Харесвате ли да анализирате низове? Ако е така, една от незаменимите низови функции за използване е SQL SUBSTRING. Това е едно от онези умения, които разработчикът трябва да притежава за всеки език.
И така, как го правите?
Важни точки при анализа на низове
Да приемем, че сте нов в анализа. Какви важни точки трябва да запомните?
- Разберете каква информация е вградена в низа.
- Вземете точните позиции на всяка част от информацията в низ. Може да се наложи да преброите всички знаци в низа.
- Познайте размера или дължината на всяка част от информацията в низ.
- Използвайте функцията за правилен низ, която може лесно да извлече всяка част от информацията в низа.
Познаването на всички тези фактори ще ви подготви за използване на SQL SUBSTRING() и предаване на аргументи към него.
SQL SUBSTRING Синтаксис

Синтаксисът на SQL SUBSTRING е както следва:
SUBSTRING(низов израз, начало, дължина)
- низов израз – а литерален низ или SQL израз, който връща низ.
- стартиране – номер, от който ще започне извличането. Също така е базиран на 1 – първият знак в аргумента на низовия израз трябва да започва с 1, а не с 0. В SQL Server това винаги е положително число. В MySQL или Oracle обаче то може да бъде положително или отрицателно. Ако е отрицателен, сканирането започва от края на низа.
- дължина – дължината на знаците за извличане. SQL Server го изисква. В MySQL или Oracle е по избор.
4 примера за SQL SUBSTRING
1. Използване на SQL SUBSTRING за извличане от литерален низ
Нека започнем с прост пример, използвайки литерален низ. Използваме името на известна корейска група момичета, BlackPink, а Фигура 1 илюстрира как ще работи SUBSTRING:

Кодът по-долу показва как ще го извлечем:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Сега нека проверим и набора от резултати на фигура 2:
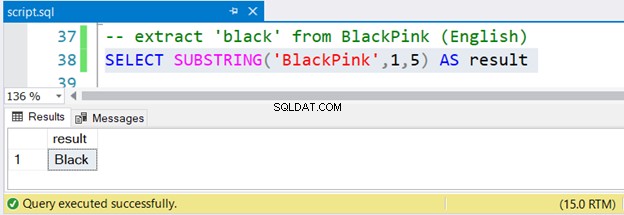
Не е ли лесно?
За извличане на черно отBlackPink , започвате от позиция 1 и завършвате на позиция 5. Тъй като BlackPink е корейски, нека разберем дали SUBSTRING работи с Unicode корейски знаци.
(ОТКАЗ ОТ ОТГОВОРНОСТ :Не мога да говоря, чета или пиша корейски, така че взех превода на корейски от Уикипедия. Използвах и Google Translate, за да видя кои знаци отговарят на Черно и Розово . Моля, извинете ми, ако не е наред. Все пак се надявам, че точката, която се опитвам да изясня, дойде и напречно)
Нека да имаме низа на корейски (вижте фигура 3). Използваните корейски знаци се превеждат на BlackPink:

Сега вижте кода по-долу. Ще извлечем два знака, съответстващи на Черен .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Забелязахте ли корейския низ, предшестван от N ? Той използва Unicode знаци, а SQL Server приема NVARCHAR и трябва да бъде предшестван от N . Това е единствената разлика в английската версия. Но дали ще работи добре? Вижте Фигура 4:
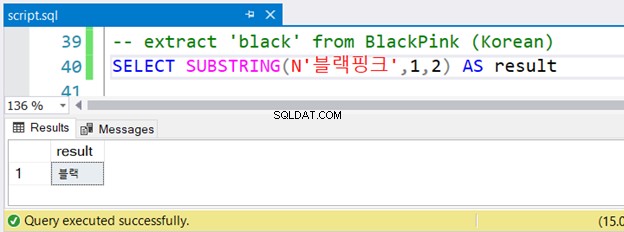
Работи без грешки.
2. Използване на SQL SUBSTRING в MySQL с отрицателен начален аргумент
Наличието на отрицателен начален аргумент няма да работи в SQL Server. Но можем да имаме пример за това, използвайки MySQL. Този път нека извлечем Розово отBlackPink . Ето кода:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Сега, нека имаме резултата на фигура 5:
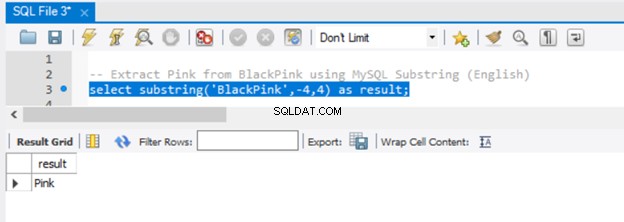
Тъй като предадохме -4 на началния параметър, извличането започна от края на низа, като върви 4 знака назад. За да постигнете същия резултат в SQL Server, използвайте функцията RIGHT().
Unicode символите също работят с MySQL SUBSTRING, както можете да видите на Фигура 6:
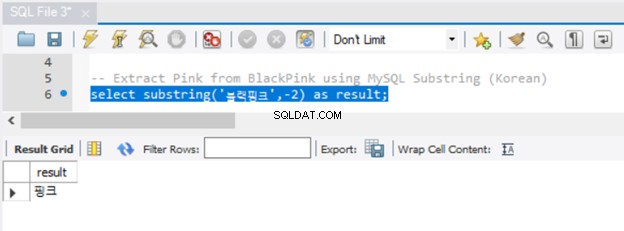
Работеше добре. Но забелязахте ли, че не е необходимо да предхождаме низа с N? Също така имайте предвид, че има няколко начина да получите подниз в MySQL. Вече видяхте SUBSTRING. Еквивалентните функции в MySQL са SUBSTR() и MID().
3. Разбор на поднизове с променливи начални и дължина аргументи
За съжаление, не всички извличания на низове използват фиксирани аргументи за начало и дължина. В такъв случай имате нужда от CHARINDEX, за да получите позицията на низ, към който сте насочени. Нека имаме пример:
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
В кода по-горе трябва да извлечете име на корейски, датата на раждане и акаунта в Instagram.
Започваме с дефиниране на три променливи, които да съхраняват тези части от информация. След това можем да анализираме низа и да присвоим резултатите на всяка променлива.
Може да си мислите, че да имате фиксирани стартове и дължини е по-лесно. Освен това можем да го определим, като преброим знаците ръчно. Но какво ще стане, ако имате много от тях на маса?
Ето нашия анализ:
- Единственият фиксиран елемент в низа е @ герой в акаунта в Instagram. Можем да получим позицията му в низа с помощта на CHARINDEX. След това използваме тази позиция, за да получим началото и дължините на останалите.
- Дата на раждане е във фиксиран формат с MM/dd/yyyy с 10 знака.
- За да извлечем името, започваме от 1. Тъй като рождената дата има 10 знака плюс @ символ, можете да стигнете до крайния знак на името в низа. От позицията на @ символ, връщаме се 11 знака назад. SUBSTRING(@lineString,1,CHARINDEX(‘@’,@lineString)-11) е пътят.
- За да получим рождената дата, прилагаме същата логика. Вземете позицията на @ знак и преместете 10 знака назад, за да получите началната стойност на датата на раждане. 10 е фиксирана дължина. SUBSTRING(@lineString,CHARINDEX(‘@’,@lineString)-10,10) е как да получите рождената дата.
- Накрая, получаването на акаунт в Instagram е лесно. Започнете от позицията на @ символ с помощта на CHARINDEX. Забележка:30 е ограничението за потребителско име в Instagram.
Вижте резултатите на фигура 7:
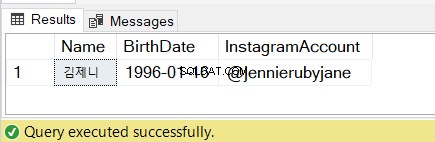
4. Използване на SQL SUBSTRING в оператор SELECT
Можете също да използвате SUBSTRING в израза SELECT, но първо трябва да имаме работни данни. Ето кода:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
Горният код прави дълъг низ, съдържащ име, имейл адрес, град и пощенски код. Също така искаме да го съхраняваме в PersonContacts таблица.
Сега нека имаме кода за обратно инженерство с помощта на SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Тъй като използвахме колони с фиксиран размер, няма нужда да използваме CHARINDEX.
Използване на SQL SUBSTRING в клауза WHERE – капан на производителността?
Вярно е. Никой не може да ви спре да използвате SUBSTRING в клауза WHERE. Това е валиден синтаксис. Но какво ще стане, ако това причини проблеми с производителността?
Ето защо ние го доказваме с пример и след това обсъждаме как да отстраним този проблем. Но първо, нека подготвим нашите данни:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Не мога да объркам SalesOrderHeader маса, така че го хвърлих на друга маса. След това направих SalesOrderID в новите Поръчки за продажба таблица първичен ключ.
Сега сме готови за запитването. Използвам dbForge Studio за SQL Server с Включен режим на профилиране на заявки за да анализирате заявките.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Както виждате, горната заявка работи добре. Сега погледнете диаграмата на плана на профила на заявка на фигура 8:
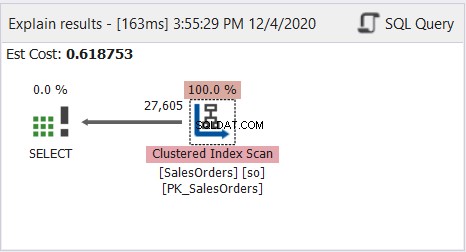
Диаграмата на плана изглежда проста, но нека да проверим свойствата на възела за сканиране на клъстериран индекс. По-специално, имаме нужда от информация за времето на изпълнение:
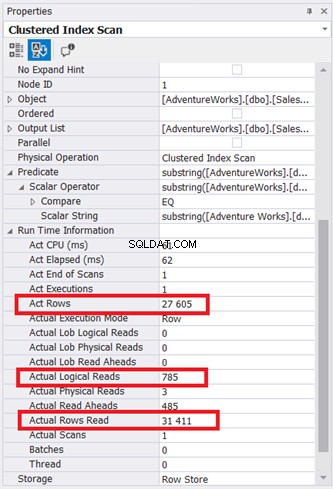
Илюстрация 9 показва 785 * 8KB страници, прочетени от двигателя на базата данни. Забележете също, че действителните прочетени редове са 31 411. Това е общият брой редове в таблицата. Заявката обаче върна само 27 605 действителни реда.
Цялата таблица беше прочетена с помощта на клъстерирания индекс като справка.
Защо?
Работата е там, че SQL Server трябва да знае дали 4030 е подниз от номер на сметка. Той трябва да чете и оценява всеки запис. Изхвърлете редовете, които не са равни и върнете редовете, от които се нуждаем. Свършва работата, но не достатъчно бързо.
Какво можем да направим, за да работи по-бързо?
Избягвайте SUBSTRING в клаузата WHERE и постигайте същия резултат по-бързо
Това, което искаме сега, е да получим същия резултат, без да използваме SUBSTRING в клаузата WHERE. Следвайте стъпките по-долу:
- Променете таблицата, като добавите изчислена колона с SUBSTRING(AccountNumber, 4,4) формула. Нека го наречем Категория на акаунт поради липса на по-добър термин.
- Създайте неклъстериран индекс за новата AccountCategory колона. Включете Дата на поръчката , Номер на акаунт и CustomerID колони.
Това е.
Променяме клаузата WHERE на заявката, за да адаптираме новата AccountCategory колона:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
В клаузата WHERE няма SUBSTRING. Сега нека проверим диаграмата на плана:
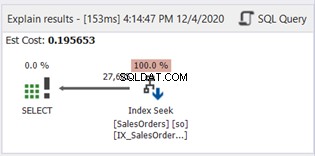
Индексното сканиране е заменено с индексно търсене. Забележете също, че SQL Server използва новия индекс на изчислената колона. Има ли промени в логическите четения и действителните четени редове? Вижте Фигура 11:
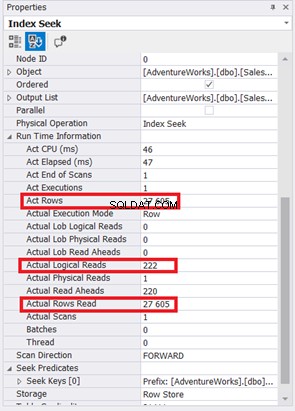
Намаляването от 785 на 222 логически четения е голямо подобрение, повече от три пъти по-малко от оригиналните логически четения. Той също така минимизира действителните редове, прочетени само до онези редове, от които се нуждаем.
По този начин използването на SUBSTRING в клаузата WHERE не е добро за производителност и важи за всяка друга функция със скаларна стойност, използвана в клаузата WHERE.
Заключение
- Разработчиците не могат да избегнат синтактичния анализ на низове. По един или друг начин ще възникне нужда от това.
- При синтактичния анализ на низове е важно да знаете информацията в низа, позициите на всяка част от информацията и техните размери или дължини.
- Една от функциите за синтактичен анализ е SQL SUBSTRING. Нуждае се само от низа за синтактичен анализ, позицията за започване на извличане и дължината на низа за извличане.
- SUBSTRING може да има различно поведение между SQL варианти като SQL Server, MySQL и Oracle.
- Можете да използвате SUBSTRING с литерални низове и низове в колони на таблицата.
- Използвахме и SUBSTRING с Unicode знаци.
- Използването на SUBSTRING или която и да е функция със скаларна стойност в клаузата WHERE може да намали производителността на заявката. Поправете това с индексирана изчислена колона.
Ако намирате тази публикация за полезна, споделете я в предпочитаните от вас социални медийни платформи или споделете коментара си по-долу?



