Още през януари 2015 г. моят добър приятел и колега MVP на SQL Server Роб Фарли написа за ново решение на проблема с намирането на медианата във версиите на SQL Server преди 2012 г. Освен че е интересно четиво само по себе си, се оказва, че чудесен пример за използване, за да демонстрирате някои усъвършенствани анализи на план за изпълнение и да подчертаете някои фини поведения на оптимизатора на заявки и машината за изпълнение.
Единична медиана
Въпреки че статията на Роб е насочена специално към групирано изчисление на медиана, ще започна с прилагане на неговия метод към голям проблем за изчисление на единична медиана, тъй като тя подчертава най-ясно важните въпроси. Примерните данни отново ще дойдат от оригиналната статия на Aaron Bertrand:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Прилагането на техниката на Роб Фарли към този проблем дава следния код:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Както обикновено, коментирах преброяването на броя на редовете в таблицата и го замених с константа, за да избегна източник на отклонение в производителността. Планът за изпълнение на важната заявка е както следва:

Тази заявка се изпълнява за 5800 мс на моята тестова машина.
Разливът на сортиране
Основната причина за тази лоша производителност трябва да бъде ясна от разглеждането на плана за изпълнение по-горе:Предупреждението на оператора Sort показва, че недостатъчното предоставяне на памет на работното пространство е причинило преливане на ниво 2 (многопроходно) към физически tempdb диск:
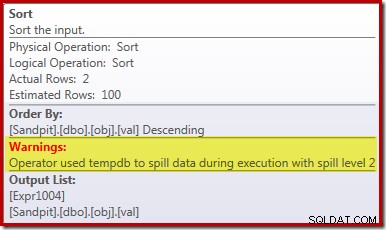
Във версиите на SQL Server преди 2012 г. ще трябва да наблюдавате отделно за събития на сортиране на разливане, за да видите това. Както и да е, недостатъчната резервация на паметта за сортиране е причинена от грешка в оценката на кардиналността, както показва планът за предварително изпълнение (приблизителен):

Оценката за мощност от 100 реда на входа за сортиране е (удивително неточна) предположение от оптимизатора, поради израза на локалната променлива в предходния оператор Top:

Имайте предвид, че тази грешка в оценката на кардиналността не е проблем с целта на реда. Прилагането на флаг за проследяване 4138 ще премахне ефекта на целта на реда под първата горна част, но оценката след най-горната все пак ще бъде предположение от 100 реда (така че резервацията на паметта за сортирането все още ще бъде твърде малка):

Намекване на стойността на локалната променлива
Има няколко начина, по които бихме могли да разрешим този проблем с оценката на мощността. Една от опциите е да използвате намек, за да предоставите на оптимизатора информация за стойността, съхранявана в променливата:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Използването на подсказката подобрява производителността до 3250 ms от 5800ms. Планът след изпълнение показва, че сортирането вече не се разлива:

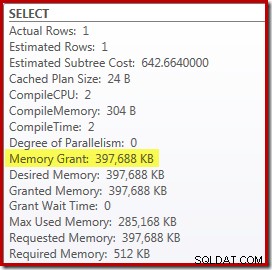
Има обаче няколко недостатъка в това. Първо, този нов план за изпълнение изисква 388MB предоставяне на памет – памет, която иначе би могла да се използва от сървъра за кеширане на планове, индекси и данни:
Второ, може да е трудно да изберете добър номер за намек, който ще работи добре за всички бъдещи изпълнения, без да резервирате памет ненужно.
Забележете също, че трябваше да намекнем стойност за променливата, която е с 10% по-висока от действителната стойност на променливата, за да елиминираме напълно разлива. Това не е необичайно, тъй като общият алгоритъм за сортиране е доста по-сложен от обикновеното сортиране на място. Резервирането на памет, равна на размера на набора за сортиране, не винаги (или дори като цяло) ще бъде достатъчно, за да се избегне разливане по време на изпълнение.
Вграждане и прекомпилиране
Друга възможност е да се възползвате от активираната оптимизация за вграждане на параметри чрез добавяне на подсказка за прекомпилиране на ниво заявка в SQL Server 2008 SP1 CU5 или по-нова версия. Това действие ще позволи на оптимизатора да види стойността по време на изпълнение на променливата и да оптимизира съответно:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Това подобрява времето за изпълнение до 3150 ms – 100 ms по-добре от използването на OPTIMIZE FOR намек. Причината за това допълнително малко подобрение може да се разбере от новия план след изпълнение:

Изразът (2 – @Count % 2) – както се вижда по-рано във втория оператор Top – вече може да бъде сгънат до една известна стойност. След оптимизационното пренаписване може след това да се комбинира най-горното със сортирането, което води до единично топ N сортиране. Това пренаписване не беше възможно по-рано, тъй като свиването на Top + Sort в Top N Sort работи само с постоянна литерална стойност на Top (не променливи или параметри).
Замяната на най-горното и сортиране с най-добро N сортиране има малък благоприятен ефект върху производителността (тук 100 мс), но също така почти изцяло елиминира изискването за памет, тъй като Топ N сортиране трябва да следи само най-високото (или най-ниското) N редове, а не целия комплект. В резултат на тази промяна в алгоритъма, планът след изпълнение за тази заявка показва, че минималният 1MB паметта беше запазена за Top N Sort в този план и само 16KB беше използван по време на изпълнение (не забравяйте, че планът за пълен сорт изисква 388 MB):
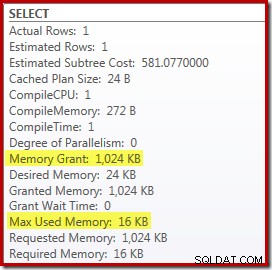
Избягване на прекомпилация
(Очевидният) недостатък на използването на намек за заявка за прекомпилиране е, че изисква пълна компилация при всяко изпълнение. В този случай режийните разходи са доста малки – около 1 мс процесорно време и 272 KB памет. Въпреки това има начин да настроите заявката така, че да получим предимствата на Top N Sort, без да използваме никакви подсказки и без повторно компилиране.
Идеята идва от признаването на това максимум от два реда ще са необходими за окончателното изчисление на медиана. Може да е един ред, или може да са два по време на изпълнение, но никога не може да бъде повече. Това прозрение означава, че можем да добавим логически излишна междинна стъпка отгоре (2) към заявката, както следва:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Новият Top (с изключително важния константен литерал) означава, че крайният план за изпълнение включва желания оператор Top N Sort без повторно компилиране:

Ефективността на този план за изпълнение е непроменена спрямо версията, подсказана за прекомпилиране на 3150 мс и изискването за памет е същото. Имайте предвид обаче, че липсата на вграждане на параметри означава, че оценките за мощността под сортирането са 100-редови предположения (въпреки че това не засяга производителността тук).
Основният извод на този етап е, че ако искате Top N Sort с малко памет, трябва да използвате постоянен литерал или да разрешите на оптимизатора да вижда литерал чрез оптимизация за вграждане на параметри.
Изчислителният скалар
Премахване на 388MB Предоставянето на памет (като същевременно прави подобрение на производителността със 100 мс) със сигурност си струва, но има много по-голяма печалба в производителността. Малко вероятната цел на това окончателно подобрение е изчислителният скалар точно над сканирането на клъстерирания индекс.
Този скалар за изчисляване се отнася до израза (0E + f.val) съдържащи се в AVG агрегат в заявката. В случай, че това ви изглежда странно, това е доста често срещан трик за писане на заявки (като умножаване по 1.0), за да се избегне целочислена аритметика при средното изчисление, но има някои много важни странични ефекти.
Тук има определена последователност от събития, които трябва да следваме стъпка по стъпка.
Първо, забележете, че 0E е постоянен литерал нула, с float тип данни. За да добави това към стойността на целочислената колона, процесорът на заявки трябва да преобразува колоната от цяло число в плаващо число (в съответствие с правилата за приоритет на типа данни). Подобен вид преобразуване би било необходимо, ако избрахме да умножим колоната по 1.0 (литерал с имплицитно числов тип данни). Важният момент е, че този рутинен триквъвежда израз .
Сега SQL Server обикновено се опитва да натисне изразите надолу дървото на плана, доколкото е възможно по време на компилация и оптимизация. Това се прави по няколко причини, включително за улесняване на съпоставянето на изрази с изчислени колони и за улесняване на опростяването с помощта на информация за ограничения. Тази политика за натискане надолу обяснява защо изчислителният скалар изглежда много по-близо до нивото на листа на плана, отколкото би предполагала оригиналната текстова позиция на израза в заявката.
Рискът от извършването на това натискане е, че изразът може да бъде изчислен повече пъти, отколкото е необходимо. Повечето планове включват намаляване на броя на редовете, докато се придвижваме нагоре по дървото на плана, поради ефекта на обединяването, агрегирането и филтрите. Следователно натискането на изрази надолу по дървото рискува тези изрази да бъдат оценени повече пъти (т.е. на повече редове), отколкото е необходимо.
За да смекчи това, SQL Server 2005 въведе оптимизация, при която Compute Scalars може просто да дефинира израз, с работата по действително оценяване изразът отложен докато по-късен оператор в плана не изисква резултата. Когато тази оптимизация работи по предназначение, ефектът е да се спечелят всички предимства от избутването на изразите надолу по дървото, като същевременно се оценява само толкова пъти, колкото е действително необходимо.
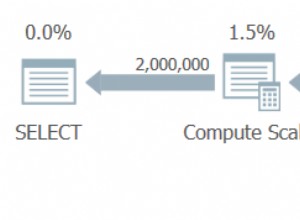
Какво означава всичко това Compute Scalar
В нашия пример за изпълнение, 0E + val изразът първоначално е бил свързан с AVG aggregate, така че може да очакваме да го видим в (или малко след) Stream Aggregate. Този израз обаче беизбутан надолу дървото да се превърне в нов Изчислителен скалар непосредствено след сканирането, с израза, обозначен като [Expr1004].
Разглеждайки плана за изпълнение, можем да видим, че [Expr1004] се препраща от Stream Aggregate (извлечение от раздела Plan Explorer Expressions, показан по-долу):

При равни условия оценката на израза [Expr1004] ще бъде отложена докато агрегатът се нуждае от тези стойности за сборната част от средното изчисление. Тъй като агрегатът може да срещне само един или два реда, това трябва да доведе до [Expr1004] да бъде оценен само веднъж или два пъти:
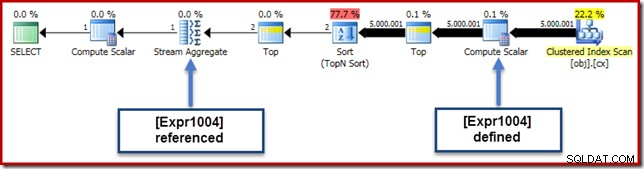
За съжаление тук нещата не стоят точно така. Проблемът е в блокиращия оператор за сортиране:
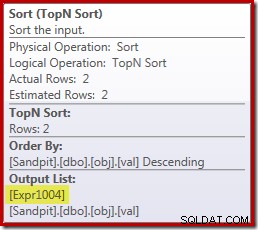
Това налага оценка на [Expr1004], така че вместо да бъде оценен само веднъж или два пъти в Stream Aggregate, Сортирането означава, че в крайна сметка преобразуваме val колона към float и добавяне на нула към него 5 000 001 пъти!
Заобиколно решение
В идеалния случай SQL Server би бил малко по-умен за всичко това, но днес не работи така. Няма намек за заявка, която да предотврати изтласкването на изрази надолу по дървото на плана и не можем да принудим да изчислим скалари с ръководство за план. Неизбежно има недокументиран флаг за проследяване, но за него не мога да говоря отговорно в настоящия контекст.
Така че, за добро или лошо, това ни оставя да се опитваме да намерим пренаписване на заявка, което се случва, за да попречи на SQL Server да отдели израза от агрегата и да го избута надолу покрай сортирането, без да променя резултата от заявката. Това не е толкова лесно, колкото може би си мислите, но модификацията по-долу (признано леко странно изглеждаща) постига това с помощта на CASE израз върху недетерминирана вътрешна функция:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Планът за изпълнение на тази последна форма на заявката е показан по-долу:

Забележете, че изчислителен скалар вече не се появява между сканирането на клъстериран индекс и горната част. 0E + val изразът вече се изчислява в Stream Aggregate на максимум два реда (а не на пет милиона!) и производителността се увеличава с още 32% от 3150ms до 2150ms като резултат.
Това все още не се сравнява толкова добре с представянето под секунда на OFFSET и решения за изчисление на медиана на динамичен курсор, но все пак представлява много значително подобрение спрямо оригиналните 5800 мс за този метод върху голям набор от проблеми с една медиана.
Не е гарантирано, че трикът CASE ще работи в бъдеще, разбира се. Изводът не е толкова за използването на странни трикове за изразяване на главни букви, колкото за потенциалните последици за производителността на Compute Scalars. След като разберете за подобни неща, може да помислите два пъти, преди да умножите по 1,0 или да добавите нула с плаваща стойност в средното изчисление.
Актуализация: моля, вижте първия коментар за хубаво решение от Робърт Хайниг, което не изисква никакви недокументирани трикове. Нещо, което трябва да имате предвид, когато следващия път се изкушите да умножите цяло число по десетично (или с плаваща) единица в среден агрегат.
Групирана медиана
За пълнота и за да свържем този анализ по-тясно с оригиналната статия на Роб, ще завършим, като приложим същите подобрения към групирано изчисление на медиана. По-малките размери на набора (за група) означават, че ефектите ще бъдат по-малки, разбира се.
Групираните средни извадкови данни (отново както първоначално са създадени от Аарон Бертран) включват десет хиляди реда за всеки от стоте въображаеми продавачи:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Прилагането на решението на Роб Фарли директно дава следния код, който се изпълнява за 560 мс на моята машина.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
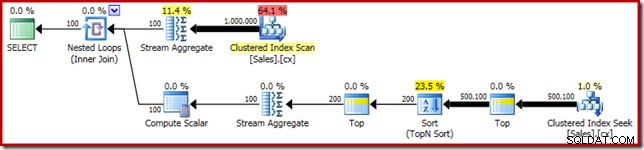
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Планът за изпълнение има очевидни прилики с единичната медиана:
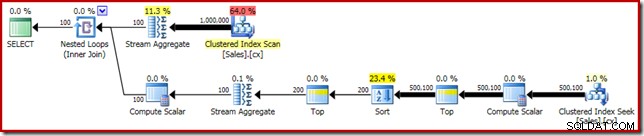
Първото ни подобрение е да заменим Сортиране с Топ N Сортиране, като добавим изрично Топ (2). Това леко подобрява времето за изпълнение от 560 ms на 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Планът за изпълнение показва най-добрия N сорт, както се очаква:
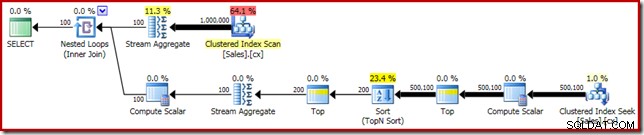
И накрая, ние разгръщаме странно изглеждащия CASE израз, за да премахнем избутания Compute Scalar израз. Това допълнително подобрява производителността до 450 мс (20% подобрение спрямо оригинала):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Готовият план за изпълнение е както следва: