За всяка нова база данни, създадена в SQL Server, стойността по подразбиране за опцията Auto Update Statistics е разрешена . Подозирам, че повечето DBA оставят опцията активирана, тъй като тя позволява на оптимизатора автоматично да актуализира статистическите данни, когато те са невалидни, и обикновено се препоръчва да я оставите активирана. Статистиките също се актуализират, когато индексите се преизграждат и въпреки че не е необичайно статистиката да се управлява добре чрез опцията за автоматично актуализиране на статистическите данни и чрез възстановяване на индекси, от време на време DBA може да намери за необходимо да настрои редовно задание за актуализиране на статистика или набор от статистически данни.
Персонализираното управление на статистиката често включва командата UPDATE STATISTICS, която изглежда доста безобидна. Може да се изпълнява за всички статистически данни за таблица или индексиран изглед или за конкретна статистика. Може да се използва извадката по подразбиране, може да се посочи специфична честота на извадка или брой редове за извадка или можете да използвате същата стойност на извадката, която е била използвана преди. Ако статистическите данни се актуализират за таблица или индексиран изглед, можете да изберете да актуализирате всички статистически данни, само статистики за индекси или само статистики за колони. И накрая, можете да деактивирате опцията за автоматично актуализиране на статистиката за статистика.
За повечето администратори на база данни най-голямото внимание може да бъде кога за да изпълните оператора UPDATE STATISTICS. Но DBA също решават, съзнателно или не, размера на извадката за актуализацията. Избраният размер на извадката може да повлияе на производителността на действителната актуализация, както и на производителността на заявките.
Разбиране на ефектите от размера на извадката
Размерът на извадката по подразбиране за АКТУАЛИЗАЦИЯТА НА СТАТИСТИКАТА идва от нелинеен алгоритъм и размерът на извадката намалява с увеличаването на размера на таблицата, както показа Джо Сак в публикацията си, Тест за извадка по подразбиране за автоматично актуализиране на статистическите данни. В някои случаи размерът на извадката може да не е достатъчно голям, за да улови достатъчно интересна информация, или вдясно информация за статистическата хистограма, както е отбелязано от Конър Кънингам в публикацията му за статистически извадки. Ако извадката по подразбиране не създава добра хистограма, администраторите на база данни могат да изберат да актуализират статистиката с по-висока честота на извадка, до FULLSCAN (сканиране на всички редове в таблицата или индексиран изглед). Но както Conor спомена в публикацията си, сканирането на повече редове е на цена и DBA е изправен пред предизвикателството да реши дали да изпълни FULLSCAN, за да опита да създаде възможната „най-добрата“ хистограма, или да пробва по-малък процент, за да сведе до минимум влиянието на производителността на актуализацията.
За да се опитам да разбера в кой момент една проба отнема повече време от FULLSCAN, изпълних следните изявления срещу копия на таблицата SalesOrderDetail, които бяха увеличени със скрипта на Джонатан Кехайас:
| ИД на изявление | Изявление UPDATE STATISTICS |
|---|---|
| 1 | АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] С ПЪЛНО СКАНИРАНЕ; |
| 2 | АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged]; |
| 3 | АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] С ПРОБА 10 ПРОЦЕНТА; |
| 4 | АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] С ПРОБА 25 ПРОЦЕНТА; |
| 5 | АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] С ПРОБА 50 ПРОЦЕНТА; |
| 6 | АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] С ПРОБА 75 ПРОЦЕНТА; |
Имах три копия на таблицата SalesOrderDetailEnlarged, със следните характеристики*:
| Брой редове | Брой страници | MAXDOP | Максимална памет | Съхранение | Машина |
|---|---|---|---|---|---|
| 23 899 449 | 363 284 | 4 | 8GB | SSD_1 | Лаптоп |
| 607 312 902 | 7 757 200 | 16 | 54GB | SSD_2 | Тестов сървър |
| 607 312 902 | 7 757 200 | 16 | 54GB | 15K | Тестов сървър |
*Допълнителни подробности за хардуера са в края на тази публикация.
Всички копия на таблицата имат следните статистически данни и нито една от трите индексни статистики не включва колони:
| Статистика | Тип | Колони в ключ |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Индекс | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Индекс | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Индекс | Идентификатор на продукта |
| user_CarrierTrackingNumber | Колона | CarrierTrackingNumber |
Изпълних горните оператори UPDATE STATISTICS четири пъти срещу таблицата SalesOrderDetailEnlarged на моя лаптоп и два пъти срещу таблиците SalesOrderDetailEnlarged на TestServer. Изявленията се изпълняваха в произволен ред всеки път и кешът на процедурите и кешът на буфера бяха изчистени преди всеки израз за актуализиране. Продължителността и използването на tempdb за всеки набор от изрази (усреднени) са в графиките по-долу:
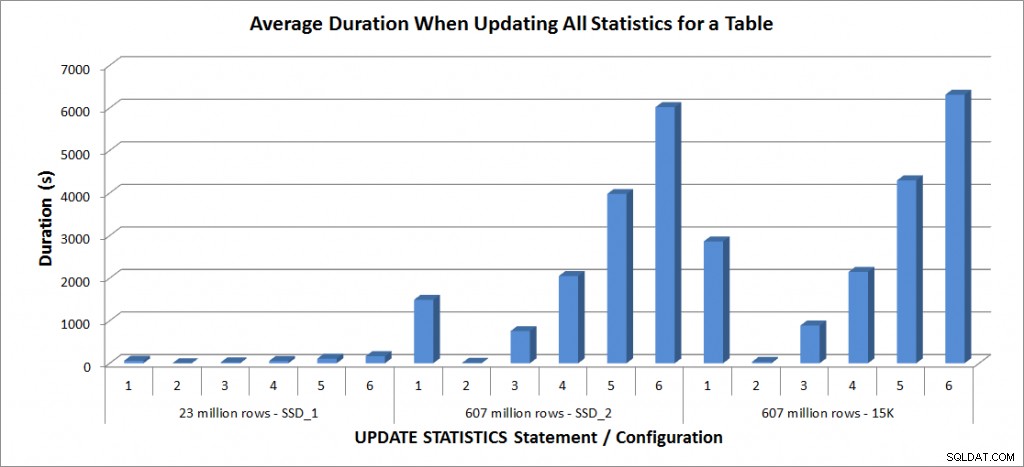
Средна продължителност – Актуализиране на всички статистически данни за SalesOrderDetailEnlarged
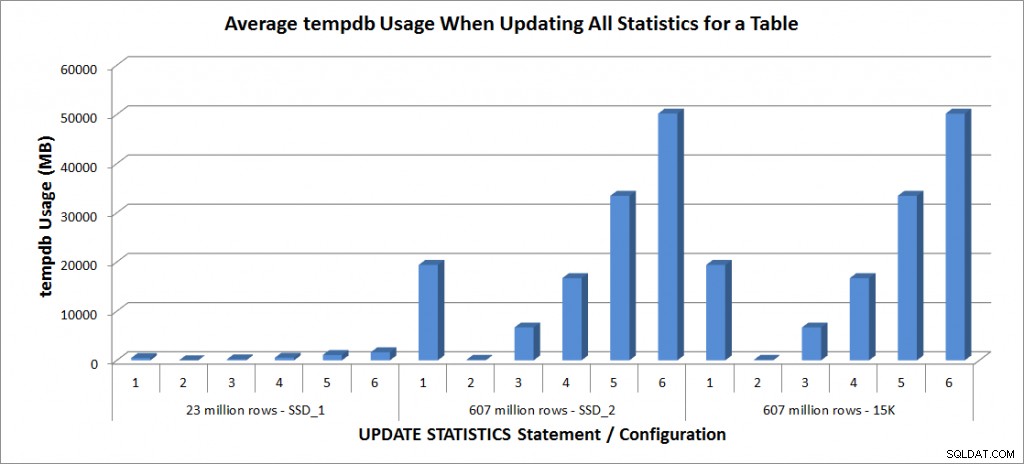
Използване на tempdb – Актуализиране на всички статистически данни за SalesOrderDetailEnlarged
Времетраенето на таблицата с редове от 23 милиона бяха по-малко от три минути и са описани по-подробно в следващия раздел. За таблицата на дисковете SSD_2, изявлението FULLSCAN отне 1492 секунди (почти 25 минути), а актуализацията с 25% извадка отне 2051 секунди (над 34 минути). За разлика от тях, на 15K дискове, изявлението FULLSCAN отне 2864 секунди (над 47 минути), а актуализацията с 25% извадка отне 2147 секунди (почти 36 минути) – по-малко от времето на FULLSCAN. Актуализацията с 50% извадка обаче отне 4296 секунди (над 71 минути).
Използването на Tempdb е много по-последователно, показвайки постоянно нарастване с увеличаване на размера на извадката и използва повече пространство за tempdb от FULLSCAN някъде между 25% и 50%. Това, което е забележително тук, е, че UPDATE STATISTICS прави използвайте tempdb, което е важно да запомните, когато оразмерявате tempdb за среда на SQL Server. Използването на Tempdb се споменава в записа UPDATE STATISTICS BOL:
UPDATE STATISTICS може да използва tempdb за сортиране на извадката от редове за изграждане на статистически данни.“
И ефектът е документиран в публикацията на Linchi Shea, Въздействие върху производителността:tempdb и статистика за актуализиране. Това обаче не е нещо, което винаги се споменава по време на дискусиите за оразмеряване на tempdb. Ако имате големи таблици и извършвате актуализации с FULLSCAN или високи стойности на извадката, имайте предвид използването на tempdb.
Изпълнение на селективни актуализации
След това реших да тествам изразите UPDATE STATISTICS за другите статистически данни в таблицата, но ограничих тестовете си до копие на таблицата с 23 милиона реда. Горните шест варианта на израза UPDATE STATISTICS бяха повторени четири пъти за следните отделни статистически данни и след това сравнени с актуализацията за цялата таблица:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Всички тестове бяха проведени с гореспоменатата конфигурация на моя лаптоп и резултатите са в графиката по-долу:
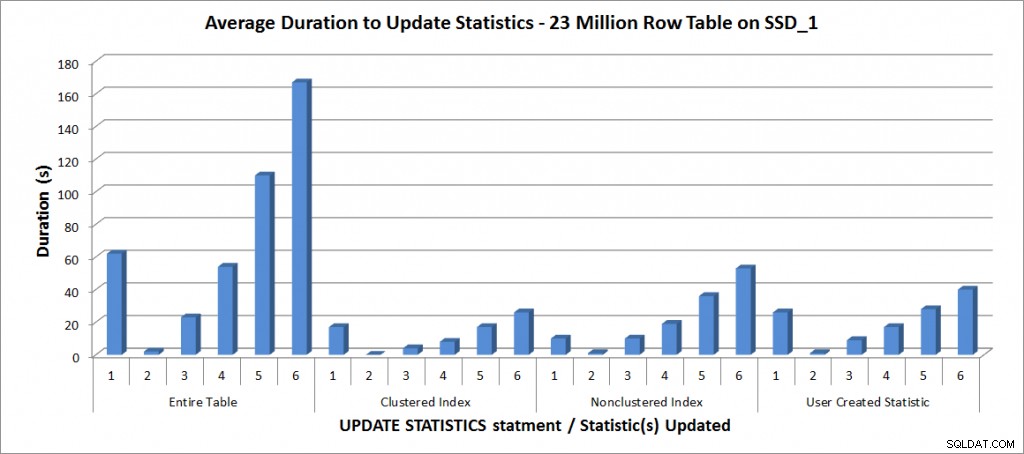
Средна продължителност за АКТУАЛИЗИРАНЕ НА СТАТИСТИКА – Всички статистически данни спрямо избрани
Както се очакваше, актуализациите на отделна статистика отнеха по-малко време, отколкото при актуализиране на всички статистически данни за таблицата. Стойността, при която актуализирането на извадката отне повече време, отколкото FULLSCAN варира:
| Изявление UPDATE | Продължителност на FULLSCAN (s) | Първата АКТУАЛИЗАЦИЯ, която отне повече време |
|---|---|---|
| Цяла таблица | 62 | 50% – 110 секунди |
| Клъстериран индекс | 17 | 75% – 26 секунди |
| Неклъстериран индекс | 10 | 25% – 19 секунди |
| Статистика, създадена от потребителя | 26 | 50% – 28 секунди |
Заключение
Въз основа на тези данни и данните от FULLSCAN от 607 милиона таблици с редове, няма конкретни повратна точка, при която извадката актуализация отнема повече време от FULLSCAN; тази точка зависи от размера на таблицата и наличните ресурси. Но данните все още си заслужават, тъй като показват, че има точка, в която заснемането на дадена извадка стойност може да отнеме повече време от FULLSCAN. Отново се свежда до познаване на вашите данни. Това е от решаващо значение не само за разбиране дали дадена таблица се нуждае от персонализирано управление на статистически данни, но и за разбиране на идеалния размер на извадката за създаване на полезна хистограма и също така за оптимизиране на използването на ресурсите.
Спецификации
Спецификации на лаптопа:Dell M6500, 1 Intel i7 (2,13GHz 4 ядра и HT е активиран, така че 8 логически ядра), 32 GB памет, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), файлове с база данни, съхранявани на 265GB Samsung SSD PM810Спецификации на тестовия сървър:Dell R720, 2 Intel E5-2670 (2.6GHz 8 ядра и HT е активиран, така че 16 логически ядра на сокет), 64 GB памет, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), файлове с база данни за едната таблица се намира на две 640GB Fusion-io Duo MLC карти, файловете с база данни за другата таблица са на девет 15K RPM диска в RAID5 масив