Нарастващото търсене на системи с висока наличност и строгите SLA ни кара да заменим ръчните процедури с автоматизирани решения. Но имате ли времето и необходимите ресурси, за да се справите сами със сложността на операциите за преодоляване на срив? Ще пожертвате ли престой на производствената база данни, за да я научите по трудния начин?
ClusterControl осигурява разширена поддръжка за откриване и обработка на неизправности. Използва се от много корпоративни организации, като поддържа най-критичните производствени системи работещи в режим 24/7.
Това решение за управление на база данни също ви подкрепя с внедряването на различни прокси сървъри за зареждане. Тези прокси сървъри играят ключова роля в стека на HA, така че няма нужда да коригирате низа за връзка с приложението или DNS запис, за да пренасочите връзките на приложението към новия главен възел.
Когато се открие неизправност, ClusterControl върши цялата работа на заден план, за да избере нов главен, да внедри подчинени сървъри при отказ и да конфигурира балансиращите устройства. В този блог ще научите как да постигнете автоматично преминаване при отказ на TimescaleDB във вашите производствени системи.
Разгръщане на цели репликационни топологии
Започвайки от ClusterControl 1.7.2, можете да разположите цяла настройка за репликация на TimescaleDB по същия начин, както бихте разгърнали PostgreSQL:можете да използвате менюто „Разгръщане на клъстер“, за да разположите първичен и един или повече резервни сървъри на TimescaleDB. Нека видим как изглежда.
Първо, трябва да дефинирате подробности за достъп, когато разгръщате нови клъстери с помощта на ClusterControl. Изисква достъп с root или sudo парола до всички възли, на които ще бъде разположен вашият нов клъстер.
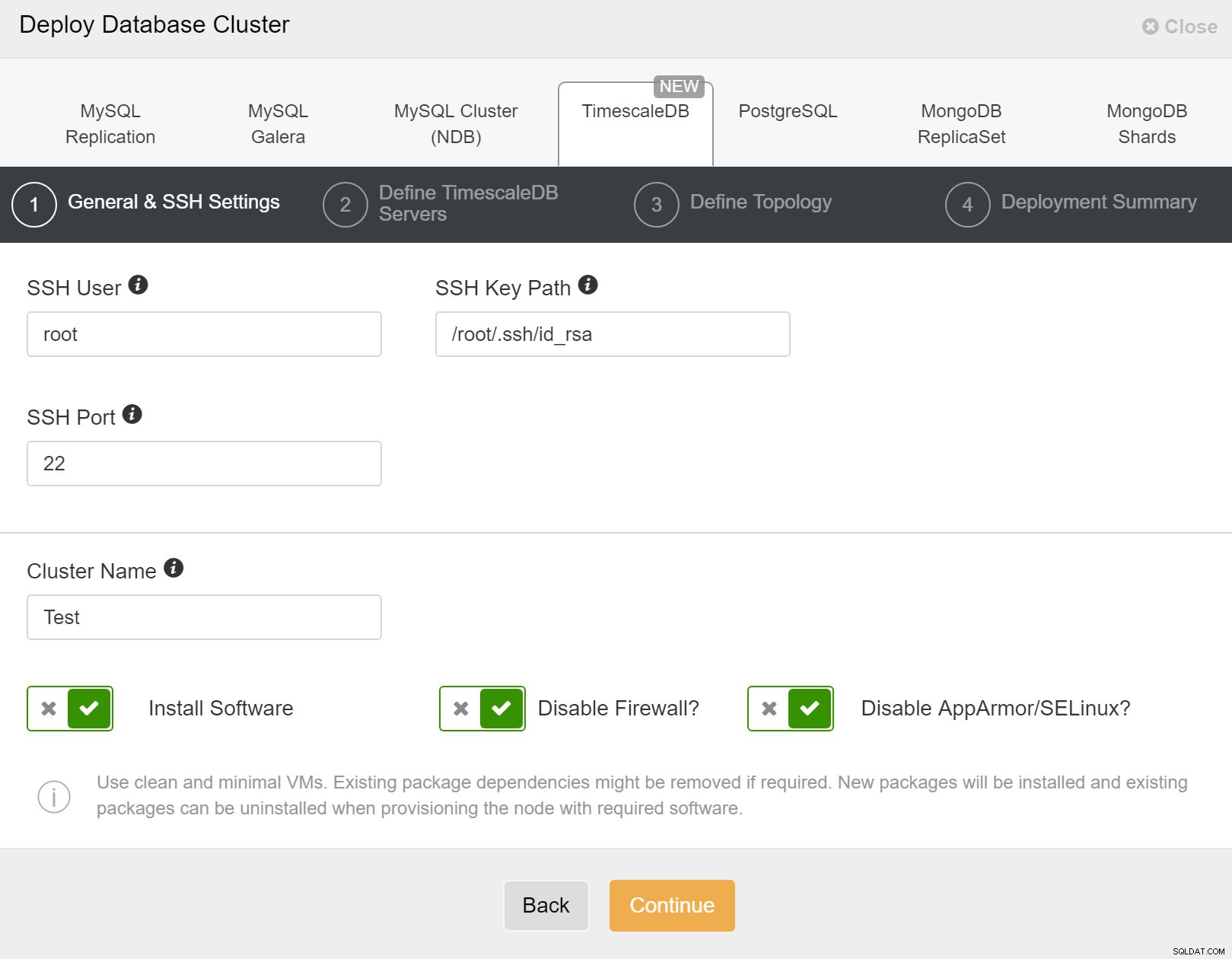 ClusterControl:Внедряване на нов клъстер
ClusterControl:Внедряване на нов клъстер След това трябва да дефинираме потребителя и паролата за потребителя на TimescaleDB.
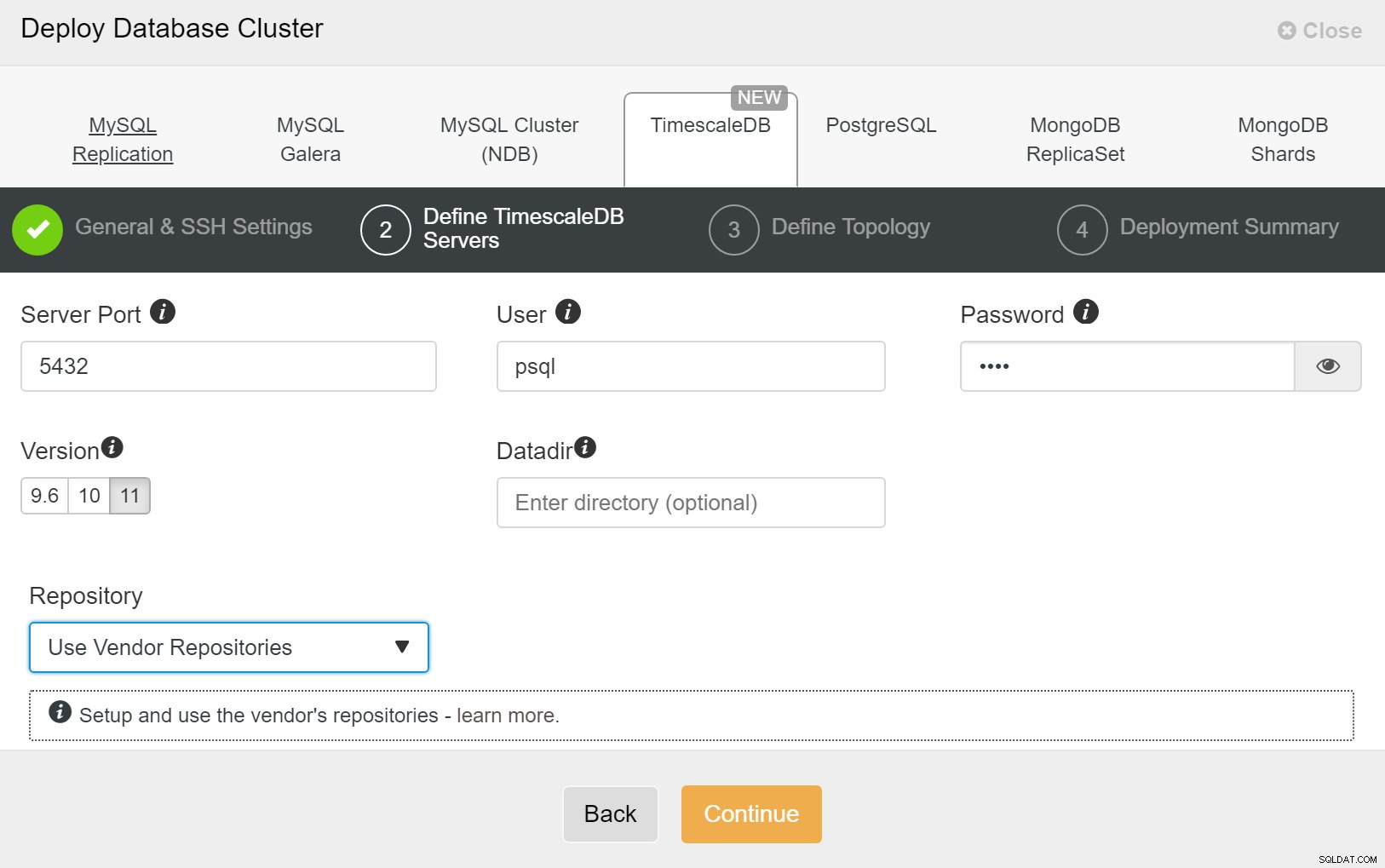 ClusterControl:Разгръщане на клъстер от база данни
ClusterControl:Разгръщане на клъстер от база данни И накрая, искате да дефинирате топологията - кой хост трябва да бъде основен и кои хостове трябва да бъдат конфигурирани като режим на готовност. Докато дефинирате хостове в топологията, ClusterControl ще провери дали ssh достъпът работи както се очаква - това ви позволява да откриете проблеми със свързаността рано. На последния екран ще бъдете попитани за типа репликация, синхронна или асинхронна.
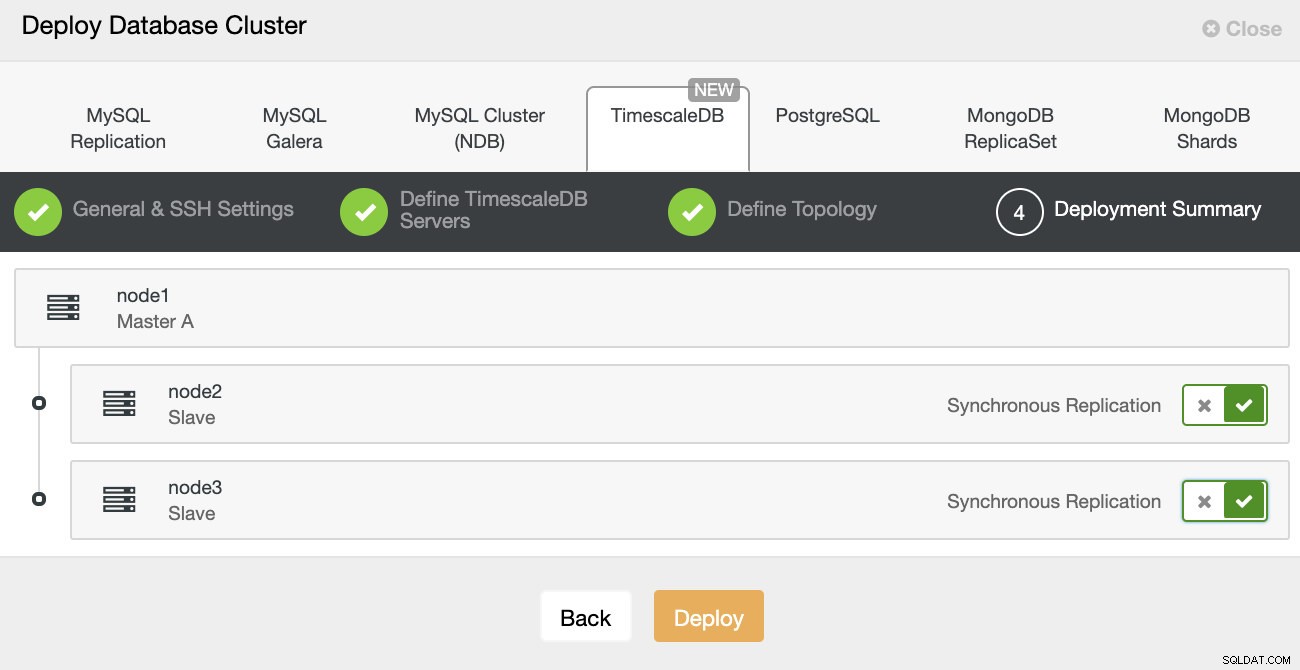 Разгръщане на ClusterControl
Разгръщане на ClusterControl Това е всичко, тогава е въпрос на започване на внедряването. В ClusterControl е създадено задание и вие ще можете да следите напредъка.
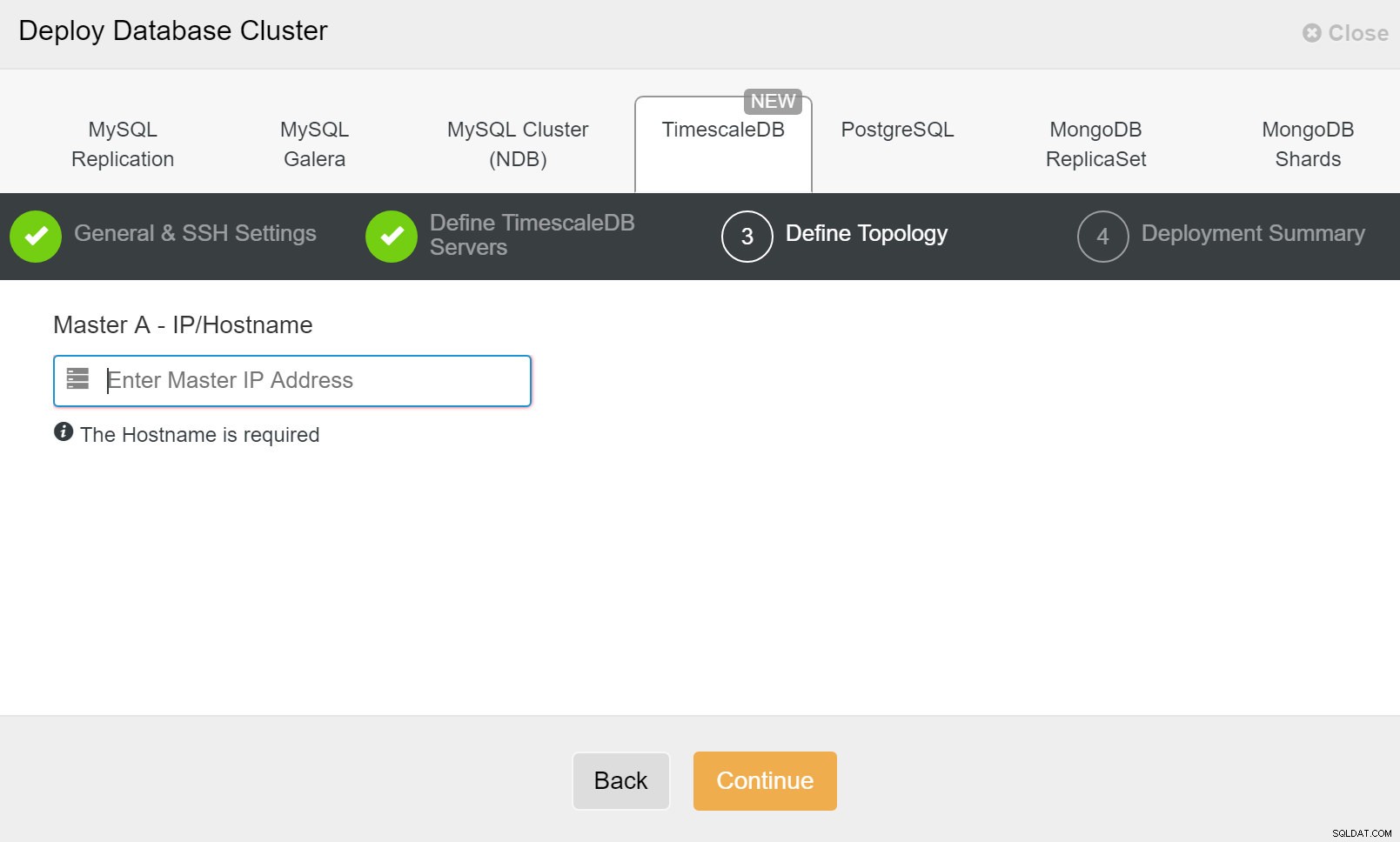 ClusterControl:Дефиниране на топология за клъстер TimescleDb
ClusterControl:Дефиниране на топология за клъстер TimescleDb След като приключите, ще видите настройката на топологията с роли в клъстера. Имайте предвид, че ние също така добавихме балансьор на натоварване (HAProxy) пред екземплярите на базата данни, така че автоматичното преминаване на отказ няма да изисква промени в настройките за връзка с базата данни.
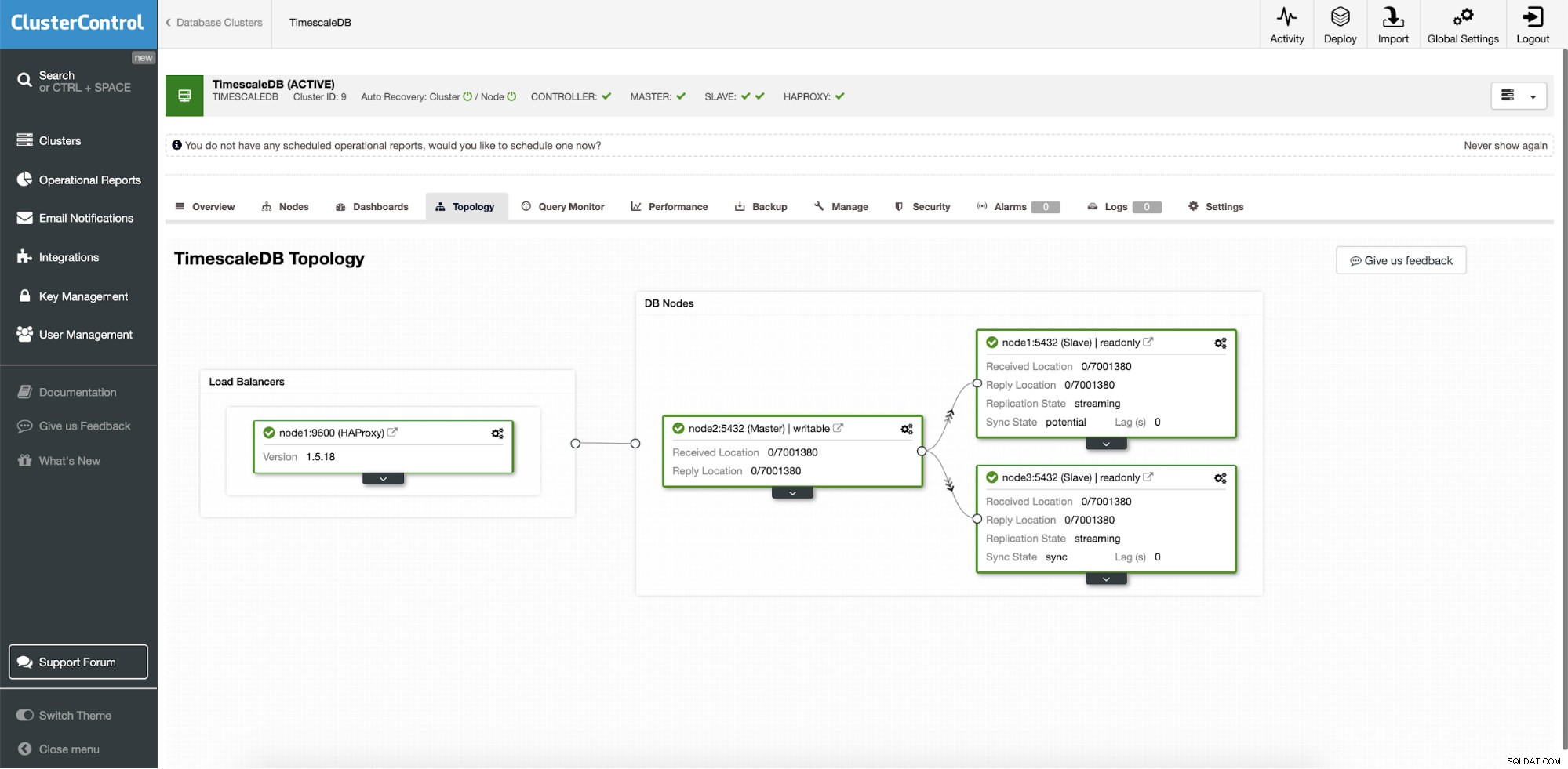 ClusterControl:Топология
ClusterControl:Топология Когато Timescale е разгърнат от ClusterControl, автоматичното възстановяване е активирано по подразбиране. Състоянието може да се провери в лентата на клъстера.
 ClusterControl:Клъстер за автоматично възстановяване и състояние на възел
ClusterControl:Клъстер за автоматично възстановяване и състояние на възел Конфигурация при отказ
След като настройката за репликация е разгърната, ClusterControl е в състояние да наблюдава настройката и автоматично да възстановява всички неуспешни сървъри. Може също да организира промени в топологията.
Автоматичното превключване при отказ на ClusterControl е проектирано със следните принципи:
- Уверете се, че главният е наистина мъртъв, преди да преминете при отказ
- Отказ само веднъж
- Не прехвърляйте при отказ към непоследователно подчинено устройство
- Пишете само на главната
- Не възстановявайте автоматично неуспешния главен код
С вградените алгоритми преминаването при отказ често може да се извърши доста бързо, за да можете да осигурите най-високите SLA за вашата среда на база данни.
Процесът е конфигурируем. Той идва с множество параметри, които можете да използвате, за да адаптирате възстановяването към спецификата на вашата среда.
| max_replication_lag | Максимално разрешено забавяне на репликацията в секунди преди |
| replication_stop_on_error | Процедурите за отказ/превключване ще се провалят, ако възникнат грешки, които могат да причинят загуба на данни. Разрешено по подразбиране. 0 означава деактивиране, |
| replication_auto_rebuild_slave | Ако SQL THREAD е спрян и кодът на грешката е различен от нула, тогава подчиненият ще бъде автоматично възстановен. 1 означава активиране, 0 означава деактивиране (по подразбиране). |
| черен_списък_при_отказ_репликация | Разделен със запетая списък с двойки име на хост:порт. Сървърите в черния списък няма да се считат за кандидат по време на отказ. replication_failover_blacklist се игнорира, ако replication_failover_whitelist е зададен. |
| replication_failover_whitelist | Списък с двойки име на хост:порт, разделен със запетая. Само сървърите в белия списък ще се считат за кандидати по време на отказ. Ако няма наличен сървър в белия списък (нагоре/свързан), преминаването при отказ ще бъде неуспешно. replication_failover_blacklist се игнорира, ако replication_failover_whitelist е зададен. |
Обработка при отказ
Когато се открие главен неизправност, се създава списък с главни кандидати и един от тях се избира да бъде новият главен. Възможно е да имате бял списък със сървъри, които да се повиши до първичен, както и черен списък на сървъри, които не могат да бъдат повишени до основни. Останалите подчинени устройства вече са подчинени от новия първичен, а старият първичен не се рестартира.
По-долу можем да видим симулация на повреда на възел.
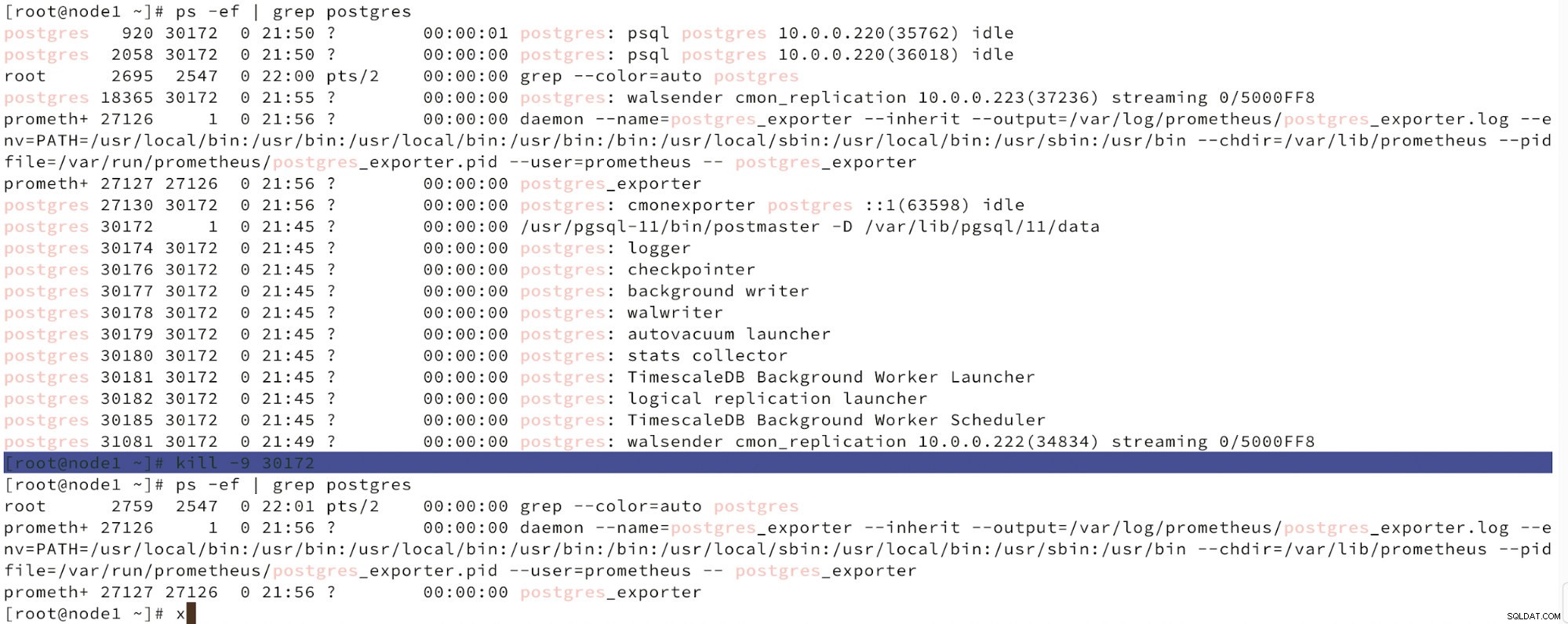 Симулира повреда на главния възел с убийство
Симулира повреда на главния възел с убийство Когато се открие неизправност на възлите и се установи автоматично възстановяване, ClusterControl задейства задание за извършване на отказ. По-долу можем да видим действията, предприети за възстановяване на клъстера.
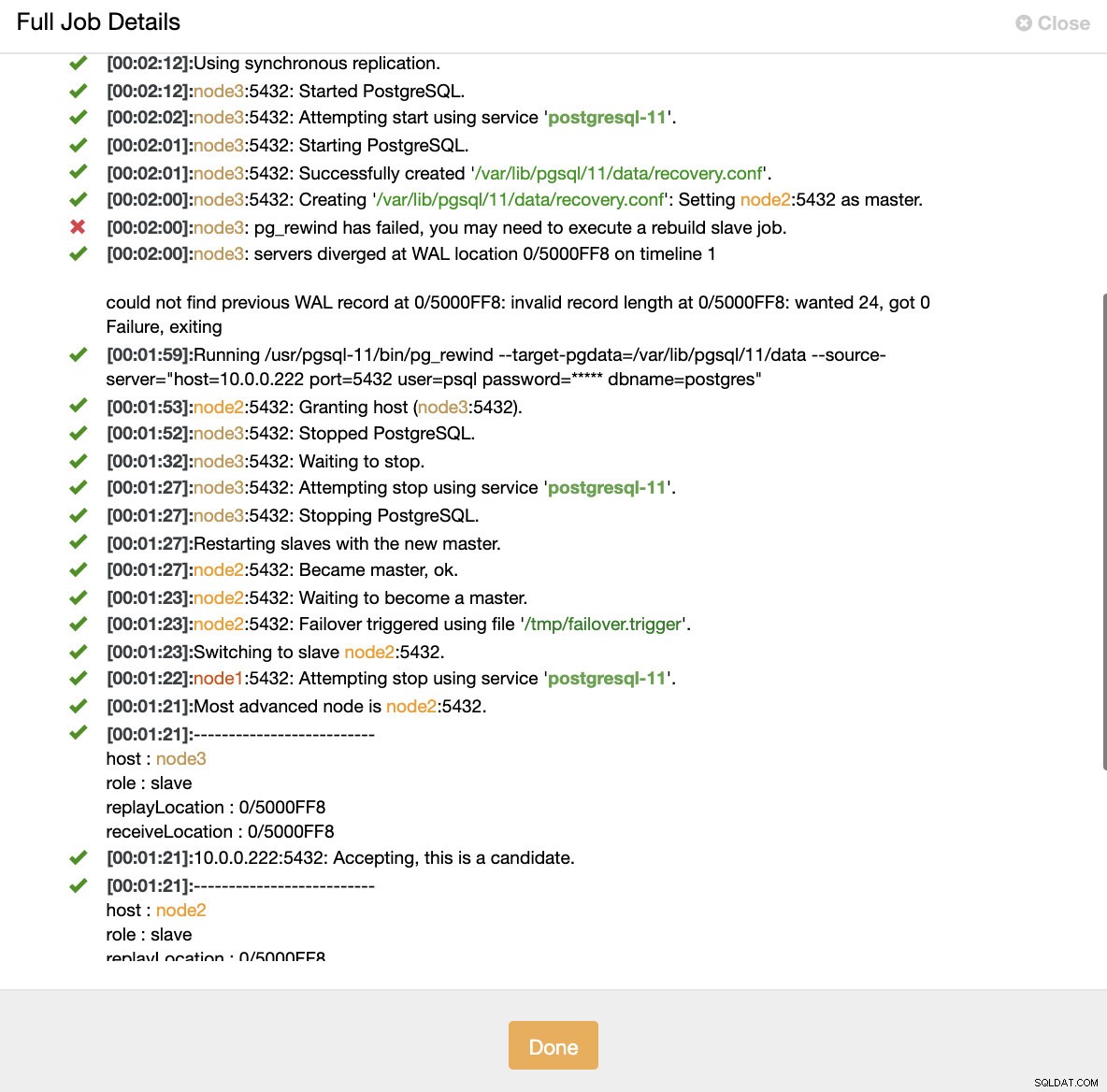 ClusterControl:Задейства се задание за възстановяване на клъстера
ClusterControl:Задейства се задание за възстановяване на клъстера ClusterControl умишлено поддържа стария първичен офлайн, защото може да се случи някои от данните да не са прехвърлени към резервните сървъри. В такъв случай основният е единственият хост, съдържащ тези данни и може да искате да възстановите липсващите данни ръчно. За тези, които искат неуспешният първичен да бъде възстановен автоматично, има опция в конфигурационния файл на cmon:replication_auto_rebuild_slave. По подразбиране той е деактивиран, но когато потребителят го активира, неуспешният първичен ще бъде възстановен като подчинен на новия първичен. Разбира се, ако има липсващи данни, които съществуват само на неуспешния първичен, тези данни ще бъдат загубени.
Преизграждане на резервни сървъри
Различна функция е задачата „Rebuild Replication Slave“, която е достъпна за всички подчинени (или резервни сървъри) в настройката за репликация. Това трябва да се използва например, когато искате да изчистите данните в режим на готовност и да ги изградите отново с ново копие на данните от първичния. Може да бъде от полза, ако сървър в режим на готовност не може да се свърже и репликира от основния по някаква причина.
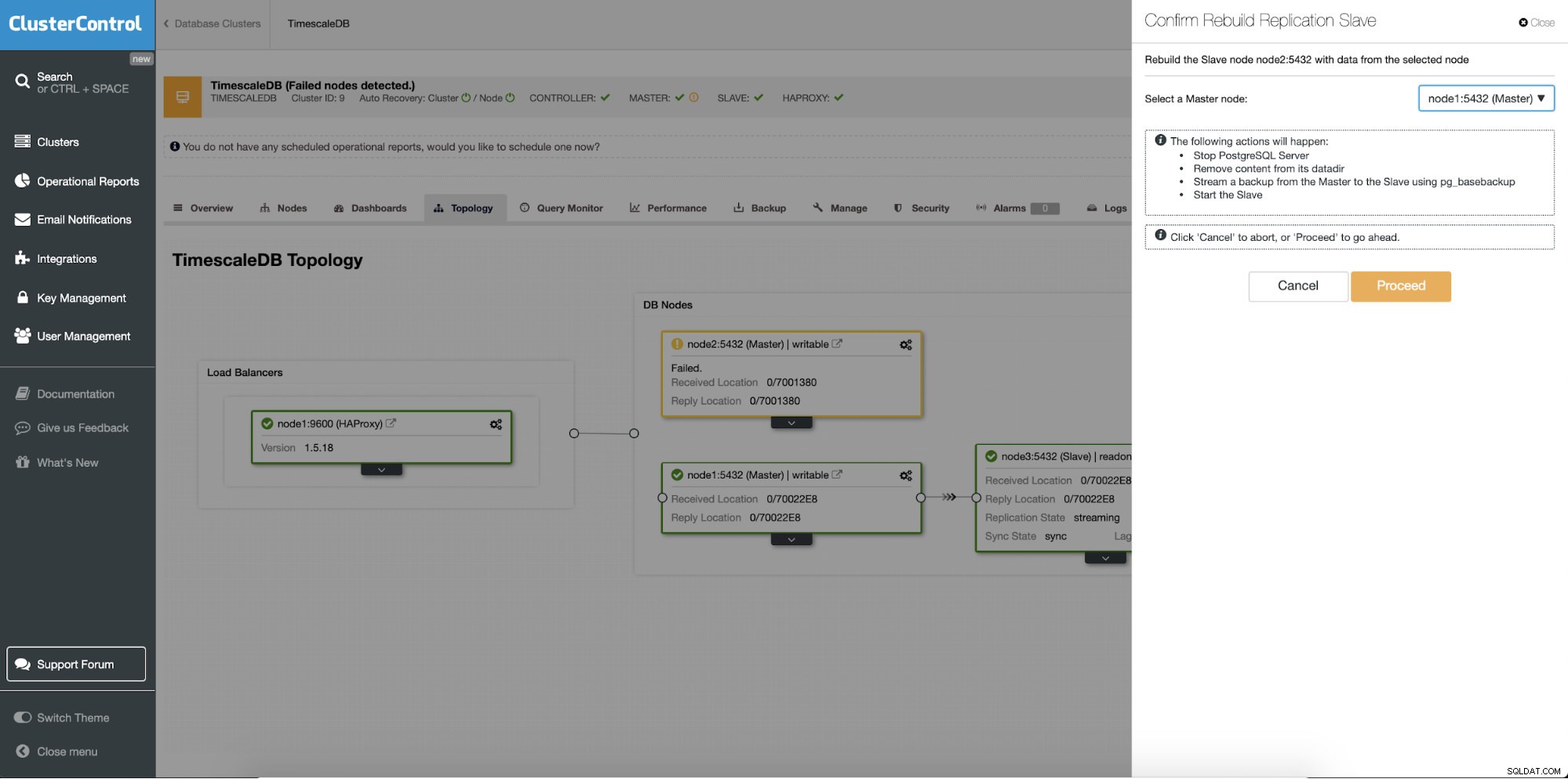 ClusterControl:Повторно изграждане на подчинен репликация
ClusterControl:Повторно изграждане на подчинен репликация 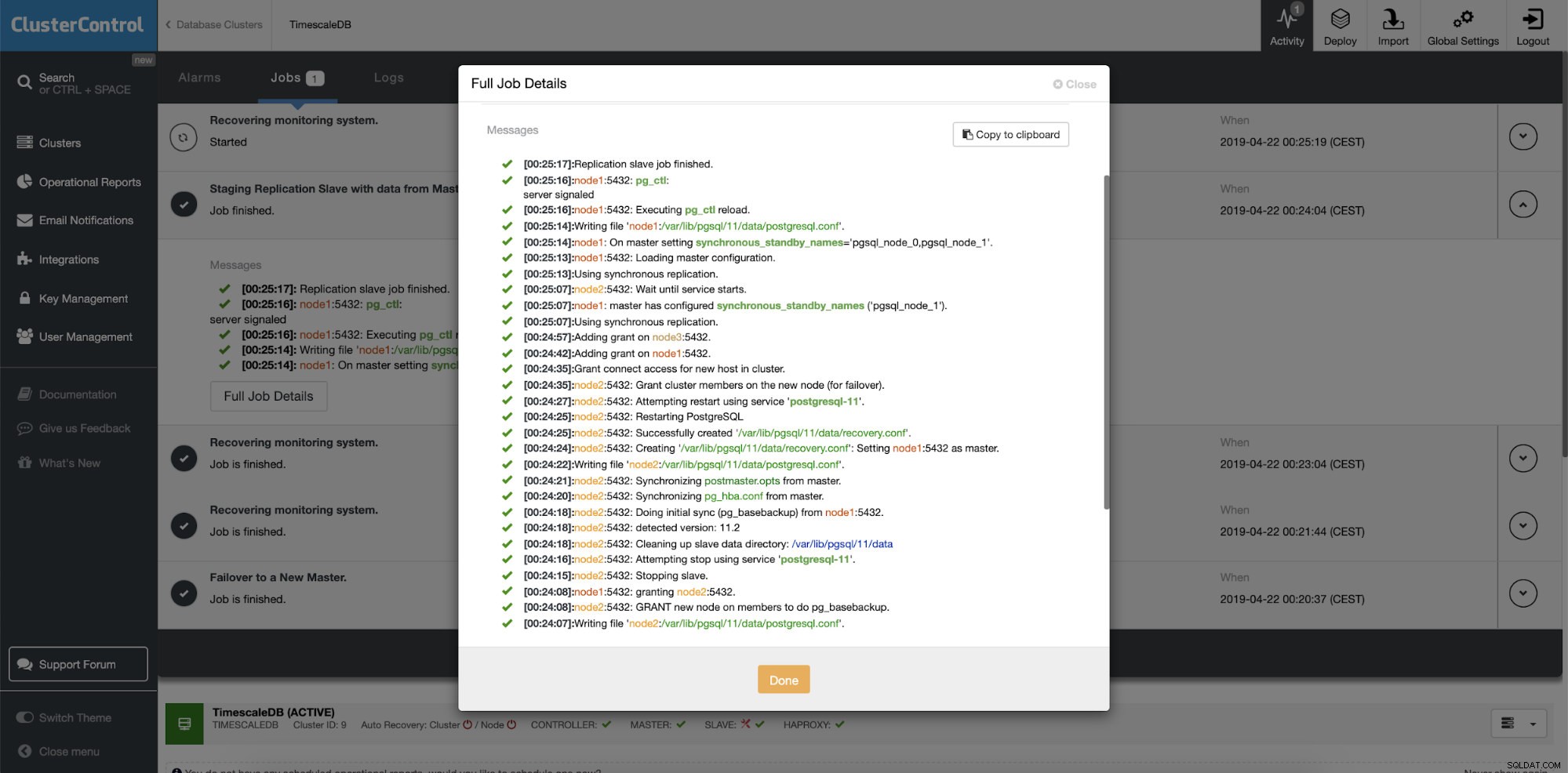 ClusterControl:Възстановяване на подчинен
ClusterControl:Възстановяване на подчинен