Единични предикати
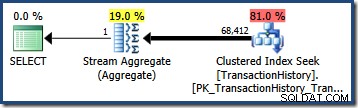
Изчисляването на броя на редовете, квалифицирани от един предикат на заявка, често е лесно. Когато предикат прави просто сравнение между колона и скаларна стойност, шансовете са добри оценителя на мощността ще може да изведе оценка с добро качество от статистическата хистограма. Например, следната заявка на AdventureWorks произвежда точно правилна оценка от 203 реда (ако приемем, че не са правени промени в данните от създаването на статистиката):
ИЗБЕРЕТЕ COUNT_BIG(*)ОТ Production.TransactionHistory КАТО THWHERE TH.TransactionDate ='20070903';
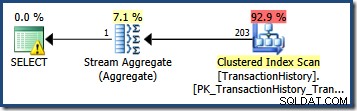
Разглеждане на статистическата хистограма за TransactionDate колона, е ясно да се види откъде идва тази оценка:
DBCC SHOW_STATISTICS ( 'Production.TransactionHistory', 'TransactionDate')С ХИСТОГРАМА;
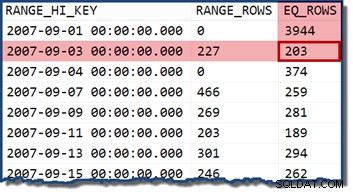
Ако променим заявката, за да посочим дата, която попада в рамките на хистограма, оценителят на мощността приема, че стойностите са равномерно разпределени. Използване на дата от 2007-09-02 произвежда оценка от 227 реда (от RANGE_ROWS влизане). Като интересна странична бележка, оценката остава на 227 реда, независимо от частта от време, която бихме могли да добавим към стойността на датата (TransactionDate колоната е datetime тип данни).
Ако опитаме заявката отново с дата на 2007-09-05 или 2007-09-06 (и двете попадат между 2007-09-04 и 2007-09-07 стъпки на хистограма), оценителят на мощността приема 466 RANGE_ROWS са равномерно разделени между двете стойности, като се оценяват 233 реда и в двата случая.
Има много други подробности за оценката на мощността за прости предикати, но горното ще служи като освежаване за нашите настоящи цели.
Проблемите с множество предикати
Когато заявка съдържа повече от един предикат на колона, оценката на мощността става по-трудна. Помислете за следната заявка с два прости предиката (всеки от които е лесно да се оцени самостоятелно):
ИЗБЕРЕТЕ COUNT_BIG(*)FROM Production.TransactionHistory КАТО THWHERE TH.TransactionID МЕЖДУ 100000 И 168412 И TH.TransactionDate BETWEEN '20070901' И '20080313';
Конкретните диапазони от стойности в заявката са умишлено избрани, така че и двата предиката да идентифицират точно едни и същи редове. Бихме могли лесно да модифицираме стойностите на заявката, за да доведат до всякакво припокриване, включително изобщо да няма припокриване. Представете си сега, че вие сте оценителят на мощността:как бихте извели оценка на мощността за тази заявка?
Проблемът е по-труден, отколкото изглежда на пръв поглед. По подразбиране SQL Server автоматично създава статистически данни с една колона и за двете предикатни колони. Можем също така да създадем ръчно статистика за няколко колони. Това дава ли ни достатъчно информация, за да направим добра оценка за тези специфични стойности? Какво ще кажете за по-общия случай, когато може да има някакви степен на припокриване?
Използвайки двата статистически обекта с една колона, можем лесно да извлечем оценка за всеки предикат, използвайки метода на хистограмата, описан в предишния раздел. За конкретните стойности в заявката по-горе, хистограмите показват, че TransactionID се очаква диапазонът да съответства на 68412.4 редове и TransactionDate се очаква диапазонът да съответства на 68 413 редове. (Ако хистограмите бяха перфектни, тези две числа биха били абсолютно еднакви.)
Какво хистограмите не могат кажете ни колко от тези два набора редове ще бъдат същите редове . Всичко, което можем да кажем въз основа на информацията от хистограмата, е, че нашата оценка трябва да бъде някъде между нула (за никакво припокриване) и 68412,4 реда (пълно припокриване).
Създаването на статистически данни с няколко колони не предоставя помощ за тази заявка (или за заявки за диапазон като цяло). Статистиката с няколко колони все още създава само хистограма върху първата именувана колона, като по същество дублира хистограмата, свързана с една от автоматично създадените статистики. Допълнителната плътност информацията, предоставена от статистиката с няколко колони, може да бъде полезна за предоставяне на информация за среден случай за заявки, които съдържат множество предикати за равенство, но тук те не са ни от помощ.
За да направим оценка с висока степен на увереност, ще ни трябва SQL Server, който да предостави по-добра информация за разпределението на данните – нещо като многоизмерен статистическа хистограма. Доколкото знам, понастоящем нито една търговска машина за бази данни не предлага подобна възможност, въпреки че са публикувани няколко технически доклада по темата (включително един Microsoft Research, който използва вътрешна разработка на SQL Server 2000).
Без да знаем нищо за корелациите и припокриванията на данните за определени диапазони от стойности, не е ясно как трябва да продължим, за да направим добра оценка за нашата заявка. И така, какво прави SQL Server тук?
SQL Server 7 – 2012
Оценителят на мощността в тези версии на SQL Server обикновено приема, че стойностите на различни атрибути в таблица се разпределят напълно независимо една от друга. Това предположение за независимост рядко е точно отражение на реалните данни, но има предимството да прави по-прости изчисления.
И Селективност
Използвайки предположението за независимост, два предиката, свързани с AND (известен като съединител ) със селективности S1 и S2 , води до комбинирана селективност на:
(S1 * S2)
В случай, че терминът не ви е познат, селективност е число между 0 и 1, представляващо частта от редовете в таблицата, които предават предиката. Например, ако предикат избере 12 реда от таблица от 100 реда, селективността е (12/100) =0,12.
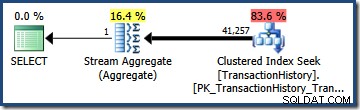
В нашия пример, TransactionHistory таблицата съдържа общо 113 443 реда. Предикатът на TransactionID се изчислява (от хистограмата) за квалифициране на 68 412,4 реда, така че селективността е (68 412,4 / 113 443) или приблизително 0,603055 . Предикатът на TransactionDate по подобен начин се оценява, че има селективност от (68 413 / 113 443) =приблизително 0,603061 .
Умножаването на двете селективности (с помощта на формулата по-горе) дава комбинирана оценка на селективността от 0,363679 . Умножаването на тази селективност по мощността на таблицата (113 443) дава крайната оценка от 41 256,8 редове:
ИЛИ Селективност
Два предиката, свързани с OR (дизюнкция ) със селективности S1 и S2 , води до комбинирана селективност на:
(S1 + S2) – (S1 * S2)
Интуицията зад формулата е да се съберат двете селективности, след което да се извади оценката за тяхната връзка (като се използва предишната формула). Ясно е, че бихме могли да имаме два предиката, всеки със селективност 0,8, но простото им събиране би довело до невъзможна комбинирана селективност от 1,6. Въпреки допускането за независимост, трябва да признаем, че двата предиката може да се припокриват, така че за да се избегне двойно отчитане, изчислената селективност на връзката се изважда.
Можем лесно да модифицираме нашия пример за изпълнение, за да използваме OR :
ИЗБЕРЕТЕ COUNT_BIG(*)FROM Production.TransactionHistory КАТО THWHERE TH.TransactionID МЕЖДУ 100000 И 168412 ИЛИ TH.TransactionDate МЕЖДУ '20070901' И '20080313';
Заместване на предикатната селективност в OR формулата дава комбинирана селективност от:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Умножена по броя на редовете в таблицата, тази селективност ни дава крайната оценка на кардиналите от 95 568,6 :
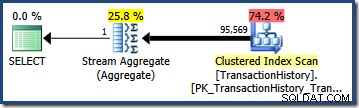
Нито една оценка (41 257 за AND запитване; 95 569 за OR query) е особено добър, тъй като и двете се основават на предположение за моделиране, което не съответства много добре на разпределението на данните. И двете заявки всъщност връщат 68 413 редове (тъй като предикатите идентифицират точно същите редове).
Флаг за проследяване 4137 – Минимална селективност
За SQL Server 2008 (R1) до 2012 г. включително, Microsoft пусна корекция, която променя начина, по който се изчислява селективността за AND само падеж (съединителни предикати). Статията от базата знания в тази връзка не съдържа много подробности, но се оказва, че корекцията променя използваната формула за селективност. Вместо да умножава индивидуалните селективности, оценката на мощността за конюнктивни предикати сега използва само най-ниската селективност.
За да активирате промененото поведение, е необходим поддържан флаг за проследяване 4137. Отделна статия в базата знания документира, че този флаг за проследяване също се поддържа за използване на заявка чрез QUERYTRACEON намек:
ИЗБЕРЕТЕ COUNT_BIG(*)FROM Production.TransactionHistory КАТО THWHERE TH.TransactionID МЕЖДУ 100000 И 168412 И TH.TransactionDate МЕЖДУ '20070901' И '20080313' ONCE (Q4UERY)>);При активен този флаг оценката на мощността използва минималната селективност на двата предиката, което води до оценка от 68 412,4 редове:
Това се оказва почти идеално за нашата заявка, защото нашите тестови предикати са точно корелирани (и оценките, получени от базовите хистограми, също са много добри).
Сравнително рядко е предикатите да бъдат перфектно корелирани по този начин с реални данни, но въпреки това флагът за проследяване може да помогне в някои случаи. Имайте предвид, че поведението на минималната селективност ще се прилага за всички конюнктиви (
AND) предикати в заявката; няма начин да се уточни поведението на по-подробно ниво.Няма съответен флаг за проследяване за оценка на дизюнктивно (
OR) предикати, използващи минимална селективност.SQL Server 2014
Изчисляването на селективността в SQL Server 2014 се държи по същия начин като предишните версии (и флагът за проследяване 4137 работи както преди), ако нивото на съвместимост на базата данни е зададено по-ниско от 120 или ако флагът за проследяване 9481 е активен. Задаването на нивото на съвместимост на базата данни е официално начин за използване на оценката на мощността преди 2014 г. в SQL Server 2014. Флагът за проследяване 9481 е ефективен за извършване на същото нещо, както към момента на писане, а също така работи с
QUERYTRACEON, въпреки че това не е документирано. Няма начин да разберем какво ще бъде RTM поведението на този флаг.Ако новият оценител на мощността е активен, SQL Server 2014 използва различна формула по подразбиране за комбиниране на конюнктивни и дизюнктивни предикати. Макар и недокументирана, формулата за селективност за съюзи е открита и документирана няколко пъти. Първата, която си спомням, че видях, е в тази публикация в блога на португалски език и последващата част втора, издадена няколко седмици по-късно. За да обобщим, подходът от 2014 г. към конюнктивните предикати е да се използва експоненциално отстъпление: дадена таблица с мощност C и селективност на предикатите S1 , S2 , S3 … Sn , където S1 е най-селективен и Sn най-малкото:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …Оценката се изчислява като най-селективния предикат, умножен по мощността на таблицата, умножен по квадратния корен на следващия най-селективен предикат и така нататък с всяка нова селективност, която получава допълнителен квадратен корен.
Като се припомни, че селективността е число между 0 и 1, е ясно, че прилагането на квадратен корен придвижва числото по-близо до 1. Ефектът е да се вземат предвид всички предикати в крайната оценка, но да се намали въздействието на по-малко селективните предикати експоненциално. Може би има повече логика в тази идея, отколкото при предположението за независимост , но все още е фиксирана формула – не се променя въз основа на действителната степен на корелация на данните.
Оценителят на мощността за 2014 г. използва експоненциална формула за отмяна за и двете конюнктивни и дизюнктивни предикати, въпреки че формулата, използвана в дизюнктивното (
OR) случай все още не е документиран (официално или по друг начин).Флагове за проследяване на селективност на SQL Server 2014
Флаг за проследяване 4137 (за използване на минимална селективност) не работи в SQL Server 2014, ако новият оценител на мощността се използва при компилиране на заявка. Вместо това има нов флаг за проследяване 9471 . Когато този флаг е активен, се използва минимална селективност за оценка на множество конюнктивни и дизюнктивни предикати. Това е промяна от поведението 4137, което засяга само конюнктивните предикати.
По същия начин, флаг за проследяване 9472 може да се посочи, за да приеме независимост за множество предикати, както направиха предишните версии. Този флаг е различен от 9481 (за да се използва оценката на мощността преди 2014 г.), тъй като под 9472 новият оценител на мощността все още ще се използва, само формулата за селективност за множество предикати е засегната.
Нито 9471, нито 9472 са документирани към момента на писане (въпреки че може да са в RTM).
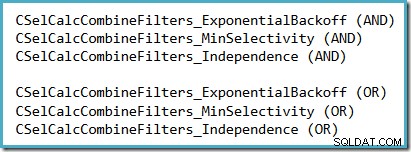
Удобен начин да видите кое предположение за селективност се използва в SQL Server 2014 (с активен новия оценител на мощността) е да проучите изхода за отстраняване на грешки при изчисление на селективността, получен при флагове за проследяване 2363 и3604 са активни. Разделът, който трябва да търсите, се отнася до калкулатора за селективност, който комбинира филтри, където ще видите едно от следните, в зависимост от това кое предположение се използва:
Няма реалистична перспектива 2363 да бъде документиран или подкрепен.
Последни мисли
Няма нищо магическо в експоненциалното отстъпване, минималната селективност или независимостта. Всеки подход представлява (изключително) опростяващо предположение, което може или не може да даде приемливи оценки за всяка конкретна заявка или разпределение на данни.
В някои отношения експоненциално отстъпление представлява компромис между двете крайности на независимостта и минимална селективност . Въпреки това е важно да нямате неоправдани очаквания към него. Докато не бъде намерен по-точен начин за оценка на селективността за множество предикати (с приемливи характеристики на ефективност), остава важно да сте наясно с ограниченията на модела и съответно да внимавате за (потенциални) грешки в оценката.
Различните флагове за проследяване осигуряват известен контрол върху това кое предположение се използва, но ситуацията далеч не е перфектна. От една страна, най-добрата детайлност, при която може да се приложи флаг, е една заявка – поведението на оценката не може да бъде определено на ниво предикат. Ако имате заявка, при която някои предикати са корелирани, а други независими, флаговете за проследяване може да не ви помогнат много, без да преработите заявката по един или друг начин. По същия начин проблемна заявка може да има предикатни корелации, които не са моделирани добре от нито една от наличните опции.
Ad-hoc използването на флаговете за проследяване изисква същите разрешения като
DBCC TRACEON– а именно sysadmin . Това вероятно е добре за лично тестване, но за производство използвайте ръководство за план, като използватеQUERYTRACEONнамек е по-добър вариант. С ръководството за план не се изискват допълнителни разрешения за изпълнение на заявката (въпреки че са необходими повишени разрешения за създаване на ръководството за план, разбира се).