PostgreSQL е една от базите данни, които могат да бъдат разгърнати чрез ClusterControl, заедно с MySQL, MariaDB и MongoDB. ClusterControl не само опростява разгръщането на клъстера на базата данни, но има функция за мащабируемост, в случай че приложението ви се разраства и изисква тази функционалност.
Чрез мащабиране на вашата база данни, вашето приложение ще работи много по-плавно и по-добре в случай, че натоварването на приложението или трафикът се увеличи. В тази публикация в блога ще прегледаме стъпките за това как да направите внедряването, както и мащабирането на PostgreSQL v13 с ClusterControl 1.8.2.
Внедряване на потребителски интерфейс (UI)
Има два начина за внедряване в ClusterControl, уеб потребителски интерфейс (UI), както и интерфейс на командния ред (CLI). Потребителят има свободата да избере всяка от опциите за внедряване в зависимост от своите предпочитания и нужди. И двете опции са лесни за следване и добре документирани в нашата документация. В този раздел ще преминем през процеса на внедряване, използвайки първата опция – уеб потребителски интерфейс.
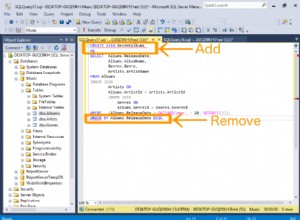
Първата стъпка е да влезете във вашия ClusterControl и да кликнете върху Разгръщане:
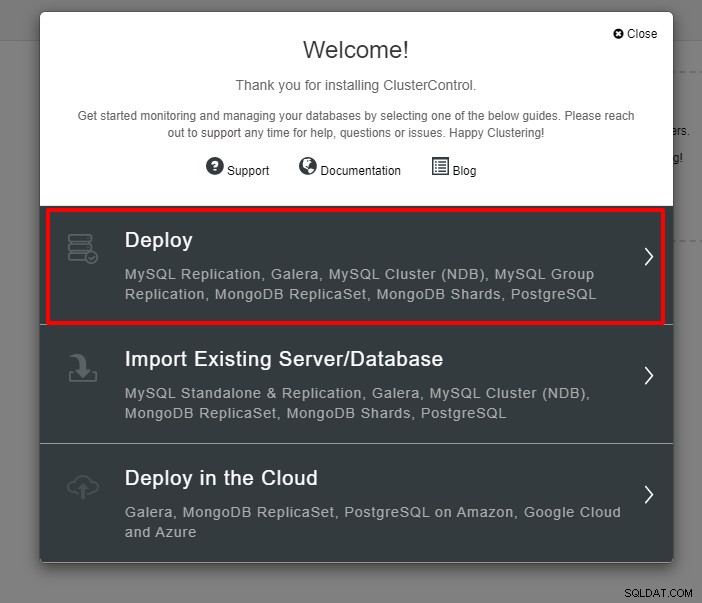
Ще ви бъде представена екранната снимка по-долу за следващата стъпка от внедряването , изберете раздела PostgreSQL, за да продължите:
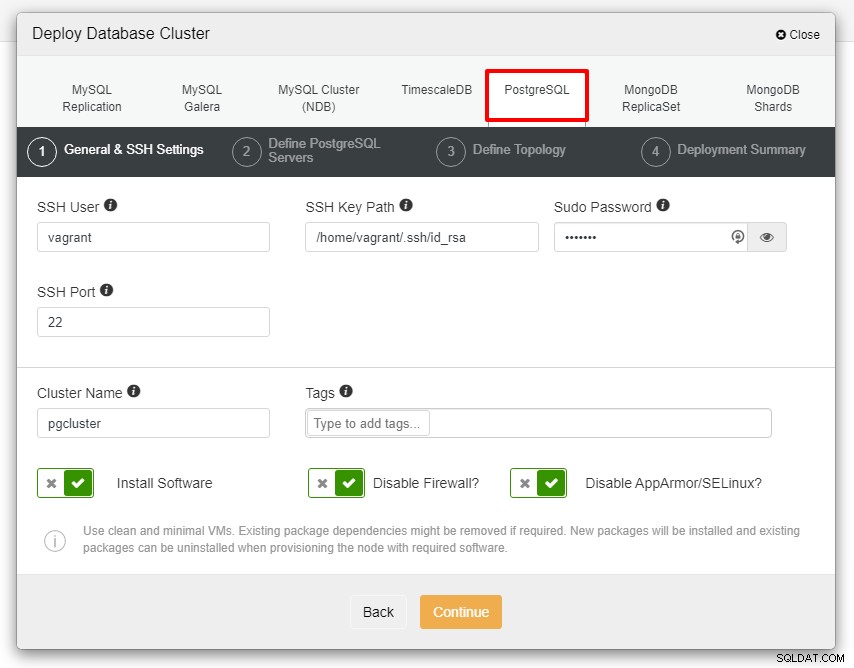
Преди да продължим, бих искал да ви напомня, че връзката между възелът ClusterControl и възлите на базите данни трябва да са без парола. Преди внедряването, всичко, което трябва да направим, е да генерираме ssh-keygen от възела ClusterControl и след това да го копираме във всички възли. Попълнете въвеждането за SSH потребител, парола Sudo, както и име на клъстер според вашето изискване и щракнете върху Продължи.
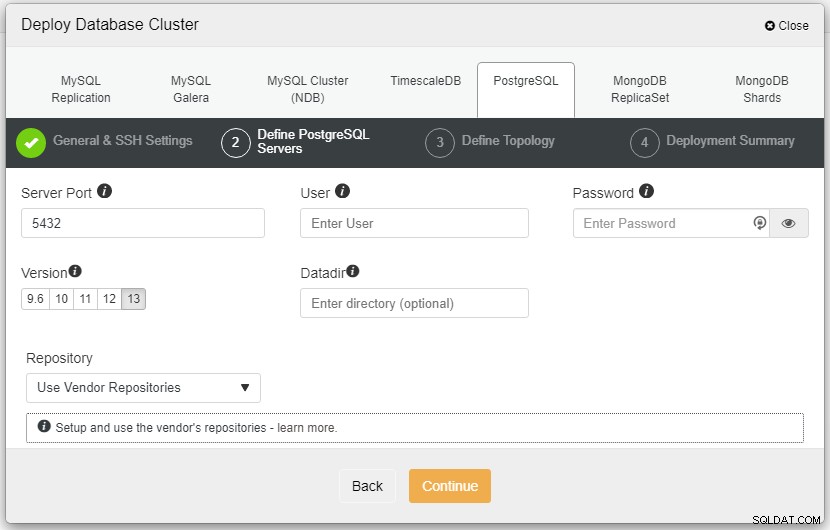
На екранната снимка по-горе ще трябва да дефинирате сървърния порт (в в случай, че искате да използвате други), потребителя, който искате, както и паролата и не забравяйте да изберете версия 13, която искате да инсталирате.
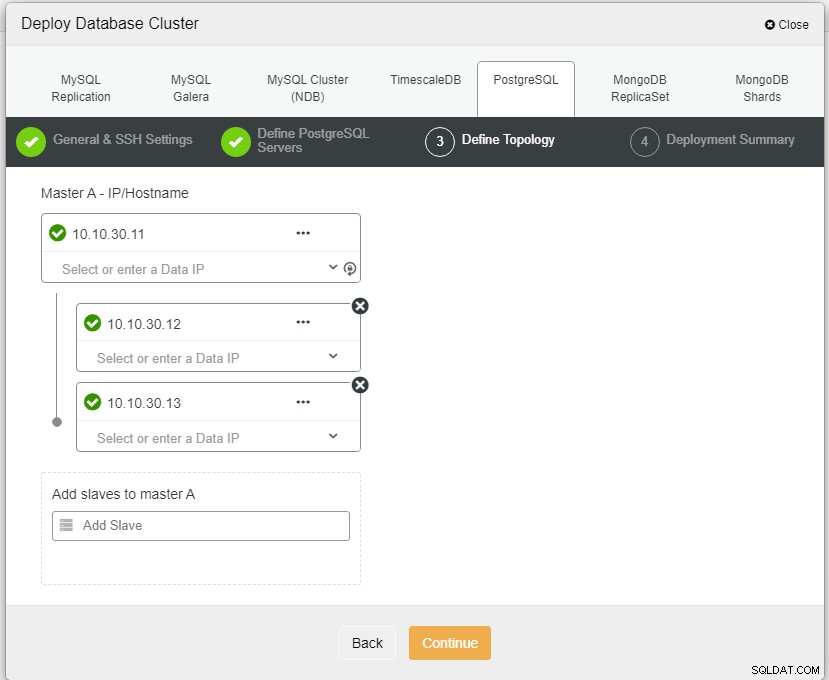 Автор на снимкаОписание на снимка
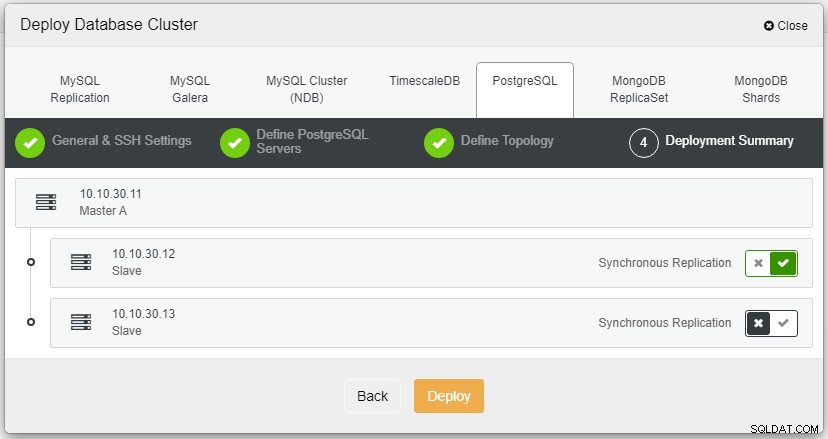
Автор на снимкаОписание на снимкаТук трябва да дефинираме сървърите или чрез името на хоста, или IP адреса, като в този случай 1 главен и 2 подчинени. Последната стъпка е да изберете режима на репликация за нашия клъстер.
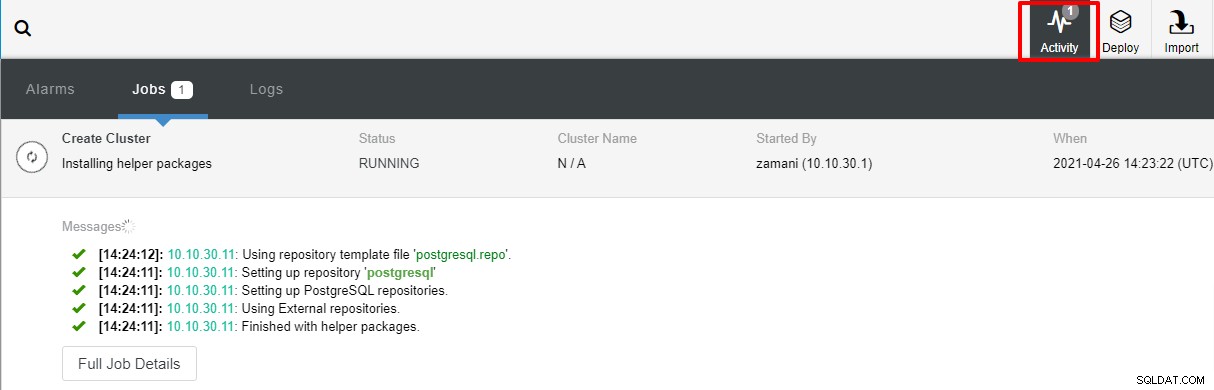
След като щракнете върху Разгръщане, процесът на внедряване ще започне и ние можем да наблюдаваме напредък в раздела Активност.
Разгръщането обикновено ще отнеме няколко минути, производителността зависи най-вече от мрежа и спецификацията на сървъра.

Сега, когато имаме инсталиран PostgreSQL v13 с помощта на ClusterControl GUI, което е доста лесно .
Интерфейс на командния ред (CLI) PostgreSQL Разгръщане
От горното можем да видим, че внедряването е доста лесно с помощта на уеб потребителски интерфейс. Важната забележка е, че всички възли трябва да имат SSH връзки без пароли преди внедряването. В този раздел ще видим как да се внедри с помощта на командния ред на ClusterControl CLI или „s9s“ tools.
Предположихме, че ClusterControl е инсталиран преди това, нека започнем с генерирането на ssh-keygen. В възела ClusterControl изпълнете следните команди:
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3След като всички команди по-горе се изпълнят успешно, можем да проверим връзката без парола, като използваме следната команда:
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordАко горната команда се изпълнява успешно, разполагането на клъстер може да бъде стартирано от сървъра ClusterControl, като се използва следния команден ред:
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logВеднага след като изпълните командата по-горе, ще видите нещо подобно, което означава, че задачата е започнала да се изпълнява:
Клъстерът ще бъде създаден на 3 възела с данни.
Проверка на параметрите на заданието.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.
Можете също да го потвърдите, като влезете в уеб конзолата, като използвате потребителското име, което сте създали. Сега имаме PostgreSQL клъстер, разгърнат с 3 възела. Ако искате да научите повече за командата за разгръщане по-горе, тук е най-добрата справка за вас.
Увеличаване на PostgreSQL с потребителски интерфейс на ClusterControl
PostgreSQL е релационна база данни и знаем, че мащабирането на този тип база данни не е лесно в сравнение с нерелационна база данни. В наши дни повечето приложения се нуждаят от мащабируемост, за да осигурят по-добра производителност и скорост. Има много начини как да го приложите в зависимост от вашата инфраструктура и среда.
Мащабируемостта е една от функциите, които могат да бъдат улеснени от ClusterControl и могат да бъдат постигнати както с потребителски интерфейс, така и с CLI. В този раздел ще видим как можем да мащабираме PostgreSQL с помощта на потребителския интерфейс на ClusterControl. Първата стъпка е да влезете в потребителския си интерфейс и да изберете клъстера, след като клъстерът бъде избран, можете да щракнете върху опцията според екранната снимка по-долу:
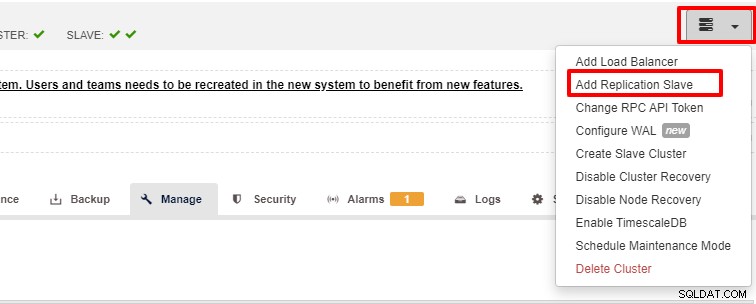
След като щракнете върху „Add Replication Slave“, ще видите следната страница . Можете да изберете „Добавяне на нов…“ или „Импортиране…“ в зависимост от ситуацията. В този пример ще изберем първата опция:
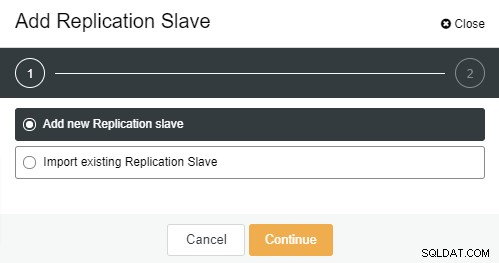
Ще се покаже следният екран, след като щракнете върху него:
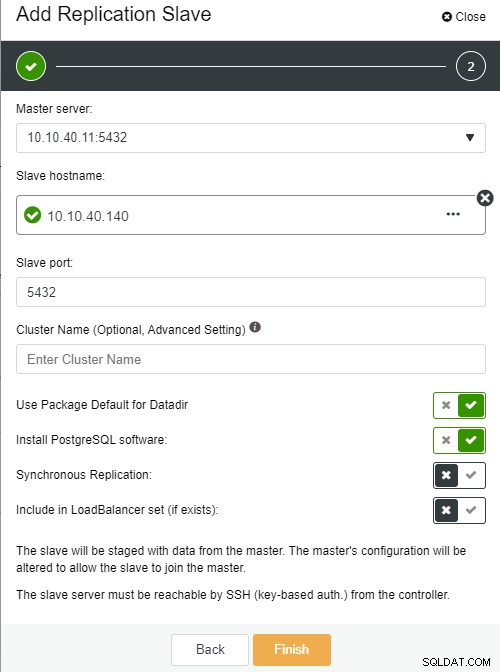 Автор на снимка Описание на снимка
Автор на снимка Описание на снимка-
Име на подчинен хост:името на хоста/IP адреса на новия подчинен или възел
-
Подчинен порт:PostgreSQL портът на подчинения, по подразбиране е 5432
-
Име на клъстер:името на клъстера, можете да добавите или да го оставите празно
-
Използване на пакет по подразбиране за Datadir:можете да поставите отметка в тази опция при премахване на отметката, ако искате да имате различно местоположение за Datadir
-
Инсталиране на софтуера PostgreSQL:можете да оставите тази опция отметната
-
Синхронна репликация:можете да изберете какъв тип репликация искате в тази
-
Включи в комплекта LoadBalancer (ако съществува):тази опция трябва да бъде проверена, ако имате конфигуриран LoadBalancer за клъстера
Основната важна забележка тук е, че трябва да конфигурирате новия подчинен хост да бъде без парола, преди да можете да стартирате тази настройка. След като всичко е потвърдено, можем да щракнем върху бутона „Край“, за да завършим настройката. В този пример добавих IP „10.10.40.140“.
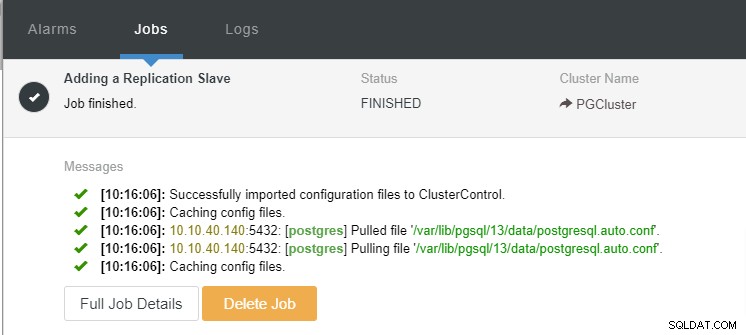
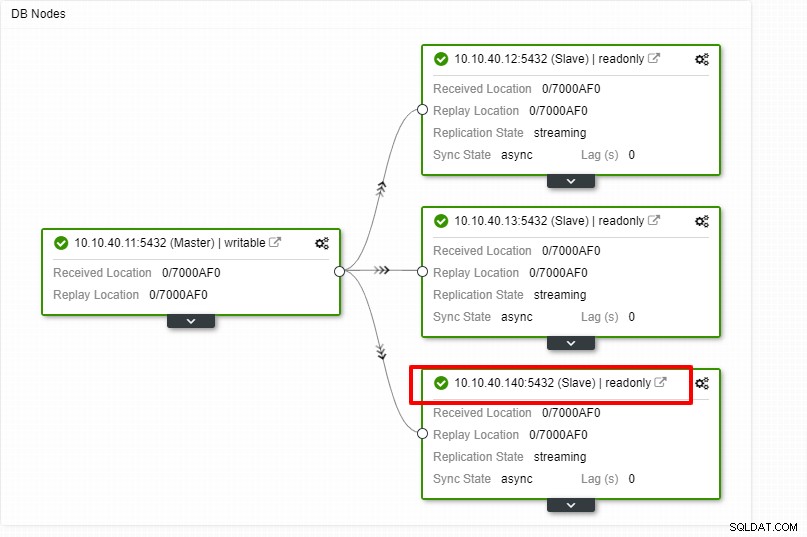
Вече можем да наблюдаваме дейността на заданието и да оставим настройката да завърши. За да потвърдим настройката, можем да отидем в раздела „Топология“, за да видим новия подчинен:
Мащабиране на PostgreSQL с ClusterControl CLI
Добавянето на нови възли в съществуващия клъстер е много лесно с помощта на CLI. От възела на контролера изпълнявате следната команда. Първата команда е да идентифицираме клъстера, към който бихме искали да добавим новия възел:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.В този пример можем да видим, че ID на възел е „1“ за името на клъстера „PGCluster“. Нека да видим първата опция за команда за това как да добавите нов възел към съществуващия PostgreSQL клъстер:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logСъкращението “--log” в края на реда ще ни позволи да видим каква е текущата задача, която се изпълнява след командата, изпълнена, както е посочено по-долу:
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…Следващата налична команда, която можете да използвате, е следната:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitДобавяне на възел към клъстер
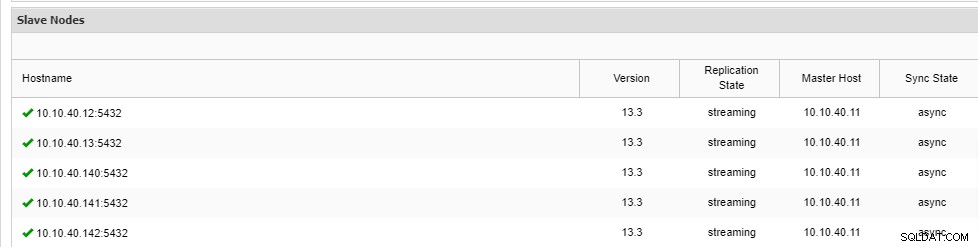
\ Job 9 RUNNING [▋ ] 5% Installing packagesЗабележете, че в реда има съкратено „--wait“ и изходът, който ще видите, ще бъде показан както по-горе. След като процесът завърши, можем да потвърдим новите възли в раздела „Преглед“ на клъстера от потребителския интерфейс:
Заключение
В тази публикация в блога разгледахме две опции за мащабиране на PostgreSQL в ClusterControl. Както може да забележите, мащабирането на PostgreSQL е лесно с ClusterControl. ClusterControl не само може да направи мащабируемост, но също така можете да постигнете настройка за висока наличност за вашия клъстер от база данни. Функции като HAProxy, PgBouncer, както и Keepalived са налични и готови за внедряване за вашия клъстер, когато почувствате нужда от тези опции. С ClusterControl вашият клъстер от база данни е лесен за управление и едновременно наблюдение.
Надяваме се, че тази публикация в блога ще ви помогне да ви насочи в мащабирането на вашата PostgreSQL настройка.