В Част 1 и Част 2 от тази поредица разгледах логическите или концептуалните аспекти на изразите на именувани таблици като цяло и конкретно извлечените таблици. Този месец и следващия ще покрия аспектите на физическата обработка на извлечените таблици. Припомнете си от част 1 независимостта на физическите данни принцип на релационната теория. Релационният модел и стандартният език за заявки, който се базира на него, трябва да се занимават само с концептуалните аспекти на данните и да оставят детайлите за физическото изпълнение като съхранение, оптимизация, достъп и обработка на данните на платформата на базата данни (изпълнение ). За разлика от концептуалното третиране на данните, което се основава на математически модел и стандартен език и следователно е много сходно в различните системи за управление на релационни бази данни, физическото третиране на данните не се основава на никакъв стандарт и следователно има тенденция да бъде много специфичен за платформата. В моето отразяване на физическото третиране на изрази на именувани таблици в поредицата се фокусирам върху обработката в Microsoft SQL Server и Azure SQL база данни. Физическото третиране в други платформи за бази данни може да бъде доста различно.
Припомнете си, че това, което задейства тази серия, е известно объркване, което съществува в общността на SQL Server около изразите на именувани таблици. И по отношение на терминологията, и по отношение на оптимизацията. Разгледах някои терминологични съображения в първите две части на поредицата и ще разгледам повече в бъдещи статии, когато обсъждаме CTE, изгледи и вградени TVF. Що се отнася до оптимизирането на изразите на именувани таблици, има объркване около следните елементи (тук споменавам производни таблици, тъй като това е фокусът на тази статия):
- Постоянство: Произведена таблица съхранява ли се някъде? Запазва ли се на диска и как SQL Server обработва паметта за него?
- Проекция на колона: Как работи съпоставянето на индекси с производни таблици? Например, ако извлечена таблица проектира определено подмножество от колони от някаква основна таблица, а най-външната заявка проектира подмножество от колоните от извлечената таблица, SQL Server е достатъчно интелигентен, за да изчисли оптимално индексиране въз основа на окончателното подмножество от колони това всъщност е необходимо? А какво ще кажете за разрешенията; потребителят има ли нужда от разрешения за всички колони, които са посочени във вътрешните заявки, или само за крайните, които са действително необходими?
- Множество препратки към псевдоними на колони: Ако извлечената таблица има колона с резултат, която се основава на недетерминирано изчисление, например извикване на функцията SYSDATETIME, и външната заявка има множество препратки към тази колона, изчислението ще бъде извършено само веднъж или отделно за всяка външна препратка ?
- Отмяна/замяна/включване: SQL Server деактивира ли или вградена заявката за производна таблица? Тоест SQL Server изпълнява ли процес на заместване, при който преобразува оригиналния вложен код в една заявка, която отива директно срещу базовите таблици? И ако е така, има ли начин да се инструктира SQL Server да избегне този процес на разместване?
Това са всички важни въпроси и отговорите на тези въпроси имат значителни последици за производителността, така че е добра идея да имате ясно разбиране за това как тези елементи се обработват в SQL Server. Този месец ще се спра на първите три точки. Има доста какво да се каже за четвъртия елемент, така че следващия месец ще му посветя отделна статия (Част 4).
В моите примери ще използвам примерна база данни, наречена TSQLV5. Можете да намерите скрипта, който създава и попълва TSQLV5 тук, и неговата ER диаграма тук.
Постоянство
Някои хора интуитивно приемат, че SQL Server запазва резултата от частта от израза на таблицата на извлечената таблица (резултатът от вътрешната заявка) в работна таблица. Към датата на това писане това не е така; Въпреки това, тъй като съображенията за постоянство са избор на доставчик, Microsoft може да реши да промени това в бъдеще. Всъщност SQL Server е в състояние да запази междинните резултати от заявката в работни таблици (обикновено в tempdb) като част от обработката на заявката. Ако избере да го направи, вие виждате някаква форма на шпула в плана (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). Въпреки това, изборът на SQL Server дали да пулсира нещо в работна таблица или не в момента няма нищо общо с използването от вас на изрази на именувани таблици в заявката. SQL Server понякога пулсира междинни резултати от съображения за производителност, като например избягване на повтаряща се работа (макар понастоящем несвързана с използването на изрази на именувани таблици), а понякога и по други причини, като например защита за Хелоуин.
Както споменахме, следващия месец ще стигна до подробностите за разместването на извлечени таблици. Засега е достатъчно да се каже, че SQL Server обикновено прилага процес на разместване/вграждане към извлечени таблици, където замества вложените заявки със заявка срещу основните базови таблици. Е, опростявам малко. Не е като SQL Server буквално да преобразува оригиналния низ за заявка на T-SQL с извлечените таблици в нов низ на заявка без тях; по-скоро SQL Server прилага трансформации към вътрешно логическо дърво от оператори и резултатът е, че ефективно извлечените таблици обикновено се отменят. Когато погледнете план за изпълнение на заявка, включваща извлечени таблици, не виждате никакво споменаване за тях, защото за повечето цели на оптимизация те не съществуват. Виждате достъп до физическите структури, които съдържат данните за основните базови таблици (heap, B-tree индекси на rowstore и columnstore индекси за базирани на диск таблици и дървовидни и хеш индекси за оптимизирани за памет таблици).
Има случаи, които пречат на SQL Server да размести извлечена таблица, но дори и в тези случаи SQL Server не запазва резултата от израза на таблицата в работна таблица. Ще предоставя подробностите заедно с примери следващия месец.
Тъй като SQL Server не поддържа извлечени таблици, а взаимодейства директно с физическите структури, които съхраняват данните за основните базови таблици, въпросът относно това как се обработва паметта за производни таблици е спорен. Ако основните базови таблици са базирани на диск, съответните им страници трябва да бъдат обработени в буферния пул. Ако основните таблици са оптимизирани за паметта, съответните им редове в паметта трябва да бъдат обработени. Но това не е по-различно от това, когато правите заявка към основните таблици директно сами, без да използвате производни таблици. Така че тук няма нищо особено. Когато използвате производни таблици, SQL Server не трябва да прилага никакви специални съображения за паметта за тях. За повечето цели на оптимизиране на заявки те не съществуват.
Ако имате случай, в който трябва да запазите резултата от някаква междинна стъпка в работна таблица, трябва да използвате временни таблици или таблични променливи – а не наименувани таблични изрази.
Проекция на колона и дума върху SELECT *
Проекцията е един от оригиналните оператори на релационната алгебра. Да предположим, че имате връзка R1 с атрибути x, y и z. Проекцията на R1 върху някакво подмножество от неговите атрибути, например x и z, е нова релация R2, чието заглавие е подмножеството от проектирани атрибути от R1 (x и z в нашия случай) и чието тяло е набор от кортежи формирана от оригиналната комбинация от прогнозирани стойности на атрибути от кортежи на R1.
Припомнете си, че тялото на релация - като набор от кортежи - по дефиниция няма дубликати. Така че от само себе си се разбира, че кортежите на резултатната връзка са отделната комбинация от стойности на атрибути, проектирани от оригиналната връзка. Не забравяйте обаче, че тялото на таблица в SQL е множество от редове, а не набор и обикновено SQL няма да елиминира дублиращи се редове, освен ако не го инструктирате. Като се има предвид таблица R1 с колони x, y и z, следната заявка може потенциално да върне дублиращи се редове и следователно не следва семантиката на проекционния оператор на релационна алгебра за връщане на набор:
ИЗБЕРЕТЕ x, zFROM R1;
Чрез добавяне на клауза DISTINCT елиминирате дублиращи се редове и по-внимателно следвате семантиката на релационната проекция:
ИЗБЕРЕТЕ РАЗЛИЧЕН x, z ОТ R1;
Разбира се, има някои случаи, в които знаете, че резултатът от вашата заявка има различни редове без нужда от клауза DISTINCT, например, когато подмножество от колоните, които връщате, включва ключ от запитаната таблица. Например, ако x е ключ в R1, горните две заявки са логически еквивалентни.
Във всеки случай, припомнете си въпросите, които споменах по-рано относно оптимизирането на заявки, включващи извлечени таблици и проекция на колони. Как работи съпоставянето на индекси? Ако извлечена таблица проектира определено подмножество от колони от някаква основна таблица, а най-външната заявка проектира подмножество от колоните от получената таблица, SQL Server е достатъчно интелигентен, за да разбере оптимално индексиране въз основа на крайното подмножество от колони, което всъщност е необходимо? А какво ще кажете за разрешенията; потребителят има ли нужда от разрешения за всички колони, които са посочени във вътрешните заявки, или само за крайните, които са действително необходими? Също така да предположим, че заявката за израз на таблица дефинира колона с резултат, която се основава на изчисление, но външната заявка не проектира тази колона. Изчислението оценено ли е изобщо?
Започвайки с последния въпрос, нека опитаме. Помислете за следната заявка:
ИЗПОЛЗВАЙТЕ TSQLV5;GO SELECT custid, city, 1/0 КАТО div0errorFROM Sales.Customers;
Както бихте очаквали, тази заявка се проваля с грешка при деление на нула:
Съобщение 8134, ниво 16, състояние 1Открита е грешка при разделяне на нула.
След това дефинирайте извлечена таблица, наречена D въз основа на горната заявка, а във външната заявка проект D само за custid и city, така:
ИЗБЕРЕТЕ custid, cityFROM ( SELECT custid, city, 1/0 AS div0error FROM Sales.Customers ) AS D;
Както споменахме, SQL Server обикновено прилага разместване/замяна и тъй като в тази заявка няма нищо, което да възпрепятства разместването (повече за това следващия месец), горната заявка е еквивалентна на следната заявка:
ИЗБЕРЕТЕ custid, cityFROM Sales.Customers;
Отново, тук опростявам малко. Реалността е малко по-сложна от тези две заявки, които се считат за наистина идентични, но ще стигна до тези сложности следващия месец. Въпросът е, че изразът 1/0 дори не се показва в плана за изпълнение на заявката и изобщо не се оценява, така че горната заявка се изпълнява успешно без грешки.
Все пак изразът на таблицата трябва да е валиден. Например, помислете за следната заявка:
ИЗБЕРЕТЕ СТРАНА ОТ ( ИЗБЕРЕТЕ * ОТ Продажби. КЛИЕНТИ ГРУПА ПО Държава) КАТО D;
Въпреки че външната заявка проектира само колона от набора за групиране на вътрешната заявка, вътрешната заявка не е валидна, тъй като се опитва да върне колони, които нито са част от групиращия набор, нито се съдържат в агрегатна функция. Тази заявка е неуспешна със следната грешка:
Съобщение 8120, ниво 16, състояние 1Колоната „Sales.Customers.custid“ е невалидна в списъка за избор, тъй като не се съдържа нито в агрегатна функция, нито в клаузата GROUP BY.
След това нека се заемем с въпроса за съвпадението на индекса. Ако външната заявка проектира само подмножество от колоните от извлечената таблица, SQL Server ще бъде ли достатъчно интелигентен, за да направи съпоставяне на индекси въз основа само на върнатите колони (и разбира се всякакви други колони, които играят значима роля в противен случай, като филтриране, групиране и така нататък)? Но преди да се заемем с този въпрос, може да се чудите защо изобщо се занимаваме с него. Защо трябва вътрешната заявка да връща колони, от които външната заявка не се нуждае?
Отговорът е прост, за да съкратите кода, като накарате вътрешната заявка да използва прословутия SELECT *. Всички знаем, че използването на SELECT * е лоша практика, но това е така преди всичко, когато се използва в най-външната заявка. Ами ако направите заявка към таблица с определено заглавие и по-късно това заглавие бъде променено? Приложението може да завърши с грешки. Дори и да не се окажете с грешки, бихте могли да генерирате ненужен мрежов трафик, като връщате колони, от които приложението всъщност не се нуждае. Освен това в такъв случай използвате индексирането по-малко оптимално, тъй като намалявате шансовете за съвпадение на покриващи индекси, които се основават на наистина необходимите колони.
Въпреки това, всъщност се чувствам доста комфортно да използвам SELECT * в табличен израз, знаейки, че така или иначе ще проектирам само наистина необходимите колони в най-външната заявка. От логическа гледна точка това е доста безопасно с някои дребни предупреждения, на които ще стигна скоро. Това е, стига съпоставянето на индекси да се извършва оптимално в такъв случай и добрата новина е така.
За да демонстрирате това, да предположим, че трябва да направите заявка в таблицата Sales.Orders, връщайки трите най-скорошни поръчки за всеки клиент. Планирате да дефинирате производна таблица, наречена D, въз основа на заявка, която изчислява номера на редове (резултатна колона rownum), които са разделени по custid и подредени по дата на поръчка DESC, orderid DESC. Външната заявка ще филтрира от D (релационно ограничение ) само редовете, при които rownum е по-малък или равен на 3 и проект D върху custid, orderdate, orderid и rownum. Сега Sales.Orders има повече колони от тези, които трябва да проектирате, но за краткост искате вътрешната заявка да използва SELECT *, плюс изчисляването на номера на редовете. Това е безопасно и ще бъде обработено оптимално по отношение на съвпадението на индексите.
Използвайте следния код, за да създадете оптимален покриващ индекс, който да поддържа вашата заявка:
СЪЗДАВАЙТЕ ИНДЕКС idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Ето заявката, която архивира текущата задача (ще я наречем заявка 1):
ИЗБЕРЕТЕ custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) КАТО rownum FROM Sales.Orders ) КАТО DWHERE rownum <=3;
Забележете SELECT * на вътрешната заявка и изричния списък с колони на външната заявка.
Планът за тази заявка, както е представен от SentryOne Plan Explorer, е показан на Фигура 1.
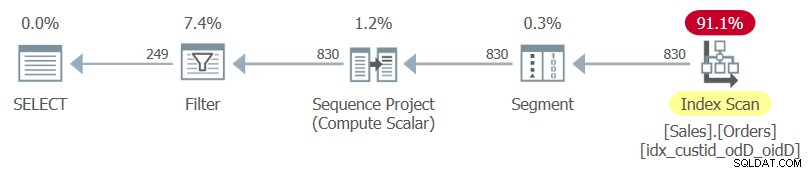 Фигура 1:План за заявка 1
Фигура 1:План за заявка 1
Обърнете внимание, че единственият индекс, използван в този план, е оптималният покриващ индекс, който току-що създадохте.
Ако маркирате само вътрешната заявка и разгледате нейния план за изпълнение, ще видите използвания клъстериран индекс на таблицата, последван от операция за сортиране.
Така че това е добра новина.
Що се отнася до разрешенията, това е различна история. За разлика от съпоставянето на индекси, където не се нуждаете от индекса, за да включва колони, които се препращат от вътрешните заявки, стига в крайна сметка да не са необходими, от вас се изисква да имате разрешения за всички реферирани колони.
За да демонстрирате това, използвайте следния код, за да създадете потребител, наречен user1, и да зададете някои разрешения (ИЗБЕРЕТЕ разрешения за всички колони от Sales.Customers и само за трите колони от Sales.Orders, които в крайна сметка са релевантни в горната заявка):
СЪЗДАВАНЕ НА ПОТРЕБИТЕЛ user1 БЕЗ ВХОД; ПРЕДОСТАВЯТЕ SHOWPLAN НА потребител1; ПРЕДОСТАВЯ ИЗБОР НА Sales.Customers НА user1; ПРЕДОСТАВЯ ИЗБОР НА Sales.Orders(custid, orderdate, orderid) НА потребител1;
Изпълнете следния код, за да се представяте за потребител1:
ИЗПЪЛНИТЕ КАТО ПОТРЕБИТЕЛ ='user1';
Опитайте да изберете всички колони от Sales.Orders:
ИЗБЕРЕТЕ * ОТ Sales.Orders;
Както се очакваше, получавате следните грешки поради липсата на разрешения за някои от колоните:
Msg 230, Level 14, State 1Разрешението SELECT беше отказано в колоната „empid“ на обекта „Orders“, база данни „TSQLV5“, схема „Sales“.
Съобщение 230 , Ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „необходима дата“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „дата на доставка“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, Състояние 1
Разрешението SELECT беше отказано в колоната „shipperid“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „товар“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „име на кораба“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „адрес на кораб“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната 'shipcity' на обекта 'Orders', базата данни 'TSQLV5', схемата 'Sales'.
Съобщение 230, ниво 14, състояние 1
Изберете беше отказано разрешение за колоната „регион на кораб“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната 'shippostalcode' на обекта 'Orders', база данни 'TSQLV5', схема 'Sales'.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT бе отказано на колоната 'shipcountry' на обекта 'Orders', база данни 'TSQLV5', схема 'Sales'.
Опитайте следната заявка, прожектиране и взаимодействие само с колони, за които user1 има разрешения:
ИЗБЕРЕТЕ custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) КАТО rownum FROM Sales.Orders ) КАТО DWHERE rownum <=3;
Все пак получавате грешки в разрешенията за колони поради липсата на разрешения за някои от колоните, които се препращат от вътрешната заявка чрез нейното SELECT *:
Msg 230, Level 14, State 1Разрешението SELECT беше отказано в колоната „empid“ на обекта „Orders“, база данни „TSQLV5“, схема „Sales“.
Съобщение 230 , Ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „необходима дата“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „дата на доставка“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, Състояние 1
Разрешението SELECT беше отказано в колоната „shipperid“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „товар“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „име на кораба“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната „адрес на кораб“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната 'shipcity' на обекта 'Orders', базата данни 'TSQLV5', схемата 'Sales'.
Съобщение 230, ниво 14, състояние 1
Изберете беше отказано разрешение за колоната „регион на кораб“ на обекта „Поръчки“, база данни „TSQLV5“, схема „Продажби“.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT беше отказано в колоната 'shippostalcode' на обекта 'Orders', база данни 'TSQLV5', схема 'Sales'.
Съобщение 230, ниво 14, състояние 1
Разрешението SELECT бе отказано на колоната 'shipcountry' на обекта 'Orders', база данни 'TSQLV5', схема 'Sales'.
Ако наистина във вашата компания е практика да се присвояват разрешения на потребителите само за съответните колони, с които те трябва да взаимодействат, би имало смисъл да използвате малко по-дълъг код и да бъдете изрични относно списъка с колони както във вътрешните, така и във външните заявки, така:
ИЗБЕРЕТЕ custid, orderdate, orderid, rownumFROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE3 rownum;<<=/предварително>Този път заявката се изпълнява без грешки.
Друг вариант, който изисква от потребителя да има разрешения само за съответните колони, е да бъде изрично за имената на колоните в списъка SELECT на вътрешната заявка и да използва SELECT * във външната заявка, както следва:
SELECT *FROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) КАТО rownum FROM Sales.Orders ) КАТО DWHERE rownum <=3;Тази заявка също работи без грешки. Въпреки това, аз виждам тази версия като такава, която е склонна към грешки, в случай че по-късно бъдат направени някои промени в някакво вътрешно ниво на влагане. Както споменахме по-рано, за мен най-добрата практика е да бъдете изрични относно списъка с колони в най-външната заявка. Така че стига да нямате никакви притеснения относно липсата на разрешение за някои от колоните, се чувствам комфортно с SELECT * във вътрешните заявки, но изричен списък с колони в най-външната заявка. Ако прилагането на конкретни разрешения за колони е обичайна практика в компанията, тогава е най-добре просто да бъдете изрични за имената на колони във всички нива на влагане. Имайте предвид, че да бъдете изрични относно имената на колони във всички нива на влагане всъщност е задължително, ако вашата заявка се използва в обект, свързан със схема, тъй като свързването на схемата забранява използването на SELECT * навсякъде в заявката.
В този момент изпълнете следния код, за да премахнете индекса, който сте създали по-рано в Sales.Orders:
ОТПУСКАНЕ НА ИНДЕКС, АКО СЪЩЕСТВУВА idx_custid_odD_oidD НА Sales.Orders;Има и друг случай с подобна дилема относно легитимността на използването на SELECT *; във вътрешната заявка на предиката EXISTS.
Помислете за следната заявка (ще я наречем Заявка 2):
ИЗБЕРЕТЕ custidFROM Sales.Customers КАКТО СЪЩЕСТВУВА CW (ИЗБЕРЕТЕ * ОТ Продажби.Поръчки КАТО КЪДЕТО O.custid =C.custid);Планът за тази заявка е показан на Фигура 2.
Фигура 2:План за заявка 2
Когато прилага съвпадение на индекси, оптимизаторът смята, че индексът idx_nc_custid е покриващ индекс за Sales.Orders, тъй като съдържа колоната custid – единствената истинска подходяща колона в тази заявка. Това е въпреки факта, че този индекс не съдържа друга колона освен custid и че вътрешната заявка в предиката EXISTS казва SELECT *. Досега поведението изглежда подобно на използването на SELECT * в производни таблици.
Различното с тази заявка е, че тя работи без грешки, въпреки факта, че user1 няма разрешения за някои от колоните от Sales.Orders. Има аргумент за оправдание да не се изискват разрешения за всички колони тук. В крайна сметка предикатът EXISTS трябва само да провери наличието на съвпадащи редове, така че списъкът SELECT на вътрешната заявка е наистина безсмислен. Вероятно би било най-добре, ако SQL изобщо не изискваше списък SELECT в такъв случай, но този кораб вече е отплавал. Добрата новина е, че списъкът SELECT ефективно се игнорира – както по отношение на съвпадението на индекси, така и по отношение на необходимите разрешения.
Изглежда също така, че има друга разлика между извлечените таблици и EXISTS при използване на SELECT * във вътрешната заявка. Запомнете тази заявка от по-рано в статията:
ИЗБЕРЕТЕ СТРАНА ОТ ( ИЗБЕРЕТЕ * ОТ Продажби. КЛИЕНТИ ГРУПА ПО Държава) КАТО D;Ако си спомняте, този код генерира грешка, тъй като вътрешната заявка е невалидна.
Опитайте същата вътрешна заявка, само че този път в предиката EXISTS (ще наречем това изявление 3):
АКО СЪЩЕСТВУВА ( ИЗБЕРЕТЕ * ОТ Продажби. КЛИЕНТИ ГРУПА ПО Държава ) ПЕЧАТ 'Това работи! Благодаря Дмитрий Короткевич за съвета!';Странно, SQL Server счита този код за валиден и работи успешно. Планът за този код е показан на Фигура 3.
Фигура 3:План за изявление 3
Този план е идентичен с плана, който бихте получили, ако вътрешната заявка беше просто SELECT * FROM Sales.Customers (без GROUP BY). В крайна сметка вие проверявате за съществуване на групи и ако има редове, естествено има групи. Както и да е, мисля, че фактът, че SQL Server счита тази заявка за валидна, е грешка. Разбира се, SQL кодът трябва да е валиден! Но виждам защо някои биха могли да твърдят, че списъкът SELECT в заявката EXISTS трябва да бъде игнориран. Във всеки случай, планът използва пробно ляво полусъединяване, което не трябва да връща никакви колони, а просто да изследва таблица, за да провери за съществуването на редове. Индексът на Клиенти може да бъде всеки индекс.
В този момент можете да изпълните следния код, за да спрете да се представяте за user1 и да го пуснете:
ВРЪЩАНЕ; ИЗПУСКАНЕ НА ПОТРЕБИТЕЛЯ, АКО СЪЩЕСТВУВА потребител1;Обратно към факта, че намирам за удобна практика да използвате SELECT * във вътрешни нива на влагане, колкото повече нива имате, толкова повече тази практика съкращава и опростява вашия код. Ето пример с две нива на влагане:
ИЗБЕРЕТЕ идентификатор на поръчка, година на поръчка, custid, empid, shipperidFROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear FROM ( SELECT *, YEAR(orderdate) AS order year FROM Sales.Orders ) AS D1 ) AS D2WHERE дата на поръчка =края на годината;Има случаи, когато тази практика не може да се използва. Например, когато вътрешната заявка обединява таблици с общи имена на колони, като в следния пример:
ИЗБЕРЕТЕ custid, companyname, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) КАТО rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Както Sales.Customers, така и Sales.Orders имат колона, наречена custid. Използвате табличен израз, който се основава на свързване между двете таблици, за да дефинирате извлечената таблица D. Не забравяйте, че заглавието на таблицата е набор от колони и като набор не можете да имате дублиращи се имена на колони. Следователно тази заявка е неуспешна със следната грешка:
Съобщение 8156, ниво 16, състояние 1
Колоната „custid“ беше посочена няколко пъти за „D“.Тук трябва да сте изрични относно имената на колони във вътрешната заявка и да се уверите, че или връщате custid само от една от таблиците, или присвоявате уникални имена на колони на колоните с резултати, в случай че искате да върнете и двете. По-често бихте използвали предишния подход, като така:
ИЗБЕРЕТЕ custid, companyname, orderdate, orderid, rownumFROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O. orderid DESC) КАТО rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Отново можете да бъдете изрични с имената на колоните във вътрешната заявка и да използвате SELECT * във външната заявка, както следва:
ИЗБЕРЕТЕ *ОТ ( ИЗБЕРЕТЕ C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) КАТО номер на реда ОТ Продажби .Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Но както споменах по-рано, смятам, че е лоша практика да не се уточняват имената на колоните в най-външната заявка.
Множество препратки към псевдоними на колони
Нека преминем към следващия елемент – множество препратки към колони на извлечени таблици. Ако извлечената таблица има колона с резултат, която се основава на недетерминирано изчисление и външната заявка има множество препратки към тази колона, изчислението ще бъде ли оценено само веднъж или поотделно за всяка препратка?
Нека започнем с факта, че множество препратки към една и съща недетерминистична функция в заявка трябва да се оценяват независимо. Разгледайте следната заявка като пример:
ИЗБЕРЕТЕ NEWID() КАТО mynewid1, NEWID() КАТО mynewid2;Този код генерира следния изход, показващ два различни GUID:
mynewid1 mynewid2 ------------------------------------- --------- ---------------------------7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406Обратно, ако имате извлечена таблица с колона, която се основава на недетерминирано изчисление и външната заявка има множество препратки към тази колона, изчислението трябва да бъде оценено само веднъж. Помислете за следната заявка (ще наречем тази заявка 4):
ИЗБЕРЕТЕ mynewid КАТО mynewid1, mynewid КАТО mynewid2FROM ( ИЗБЕРЕТЕ NEWID() КАТО mynewid ) КАТО D;Планът за тази заявка е показан на Фигура 4.
Фигура 4:План за заявка 4
Обърнете внимание, че има само едно извикване на функцията NEWID в плана. Съответно, изходът показва един и същ GUID два пъти:
mynewid1 mynewid2 ------------------------------------- --------- ---------------------------296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74AТака че, горните две заявки не са логически еквивалентни и има случаи, при които вмъкване/замяна не се извършва.
С някои недетерминирани функции е малко по-трудно да се демонстрира, че множеството извиквания в заявка се обработват отделно. Вземете функцията SYSDATETIME като пример. Има 100 наносекунди точност. Какви са шансовете заявка като следната действително да покаже две различни стойности?
ИЗБЕРЕТЕ SYSDATETIME() КАТО mydt1, SYSDATETIME() КАТО mydt2;Ако ви е скучно, можете да натиснете F5 многократно, докато не се случи. Ако имате по-важни неща за вършене с времето си, може да предпочетете да изпълните цикъл, като така:
ДЕКЛАРИРАНЕ @i КАТО INT =1; ДОКАТО СЪЩЕСТВУВА( ИЗБЕРЕТЕ * ОТ ( ИЗБЕРЕТЕ SYSDATETIME() КАТО mydt1, SYSDATETIME() КАТО mydt2 ) КАТО D КЪДЕ mydt1 =mydt2 ) SET @i +=1; ПЕЧАТ @i;Например, когато изпълних този код, получих 1971.
Ако искате да сте сигурни, че недетерминистичната функция се извиква само веднъж и разчитате на една и съща стойност в множество препратки към заявка, уверете се, че дефинирате израз на таблица с колона въз основа на извикването на функцията и имате множество препратки към тази колона от външната заявка, така (ще наречем тази заявка 5):
ИЗБЕРЕТЕ mydt КАТО mydt1, mydt КАТО mydt1FROM ( ИЗБЕРЕТЕ SYSDATETIME() КАТО mydt ) КАТО D;Планът за тази заявка е показан на Фигура 5.
Figure 5:Plan for Query 5
Notice in the plan that the function is invoked only once.
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT =1; WHILE EXISTS ( SELECT * FROM (SELECT mydt AS mydt1, mydt AS mydt2 FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2 WHERE mydt1 =mydt2 ) SET @i +=1; PRINT @i;You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT CASE WHEN RAND() <0.5 THEN STR(RAND(), 5, 3) + ' is less than half.' ELSE STR(RAND(), 5, 3) + ' is at least half.' END;Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT CASE WHEN rnd <0.5 THEN STR(rnd, 5, 3) + ' is less than half.' ELSE STR(rnd, 5, 3) + ' is at least half.' ENDFROM ( SELECT RAND() AS rnd ) AS D;Резюме
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.