От време на време може да забележите, че едно или повече присъединявания в план за изпълнение са анотирани с StarJoinInfo структура. Официалната схема на showplan има следното да се каже за този елемент на плана (щракнете, за да го увеличите):
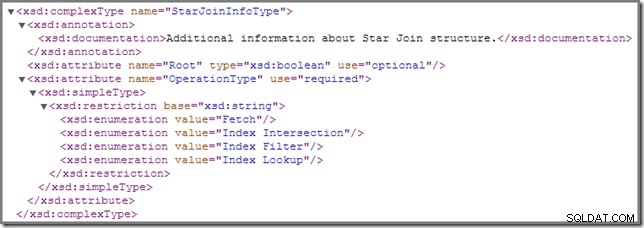
Вградената документация, показана там („допълнителна информация за структурата на Star Join ") не е чак толкова поучително, въпреки че другите подробности са доста интригуващи – ще ги разгледаме подробно.
Ако се консултирате с любимата си търсачка за повече информация, използвайки термини като „SQL Server star join optimization“, вероятно ще видите резултати, описващи оптимизирани растерни филтри. Това е отделна функция само за предприятия, въведена в SQL Server 2008 и не е свързана с StarJoinInfo структура изобщо.
Оптимизации за селективни заявки със звезда
Наличието на StarJoinInfo показва, че SQL Server е приложил една от набор от оптимизации, насочени към селективни заявки със звездна схема. Тези оптимизации са налични от SQL Server 2005, във всички издания (не само Enterprise). Имайте предвид, че селективен тук се отнася до броя на редовете, извлечени от таблицата с факти. Комбинацията от дименсионни предикати в заявка все още може да бъде селективна, дори когато нейните отделни предикати квалифицират голям брой редове.
Обикновено пресичане на индекси
Оптимизаторът на заявки може да обмисли комбиниране на множество неклъстерирани индекси, когато не съществува подходящ единичен индекс, както показва следната заявка на AdventureWorks:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
Оптимизаторът определя, че комбинирането на два неклъстерирани индекса (един на SalesPersonID а другият на CustomerID ) е най-евтиният начин да удовлетворите тази заявка (няма индекс и в двете колони):
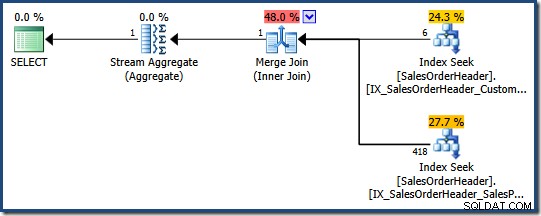
Всяко търсене на индекс връща клъстерирания индексен ключ за редове, които предават предиката. Обединяването съвпада с върнатите ключове, за да се гарантира, че само редовете, които съвпадат с и двете предикатите се предават.
Ако таблицата беше купчина, всяко търсене би връщало идентификатори на редове на купчина (RID) вместо клъстерирани индексни ключове, но цялостната стратегия е същата:намерете идентификатори на редове за всеки предикат, след което ги съпоставете.
Ръчно пресичане на индекса за свързване със звезда
Същата идея може да бъде разширена и до заявки, които избират редове от таблица с факти, използвайки предикати, приложени към таблици с измерения. За да видите как работи това, помислете за следната заявка (използвайки примерната база данни на Contoso BI), за да намерите общата сума на продажбите за MP3 плейъри, продавани в магазините на Contoso с точно 50 служители:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; За сравнение с по-късните усилия, тази (много селективна) заявка създава план за заявка като следния (щракнете за разгъване):
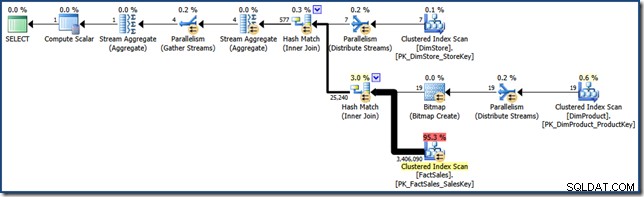
Този план за изпълнение има прогнозна цена от малко над 15,6 единици . Той включва паралелно изпълнение с пълно сканиране на таблицата с факти (макар и с приложен филтър за растерни изображения).
Таблиците с факти в тази примерна база данни не включват неклъстерирани индекси на външните ключове на таблицата с факти по подразбиране, така че трябва да добавим няколко:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
С тези индекси можем да започнем да виждаме как може да се използва пресичането на индекси за подобряване на ефективността. Първата стъпка е да намерите идентификатори на редове в таблица с факти за всеки отделен предикат. Следните заявки прилагат предикат с едно измерение, след което се присъединяват обратно към таблицата с факти, за да намерите идентификатори на редове (кластерни индексни ключове на таблицата с факти):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Плановете на заявката показват сканиране на таблицата с малки измерения, последвано от справки, използващи неклъстерирания индекс на таблицата с факти, за да се намерят идентификатори на редове (не забравяйте, че неклъстерираните индекси винаги включват основния ключ за клъстериране на таблицата или RID на купчина):
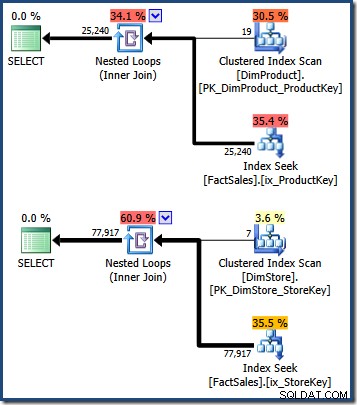
Пресечната точка на тези два набора от клъстерирани индексни ключове на таблица с факти идентифицира редовете, които трябва да бъдат върнати от оригиналната заявка. След като имаме тези идентификатори на редове, просто трябва да потърсим сумата на продажбите във всеки ред на таблицата с факти и да изчислим сумата.
Ръчна заявка за пресичане на индекс
Обединяването на всичко това в заявка дава следното:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
FORCESEEK намек е там, за да гарантираме, че получаваме точкови справки в таблицата с факти. Без това оптимизаторът избира да сканира таблицата с факти, което е точно това, което искаме да избегнем. MAXDOP 1 намек просто помага да запазите крайния план в доста разумен размер за целите на показване (щракнете, за да го видите в пълен размер):
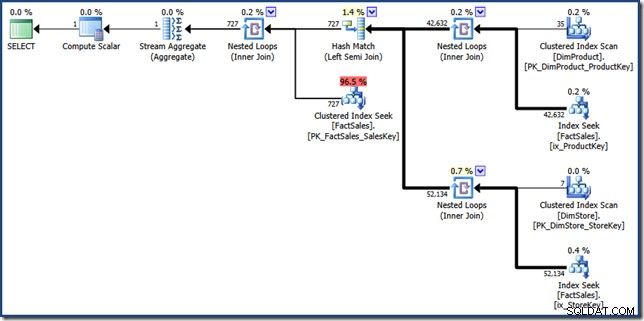
Съставните части на ръчния план за пресичане на индекса са доста лесни за идентифициране. Двете неклъстерирани индексни търсения на таблица с факти от дясната страна произвеждат двата набора от идентификатори на редове в таблицата с факти. Хеш обединението намира пресечната точка на тези два набора. Търсенето на клъстериран индекс в таблицата с факти намира сумите на продажбите за тези идентификатори на редове. И накрая, Stream Aggregate изчислява общата сума.
Този план за заявка извършва сравнително малко претърсвания в неклъстерирани и клъстерирани индекси на таблицата с факти. Ако заявката е достатъчно селективна, това може да е по-евтина стратегия за изпълнение от пълното сканиране на таблицата с факти. Примерната база данни на Contoso BI е сравнително малка, със само 3,4 милиона реда в таблицата с факти за продажбите. За по-големи таблици с факти разликата между пълно сканиране и няколкостотин търсения може да бъде много значителна. За съжаление, ръчното пренаписване въвежда някои сериозни грешки в кардиналността, което води до план с прогнозна цена от 46,5 единици .
Автоматично пресичане на индекса за присъединяване със звезда с справки
За щастие не е нужно да решаваме дали заявката, която пишем, е достатъчно селективна, за да оправдае това ръчно пренаписване. Оптимизациите за свързване със звезда за селективни заявки означават, че оптимизаторът на заявки може да проучи тази опция вместо нас, като използва по-удобния за потребителя оригинален синтаксис на заявката:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Оптимизаторът произвежда следния план за изпълнение с прогнозна цена от 1,64 единици (щракнете за увеличаване):
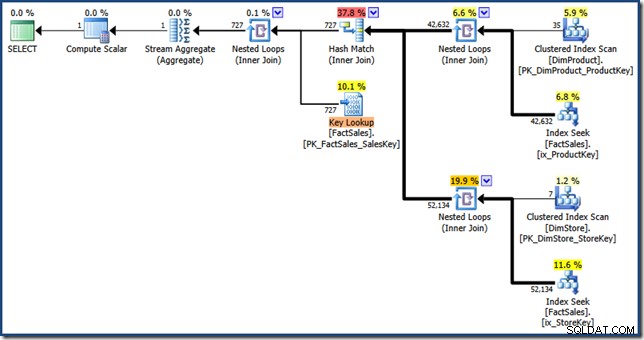
Разликите между този план и ръчната версия са:пресечната точка на индекса е вътрешно съединение вместо полусъединяване; и търсенето на клъстериран индекс се показва като ключово търсене вместо търсене на клъстериран индекс. С риск да се заемем с въпроса, ако таблицата с факти беше купчина, ключовото търсене би било RID търсене.
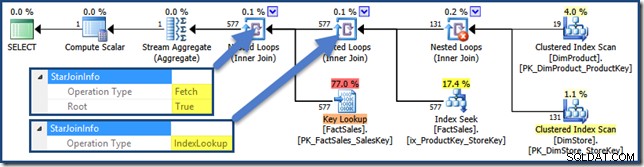
Свойствата на StarJoinInfo
Всички присъединявания в този план имат StarJoinInfo структура. За да го видите, щракнете върху итератор за присъединяване и погледнете в прозореца Свойства на SSMS. Щракнете върху стрелката вляво от StarJoinInfo елемент за разширяване на възела.
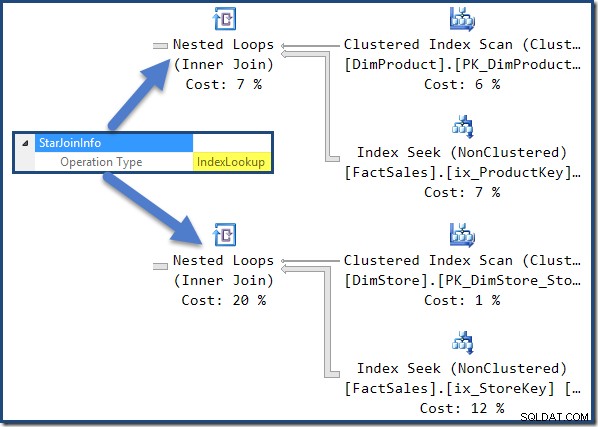
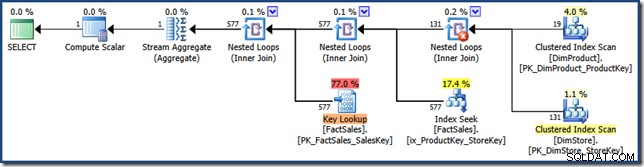
Неклъстерираната таблица с факти, която се присъединява отдясно на плана, представлява търсене на индекси, изградено от оптимизатора:
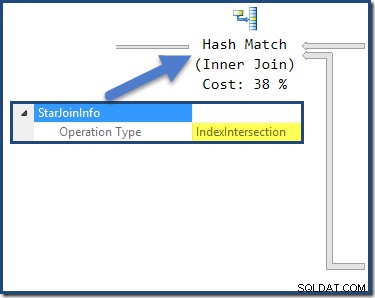
Хеш присъединяването има StarJoinInfo структура, показваща, че извършва пресичане на индекс (отново произведено от оптимизатора):
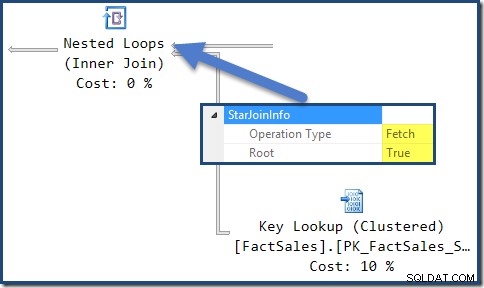
StarJoinInfo за най-лявото присъединяване на вложени цикли показва, че е генерирано за извличане на редове в таблица с факти по идентификатор на ред. Той е в основата на генерираното от оптимизатора поддърво за свързване със звезда:
Картезиански продукти и търсене в многоколонови индекси
Плановете за пресичане на индекси, разглеждани като част от оптимизацията за свързване на звезда, са полезни за селективни заявки за таблици с факти, където съществуват неклъстерирани индекси с една колона върху външни ключове на таблицата с факти (често срещана дизайнерска практика).
Понякога също има смисъл да създавате индекси с няколко колони върху външни ключове на таблицата с факти за често заявени комбинации. Вградените оптимизации на селективни заявки със звезда съдържат пренаписване и за този сценарий. За да видите как работи това, добавете следния индекс с няколко колони към таблицата с факти:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Отново компилирайте тестовата заявка:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Планът на заявката вече не включва пресичане на индекса (щракнете, за да увеличите):
Избраната тук стратегия е да се приложи всеки предикат към таблиците с измерения, да се вземе декартовото произведение на резултатите и да се използва за търсене в двата ключа на индекса с много колони. След това планът на заявката извършва Key Lookup в таблицата с факти, използвайки идентификатори на редове точно както се вижда по-рано.
Планът на заявката е особено интересен, защото съчетава три функции, които често се считат за лоши неща (пълни сканирания, декартови продукти и ключови търсения) в оптимизацията на производителността . Това е валидна стратегия, когато се очаква продуктът на двете измерения да бъде много малък.
Няма StarJoinInfo за декартовото произведение, но другите съединения имат информация (щракнете, за да увеличите):
Индексен филтър
Обръщайки се обратно към схемата на showplan, има още един StarJoinInfo операция, която трябва да покрием:
Index Filter стойността се вижда с обединения, които се считат за достатъчно селективни, за да си струва да бъдат изпълнени преди извличането на таблицата с факти. Присъединяванията, които не са достатъчно селективни, ще се извършват след извличането и няма да имат StarJoinInfo структура.
За да видим индексен филтър с помощта на нашата тестова заявка, трябва да добавим трета таблица за присъединяване към микса, да премахнем неклъстерираните индекси на таблица с факти, създадени досега, и да добавим нова:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Планът на заявката сега е (щракнете за уголемяване):
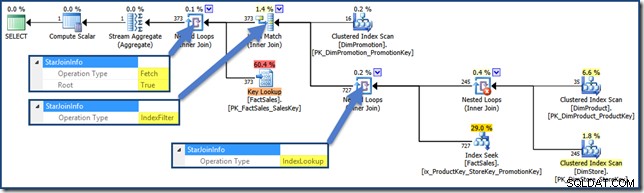
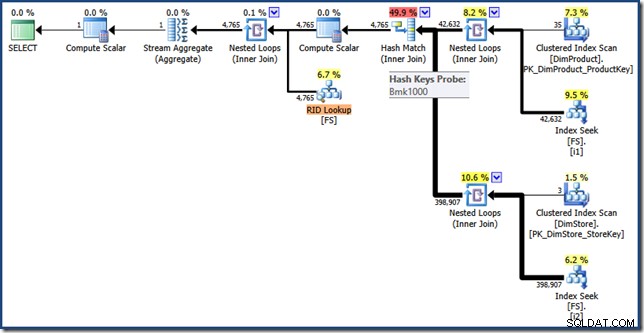
План за заявка за пресичане на индекс на Heap
За пълнота, ето скрипт за създаване на купчина копие на таблицата с факти с двата неклъстерирани индекса, необходими, за да се даде възможност за пренаписване на оптимизатора за пресичане на индекси:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Планът за изпълнение на тази заявка има същите функции като преди, но пресичането на индекса се извършва с помощта на RID вместо клъстерирани индексни ключове в таблицата с факти, а окончателното извличане е търсене на RID (щракнете, за да разгънете):
Последни мисли
Показаните тук пренаписвания на оптимизатора са насочени към заявки, които връщат относително малък брой редове от голям таблица с факти. Тези пренаписвания са налични във всички издания на SQL Server от 2005 г. насам.
Въпреки че има за цел да ускори селективните заявки за схема със звезда (и снежинка) в съхранението на данни, оптимизаторът може да приложи тези техники навсякъде, където открие подходящ набор от таблици и съединения. Евристиките, използвани за откриване на заявки със звезда, са доста широки, така че може да срещнете форми на план с StarJoinInfo структури в почти всеки тип база данни. Всяка таблица с разумен размер (да речем 100 страници или повече) с препратки към по-малки (подобни на измерения) таблици е потенциален кандидат за тези оптимизации (обърнете внимание, че изричните външни ключове не задължително).
За тези от вас, които харесват подобни неща, правилото за оптимизатор, отговорно за генериране на селективни модели на свързване в звезда от логическо свързване на n-таблици, се нарича StarJoinToIdxStrategy (стратегия за присъединяване със звезда към индекс).