Типът данни низ е един от най-значимите типове данни във всеки език за програмиране. Едва ли можете да напишете полезна програма без нея. Въпреки това много разработчици не познават някои аспекти от този тип. Затова нека разгледаме тези аспекти.
Представяне на низове в паметта
В .Net низовете са разположени според правилото BSTR (основен низ или двоичен низ). Този метод за представяне на низови данни се използва в COM (думата „основен“ произлиза от езика за програмиране на Visual Basic, в който е била използвана първоначално). Както знаем, PWSZ (Pointer to Wide-character String, Zero-terminated) се използва в C/C++ за представяне на низове. При такова местоположение в паметта, нулев край се намира в края на низ. Този терминатор позволява да се определи края на низа. Дължината на низа в PWSZ е ограничена само от обем свободно пространство.
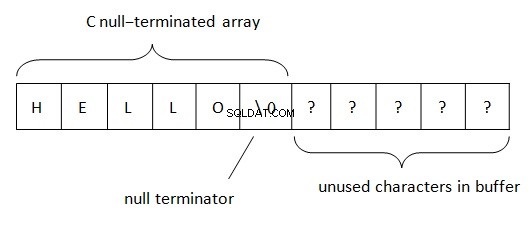
В BSTR ситуацията е малко по-различна.
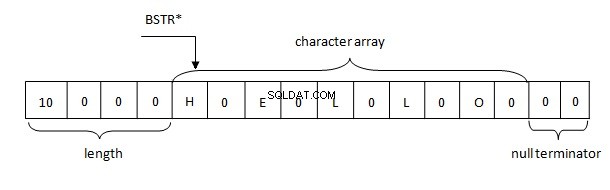
Основните аспекти на представянето на низове BSTR в паметта са следните:
- Дължината на низа е ограничена от определено число. В PWSZ дължината на низа е ограничена от наличността на свободна памет.
- BSTR низът винаги сочи към първия знак в буфера. PWSZ може да сочи към всеки знак в буфера.
- В BSTR, подобно на PWSZ, нулевият символ винаги се намира в края. В BSTR символът null е валиден знак и може да бъде намерен навсякъде в низа.
- Тъй като нулевият терминатор се намира в края, BSTR е съвместим с PWSZ, но не и обратното.
Следователно низовете в .NET са представени в паметта съгласно правилото BSTR. Буферът съдържа 4-байтова дължина на низ, последвана от двубайтови символи на низ във формат UTF-16, който от своя страна е последван от два нулеви байта (\u0000).
Използването на тази реализация има много предимства:дължината на низа не трябва да се преизчислява, тъй като се съхранява в заглавката, низът може да съдържа нулеви знаци навсякъде. И най-важното е, че адресът на низ (закачен) може лесно да бъде прехвърлен върху собствения код, където WCHAR* се очаква.
Колко памет заема един низ обект?
Срещнах статии, в които се посочва, че размерът на низовия обект е равен на size=20 + (дължина/2)*4, но тази формула не е съвсем правилна.
Като начало низът е тип връзка, така че първите четири байта съдържат SyncBlockIndex и следващите четири байта съдържат указателя за типа.
Размер на низа =4 + 4 + …
Както казах по-горе, дължината на низа се съхранява в буфера. Това е поле от тип int, следователно трябва да добавим още 4 байта.
Размер на низа =4 + 4 + 4 + …
За да прехвърлите бързо низ към собствения код (без копиране), нулевият терминатор се намира в края на всеки низ, който отнема 2 байта. Следователно,
Размер на низа =4 + 4 + 4 + 2 + …
Единственото, което остава, е да си припомним, че всеки знак в низ е в UTF-16 кодиране и също така отнема 2 байта. Следователно:
Размер на низа =4 + 4 + 4 + 2 + 2 * дължина =14 + 2 * дължина
Още нещо и сме готови. Паметта, разпределена от мениджъра на паметта в CLR, е кратна на 4 байта (4, 8, 12, 16, 20, 24, ...). Така че, ако дължината на низа заема общо 34 байта, ще бъдат разпределени 36 байта. Трябва да закръглим стойността си до най-близкото по-голямо число, което е кратно на четири. За целта ни трябва:
Размер на низ =4 * ((14 + 2 * дължина + 3) / 4) (цело число)
Проблемът с версиите :до .NET v4 имаше допълнителен m_arrayLength поле от типа int в класа String, което заема 4 байта. Това поле е реална дължина на буфера, разпределен за низ, включително нулевия терминатор, т.е. е дължина + 1. В .NET 4.0 това поле беше изхвърлено от класа. В резултат на това обект тип низ заема 4 байта по-малко.
Размерът на празен низ без m_arrayLength поле (т.е. в .Net 4.0 и по-високи) е равно на =4 + 4 + 4 + 2 =14 байта и с това поле (т.е. по-ниско от .Net 4.0), неговият размер е равен =4 + 4 + 4 + 4 + 2 =18 байта. Ако закръглим 4 байта, размерът ще бъде съответно 16 и 20 байта.
Аспекти на низове
И така, разгледахме представянето на низовете и размера, който те заемат в паметта. Сега нека поговорим за техните особености.
Основните аспекти на низовете в .NET са следните:
- Стринговете са референтни типове.
- Стринговете са неизменни. Веднъж създаден, низ не може да бъде променен (по справедливи средства). Всяко извикване на метода от този клас връща нов низ, докато предишният низ става плячка за събирача на боклук.
- Стринговете предефинират метода Object.Equals. В резултат на това методът сравнява стойностите на знаци в низове, а не стойностите на връзките.
Нека разгледаме всяка точка в детайли.
Стринговете са референтни типове
Низовете са реални референтни типове. Тоест те винаги са разположени в купчина. Много от нас ги бъркат със стойностни типове, тъй като и вие се държите по същия начин. Например, те са неизменни и тяхното сравнение се извършва по стойност, а не по препратки, но трябва да имаме предвид, че това е референтен тип.
Стринговете са неизменни
- Стринговете са неизменни за определена цел. Неизменяемостта на низовете има редица предимства:
- Типът низ е безопасен за нишки, тъй като нито една нишка не може да промени съдържанието на низ.
- Използването на неизменяеми низове води до намаляване на натоварването на паметта, тъй като не е необходимо да се съхраняват 2 екземпляра на един и същи низ. В резултат на това се изразходва по-малко памет и сравнението се извършва по-бързо, тъй като се сравняват само препратките. В .NET този механизъм се нарича интерниране на низове (string pool). Ще говорим за това малко по-късно.
- Когато предаваме неизменяем параметър към метод, можем да спрем да се притесняваме, че той ще бъде променен (ако не е бил предаден като ref или изход, разбира се).
Структурите от данни могат да бъдат разделени на два типа:ефимерни и постоянни. Ефемерните структури от данни съхраняват само последните си версии. Постоянните структури от данни запазват всичките си предишни версии по време на модификация. Последните всъщност са неизменни, тъй като техните операции не променят структурата на място. Вместо това те връщат нова структура, базирана на предишната.
Предвид факта, че низовете са неизменни, те могат да бъдат постоянни, но не са. Низовете са ефимерни в .Net.
За сравнение, нека вземем Java низове. Те са неизменни, както в .NET, но освен това са постоянни. Реализацията на класа String в Java изглежда по следния начин:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
В допълнение към 8 байта в заглавката на обекта, включително препратка към типа и препратка към обект за синхронизация, низовете съдържат следните полета:
- Препратка към char масив;
- Индекс на първия знак от низа в char масива (отместен от началото)
- Броят на знаците в низа;
- Хеш-кодът, изчислен след първо извикване на HashCode() метод.
Низовете в Java заемат повече памет, отколкото в .NET, тъй като съдържат допълнителни полета, позволяващи им да бъдат постоянни. Благодарение на постоянството, изпълнението на String.substring() метод в Java отнема O(1) , тъй като не изисква копиране на низове, както в .NET, където изпълнението на този метод отнема O(n) .
Внедряване на метод String.substring() в Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} Въпреки това, ако изходният низ е достатъчно голям и изрязаният подниз е с дължина от няколко знака, целият масив от знаци на първоначалния низ ще бъде чакащ в паметта, докато има препратка към подниза. Или, ако сериализирате получения подниз по стандартни средства и го предадете през мрежата, целият оригинален масив ще бъде сериализиран и броят на байтовете, които се предават по мрежата, ще бъде голям. Следователно вместо кода
s =ss.substring(3)
може да се използва следният код:
s =нов низ(ss.substring(3)),
Този код няма да съхранява препратката към масива от знаци на изходния низ. Вместо това, той ще копира само действително използваната част от масива. Между другото, ако извикаме този конструктор на низ, чиято дължина е равна на дължината на масива от знаци, копирането няма да се осъществи. Вместо това ще се използва препратката към оригиналния масив.
Както се оказа, реализацията на типа низ е променена в последната версия на Java. Сега в класа няма полета за отместване и дължина. Новият hash32 (с различен алгоритъм за хеширане) е въведен вместо това. Това означава, че низовете вече не са постоянни. Сега, String.substring метод ще създава нов низ всеки път.
Низът предефинира Onbject.Equals
Класът string предефинира метода Object.Equals. В резултат на това се извършва сравнение, но не по препратка, а по стойност. Предполагам, че разработчиците са благодарни на създателите на класа String за предефинирането на оператора ==, тъй като кодът, който използва ==за сравнение на низове, изглежда по-задълбочен от извикването на метода.
if (s1 == s2)
В сравнение с
if (s1.Equals(s2))
Между другото, в Java операторът ==сравнява чрез препратка. Ако трябва да сравнявате низове по знак, трябва да използваме метода string.equals().
Интерниране на низ
И накрая, нека разгледаме интернирането на низове. Нека да разгледаме прост пример – код, който обръща низ.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Очевидно този код не може да бъде компилиран. Компилаторът ще хвърли грешки за тези низове, тъй като се опитваме да модифицираме съдържанието на низа. Всеки метод от класа String връща нов екземпляр на низа, вместо промяна на съдържанието му.
Низът може да бъде променен, но ще трябва да използваме опасния код. Нека разгледаме следния пример:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} След изпълнение на този код, elbatummi era sgnirtS ще бъде записано в низа, както се очаква. Променливостта на низовете води до фантастичен случай, свързан с интернирането на низове.
Интерниране на низ е механизъм, при който подобни литерали се представят в паметта като един обект.
Накратко, смисълът на интернирането на низове е следният:има една хеширана вътрешна таблица в рамките на процес (не в рамките на домейн на приложение), където низовете са неговите ключове, а стойностите са препратки към тях. По време на JIT компилацията литералните низове се поставят в таблица последователно (всеки низ в таблицата може да бъде намерен само веднъж). По време на изпълнение от тази таблица се присвояват препратки към литерални низове. По време на изпълнение можем да поставим низ във вътрешна таблица с String.Intern метод. Също така можем да проверим наличността на низ във вътрешната таблица с помощта на String.IsInterned метод.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Имайте предвид, че само низови литерали са интернирани по подразбиране. Тъй като хешираната вътрешна таблица се използва за интерниране, търсенето в тази таблица се извършва по време на JIT компилация. Този процес отнема известно време. Така че, ако всички низове са интернирани, това ще намали оптимизацията до нула. По време на компилацията в IL код, компилаторът обединява всички литерални низове, тъй като няма нужда да ги съхранявате на части. Следователно второто равенство връща true .
Сега да се върнем към нашия случай. Помислете за следния код:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Изглежда, че всичко е съвсем очевидно и кодът трябва да върне Strings are inmutable . Въпреки това не става! Кодът връща elbatummi era sgnirtS . Това се случва точно заради интернирането. Когато модифицираме низове, ние променяме съдържанието му и тъй като е литерален, той се интернира и представлява от единичен екземпляр на низа.
Можем да изоставим интернирането на низове, ако приложим CompilationRelaxationsAttribute атрибут на събранието. Този атрибут контролира точността на кода, създаден от JIT компилатора на CLR средата. Конструкторът на този атрибут приема CompilationRelaxations изброяване, което понастоящем включва само CompilationRelaxations.NoStringInterning . В резултат на това монтажът е маркиран като този, който не изисква интерниране.
Между другото, този атрибут не се обработва в .NET Framework v1.0. Ето защо беше невъзможно да се деактивира интернирането. От версия 2, mscorlib монтажът е маркиран с този атрибут. Така се оказва, че низовете в .NET могат да бъдат модифицирани с опасния код.
Ами ако забравим за опасното?
Както се случва, можем да променим съдържанието на низове без опасния код. Вместо това можем да използваме механизма за отражение. Този трик беше успешен в .NET до версия 2.0. След това разработчиците на класа String ни лишиха от тази възможност. В .NET 2.0 класът String има два вътрешни метода:SetChar за проверка на границите и InternalSetCharNoBoundsCheck това не прави проверка на границите. Тези методи задават посочения знак с определен индекс. Реализацията на методите изглежда по следния начин:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Следователно можем да променим съдържанието на низа без опасен код с помощта на следния код:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Както се очаква, кодът връща elbatummi era sgnirtS .
Проблемът с версиите :в различни версии на .NET Framework string.Empty може да бъде интегриран или не. Нека разгледаме следния код:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); В .NET Framework 1.0, .NET Framework 1.1 и .NET Framework 3.5 със сервизен пакет 1 (SP1), str1 и str2 не са равни. В момента string.Empty не е интерниран.
Аспекти на производителността
Има един отрицателен страничен ефект от интернирането. Работата е там, че препратката към интерниран обект String, съхранен от CLR, може да бъде запазена дори след края на работата на приложението и дори след края на работата на домейна на приложението. Ето защо е по-добре да пропуснете използването на големи литерални низове. Ако все още се изисква, стажирането трябва да бъде деактивирано чрез прилагане на CompilationRelaxations атрибут на сглобяване.