Дискусията за разликата в предпочитанията между FOREACH и FOR не е нова. Всички знаем, че FOREACH е по-бавен, но не всички знаят защо.
Когато започнах да уча .NET, един човек ми каза, че FOREACH е два пъти по-бавен от FOR. Той каза това без никакви основания. Приех го за даденост.
В крайна сметка реших да проуча разликата в производителността на цикъла FOREACH и FOR и да напиша тази статия, за да обсъдя нюансите.
Нека да разгледаме следния код:
foreach (var item in Enumerable.Range(0, 128))
{
Console.WriteLine(item);
}FOREACH е синтактична захар. В този конкретен случай компилаторът го трансформира в следния код:
IEnumerator<int> enumerator = Enumerable.Range(0, 128).GetEnumerator();
try
{
while (enumerator.MoveNext())
{
int item = enumerator.Current;
Console.WriteLine(item);
}
}
finally
{
if (enumerator != null)
{
enumerator.Dispose();
}
}Знаейки това, можем да предположим причината, поради която FOREACH е по-бавен от FOR:
- Създава се нов обект. Нарича се Създател.
- Методът MoveNext се извиква при всяка итерация.
- Всяка итерация има достъп до свойството Current.
Това е! Не всичко обаче е толкова лесно, колкото звучи.
За щастие (или за съжаление), C#/CLR може да извършва оптимизации по време на изпълнение. Плюсът е, че кодът работи по-бързо. Лошите – разработчиците трябва да са наясно с тези оптимизации.
Масивът е тип, дълбоко интегриран в CLR и CLR предоставя редица оптимизации за този тип. Цикълът FOREACH е итерируем обект, който е ключов аспект на производителността. По-нататък в статията ще обсъдим как да преглеждате масиви и списъци с помощта на статичния метод Array.ForEach и метода List.ForEach.
Методи за изпитване
static double ArrayForWithoutOptimization(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < array.Length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForWithOptimization(int[] array)
{
int length = array.Length;
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForeach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
foreach (var item in array)
sum += item;
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForEach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
Array.ForEach(array, i => { sum += i; });
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}Условия за тестване:
- Опцията „Оптимизиране на кода“ е включена.
- Броят на елементите е равен на 100 000 000 (както в масива, така и в списъка).
- Спецификация на компютъра:Intel Core i-5 и 8 GB RAM.
Масиви
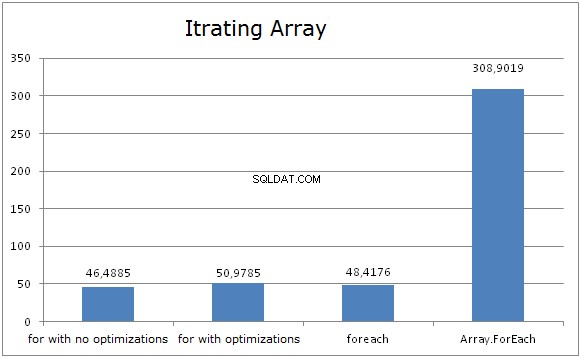
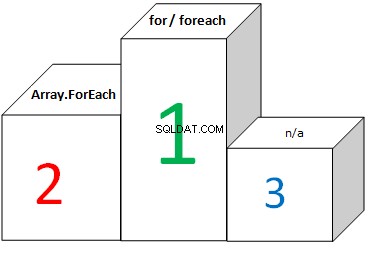
Диаграмата показва, че FOR и FOREACH прекарват еднакво време, докато итерират през масиви. И това е така, защото CLR оптимизацията преобразува FOREACH в FOR и използва дължината на масива като максимална граница на итерацията. Няма значение дали дължината на масива е кеширана или не (при използване на FOR), резултатът е почти същият.
Може да звучи странно, но кеширането на дължината на масива може да повлияе на производителността. Докато използвате масив .Дължина като граница на итерацията, JIT тества индекса за попадане в дясната граница отвъд цикъла. Тази проверка се извършва само веднъж.
Много е лесно да се унищожи тази оптимизация. Случаят, когато променливата е кеширана, почти не се оптимизира.
Масив.foreach показа най-лошите резултати. Изпълнението му е доста просто:
public static void ForEach<T>(T[] array, Action<T> action)
{
for (int index = 0; index < array.Length; ++index)
action(array[index]);
}Тогава защо работи толкова бавно? Използва FOR под капака. Е, причината е в извикването на делегата на ACTION. Всъщност при всяка итерация се извиква метод, което намалява производителността. Освен това делегатите не се извикват толкова бързо, колкото бихме искали.
Списъци

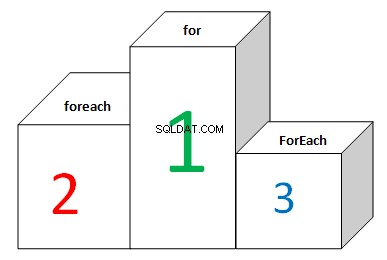
Резултатът е съвсем различен. Когато итерирате списъци, FOR и FOREACH показват различни резултати. Няма оптимизация. FOR (с кеширане на дължината на списъка) показва най-добрия резултат, докато FOREACH е повече от 2 пъти по-бавен. Това е така, защото се занимава с MoveNext и Current под капака. List.ForEach, както и Array.ForEach показва най-лошия резултат. Делегатите винаги се извикват виртуално. Реализацията на този метод изглежда така:
public void ForEach(Action<T> action)
{
int num = this._version;
for (int index = 0; index < this._size && num == this._version; ++index)
action(this._items[index]);
if (num == this._version)
return;
ThrowHelper.ThrowInvalidOperationException(ExceptionResource.InvalidOperation_EnumFailedVersion);
}Всяка итерация извиква делегат на действие. Той също така проверява дали списъкът е променен и ако е така, се генерира изключение.
List вътрешно използва модел, базиран на масив, а методът ForEach използва индекса на масива, за да премине през него, което е значително по-бързо от използването на индексатора.
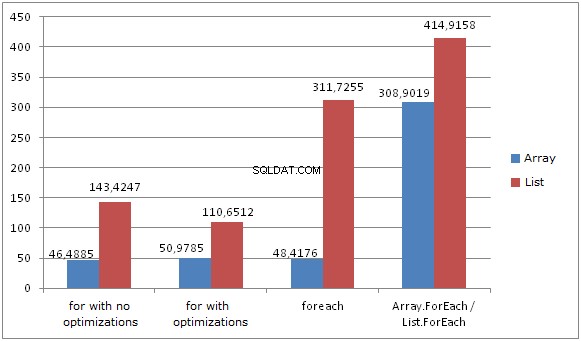
Конкретни числа
- Цикълът FOR без кеширане на дължината и FOREACH работят малко по-бързо върху масиви, отколкото FOR с кеширане на дължина.
- Масив.Foreach производителност е приблизително 6 пъти по-бавна от производителността на FOR / FOREACH.
- Цикълът FOR без кеширане на дължината работи 3 пъти по-бавно при списъци в сравнение с масивите.
- Цикълът FOR с кеширане на дължина работи 2 пъти по-бавно при списъци в сравнение с масивите.
- Цикълът FOREACH работи 6 пъти по-бавно при списъци в сравнение с масивите.
Ето табло с лидери за списъци:
И за масиви:
Заключение
Наистина ми хареса това разследване, особено процеса на писане, и се надявам, че и вие сте го харесали. Както се оказа, FOREACH е по-бърз за масиви, отколкото FOR с преследване на дължина. В списъчните структури FOREACH е по-бавен от FOR.
Кодът изглежда по-добре, когато използвате FOREACH, а съвременните процесори позволяват използването му. Въпреки това, ако трябва да оптимизирате вашата кодова база силно, по-добре е да използвате FOR.
Какво мислите, кой цикъл работи по-бързо, FOR или FOREACH?