINSERT dbo. Пример С (TABLOCKX) (низ)SELECT TOP (1 * 1000 * 1000) -- 10 цифрови знака REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), ' 0') + -- плюс 10 смесени числови + [A-F] знака RIGHT(NEWID(), 10)ОТ master.dbo.spt_values КАТО SV1CROSS JOIN master.dbo.spt_values КАТО SV2OPTION (MAXDOP 1);
Отнема около 3 секунди за създаване и попълване на данните на моя скромен лаптоп. Данните са псевдослучайни, но като индикация ще изглеждат така:
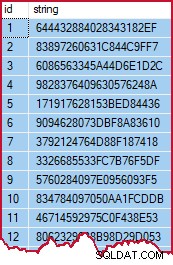
Извадка от данни
Генериране на триграми
Следната вградена функция генерира различни буквено-цифрови триграми от даден входен низ:
--- Генериране на триграми от низ CREATE FUNCTION dbo.GenerateTrigrams (@string varchar(255))ВЪРНА таблица СЪС SCHEMABINDINGAS ВЪЗРАЩАНЕ С N16 КАТО ( ИЗБЕРЕТЕ V.v ОТ ( СТОЙНОСТИ (0),(0),(0),(0) ),(0),(0),(0),(0), (0),(0),(0),(0),(0),(0),(0),(0) ) AS V (v)), -- Таблица с числа (256) Числа AS ( SELECT n =ROW_NUMBER() НАВЪРХ (ПОРЪЧКА ПО A.v) ОТ N16 КАТО КРЪСТО ПРИСЪЕДИНИ N16 AS B ), Триграми AS ( -- Всеки 3-знаков подниз ИЗБЕРЕТЕ ВЪРХА (СЛУЧАЙ, КОГАТО LEN(@string)> 2 THEN LEN(@string) - 2 ELSE 0 END) триграма =SUBSTRING(@string, N.n, 3) ОТ Nums AS N ORDER BY N.n ) -- Премахнете дубликатите и се уверете, че всички три знака са буквено-цифрови SELECT DISTINCT T.trigram FROM Trigrams AS T WHERE -- Двоично сравнение на сравнение, така че r anges работят както се очаква T.trigram COLLATE Latin1_General_BIN2 НЕ КАТО '%[^A-Z0-9a-z]%';
Като пример за неговото използване, следното извикване:
ИЗБЕРЕТЕ GT.trigramFROM dbo.GenerateTrigrams('SQLperformance.com') КАТО GT; Произвежда следните триграми:

SQLperformance.com триграми
В този случай планът за изпълнение е доста директен превод на T-SQL:
- Генериране на редове (кръстосано свързване на постоянни сканирания)
- Номериране на редове (проект за сегмент и последователност)
- Ограничаване на необходимите числа въз основа на дължината на низа (отгоре)
- Премахнете триграми с небуквени и цифрови знаци (филтър)
- Премахване на дубликати (отличително сортиране)

План за генериране на триграми
Зареждане на триграмите
Следващата стъпка е да запазите триграмите за примерните данни. Триграмите ще се съхраняват в нова таблица, попълнена с помощта на вградената функция, която току-що създадохме:
-- Триграми за Примерна таблицаCREATE TABLE dbo.ExampleTrigrams( id integer NOT NULL, trigram char(3) NOT NULL);GO-- Генериране на триграми INSERT dbo.ExampleTrigrams WITH (TABLOCKX) (id, trigram)SELECT E.id, GT.trigramFROM dbo.Пример КАТО ECROSS APPLY dbo.GenerateTrigrams(E.string) КАТО GT;
Това отнема около 20 секунди за изпълнение на моя екземпляр на лаптоп SQL Server 2016. Този конкретен цикъл произведе 17 937 972 реда на триграми за 1 милион реда от 20-символни тестови данни. Планът за изпълнение по същество показва функционалния план, който се оценява за всеки ред от таблицата с примери:
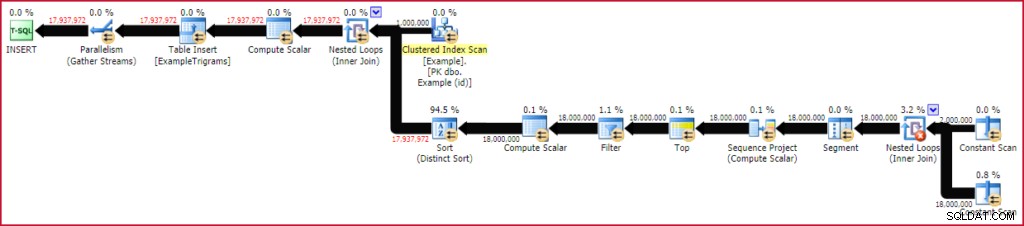
Попълване на таблицата с триграма
Тъй като този тест беше извършен на SQL Server 2016 (зареждане на хеп таблица, при ниво на съвместимост на базата данни 130 и с TABLOCK намек), планът се възползва от паралелно вмъкване. Редовете се разпределят между нишките чрез паралелното сканиране на таблицата с примери и остават в същата нишка след това (без обмен на преразпределение).
Операторът Sort може да изглежда малко внушителен, но числата показват общия брой сортирани редове за всички итерации на присъединяването на вложен цикъл. Всъщност има милион отделни сортове, по 18 реда всеки. При степен на паралелизъм от четири (две ядра с хипернишкова нишка в моя случай) има максимум четири малки сортировки, които се случват по всяко време и всеки екземпляр на сортиране може да използва повторно памет. Това обяснява защо максималното използване на паметта на този план за изпълнение е само 136 КБ (въпреки че бяха предоставени 2152 KB).
Таблицата с триграми съдържа един ред за всяка отделна триграма във всеки ред на таблицата източник (идентифициран с id ):
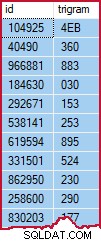
Извадка от таблица с триграми
Сега създаваме клъстериран индекс на b-дърво, за да поддържаме търсене на съвпадения на триграма:
-- Индекс за търсене на триграмаСЪЗДАВАТЕ УНИКАЛЕН КЛУСТРИРАН ИНДЕКС [CUQ dbo.ExampleTrigrams (trigram, id)]ON dbo.ExampleTrgrams (trigram, id)WITH (DATA_COMPRESSION =ROW);
Това отнема около 45 секунди , въпреки че част от това се дължи на разливането на сортиране (моят екземпляр е ограничен до 4GB памет). Инстанция с повече налична памет вероятно би могла да завърши изграждането на паралелен индекс с минимално регистриран запис доста по-бързо.
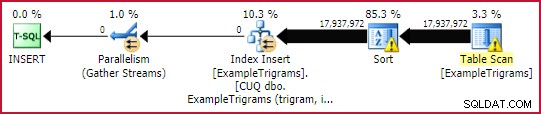
План за изграждане на индекс
Забележете, че индексът е посочен като уникален (използвайки и двете колони в ключа). Можехме да създадем неуникален клъстериран индекс само върху триграмата, но SQL Server така или иначе щеше да добави 4-байтови унификатори към почти всички редове. След като вземем предвид, че унификаторите се съхраняват в частта с променлива дължина на реда (със свързаните допълнителни разходи), просто има по-разумно да включим id в ключа и свършвайте с него.
Компресирането на ред е посочено, защото полезно намалява размера на таблицата с триграми от 277MB на 190MB (за сравнение, примерната таблица е 32MB). Ако не използвате поне SQL Server 2016 SP1 (където компресирането на данни стана достъпно за всички издания), можете да пропуснете клаузата за компресиране, ако е необходимо.
Като последна оптимизация ще създадем и индексиран изглед върху таблицата с триграми, за да направим бързо и лесно намиране кои триграми са най-често и най-рядко срещаните в данните. Тази стъпка може да бъде пропусната, но се препоръчва за производителност.
-- Селективност на всяка триграма (оптимизация на производителността)СЪЗДАВАТЕ ИЗГЛЕД dbo.ExampleTrigramCountsWITH SCHEMABINDINGASSELECT ET.trigram, cnt =COUNT_BIG(*)FROM dbo.ExampleTrigrams КАТО ETGROUP BY ET.trigram;GO-- Материализирайте изгледа CREATE CREATE UNIQLUINDEX CUQ dbo.ExampleTrigramCounts (триграма)]ON dbo.ExampleTrigramCounts (триграма);

План за сграда с индексиран изглед
Това отнема само няколко секунди, за да завърши. Размерът на материализирания изглед е малък, само 104 КБ .
Търсене в триграма
Даден низ за търсене (напр. '%find%this%' ), нашият подход ще бъде:
- Генерирайте пълния набор от триграми за низа за търсене
- Използвайте индексирания изглед, за да намерите трите най-селективни триграми
- Намерете идентификаторите, съответстващи на всички налични триграми
- Извличане на низовете по идентификатор
- Приложете пълния филтър към квалифицираните по триграма редове
Намиране на селективни триграми
Първите две стъпки са доста прости. Вече имаме функция за генериране на триграми за произволен низ. Намирането на най-селективната от тези триграми може да се постигне чрез присъединяване към индексирания изглед. Следният код обвива реализацията за нашата примерна таблица в друга вградена функция. Той завърта трите най-селективни триграми в един ред за по-лесно използване по-късно:
-- Повечето селективни триграми за низ за търсене-- Винаги връща ред (NULL, ако няма намерени триграми)CREATE FUNCTION dbo.Example_GetBestTrigrams (@string varchar(255))ВЪЗРАЩА таблица СЪС СХЕМА СВЪРЖАНЕ НА ИЗБОР НА ВЪЗРАЩАНЕ -- Pivot trigram1 =MAX СЛУЧАЙ, КОГАТО BT.rn =1 СЛУЧАЙ, КОГАТО BT.trigram END), trigram2 =MAX(CASE WHEN BT.rn =2 THEN BT.trigram END), trigram3 =MAX(CASE WHEN BT.rn =3 THEN BT.trigram END) ОТ ( -- Генерирайте триграми за низа за търсене -- и изберете най-селективните три SELECT TOP (3) rn =ROW_NUMBER() OVER ( ORDER BY ETC.cnt ASC), GT.trigram FROM dbo.GenerateTrigrams(@string) AS GT ПРИСЪЕДИНЕТЕ се dbo.ExampleTrigramCounts КАТО ETC С (NOEXPAND) ON ETC.trigram =GT.trigram ORDER BY ETC.cnt ASC ) КАТО BT;
Като пример:
ИЗБЕРЕТЕ EGBT.trigram1, EGBT.trigram2, EGBT.trigram3 ОТ dbo.Example_GetBestTrigrams('%1234%5678%') КАТО EGBT; връща (за моите примерни данни):
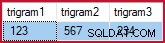
Избрани триграми
Планът за изпълнение е:
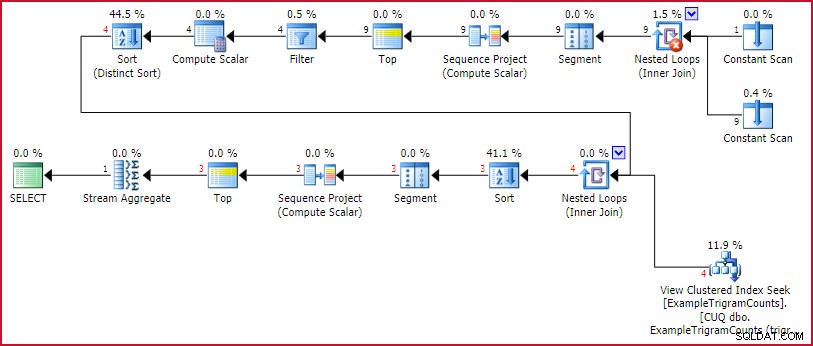
План за изпълнение на GetBestTrigrams
Това е познатият план за генериране на триграма от по-рано, последван от търсене в индексирания изглед за всяка триграма, сортиране по броя на съвпаденията, номериране на редовете (Проект на последователността), ограничаване на набора до три реда (Нагоре), след това завъртане резултата (Stream Aggregate).
Намиране на идентификатори, съответстващи на всички триграми
Следващата стъпка е да намерите примерни идентификатори на редове в таблицата, които съответстват на всички ненулеви триграми, извлечени от предишния етап. Проблемът тук е, че може да имаме налични нула, една, две или три триграма. Следната реализация обвива необходимата логика във функция с множество изрази, връщайки квалифициращите идентификатори в променлива на таблица:
-- Връща Примерни идентификатори, съответстващи на всички предоставени (не-нулеви) триграмиCREATE FUNCTION dbo.Example_GetTrigramMatchIDs( @Trigram1 char(3), @Trigram2 char(3), @Trigram3 char(3))ВЪРНА @IDs таблица (id цяло число ПЪРВИЧЕН КЛЮЧ)С ОБВЪЗВАНЕ НА СХЕМА ASBEGIN, АКО @Trigram1 НЕ Е NULL ЗАПОЧНЕ, АКО @Trigram2 НЕ Е NULL, ЗАПОЧНЕ, АКО @Trigram3 НЕ Е NULL НАЧАЛО -- налични 3 триграми ВМЕСТЕ @IDs (id) ИЗБЕРЕТЕ ET1.id ОТ dbo.Example1Trigrams .trigram =@Trigram1 INTERSECT SELECT ET2.id ОТ dbo.ExampleTrigrams AS ET2 WHERE ET2.trigram =@Trigram2 INTERSECT SELECT ET3.id ОТ dbo.ExampleTrigrams AS ET3, КЪДЕ ET3.trigram =@Trigram3 OPTION); ( КРАЙ; ELSE BEGIN -- Налични 2 триграми INSERT @IDs (id) ИЗБЕРЕТЕ ET1.id ОТ dbo.ExampleTrigrams КАТО ET1 КЪДЕ ET1.trigram =@Trigram1 INTERSECT SELECT ET2.id ОТ dbo.ExampleTrigrams КАТО ET2 КЪДЕ ET2.trigram OPTION =@Trigram ( MERGE JOIN); КРАЙ; КРАЙ; ELSE BEGIN -- 1 налична триграма INSERT @IDs (id) ИЗБЕРЕТЕ ET1.id ОТ dbo.ExampleTrigrams КАТО ET1 КЪДЕТО ET1.trigram =@Trigram1; КРАЙ; КРАЙ; ВРЪЩАНЕ;КРАЙ;
Прогнозният план за изпълнение на тази функция показва стратегията:
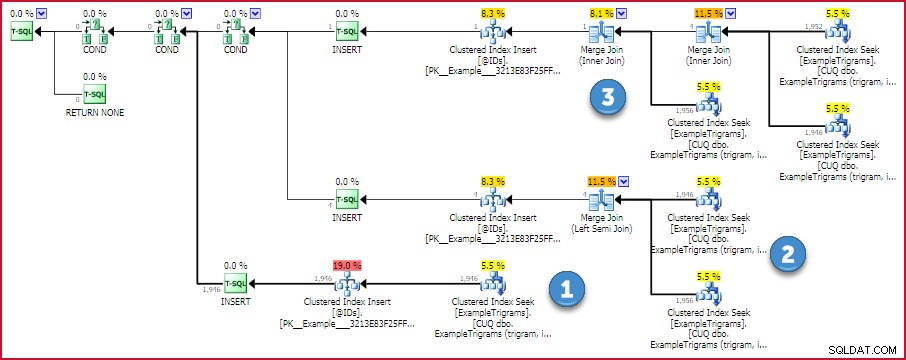
План за идентификационни номера за съвпадение на Trigram
Ако има налична една триграма, се извършва еднократно търсене в таблицата с триграми. В противен случай се извършват две или три търсения и се намира пресечната точка на идентификаторите с помощта на ефективно сливане едно към много. В този план няма оператори, които консумират памет, така че няма шанс за разливане на хеш или сортиране.
Продължавайки примерното търсене, можем да намерим идентификатори, съответстващи на наличните триграми, като приложим новата функция:
ИЗБЕРЕТЕ EGTMID.id ОТ dbo.Example_GetBestTrigrams('%1234%5678%') КАТО EGBTCROSS APPLY dbo.Example_GetTrigramMatchIDs (EGBT.trigram1, EGBT.trigram2, EGBT.trigram3) КАТО EGTMID; EGTMID; Това връща набор като следния:

Съвпадащи идентификатори
Реалният план (след изпълнение) за новата функция показва формата на плана с използвани три входа на триграма:
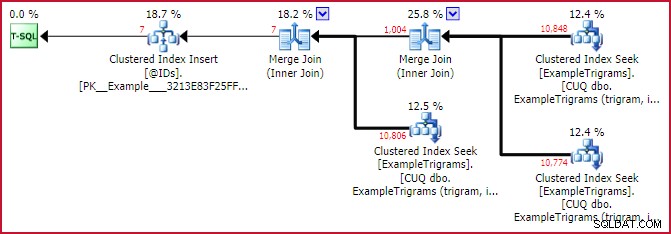
Действителен план за съвпадение на ID
Това показва доста добре силата на съвпадението на триграмата. Въпреки че всяка от трите триграми идентифицира около 11 000 реда в таблицата с примери, първото пресичане намалява този набор до 1 004 реда, а второто пресичане го намалява до само 7 .
Пълна реализация на търсене на триграма
Сега, когато имаме идентификаторите, съответстващи на триграмите, можем да потърсим съвпадащите редове в таблицата с примери. Все още трябва да приложим първоначалното условие за търсене като последна проверка, защото триграмите могат да генерират фалшиви положителни резултати (но не и фалшиви отрицателни). Последният проблем, който трябва да се обърне, е, че предишните етапи може да не са открили никакви триграми. Това може да е, например, защото низът за търсене съдържа твърде малко информация. Низ за търсене от '%FF%' не може да използва търсене на триграма, защото два знака не са достатъчни за генериране дори на една триграма. За да се справим добре с този сценарий, нашето търсене ще открие това състояние и ще се върне към търсене без триграма.
Следната последна вградена функция изпълнява необходимата логика:
-- Търсене реализацииCREATE FUNCTION dbo.Example_TrigramSearch( @Search varchar(255))ВЪРНА таблица СЪС SCHEMABINDINGASRETURN SELECT Result.string ОТ dbo.Example_GetBestTrigrams(@Search) КАТО ПРИЛАГАНЕ НА КРЪСТ GBT ( - E. Търсене на триграма ESELECT. низ ОТ dbo.Example_GetTrigramMatchIDs (GBT.trigram1, GBT.trigram2, GBT.trigram3) КАТО MID JOIN dbo.Example AS E ON E.id =MID.id WHERE -- Най-малко една намерена триграма GBT.trigram1 НЕ Е NULL И E .string LIKE @Search UNION ALL -- Търсене без триграма ИЗБЕРЕТЕ E.id, E.string ОТ dbo.Пример AS E WHERE -- Няма намерена триграма GBT.trigram1 Е NULL И E.string КАТО @Search ) КАТО Резултат;Основната характеристика е външната препратка към
GBT.trigram1от двете страни наUNION ALL. Те се превеждат във филтри със стартиращи изрази в плана за изпълнение. Филтърът за стартиране изпълнява само своето поддърво, ако условието му е вярно. Нетният ефект е, че само една част от съюза ще бъде изпълнена, в зависимост от това дали сме намерили триграма или не. Съответната част от плана за изпълнение е: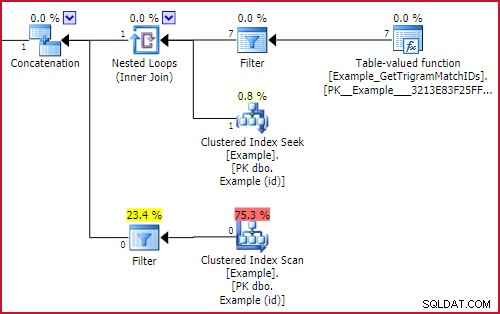
Ефект на филтър при стартиране
Или
Example_GetTrigramMatchIDsфункцията ще бъде изпълнена (и резултатите ще се търсят в Пример с помощта на търсене по идентификатор) или клъстерното индексно сканиране на примера с остатъченLIKEпредикатът ще се изпълнява, но не и двете.Ефективност
Следният код тества ефективността на търсенето на триграма спрямо еквивалентния
LIKE:ЗАДАВАНЕ НА СТАТИСТИКА XML OFFDECLARE @S datetime2 =SYSUTCDATETIME(); ИЗБЕРЕТЕ F2.stringFROM dbo.Пример КАТО F2WHERE F2.string LIKE '%1234%5678%'ОПЦИЯ (MAXDOP 1); SELECT ElapsedMS =DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());GOSET STATISTICS XML OFFDECLARE @S datetime2 =SYSUTCDATETIME(); ИЗБЕРЕТЕ ETS.stringFROM dbo.Example_TrigramSearch('%1234%5678%') КАТО ETS; ИЗБЕРЕТЕ ElapsedMS =DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());И двете произвеждат едни и същи редове с резултати, но
LIKEзаявката работи за 2100 мс , докато търсенето на триграма отнема 15 мс .Възможно е дори по-добро представяне. Като цяло производителността се подобрява, тъй като триграмите стават по-селективни и по-малко на брой (под максимума от три в тази реализация). Например:
ЗАДАВАНЕ НА СТАТИСТИКА XML OFFDECLARE @S datetime2 =SYSUTCDATETIME(); ИЗБЕРЕТЕ ETS.stringFROM dbo.Example_TrigramSearch('%BEEF%') КАТО ETS; ИЗБЕРЕТЕ ElapsedMS =DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());Това търсене върна 111 реда в SSMS мрежата за 4 мс .
LIKEеквивалентна работа за 1950 мс .Поддържане на триграмите
Ако целевата таблица е статична, очевидно няма проблем да поддържате синхронизирана базовата таблица и свързаната таблица с триграми. По същия начин, ако не се изисква резултатите от търсенето да са напълно актуални през цялото време, планираното опресняване на таблицата(ите) на триграмата може да работи добре.
В противен случай можем да използваме някои доста прости тригери, за да поддържаме данните за търсене на триграма синхронизирани с основните низове. Общата идея е да се генерират триграми за изтрити и вмъкнати редове, след което да се добавят или изтриват в таблицата с триграми според случая. Тригерите за вмъкване, актуализиране и изтриване по-долу показват тази идея на практика:
-- Поддържане на триграми след примерни вмъкванияCREATE TRIGGER MaintainTrgrams_AION dbo.ExampleAFTER INSERTASBEGIN IF @@ROWCOUNT =0 RETURN; IF TRIGGER_NESTLEVEL(@@PROCID, 'СЛЕД', 'DML')> 1 ВРЪЩАНЕ; ЗАДАДЕТЕ NOCOUNT ON; ЗАДАВАНЕ НА РЕДОВЕ 0; -- Вмъкнете свързани триграми INSERT dbo.ExampleTrigrams (id, trigram) ИЗБЕРЕТЕ INS.id, GT.trigram ОТ Вмъкнато КАТО INS CROSS APPLY dbo.GenerateTrigrams(INS.string) КАТО GT;END;-- Поддържане на триграми след Пример deletesCREATE TRIGGER MaintainTrgrams_ADON dbo.ExampleAFTER DELETEASBEGIN IF @@ROWCOUNT =0 RETURN; IF TRIGGER_NESTLEVEL(@@PROCID, 'СЛЕД', 'DML')> 1 ВРЪЩАНЕ; ЗАДАДЕТЕ NOCOUNT ON; ЗАДАВАНЕ НА РЕДОВЕ 0; -- Изтрити свързани триграми DELETE ET WITH (SERIALIZABLE) FROM Deleted AS DEL CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT JOIN dbo.ExampleTrigrams AS ET ON ET.trigram =GT.trigram И ET.id =DEL.id; КРАЙ;-- Поддържане на триграми след Примерни актуализацииCREATE TRIGGER ПоддържанеTrigrams_AUON dbo.ПримерСЛЕД АКТУАЛИЗИРАНЕ ЗАПОЧВАНЕ АКО @@ROWCOUNT =0 ВРЪЩАНЕ; IF TRIGGER_NESTLEVEL(@@PROCID, 'СЛЕД', 'DML')> 1 ВРЪЩАНЕ; ЗАДАДЕТЕ NOCOUNT ON; ЗАДАВАНЕ НА РЕДОВЕ 0; -- Изтрити свързани триграми DELETE ET WITH (SERIALIZABLE) FROM Deleted AS DEL CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT JOIN dbo.ExampleTrigrams AS ET ON ET.trigram =GT.trigram И ET.id =DEL.id; -- Вмъкнете свързани триграми INSERT dbo.ExampleTrigrams (id, trigram) ИЗБЕРЕТЕ INS.id, GT.trigram ОТ Вмъкнато КАТО INS CROSS APPLY dbo.GenerateTrigrams(INS.string) КАТО GT;END;Тригерите са доста ефективни и ще обработват промени както в един, така и в няколко реда (включително множеството действия, налични при използване на
MERGEизявление). Индексираният изглед върху таблицата с триграми ще се поддържа автоматично от SQL Server, без да е необходимо да пишем код за задействане.Операция за задействане
Като пример изпълнете оператор, за да изтриете произволен ред от примерната таблица:
-- Изтриване на един ред ИЗТРИВАНЕ НА ВЪРХА (1) dbo.Example;Планът за изпълнение (действително) след изпълнение включва запис за тригера след изтриване:
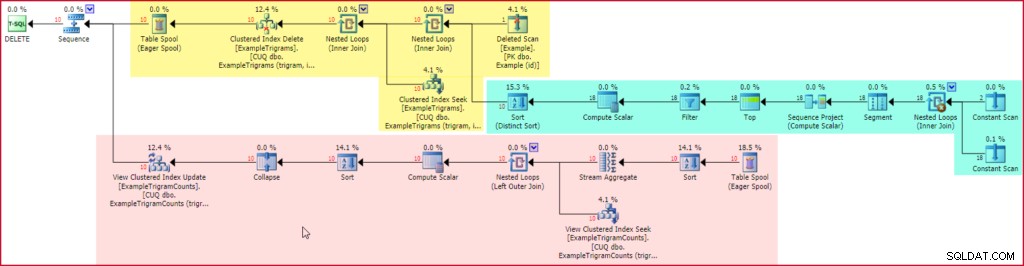
Изтриване на план за изпълнение на тригери
Жълтата секция на плана чете редове от изтрито pesudo-table, генерира триграми за всеки изтрит примерен низ (използвайки познатия план, подчертан в зелено), след това намира и изтрива свързаните записи в таблицата с триграми. Последният раздел на плана, показан в червено, се добавя автоматично от SQL Server, за да поддържа индексирания изглед актуален.
Планът за спусъка за вмъкване е изключително подобен. Актуализациите се обработват чрез извършване на изтриване, последвано от вмъкване. Изпълнете следния скрипт, за да видите тези планове и да потвърдите, че нови и актуализирани редове могат да бъдат разположени с помощта на функцията за търсене на триграма:
-- Вмъкване на един ред INSERT dbo.Пример (низ) VALUES ('SQLPerformance.com'); -- Намерете новия ред SELECT ETS.stringFROM dbo.Example_TrigramSearch('%perf%') КАТО ETS; -- Единичен ред updateUPDATE TOP (1) dbo. Пример SET string ='12345678901234567890'; -- Многоредово вмъкване INSERT dbo. Пример С (TABLOCKX) (низ)SELECT TOP (1000) REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') + НАДЯСНО(НОВИД(), 10)ОТ master.dbo.spt_values КАТО SV1; -- Многоредова актуализация UPDATE TOP (1000) dbo. Пример SET низ ='12345678901234567890'; -- Търсене на актуализираните редове SELECT ETS.string FROM dbo.Example_TrigramSearch('12345678901234567890') КАТО ETS;Пример за сливане
Следващият скрипт показва
MERGEизраз, който се използва за вмъкване, изтриване и актуализиране на примерната таблица наведнъж:-- MERGE demoDECLARE @MergeData таблица ( id integer UNIQUE CLUSTERED NULL, операция char(3) NOT NULL, низ char(20) NULL); INSERT @MergeData (id, операция, низ) VALUES (NULL, 'INS', '11223344556677889900'), -- Вмъкване (1001, 'DEL', NULL), -- Изтриване (2002, 'UPD', '0000000000'); -- Актуализиране на таблицата DECLARE @Actions ( action$ nvarchar(10) NOT NULL, old_id integer NULL, old_string char(20) NULL, new_id integer NULL, new_string char(20) NULL); MERGE dbo.Пример КАТО ИЗПОЛЗВАТЕ @MergeData КАТО MD НА MD.id =E.idWHEN MATCHED И MD.operation ='DEL' THEN DELETEWHEN MATCHED И MD.operation ='UPD' THEN UPDATE SET E.string =MD.string MATCHEN N И MD.operation ='INS' THEN INSERT (низ) СТОЙНОСТИ (MD.string)OUTPUT $action, Deleted.id, Deleted.string, Inserted.id, Inserted.stringINTO @Actions (action$, old_id, old_string, new_id, нов_низ); ИЗБЕРЕТЕ * ОТ @Действия КАТО A;Резултатът ще покаже нещо като:

Изход за действие
Последни мисли
Може би има известна възможност за ускоряване на големи операции по изтриване и актуализиране чрез директно препращане на идентификатори вместо генериране на триграми. Това не се прилага тук, защото ще изисква нов неклъстериран индекс в таблицата с триграми, удвояващ използваното (вече значително) пространство за съхранение. Таблицата с триграми съдържа едно цяло число и
char(3)на ред; неклъстериран индекс на целочислената колона ще получиchar(3)колона на всички нива (с любезното съдействие на клъстерирания индекс и необходимостта ключовете на индекса да бъдат уникални на всяко ниво). Има и място в паметта, което трябва да се вземе предвид, тъй като търсенето на триграма работи най-добре, когато всички четения са от кеша.Допълнителният индекс би направил каскадна референтна цялост като опция, но това често създава повече проблеми, отколкото си струва.
Търсенето в триграма не е панацея. Допълнителните изисквания за съхранение, сложността на внедряването и въздействието върху производителността на актуализацията са силно противопоказани. Техниката също е безполезна за търсения, които не генерират триграми (минимум 3 знака). Въпреки че основната реализация, показана тук, може да се справи с много видове търсене (започва с, съдържа, завършва с множество заместващи знаци), тя не покрива всеки възможен израз за търсене, който може да се накара да работи с
LIKE. Работи добре за низове за търсене, които генерират триграми от тип И; необходима е повече работа за обработка на низове за търсене, които изискват обработка от тип ИЛИ, или по-разширени опции като регулярни изрази.Всичко това каза, ако вашата кандидатура наистина трябва има бързо търсене на низове със заместващи знаци, n-грамите са нещо, което трябва сериозно да се обмисли.
Свързано съдържание:Един от начините да получите търсене на индекс за водещ %wildcard от Aaron Bertrand.