Миналата година Анди Малън публикува блог за увеличаване на колона от int към bigint без престой. (Защо това не е операция само с метаданни в съвременните версии на SQL Server е извън мен, но това е друга публикация.)
Обикновено, когато се занимаваме с този проблем, те са широки и масивни таблици (както по брой редове, така и по размер), а колоната, която трябва да променим, е единствената/водещата колона в ключа за клъстериране. Обикновено има и други усложнения – ограничения за входящи външни ключове, много неклъстерирани индекси и натоварена база данни, която е свръхчувствителна към активността на регистрационните файлове (защото участва в проследяването на промените, репликацията, групите за наличност или и трите ).
Поради тази причина трябва да възприемем подход като Анди, който очерта, при който изграждаме сенчеста таблица с новата схема, създаваме тригери, за да поддържаме и двете копия в синхронизиране, и след това пакетираме/запълваме със собствено темпо на този екип, докато не са готови за размяна в копието като истинската сделка.
Но аз съм мързелив!
Има някои случаи, когато можете да промените колоната директно, ако можете да си позволите малък прозорец на престой/блокиране, и това става много по-проста операция. Миналата седмица се появи един такъв случай с таблица над 1TB, но само 100K реда. Почти всички данни бяха извън ред (LOB), те можеха да си позволят малък период на престой, ако е необходимо, и планираха да деактивират проследяването на промените и да го конфигурират отново. Уверен, че повторното създаване на клъстерирания PK няма да трябва да докосва LOB данните (много), предложих, че това може да е случай, в който можем просто да приложим промяната директно.
В изолиран сценарий (без входящи външни ключове, без допълнителни индекси, без дейности, зависещи от четеца на регистрационни файлове и без притеснения относно паралелността), събрах заедно някои тестове, за да видя във вакуум какво ще изисква тази промяна по отношение на продължителността и въздействие върху регистъра на транзакциите. Основният въпрос, на който не знаех как да отговоря предварително, беше:„Каква е допълнителната цена за актуализиране на таблици на място, когато има големи количества неключови данни?“
Ще се опитам да събера много неща в един пост тук. Направих много тестове и всичко е свързано, дори ако не всички тестови сценарии се отнасят за вас. Моля, търпете.
Таблиците
Създадох 6 таблици, включително само базова линия имаше ключовата колона, една таблица с 4K, съхранявани в ред, и след това четири таблици, всяка с колона varchar(max), попълнена с различни количества низови данни (4K, 16K, 64K и 256K).
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.withJustId( id int НЕ НУЛВО, ОГРАНИЧЕНИЕ pk_withJustId ПЪРВИЧЕН КЛУСТЕР (ID)); CREATE TABLE dbo.withoutLob( id int NOT NULL, extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withoutLob ПЪРВИЧЕН КЛУСТРИРАН (id)); CREATE TABLE dbo.withLob004( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)), ОГРАНИЧЕНИЕ pk_withLob004 ПЪРВИЧЕН КЛУСТЕР (ID)); CREATE TABLE dbo.withLob016( id int НЕ НУЛЕН, extradata varchar(max) НЕ NULL ПО ПОДРАЗБИРАНЕ (REPLICATE(CONVERT(varchar(max),'x'), 16000)), ОГРАНИЧЕНИЕ pk_withLob016 ПЪРВИЧЕН КЛУСТЕР (ID)); СЪЗДАВАНЕ НА ТАБЛИЦА dbo.withLob064 ( id int НЕ НУЛЕН, extradata varchar(max) НЕ NULL ПО ПОДРАЗБИРАНЕ (REPLICATE(CONVERT(varchar(max),'x'), 64000)), ОГРАНИЧЕНИЕ pk_withLob064 ПЪРВИЧЕН КЛУСТЕР (ID)); СЪЗДАВАНЕ НА ТАБЛИЦА dbo.withLob256 ( id int НЕ НУЛЕН, extradata varchar(max) НЕ НУЛИ ПО ПОДРАЗБИРАНЕ (REPLICATE(CONVERT(varchar(max),'x'), 256000)), ОГРАНИЧЕНИЕ pk_withLob256 PRIMARY KEY CLUSTERED (CLUSTERED) предварително>
Попълних всеки със 100 000 реда:
INSERT dbo.withJustId (id) SELECT TOP (100000) id =ROW_NUMBER() НАД (ПОРЪЧАЙТЕ ПО c1.name) ОТ sys.all_columns КАТО c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) ИЗБЕРЕТЕ идентификатор ОТ dbo.withJustId;INSERT dbo.withLob004 (id) SELECT id ОТ dbo.withJustId;INSERT dbo.withLob016 (id) SELECT id ОТ dbo.withJustLob004 (id) SELECT id FROM dbo.withJustId; id ОТ dbo.withJustId;INSERT dbo.withLob256 (id) ИЗБЕРЕТЕ идентификатор ОТ dbo.withJustId;
Признавам, че горното е нереалистично; колко често имаме таблица, която е само идентификатор + LOB данни? Проведох тестовете отново с тези допълнителни четири колони, за да дам на страниците с данни, които не са LOB, малко повече реалност:
fill1 char(320) NOT NULL DEFAULT ('x'), count1 int NOT NULL DEFAULT (0), count2 int НЕ NULL DEFAULT (0), dt datetime2 НЕ NULL DEFAULT sysutcdatetime(),
Тези таблици са само малко по-големи по отношение на общия размер, но пропорционалното увеличение на количеството не-LOB данни (не е илюстрирано в тази диаграма) е голямата, но скрита разлика:
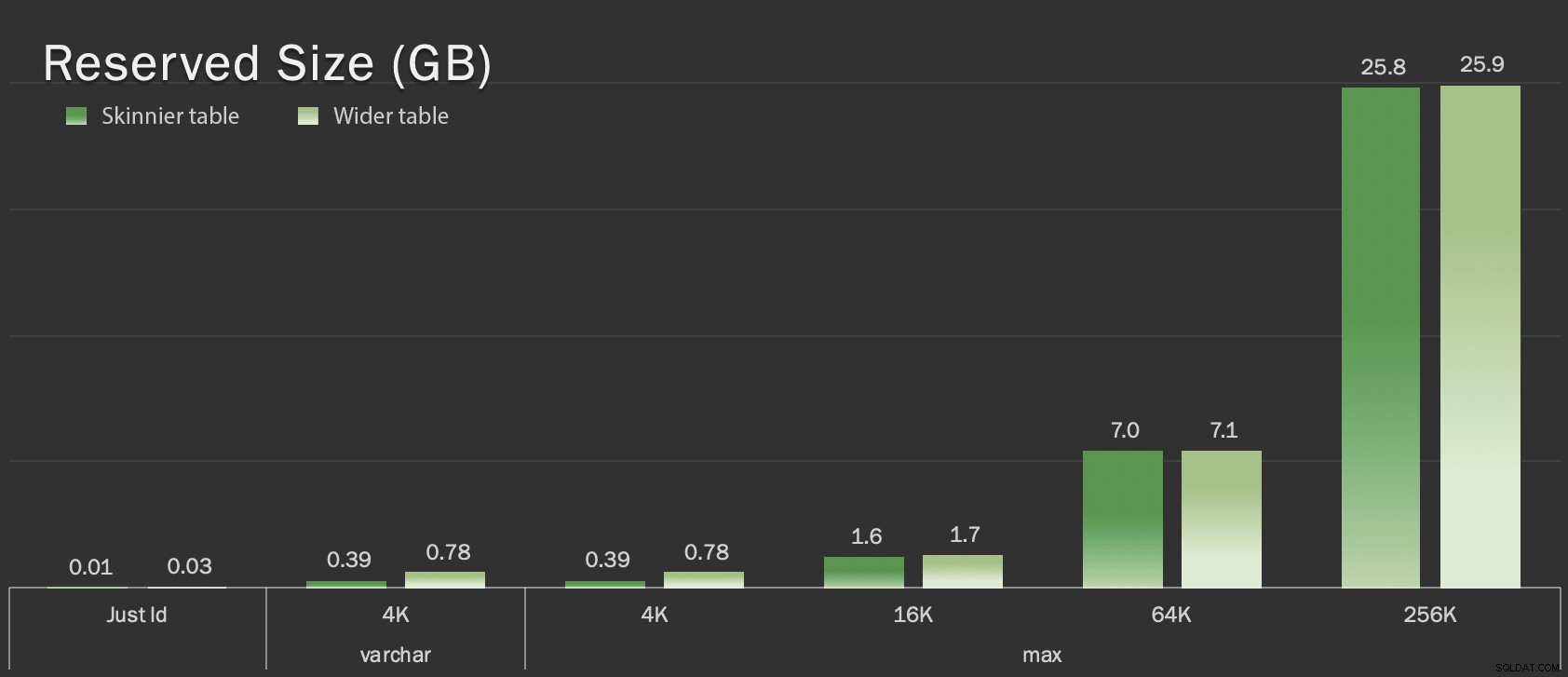 Запазен размер на таблиците, в GB
Запазен размер на таблиците, в GB
Тестовете
След това определих времето и събрах регистрационни данни за всяка от тези операции (със и без ONLINE = ON ) срещу всяка вариация на таблицата:
ALTER TABLE dbo.<име> DROP CONSTRAINT pk_<име>; ALTER TABLE dbo.<име> ALTER COLUMN id bigint NOT NULL; -- С (ОНЛАЙН =ВКЛЮЧЕНО); ALTER TABLE dbo. ДОБАВЯНЕ НА ОГРАНИЧЕНИЕ pk_ КЛУСТРИРАН ПЪРВИЧЕН КЛЮЧ (id);
В действителност използвах динамичен SQL, за да генерирам всички тези тестове, така че да не се занимавах ръчно със скриптове преди всеки тест.
В друга публикация ще споделя динамичния SQL, който използвах за генериране на тези тестове, и ще събирам времето на всяка стъпка.
За сравнение, тествах и метода на Анди (макар и без пакетиране и само на тънката версия на таблицата):
CREATE TABLE dbo._copy ( id bigint NOT NULL -- <, колона с допълнителни данни, когато е уместно> ОГРАНИЧЕНИЕ pk_copy_<име> ПЪРВИЧЕН КЛУСТРИРАН (ID)); INSERT dbo.<име>_copy SELECT * FROM dbo.<име>; EXEC sys.sp_rename N'dbo.<име>', N'dbo.<име>_old', N'OBJECT';EXEC sys.sp_rename N'dbo.<име>_copy', N'dbo.<име>' , N'OBJECT';
Пропуснах по-широките маси тук; Не исках да въвеждам сложността на кодирането и измерването на пакетни операции. Очевидната болка тук е, че за разлика от промяната на колоната на място, с метода на сянка трябва да копирате всеки един байт от тези LOB данни. Групирането може да сведе до минимум голямото въздействие от опитите да направите това в една транзакция, но цялото това разбъркване в крайна сметка ще трябва да бъде преработено надолу по веригата. Групирането в източника не може напълно да контролира колко много ще навреди на местоназначението.
Резултатите
Първите резултати, които ще покажа, са само средната продължителност на промените на място, за всички 12 конфигурации на таблицата и със и без ONLINE = ON :
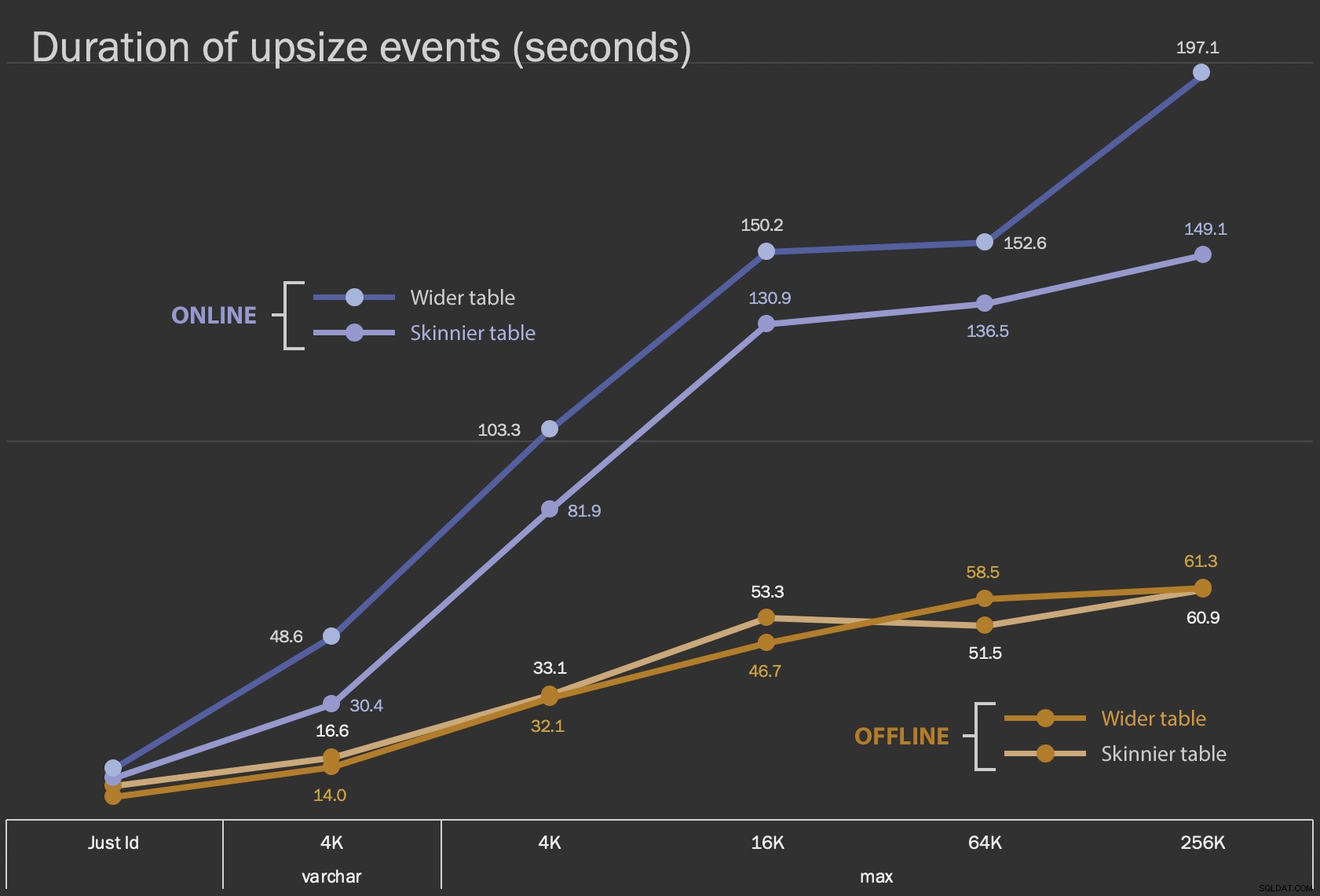 Продължителност, в секунди, на промяна на колоната на място
Продължителност, в секунди, на промяна на колоната на място
Изпълнението на това като онлайн операция отнема повече време (200 секунди в най-лошия случай), но не блокира потребителите. Изглежда, че се увеличава заедно с размера, но не съвсем линейно. Извършването на тази операция офлайн причинява блокиране, но е много по-бързо и не се променя толкова драстично, когато масата се увеличава (дори и при най-големия размер, това все още се случва за около минута).
Сравняването на тези операции на място с операцията за размяна и пускане е трудно с помощта на линейна диаграма поради огромната разлика в мащаба. Вместо това ще покажа хоризонтална лентова диаграма за продължителността, свързана с всяка конфигурация на таблицата. Когато повторното създаване е по-бързо, ще боядисам фона на този ред в зелено; когато е по-бавен (или попада между офлайн и онлайн методи), вероятно няма нужда, но ще боядисам фона на този ред в червено.
| LOB размер | Подход | Конфигурация на таблица | Продължителност (секунди) | ||
|---|---|---|---|
| Просто идентификатор | ALTER офлайн | По-слаба таблица (10 MB) | 8.8 |
| По-широка таблица (30 MB) | 6.3 | ||
| ALTER онлайн | По-слаба маса | 11.0 | |
| По-широка таблица | 13.6 | ||
| Пресъздайте отново | По-слаба маса | 3.4 | |
| varchar 4K | Офлайн | По-слаба таблица (390 MB) | 16.6 |
| По-широка таблица (780 MB) | 14.0 | ||
| Онлайн | По-слаба маса | 30.4 | |
| По-широка таблица | 48.6 | ||
| Повторно създаване | По-слаба маса | 1290.0 | |
| макс. 4k | Офлайн | По-слаба таблица (390 MB) | 33.1 |
| По-широка таблица (780 MB) | 32.1 | ||
| Онлайн | По-слаба маса | 81.9 | |
| По-широка таблица | 103.3 | ||
| Пресъздайте отново | По-слаба маса | 28.9 | |
| макс. 16k | Офлайн | По-слаба таблица (1,6 GB) | 53.3 |
| По-широка таблица (1,7 GB) | 46.7 | ||
| Онлайн | По-слаба маса | 130.9 | |
| По-широка таблица | 150.2 | ||
| Повторно създаване | По-слаба маса | 81.8 | |
| макс. 64k | Офлайн | По-слаба таблица (7,0 GB) | 51.5 |
| По-широка таблица (7,1 GB) | 58.5 | ||
| Онлайн | По-слаба маса | 136.5 | |
| По-широка таблица | 152.6 | ||
| Повторно създаване | По-слаба маса | 226.5 | |
| макс. 256k | Офлайн | По-слаба маса (25,8 GB) | 60.9 |
| По-широка таблица (25,9 GB) | 61.3 | ||
| Онлайн | По-слаба маса | 149.1 | |
| По-широка таблица | 197.1 | ||
| Повторно създаване | По-слаба маса | 1576.7 | |
Това е несправедливо разклащане на метода на Анди, защото – в реалния свят – не бихте извършили цялата тази операция наведнъж. Не показах използването на регистрационния файл на транзакциите тук за краткост, но би било по-лесно да контролирате това чрез групиране и в операция рамо до рамо. Въпреки че неговият подход изисква повече работа отпред, той е много по-безопасен по отношение на престой и/или блокиране. Но можете да видите в случаите, когато имате много данни извън реда и можете да си позволите кратък прекъсване, че директното изменение на колоната е много по-малко болезнено. „Твърде голям за промяна на място“ е субективен и може да доведе до различни резултати в зависимост от това какво означава „голям“. Преди да се ангажирате с даден подход, може да има смисъл да тествате промяната спрямо разумно копие, тъй като операцията на място може да представлява приемлив компромис.
Заключение
Не написах това, за да споря с Анди. Подходът в оригиналната публикация е стабилен, 100% надежден и ние го използваме през цялото време. Въпреки това, когато грубата сила се оценява пред хирургичната прецизност и особено ако можете да отделите време на престой, може да има стойност в по-простия подход за определени форми на маса.