Моят приятел Питър Ларсон ми изпрати предизвикателство за T-SQL, включващо съпоставяне на предлагането с търсенето. Що се отнася до предизвикателствата, то е страхотно. Това е доста често срещана нужда в реалния живот; лесно е за описание и е доста лесно за решаване с разумна производителност, като се използва решение, базирано на курсора. Трудната част е да се реши с помощта на ефективно решение, базирано на набори.
Когато Питър ми изпрати пъзел, аз обикновено отговарям с предложено решение, а той обикновено предлага по-ефективно и блестящо решение. Понякога подозирам, че ми изпраща пъзели, за да се мотивира да измисли страхотно решение.
Тъй като задачата представлява обща потребност и е толкова интересна, попитах Питър дали има нещо против, ако я споделя и неговите решения с читателите на sqlperformance.com и той с удоволствие ми позволи.
Този месец ще представя предизвикателството и класическото решение, базирано на курсора. В следващите статии ще представя решения, базирани на набори, включително тези, върху които работихме с Питър.
Предизвикателството
Предизвикателството включва запитване на таблица, наречена търгове, която създавате с помощта на следния код:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Тази таблица съдържа записи за търсене и предлагане. Записите за търсене са маркирани с код D, а записите за доставки с S. Вашата задача е да съпоставите количествата за предлагане и търсене въз основа на подреждане по ID, като запишете резултата във временна таблица. Вписванията могат да представляват поръчки за покупка и продажба на криптовалута като BTC/USD, поръчки за покупка и продажба на акции като MSFT/USD или всеки друг артикул или стока, където трябва да съпоставите предлагането с търсенето. Забележете, че в записите за търгове липсва атрибут цена. Както бе споменато, трябва да съпоставите количествата за предлагане и търсене въз основа на поръчката по ID. Това подреждане би могло да бъде извлечено от цена (възходяща за вписванията за предлагане и низходяща за вписвания за търсене) или други съответни критерии. В това предизвикателство идеята беше нещата да са прости и да се приеме, че ID вече представлява съответния ред за съвпадение.
Като пример използвайте следния код, за да попълните таблицата за търгове с малък набор от примерни данни:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Трябва да съпоставите количествата на търсенето и предлагането по следния начин:
- Количество от 5,0 се съпоставя за търсене 1 и снабдяване 1000, изчерпвайки търсенето 1 и оставяйки 3,0 от снабдяване 1000
- Количество от 3,0 се съпоставя за Demand 2 и Supply 1000, изчерпвайки както Demand 2, така и Supply 1000.
- Количество от 6,0 се съпоставя за търсене 3 и предлагане 2000, оставяйки 2,0 от търсене 3 и изчерпване на предлагането 2000.
- Количество от 2,0 се съпоставя за Demand 3 и Supply 3000, изчерпвайки както Demand 3, така и Supply 3000
- Количество от 2,0 се съпоставя за Demand 5 и Supply 4000, изчерпвайки както Demand 5, така и Supply 4000
- Количество от 4,0 се съпоставя за търсене 6 и предлагане 5000, оставяйки 4,0 от търсене 6 и изчерпване на предлагане 5000.
- Количество от 3,0 се съпоставя за търсене 6 и предлагане 6000, оставяйки 1,0 от търсене 6 и изчерпване на предлагане 6000
- Количество от 1,0 се съпоставя за търсене 6 и снабдяване 7000, изчерпвайки търсенето 6 и оставяйки 1,0 от снабдяване 7000
- Количество от 1,0 се съпоставя за търсене 7 и предлагане 7000, оставяйки 3,0 от търсене 7 и изчерпване на предлагане 7000; Търсенето 8 не е съпоставено с никакви записи за предлагане и следователно остава с пълното количество 2.0
Вашето решение трябва да запише следните данни в получената временна таблица:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Голям набор от примерни данни
За да тествате производителността на решенията, ще ви е необходим по-голям набор от примерни данни. За да помогнете с това, можете да използвате функцията GetNums, която създавате, като изпълните следния код:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Тази функция връща поредица от цели числа в искания диапазон.
С тази функция можете да използвате следния код, предоставен от Peter, за да попълните таблицата за търгове с примерни данни, като персонализирате входните данни според нуждите:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Както можете да видите, можете да персонализирате броя на купувачите и продавачите, както и минималните и максималните количества купувачи и продавачи. Горният код посочва 200 000 купувачи и 200 000 продавачи, което води до общо 400 000 реда в таблицата за търгове. Последната заявка ви казва колко записа за търсене (D) и предлагане (S) са записани в таблицата. Той връща следния изход за гореспоменатите входове:
Code Items ---- ----------- D 200000 S 200000
Ще тествам производителността на различни решения, използвайки горния код, като задавам броя на купувачите и продавачите всеки на следното:50 000, 100 000, 150 000 и 200 000. Това означава, че ще получа следния общ брой редове в таблицата:100 000, 200 000, 300 000 и 400 000. Разбира се, можете да персонализирате входовете, както желаете, за да тествате производителността на вашите решения.
Решение, базирано на курсора
Питър предостави решението, базирано на курсора. Той е доста основен, което е едно от важните му предимства. Ще се използва като еталон.
Решението използва два курсора:единият за вписвания за търсене, подредени по ID, а другият за записи за предлагане, подредени по ID. За да избегнете пълно сканиране и сортиране на курсор, създайте следния индекс:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Ето пълния код на решението:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Както можете да видите, кодът започва със създаване на временна таблица. След това декларира двата курсора и извлича ред от всеки, като записва текущото количество на търсенето в променливата @DemandQuantity и текущото количество на предлагането в @SupplyQuantity. След това обработва записите в цикъл, докато последното извличане е било успешно. Кодът прилага следната логика в тялото на цикъла:
Ако текущото количество на търсенето е по-малко или равно на текущото количество на предлагането, кодът прави следното:
- Записва ред във временната таблица с текущото сдвояване, като количеството на търсенето (@DemandQuantity) е съответстващо количество
- Изважда текущото количество на търсенето от текущото количество на предлагането (@SupplyQuantity)
- Извлича следващия ред от курсора за търсене
В противен случай кодът прави следното:
- Проверява дали текущото количество на доставката е по-голямо от нула и ако е така, прави следното:
- Записва ред във временната таблица с текущото сдвояване, като количеството на доставката е съответстващо количество
- Изважда текущото количество на предлагането от текущото количество на търсенето
- Извлича следващия ред от курсора за доставка
След като цикълът приключи, няма повече двойки за съвпадение, така че кодът просто почиства ресурсите на курсора.
От гледна точка на производителността, вие получавате типичните режийни разходи за извличане и зацикляне на курсора. От друга страна, това решение прави еднократно подредено преминаване през данните за търсенето и едно подредено преминаване върху данните за предлагането, като всеки използва сканиране за търсене и диапазон в индекса, който сте създали по-рано. Плановете за заявките на курсора са показани на фигура 1.

Фигура 1:Планове за заявки за курсор
Тъй като планът извършва търсене и подредено сканиране на диапазона на всяка от частите (търсене и предлагане) без намеса на сортиране, той има линейно мащабиране. Това беше потвърдено от числата за производителност, които получих при тестването му, както е показано на Фигура 2.
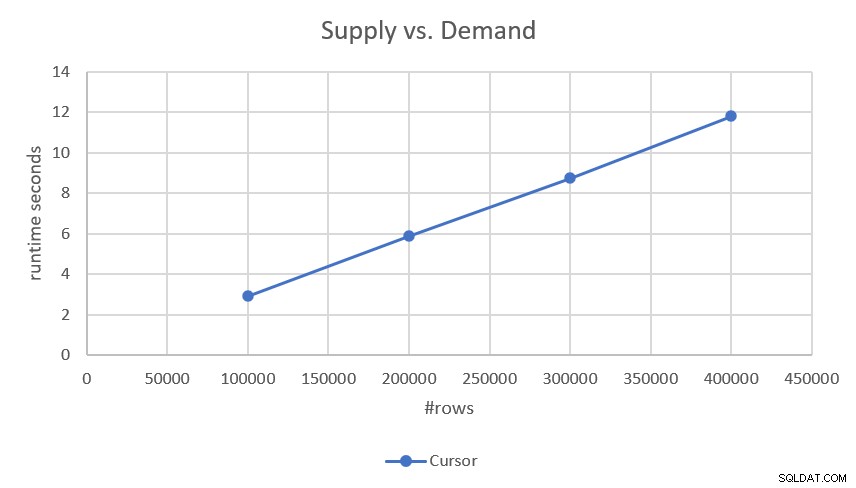
Фигура 2:Производителност на базирано на курсор решение
Ако се интересувате от по-точни времена на изпълнение, ето ги:
- 100 000 реда (50 000 искания и 50 000 доставки):2,93 секунди
- 200 000 реда:5,89 секунди
- 300 000 реда:8,75 секунди
- 400 000 реда:11,81 секунди
Като се има предвид, че решението има линейно мащабиране, можете лесно да предвидите времето за изпълнение с други скали. Например, с един милион реда (да речем, 500 000 заявки и 500 000 доставки) трябва да отнеме около 29,5 секунди, за да се изпълни.
Предизвикателството е включено
Решението, базирано на курсора, има линейно мащабиране и като такова не е лошо. Но това води до типичното извличане на курсора и зацикляне отгоре. Очевидно можете да намалите тези допълнителни разходи, като внедрите същия алгоритъм с помощта на базирано на CLR решение. Въпросът е, можете ли да измислите добре работещо, базирано на набори решение за тази задача?
Както споменахме, ще проучвам решения, базирани на набори – както лошо представящи се, така и добре работещи – от следващия месец. Междувременно, ако се справяте с предизвикателството, вижте дали можете да измислите свои собствени решения, базирани на набори.
За да проверите правилността на вашето решение, първо сравнете неговия резултат с този, показан тук за малкия набор от примерни данни. Можете също да проверите валидността на резултата от вашето решение с голям набор от примерни данни, като проверите, че симетричната разлика между резултата от курсора и вашия е празна. Ако приемем, че резултатът от курсора се съхранява във временна таблица, наречена #PairingsCursor, а вашият във временна таблица, наречена #MyPairings, можете да използвате следния код, за да постигнете това:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
Резултатът трябва да е празен.
Успех!
[ Преминете към решенията:Част 1 | Част 2 | част 3]