Мисля, че всички вече знаят моето мнение относно MERGE и защо стоя далеч от него. Но ето още един (анти)модел, който виждам навсякъде, когато хората искат да извършат upsert (актуализиране на ред, ако съществува и го вмъкнете, ако не):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Това изглежда като доста логичен поток, който отразява как мислим за това в реалния живот:
- Съществува ли вече ред за този ключ?
- ДА :Добре, актуализирайте този ред.
- НЕ :Добре, след това го добавете.
Но това е разточително.
Намирането на реда, за да се потвърди, че съществува, само за да се наложи да го намерите отново, за да го актуализирате, върши двойна работа за нищо. Дори ако ключът е индексиран (което се надявам винаги да е така). Ако поставя тази логика в блок-схема и асоциирам на всяка стъпка типа операция, която трябва да се случи в базата данни, ще имам това:
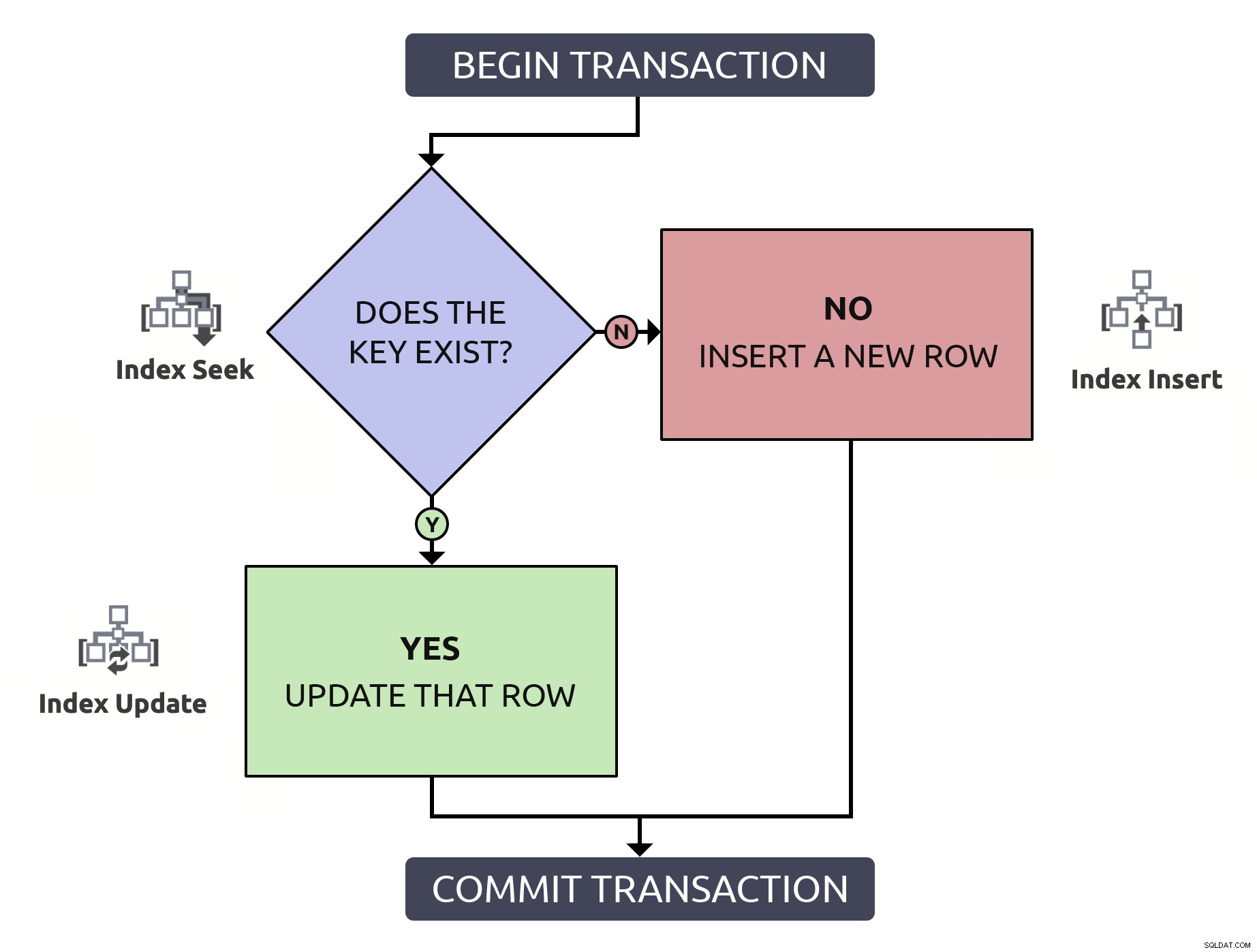 Забележете, че всички пътища ще изискват две операции с индекс.
Забележете, че всички пътища ще изискват две операции с индекс.
По-важното е, че производителността настрана, освен ако и двамата не използвате изрична транзакция и не повишите нивото на изолация, много неща могат да се объркат, когато редът вече не съществува:
- Ако ключът съществува и две сесии се опитат да се актуализират едновременно, те и двете ще се актуализират успешно (един ще „спечели“; „губещият“ ще последва промяната, която остава, което води до „загубена актуализация“). Това не е проблем сам по себе си и така трябва очаквайте да работи система с паралелност. Пол Уайт говори за вътрешната механика по-подробно тук, а Мартин Смит говори за някои други нюанси тук.
- Ако ключът не съществува, но и двете сесии преминават проверката за съществуване по един и същи начин, всичко може да се случи, когато и двете се опитат да вмъкнат:
- застой поради несъвместими ключалки;
- повишаване на грешки при ключови нарушения това не трябваше да се случва; или,
- вмъкнете дублирани стойности на ключ ако тази колона не е правилно ограничена.
Последният е най-лошият, IMHO, защото е този, който потенциално разваля данните . Застойните блокировки и изключенията могат да се обработват лесно с неща като обработка на грешки, XACT_ABORT и повторете логиката, в зависимост от това колко често очаквате сблъсъци. Но ако сте приспивани в чувство за сигурност, че IF EXISTS проверката ви предпазва от дублиране (или ключови нарушения), това е изненада, която чака да се случи. Ако очаквате колона да действа като ключ, направете я официална и добавете ограничение.
„Много хора казват…“
Дан Гузман говори за условията на състезанието преди повече от десетилетие в Условно INSERT/UPDATE Race Condition и по-късно в "UPSERT" Race Condition With MERGE.
Майкъл Суорт също е третирал тази тема няколко пъти:
- Разрушаване на митове:Паралелно актуализиране/вмъкване на решения – където той признава, че оставянето на първоначалната логика на място и само повишаването на нивото на изолация просто промени ключовите нарушения в застой;
- Бъдете внимателни с изявлението за сливане – където той провери ентусиазма си относно
MERGE; и, - Какво да избягвате, ако искате да използвате MERGE – където той потвърди още веднъж, че все още има много основателни причини да продължите да избягвате
MERGE.
Уверете се, че сте прочели и всички коментари и на трите публикации.
Решението
Поправих много блокирания в кариерата си, като просто се приспособих към следния модел (изхвърлете излишната проверка, увийте последователността в транзакция и защитете достъпа до първата таблица с подходящо заключване):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Защо са ни необходими два съвета? Не е UPDLOCK достатъчно?
UPDLOCKсе използва за защита срещу блокиране на преобразуване в изявление ниво (оставете друга сесия да изчака, вместо да насърчавате жертвата да опита отново).SERIALIZABLEсе използва за защита срещу промени в основните данни по време на цялата транзакция (уверете се, че ред, който не съществува, продължава да не съществува).
Това е малко повече код, но е 1000% по-безопасен и дори в най-лошия case (редът вече не съществува), той изпълнява същото като анти-шаблона. В най-добрия случай, ако актуализирате ред, който вече съществува, ще бъде по-ефективно да намерите този ред само веднъж. Комбинирайки тази логика с операциите на високо ниво, които трябва да се случат в базата данни, е малко по-просто:
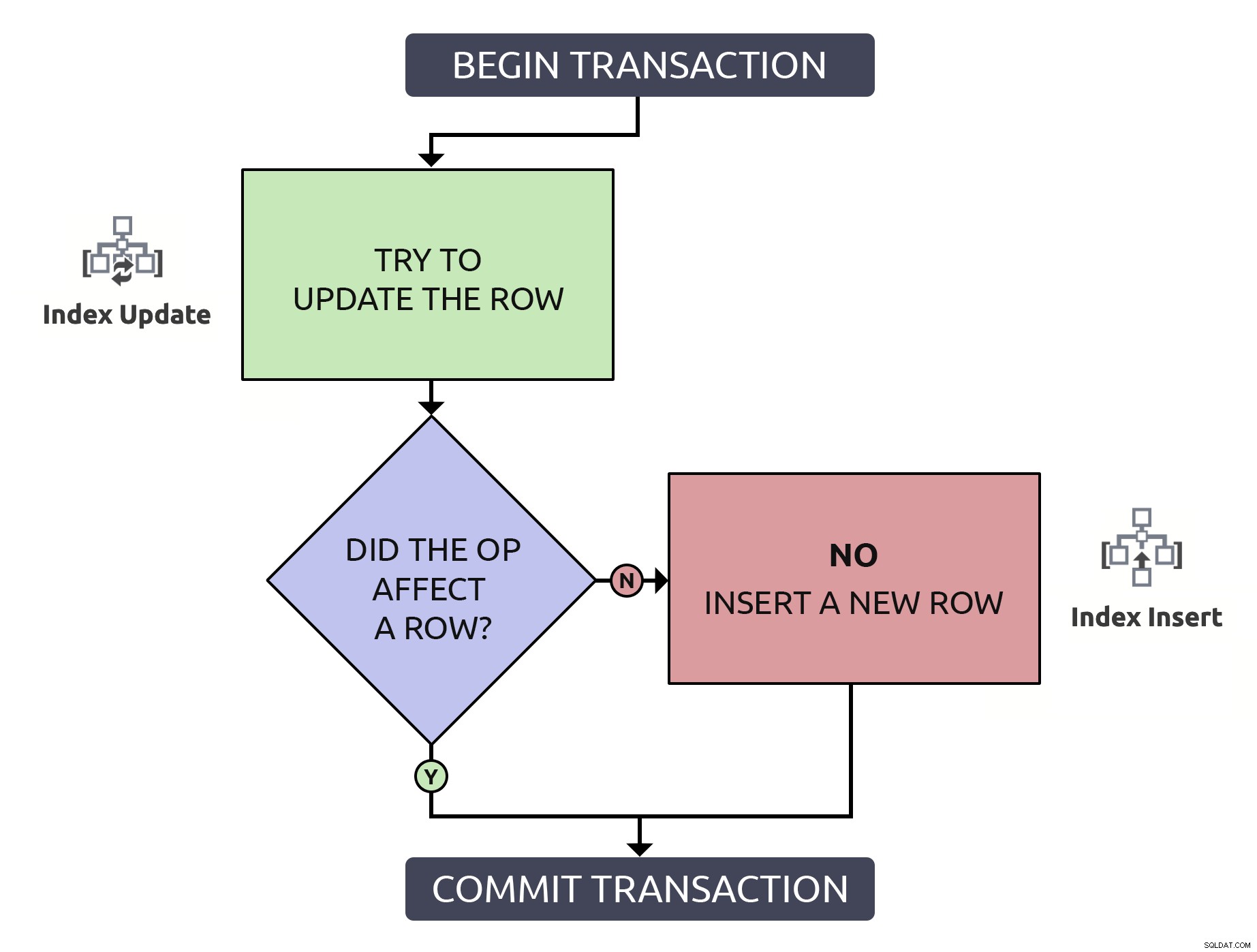 В този случай един път включва само една операция с индекс.
В този случай един път включва само една операция с индекс.
Но отново, производителността настрана:
- Ако ключът съществува и две сесии се опитат да го актуализират едновременно, те ще се редуват и ще актуализират реда успешно , както преди.
- Ако ключът не съществува, една сесия ще „спечели“ и ще вмъкне реда . Другият ще трябва да изчака докато ключалките не бъдат освободени, за да се провери дори за съществуване и да бъдат принудени да се актуализират.
И в двата случая писателят, спечелил състезанието, губи данните си заради всичко, което „губещият“ е актуализирал след тях.
Обърнете внимание, че общата пропускателна способност на система с висока конкурентност може страдате, но това е компромис, който трябва да сте готови да направите. Това, че получавате много жертви на безизходица или грешки при ключови нарушения, но те се случват бързо, не е добър показател за ефективността. Някои хора биха искали да видят, че блокирането е премахнато от всички сценарии, но част от това е блокиране, което абсолютно искате за целостта на данните.
Но какво ще стане, ако актуализацията е по-малко вероятна?
Ясно е, че горното решение оптимизира за актуализации и предполага, че ключ, към който се опитвате да пишете, вече ще съществува в таблицата толкова често, колкото и не. Ако предпочитате да оптимизирате за вмъквания, знаейки или предполагайки, че вмъкванията ще са по-вероятни от актуализациите, можете да обърнете логиката наоколо и все пак да имате безопасна операция за внасяне:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Има и подходът „просто го направи“, при който сляпо вмъквате и оставяте сблъсъците да предизвикват изключения към обаждащия се:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Цената на тези изключения често надвишава цената на първо проверка; ще трябва да го опитате с приблизително точно предположение за процента на попадане/пропускане. Писах за това тук и тук.
Ами добавянето на няколко реда?
Горното се отнася до решенията за еднократно вмъкване/актуализиране, но Джъстин Пийлинг попита какво да прави, когато обработвате няколко реда, без да знаете кои от тях вече съществуват?
Ако приемем, че изпращате набор от редове с помощта на нещо като параметър с стойност на таблица, ще актуализирате с помощта на присъединяване и след това ще вмъкнете, като използвате NOT EXISTS, но шаблонът все пак ще бъде еквивалентен на първия подход по-горе:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Ако събирате няколко реда заедно по някакъв начин, различен от TVP (XML, списък, разделен със запетая, вуду), първо ги поставете във формуляр за таблица и се присъединете към каквото и да е това. Внимавайте да не оптимизирате първо за вмъквания в този сценарий, в противен случай потенциално ще актуализирате някои редове два пъти.
Заключение
Тези шаблони на upsert са по-добри от тези, които виждам твърде често и се надявам да започнете да ги използвате. Ще посоча тази публикация всеки път, когато забележа IF EXISTS модел в дивата природа. И, хей, още едно поздравление към Пол Уайт (sql.kiwi | @SQK_Kiwi), защото той е толкова отличен в това да прави трудни концепции лесни за разбиране и от своя страна да обяснява.
И ако смятате, че трябва използвайте MERGE , моля, не ме @; или имате основателна причина (може би имате нужда от някакво неясно MERGE). -само функционалност), или не сте приели горните връзки сериозно.