Има няколко начина да се свържете с някого в наши дни, нали?
Имаме различни телефони:мобилни и стационарни, лични и работни. Имаме различни адреси – жилищни, пощенски, фактурни, служебни и т.н. – и вероятно също няколко имейл адреса. Не забравяйте Skype и различни приложения за съобщения. Сега добавете LinkedIn и Facebook – които между другото имат свои собствени елементи за съобщения.
Не толкова отдавна много от тях не съществуваха. Така че можете почти да гарантирате, че след няколко години ще имаме нов начин за контакт с хора и организации.
Можем ли да моделираме цялата тази информация за контакт по такъв начин, че да не се налага да променяме дизайна на нашата база данни, когато дойде „най-новото нещо“? Прочетете, за да разберете...
Моделът за контактна точка за парти
С една дума, да. Базите данни могат да бъдат проектирани така, че да приемат информация, която дори още нямаме.
Ще скоча направо и ще ви покажа решението, след което ще опиша как частите работят заедно. Ще нарека различните начини за свързване на страните точки за контакт , въпреки че съм виждал методи за контакт и дори места за контакт използван.
Физически всички тези точки за контакт ще се съхраняват в една колона на таблицата, contact_point.contact_value . Помислете за телефонен номер, имейл адрес или уеб адрес (URL) и ще разберете защо можем да ги съхраняваме всички тук; те са просто низове (varchars) на това ниво. Диференциацията е в метаданните. Единственото изключение от това е пощенският адрес, който ще бъде описан по-подробно по-късно.
Жълтите таблици вляво съдържат метаданни, а сините таблици вдясно съдържат бизнес данни.
Основните категории
Въпреки че имаме много начини да се свържем с някого, тези начини всъщност попадат в малък брой категории или типове. Ще разберете какво имам предвид, когато погледнете списъка по-долу:
| Тип точка за контакт |
|---|
| Телефонен номер (стационарен) |
| Мобилен номер |
| Номер на факс |
| Имейл адрес |
| Пощенски адрес |
| Уеб адрес |
| Пейджър |
В известен смисъл те са физически различни. Разбира се, можете да използвате мобилен телефон, за да се обадите на стационарен или друг мобилен телефон. Когато става въпрос за гласови разговори между стационарни и мобилни телефони, разликата не е толкова важна. Все пак е по-вероятно да изпратим текстови съобщения (SMS) на мобилен телефон, отколкото на стационарен телефон.
Но е малко вероятно умишлено да се обадите на факс номер. В края на краищата, какво ще му кажете, когато го чуете, освен „Упс, грешен номер“? Естествено е много по-вероятно да се обадите с друг факс апарат, независимо дали е физически или емулиран. Нито бихте изпратили писмо до стационарен телефон, нито бихте се опитали да осъществите гласово обаждане до пощенски адрес.
Важно е да разграничим тези типове, защото взаимодействаме по различен начин с тях. Това ще бъде особено вярно, ако приложението ви има някаква интеграция с комуникационни услуги. Трябва да знае с кой тип да взаимодейства.
Как страните използват точки за контакт
Това вероятно е малко по-интуитивно, малко повече в съответствие с начина, по който мислим за видовете контакти. Ето по-дълъг списък (но не изчерпателен!), който ще ви помогне да усетите тези типове:
| Тип контакт на страната (Тип на точка за контакт) |
|---|
| Конферентна линия (телефонен номер) |
| Адрес за фактуриране (пощенски адрес) |
| Адрес за доставка (пощенски адрес) |
| Директна линия (телефонен номер) |
| Адрес за почивка/ваканция (пощенски адрес) |
| Телефон за празници/ваканция (телефонен номер) |
| Домашен адрес (пощенски адрес) |
| Домашен телефон (телефонен номер) |
| Домашен телефон/факс (телефонен номер) |
| Профил на LinkedIn (уеб адрес) |
| Основен адрес (пощенски адрес) |
| Основен имейл (имейл адрес) |
| Основен факс (номер на факс) |
| Основен телефон (телефонен номер) |
| Основен уебсайт (уеб адрес) |
| Личен имейл (имейл адрес) |
| Личен факс (номер на факс) |
| Личен мобилен (мобилен номер) |
| Личен пейджър (пейджър) |
| Личен уебсайт (уеб адрес) |
| Вторичен адрес (пощенски адрес) |
| Вторичен телефон (телефонен номер) |
| Профил в социалните медии (уеб адрес) |
| Работен адрес (пощенски адрес) |
| Служебен имейл (имейл адрес) |
| Работен факс (номер на факс) |
| Служебен мобилен (мобилен номер) |
| Служебен телефон (телефонен номер) |
Пощенският адрес – специален случай
Всички тези типове точки за контакт се съхраняват в едно поле, с изключение на пощенски адрес. Това обикновено изисква определен брой редове (или полета).
Тук има статия в блог, която предлага прост, независим от езика начин за съхраняване на пощенски адреси. Ако вашите изисквания са по-скоро основни – напр. да отпечатвате адресни етикети почти така, както са въведени в системата – този подход вероятно ще бъде достатъчен. Ако нуждите ви са по-сложни, вероятно ще трябва да разработите различно решение.
За да получите представа колко сложно може да бъде адресирането, разгледайте набързо тази схема за типове адреси на британския стандарт BS7666. Стандартът включва редица части, обхващащи улични справочници, регистри за земя и имоти и точки за доставка. Не се прави разлика между търговски или жилищни имоти; между заета, застроена или свободна земя; между градски или селски райони; или между субекти с пощенски адрес и субект без пощенски адрес и като комуникационни мачти (кули). За да постигне това, той въвежда термини, с които повечето от нас вероятно не са запознати, като първичен адресируем обект (PAO), което е името, дадено на адресируем обект, който може да бъде адресиран без препратка към друг адресируем обект. Познатите примери за PAO включват име на сграда или номер на улица. Вторичен адресируем обект (SAO) се дава на всеки адресируем обект, който е адресиран чрез препратка към PAO. Това може да е първият етаж на сграда с име.
За да ни дам визуализация на това, бързо го преобразувах в UML инструмент за моделиране. Ето какво получаваме:
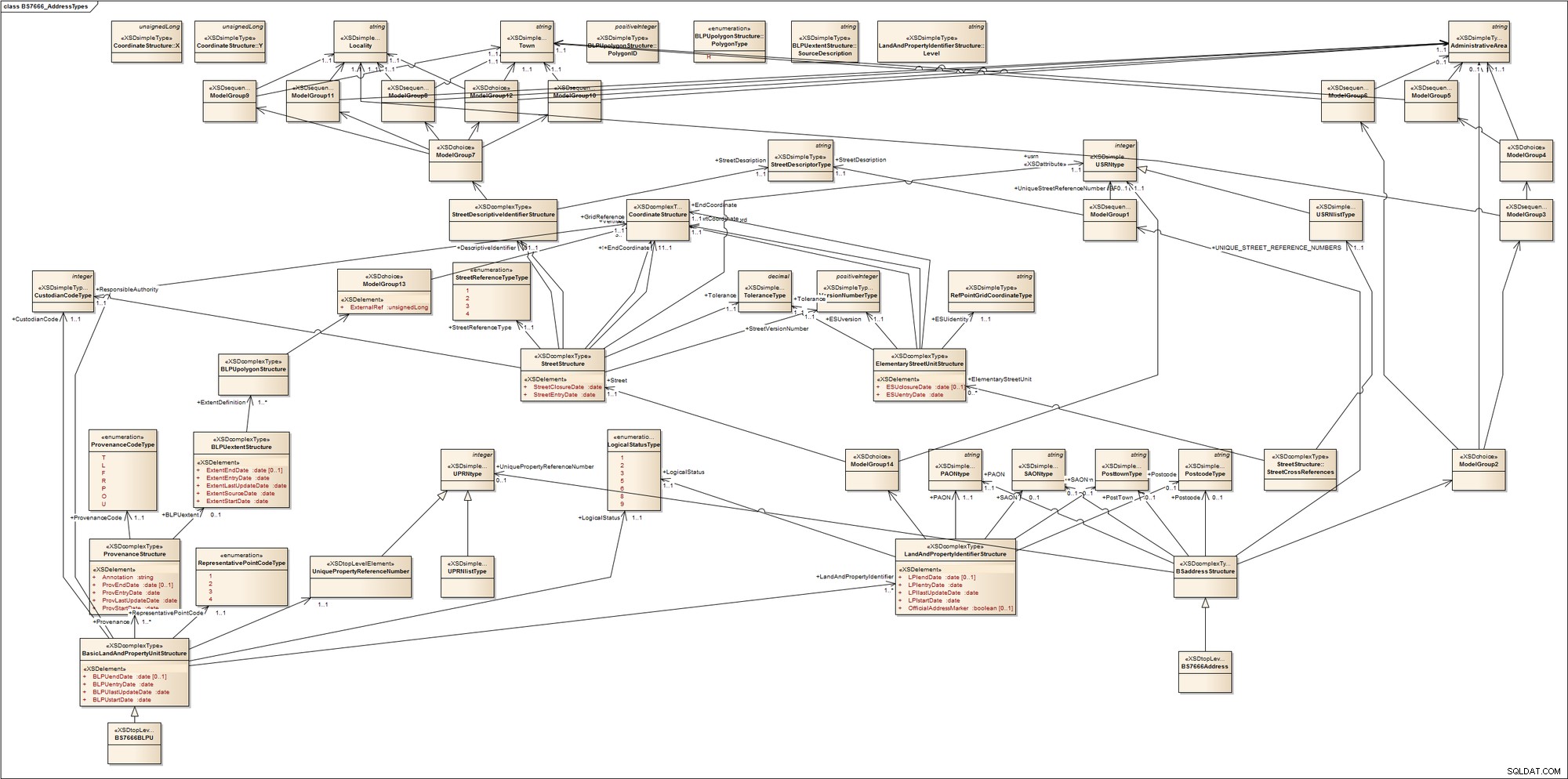
Моето мнение е, че може да стане доста сложно и объркано; адресирането в някои домейни може да бъде наистина много сложно.
Ако трябва да изравните това в една релационна таблица, ще получите нещо като следното:
Въпреки че това улавя компонентите на адреса BS7666, това не ви казва как работи моделът. Цялата релационна логика на XML схемата се скрива в логиката на приложението.
Тези две диаграми представляват две крайности за моделиране на данни . Но има ли среден начин за моделиране на адреси?
Наистина е възможно да имате сравнително прост модел на адрес, който е гъвкав и конфигурируем.
Компоненти на адреса
Компонентът за адрес обикновено е ред върху адресен етикет или по-скоро тип ред на етикет с адрес. Компонентите, които обикновено използваме за адреси в Обединеното кралство, са изброени в следната таблица:
| Тип на компонента на адреса |
|---|
| Адресат |
| Площ |
| Име на сграда |
| Номер на сграда |
| Държава |
| Окръг |
| Име на отдел |
| Зависимо населено място |
| Име на зависима пътна артерия |
| Двойно зависимо населено място |
| Международен пощенски код |
| Ниво |
| Местоположение |
| SSC за сортиране на пощата |
| Име на организация |
| Краен номер на PAO |
| Краен суфикс на PAO |
| Начален номер на PAO |
| Начален суфикс на PAO |
| PAO текст |
| Пощенска кутия |
| Пощенски код |
| Пощенски град |
| Пощенски код |
| Тип пощенски код |
| Краен номер на SAO |
| Краен суфикс на SAO |
| Начален номер на SAO |
| Начален суфикс на SAO |
| Текст на SAO |
| Улица |
| Описание на улицата |
| Име на подсграда |
| Име на пътната артерия |
| Град |
Може да имате три или четири реда за адрес, плюс пощенския град и пощенския код. Трудността обаче, която ще срещнете, е да идентифицирате какво всъщност съдържат тези редове когато има значение – напр. при картографиране на данни между системи. Когато извършвате профилиране на данни, ще откриете, че адресен ред 3 понякога съдържа зависимо населено място, но в други случаи съдържа окръг или населено място. Сега се занимавате с обработка на естествен език (NLP); трябва да разпознаете разликата между населено място и окръг. И пермутациите се умножават, когато добавяте още държави.
Така че трябва да дефинираме всички компоненти на адреса за всички държави, в които работим.
Формати на адреси
Адресните формати се състоят от две части:заглавка и нейните подробности. Заглавката е основно името или заглавието, което форматът на адреса е известен от. Примерите могат да включват:
| Тип формат на адреса |
|---|
| Общ 3-ред |
| Общ 5-ред |
| Пощенска служба на британските сили (BFPO) |
| Международен |
| Пощенски адрес (PAF) |
| САЩ Адрес |
| Френски адрес |
Вземайки за пример пълния формат на адреса на пощенската служба (PAF) на Обединеното кралство, след това дефинираме следните компоненти на адресния формат:
| Формат | Компонент | Последователност | Задължително ли е? |
|---|---|---|---|
| PAF | Адресат | 1 | N |
| PAF | Име на организация | 2 | N |
| PAF | Име на отдел | 3 | N |
| PAF | Пощенска кутия | 4 | N |
| PAF | Име на сграда | 5 | N |
| PAF | Име на подсграда | 6 | N |
| PAF | Номер на сграда | 7 | N |
| PAF | Пътна пътна артерия | 8 | N |
| PAF | Улица | 9 | N |
| PAF | Двойно зависимо населено място | 10 | N |
| PAF | Зависимо населено място | 11 | N |
| PAF | Пощенски град | 12 | Y |
| PAF | Пощенски код | 13 | Y |
Нашето приложение чете тези метаданни и показва компонентите на адреса в правилния ред. Когато се изисква улавяне на адрес, метаданните ни казват дали компонентът на адреса е задължителен или не.
По-често нашето приложение изисква пощенския код от крайния потребител и търси съответните стойности и автоматично попълва адресните компоненти. Някои приложения позволяват на потребителя да редактира адреса; други [досадни] не го правят!
Не се показва в PDM, но ако вашата организация работи в международен план, можете да дефинирате връзка много към много между address_format_type и country така че правилният формат на адреса (въз основа на държавата на потребителя) да бъде представен на крайния потребител (party ).
Когато и само когато contact_point е пощенски адрес contact_point_type , трябва да има връзка с тип_формат_адрес. Обратно, от това следва, че типовете непощенски адреси никога имат връзка с address_format_type . Освен това, форматът трябва да остане фиксиран за целия живот на contact_point , в противен случай ще въведете възможността за проблеми с целостта на данните. (За да не е така , целевият address_format_components трябва да бъде подмножество на изходния address_format_components ).
Колоната contact_value няма значение за пощенски адрес, тъй като стойностите се съхраняват в ddress_line.line_content . Обратно, contact_value е задължителен за всички останали contact_point_types . По принцип contact_point.contact_value и address_line.line_content се изключват взаимно.
Връзката много към много между страна и точка за контакт
Можете да помислите за contact_point (плюс address_line ) като съдържащ стойностите и party_contact като определяне на употребата. Това позволява една contact_point да имамногократно използване . Нашият домашен [пощенски] адрес също може да бъде нашият адрес за фактуриране и адрес за доставка, в зависимост от контекста.
Досега разказът приема, че дадена страна притежава определена contact_point . Но моделът на данни не налага това правило за собственост! То не прави такова ограничение. Има и друга възможност, която съществува с този дизайн:множество страни за едни и същи точки за контакт.
Трябва внимателно да обмислите последиците, преди да тръгнете по този път.
Ето един пример. В Обединеното кралство организациите за награждаване (AO) обикновено наемат учители като проверяващи. Учителят има две взаимоотношения:една с училището, където работи, и друга с AO като проверяващ. Училището ще има банка от contact_points с различни телефонни номера и евентуално един или повече пощенски адреса. Това ще бъдат неща като основния адрес на училището (пощенски адрес), главен имейл (имейл адрес), основен факс (номер на факс) и основен телефон (телефонен номер).
Напълно възможно е нашият проверяващ да използва същите contact_points като негово или нейно училище, но той или тя ще използва party_contact да ги определим като свързани с работата. Ако основният телефонен номер на училището се промени, работният номер на учителя ще бъде актуализиран автоматично, което е доста добре.
Ако тръгнете по този път, ще трябва да дефинирате на ниво приложение на коя страна или страни е разрешено да актуализират contact_points .
Бърза дума за производителността
Жълтите таблици с метаданни ще бъдат постоянно използвани от заявки. Следователно те вероятно ще останат в паметта. В повечето RDBMS можете да закачите таблици в паметта, за да гарантирате това. В Oracle бих ги създал като индексно организирани таблици, които са малки и се представят добре. Правете каквото е еквивалентът за вашата RDBMS.
Също така искате да се уверите, че party_contact редовете са разположени съвместно в един и същ блок (или страница) с помощта на клъстериран индекс на party_id . Направете същото с address_line.contact_point_id . Това намалява количеството IO.
Съществува и друга опция, ако искате party да притежавате изключително contact_point . След това можете да обедините contact_point в party_contact за създаване на party_contact_point (все още групирани на party_id ). Това опростява модела и може да подпомогне производителността.
Промяната на контакти не означава промяна на бази данни
Живеем във време, когато може да се каже, че промяната е единствената константа.
Това не означава, че всеки път, когато нещо се промени, това трябва да повлияе на вашата база данни. С малко мисъл можем да докажем своите проекти в бъдеще – може би повече, отколкото сме правили досега. Това ни помага да реагираме бързо на неизбежната промяна.
Ако се захващате с проект на зелено, бих препоръчал да използвате модела на партито (от който е част от точката за контакт) за организации и хора. Защо не отворите модела и не го настроите според вашите нужди? Моля, не се колебайте да вземете копие и да го направите свое.
Но ако вашата база данни или бази данни вече са определени, схемата, която представих тук, все още може да се използва в XML форма за дефиниране на вашия полезен товар при интегриране на данни между системи.



