Това е третата от поредица от пет части, която прави дълбоко потапяне в начина, по който започват да се изпълняват паралелните планове в режим на ред на SQL Server. Част 1 инициализира нулев контекст на изпълнение за родителската задача, а част 2 създаде дървото за сканиране на заявка. Вече сме готови да започнем сканирането на заявката, да извършим някаква ранна фаза обработка и стартирайте първите допълнителни паралелни задачи.
Стартиране на сканиране на заявка
Припомнете си, че само родителската задача съществува в момента и борсите (оператори на паралелизъм) имат само потребителска страна. Все пак това е достатъчно, за да започне изпълнението на заявката в работната нишка на родителската задача. Процесорът на заявки започва да се изпълнява, като стартира процеса на сканиране на заявки чрез извикване на CQueryScan::StartupQuery . Напомняне за плана (щракнете за уголемяване):
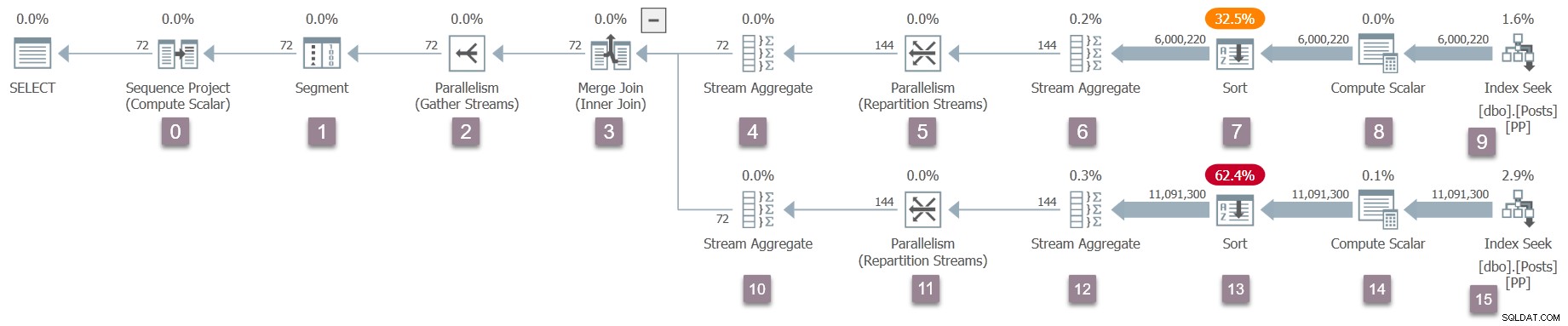
Това е първият момент в процеса досега, който е план за изпълнение по време на полет е наличен (SQL Server 2016 SP1 нататък) в sys.dm_exec_query_statistics_xml . В този момент няма нищо особено интересно да се види в такъв план, защото всички преходни броячи са нула, но планът е поне наличен . Няма намек, че все още не са създадени паралелни задачи или че борсите нямат страна на производител. Планът изглежда „нормален“ във всички отношения.
Разклонения на паралелния план
Тъй като това е паралелен план, ще бъде полезно да го покажете разбит на клонове. Те са засенчени по-долу и означени като клонове от A до D:
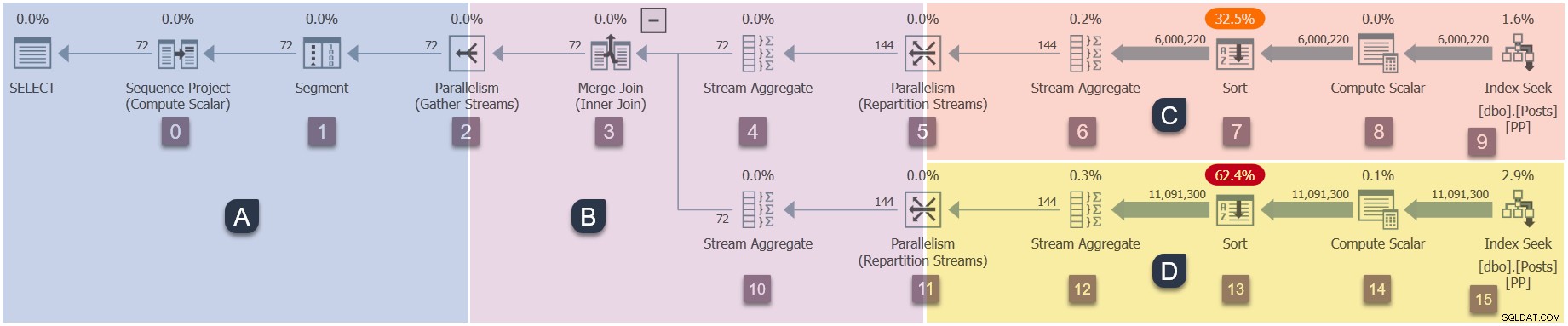
Клон А е свързан с родителската задача, изпълняваща се в работната нишка, предоставена от сесията. Допълнителни паралелни работници ще бъдат стартирани да изпълняват допълнителните паралелни задачи се съдържат в клонове B, C и D. Тези клонове са паралелни, така че във всеки от тях ще има допълнителни задачи и работници за DOP.
Нашата примерна заявка се изпълнява на DOP 2, така че клон B ще получи две допълнителни задачи. Същото важи и за клон C и клон D, което дава общо шест допълнителни задачи. Всяка задача ще се изпълнява в собствена работна нишка в собствен контекст на изпълнение.
Двасировчици (S1 и S2 ) са присвоени на тази заявка за изпълнение на допълнителни паралелни работници. Всеки допълнителен работник ще работи на един от тези два планировчика. Работникът-родител може да работи на различен планировчик, така че нашата заявка за DOP 2 може да използва максимум три процесорни ядра във всеки един момент от време.
За да обобщим, планът ни в крайна сметка ще има:
- Клон А (родител)
- Родителска задача.
- Родителска работна нишка.
- Нулев контекст на изпълнение.
- Всеки един планировчик, наличен за заявката.
- Клон Б (допълнително)
- Две допълнителни задачи.
- Допълнителна работна нишка, свързана с всяка нова задача.
- Два нови контекста на изпълнение, по един за всяка нова задача.
- Една работна нишка работи на планировчик S1 . Другият работи на планировчик S2 .
- Клон C (допълнително)
- Две допълнителни задачи.
- Допълнителна работна нишка, свързана с всяка нова задача.
- Два нови контекста на изпълнение, по един за всяка нова задача.
- Една работна нишка работи на планировчик S1 . Другият работи на планировчик S2 .
- Клон D (допълнително)
- Две допълнителни задачи.
- Допълнителна работна нишка, свързана с всяка нова задача.
- Два нови контекста на изпълнение, по един за всяка нова задача.
- Една работна нишка работи на планировчик S1 . Другият работи на планировчик S2 .
Въпросът е как се създават всички тези допълнителни задачи, работници и контексти за изпълнение и кога започват да се изпълняват.
Начална последователност
Последователността, в коятодопълнителни задачи започнете да изпълнявате за този конкретен план е:
- Клон А (родителска задача).
- Клон C (допълнителни паралелни задачи).
- Клон D (допълнителни паралелни задачи).
- Клон Б (допълнителни паралелни задачи).
Това може да не е поръчката за стартиране, която очаквахте.
Възможно е да има значително забавяне между всяка от тези стъпки, поради причини, които ще разгледаме скоро. Ключовият момент на този етап е, че допълнителните задачи, работници и контексти на изпълнение са не всички са създадени наведнъж, а те гоне всички започват да се изпълняват по едно и също време.
SQL Server може да е проектиран да стартира всички допълнителни паралелни битове наведнъж. Това може да е лесно за разбиране, но като цяло не би било много ефективно. Това ще увеличи максимално броя на допълнителните нишки и други ресурси, използвани от заявката, и ще доведе до много ненужни паралелни чакания.
С дизайна, използван от SQL Server, паралелните планове често използват по-малко общи работни нишки от (DOP, умножен по общия брой клонове). Това се постига чрез признаване, че някои клонове могат да работят до завършване, преди някой друг клон да трябва да започне. Това може да позволи повторно използване на нишки в рамките на една и съща заявка и като цяло намалява потреблението на ресурси.
Нека сега да се обърнем към подробностите за това как стартира нашият паралелен план.
Отварящ клон A
Сканирането на заявката започва да се изпълнява с родителската задача, извикваща Open() на итератора в корена на дървото. Това е началото на последователността на изпълнение:
- Клон А (родителска задача).
- Клон C (допълнителни паралелни задачи).
- Клон D (допълнителни паралелни задачи).
- Клон Б (допълнителни паралелни задачи).
Изпълняваме тази заявка с поискан „действителен“ план, така че основният итератор не операторът на проекта за последователност в възел 0. По-скоро това е невидимият профилиращ итератор който записва показатели за времето на изпълнение в планове за редов режим.
Илюстрацията по-долу показва итераторите за сканиране на заявка в клон А на плана, като позицията на невидимите профилиращи итератори е представена от иконите на „очила“.
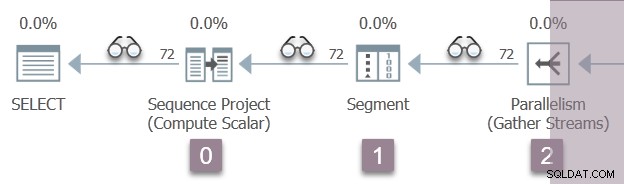
Изпълнението започва с повикване за отваряне на първия профайлър, CQScanProfileNew::Open . Това задава отворено време за оператора на проекта за дъщерна последователност чрез API на Query Performance Counter на операционната система.
Можем да видим този номер в sys.dm_exec_query_profiles :
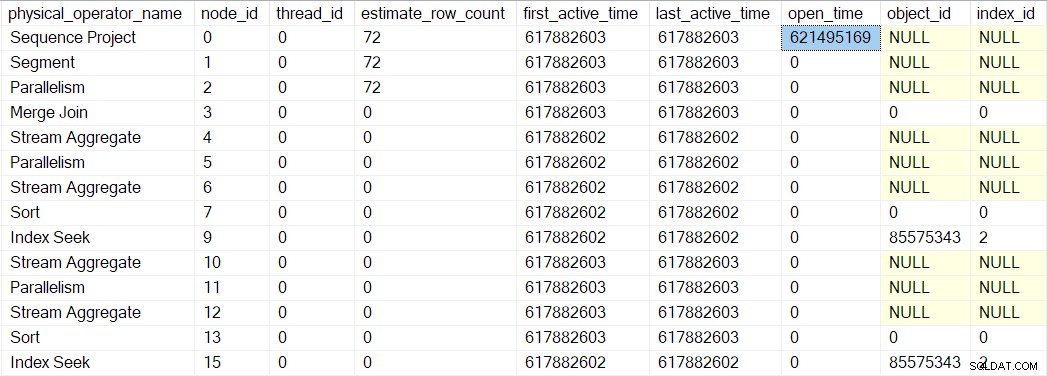
Записите там може да имат изброени имена на оператори, но данните идват от профилъра над оператора, а не самия оператор.
Както се случва, проектс последователност (CQScanSeqProjectNew ) не е необходимо да върши никаква работа, когато отворен , така че всъщност няма Open() метод. Профилизаторът над проекта за последователност е извикан, така че отворено време за последователния проект се записва в DMV.
Open на профайлъра методът не извиква Open в проекта за последователност (тъй като няма такъв). Вместо това извиква Open на профайлъра за следващия последователен итератор. Това е сегментът итератор на възел 1. Това задава времето за отваряне на сегмента, точно както предишният профайлър направи за проекта за последователност:
Итераторът на сегменти прави има какво да прави при отваряне, така че следващото извикване е CQScanSegmentNew::Open . След като сегментът направи това, което трябва, той извиква профайлъра за следващия итератор в последователност — потребителя страна на обмена на събиране на потоци на възел 2:
Следващото извикване надолу по дървото за сканиране на заявки в процеса на отваряне е CQScanExchangeNew::Open , откъдето нещата започват да стават по-интересни.
Отваряне на обмена за събиране на потоци
Искане на потребителската страна на борсата да отвори:
- Отваря локална (паралелно вложена) транзакция (
CXTransLocal::Open). Всеки процес се нуждае от съдържаща транзакция и допълнителните паралелни задачи не са изключение. Те не могат да споделят директно родителската (базовата) транзакция, така че се използват вложени транзакции. Когато паралелна задача трябва да получи достъп до основната транзакция, тя се синхронизира на ключалка и може да срещнеNESTING_TRANSACTION_READONLYилиNESTING_TRANSACTION_FULLчака. - Регистрира текущата работна нишка с порта за обмен (
CXPort::Register). - Синхронизира се с други нишки от страната на потребителя на обмена (
sqlmin!CXTransLocal::Synchronize). Няма други нишки от страна на потребителя на agather потоци, така че по същество това не е операция в този случай.
Обработка на „ранни фази“
Задачата-родител вече е достигнала ръба на клон А. Следващата стъпка е конкретна към паралелни планове в режим на ред:Родителската задача продължава изпълнението чрез извикване на CQScanExchangeNew::EarlyPhases на обменния итератор на събиране на потоци на възел 2. Това е допълнителен метод на итератор извън обичайния Open , GetRow и Close методи, с които много от вас ще са запознати. EarlyPhases се извиква само в редов режим на паралелни планове.
Искам да съм наясно с нещо в този момент:от страна на производителя на обмена на събиране на потоци на възел 2 не все още е създаден и не са създадени допълнителни паралелни задачи. Все още изпълняваме код за родителската задача, като използваме единствената нишка, която се изпълнява в момента.
Не всички итератори прилагат EarlyPhases , защото не всички от тях имат нещо специално за правене в този момент в редовия режим на паралелни планове. Това е аналогично на проекта за последователност, който не прилага Open метод, защото няма какво да прави в този момент. Основните итератори с EarlyPhases методите са:
CQScanConcatNew(конкатенация).CQScanMergeJoinNew(сливане на присъединяване).CQScanSwitchNew(превключвател).CQScanExchangeNew(паралелизъм).CQScanNew(достъп до набор от редове, напр. сканиране и търсене).CQScanProfileNew(невидими профили).CQScanLightProfileNew(невидими леки профили).
Ранни фази на клон B
Родителската задача продължава чрез извикване на EarlyPhases върху дъщерни оператори извън обмена на потоци за събиране на възел 2. Преместването на задача над границата на клон може да изглежда необичайно, но не забравяйте, че контекстът на изпълнение нула съдържа целия сериен план, с включени обмени. Ранната фазова обработка е свързана с инициализиране на паралелизъм, така че не се брои като изпълнение само по себе си .
За да ви помогне да следите, снимката по-долу показва итераторите в клон B на плана:
Не забравяйте, че все още сме в нулев контекст на изпълнение, така че наричам това само клон B за удобство. Ниене започнахме все още паралелно изпълнение.
Последователността от извиквания на код в ранна фаза в клон B е:
CQScanProfileNew::EarlyPhasesза профайлъра над възел 3.CQScanMergeJoinNew::EarlyPhasesна възел 3merge join .CQScanProfileNew::EarlyPhasesза профайлъра над възел 4. Възел 4агрегат на потока сама по себе си няма метод за ранни фази.CQScanProfileNew::EarlyPhasesна профайлъра над възел 5.CQScanExchangeNew::EarlyPhasesза потоците за преразпределяне обмен на възел 5.
Забележете, че на този етап обработваме само външния (горен) вход към обединението за сливане. Това е просто итеративната последователност на изпълнение на нормалния редов режим. Не е специално за паралелни планове.
Ранни фази на клон C
Ранната фазова обработка продължава с итераторите в клон C:

Последователността на повикванията тук е:
CQScanProfileNew::EarlyPhasesза профайлъра над възел 6.CQScanProfileNew::EarlyPhasesза профайлъра над възел 7.CQScanProfileNew::EarlyPhasesна профайлъра над възел 9.CQScanNew::EarlyPhasesза търсене на индекс на възел 9.
Няма EarlyPhases метод за агрегатиране или сортиране на потока. Работата, извършена от изчислителния скалар на възел 8, е отложена (към сортирането), така че не се появява в дървото за сканиране на заявката и няма свързан профилировчик.
Всичко за времето за профилиране
Родителска задача ранна фаза на обработка започна при обмена на събиране на потоци на възел 2. Той се спусна надолу по дървото за сканиране на заявки, следвайки външния (горен) вход към обединението за сливане, чак до търсенето на индекс на възел 9. По пътя родителската задача извика EarlyPhases метод на всеки итератор, който го поддържа.
Нито една от дейностите в ранните фази досега не е актуализирана по всяко време в профилиращия DMV. По-конкретно, нито един от итераторите, докоснати от обработката в ранните фази, не е имал свое „отворено време“. Това има смисъл, тъй като обработката в ранна фаза е просто настройка на паралелно изпълнение — тези оператори ще бъдат отворени за изпълнение по-късно.
Търсенето на индекс във възел 9 е листов възел – няма деца. Родителската задача сега започва да се връща от вложените EarlyPhases повиквания,възходящи дървото на заявката сканира обратно към обмена на събиране на потоци.
Всеки от профайлърите извиква Брояч на производителността на заявки API при влизане в техните EarlyPhases метод и те го извикват отново на излизане. Разликата между двете числа представлява изминало време за итератора и всички негови деца (тъй като извикванията на метода са вложени).
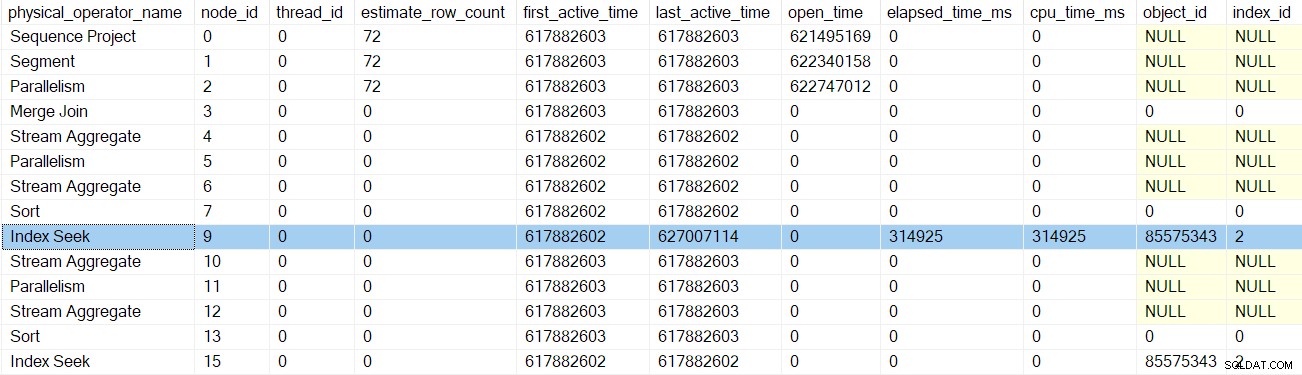
След като профайлърът за търсене на индекс се върне, DMV на профайлъра показва изтеклото и процесорното време за търсене на индекс само, както и актуализиран последен активен време. Забележете също, че тази информация се записва срещу родителската задача (единствената опция в момента):
Нито един от предишните итератори, докоснати от повикванията в ранните фази, не е изминал времена или не е актуализирал последните активни времена. Тези числа се актуализират само когато се изкачим на дървото.
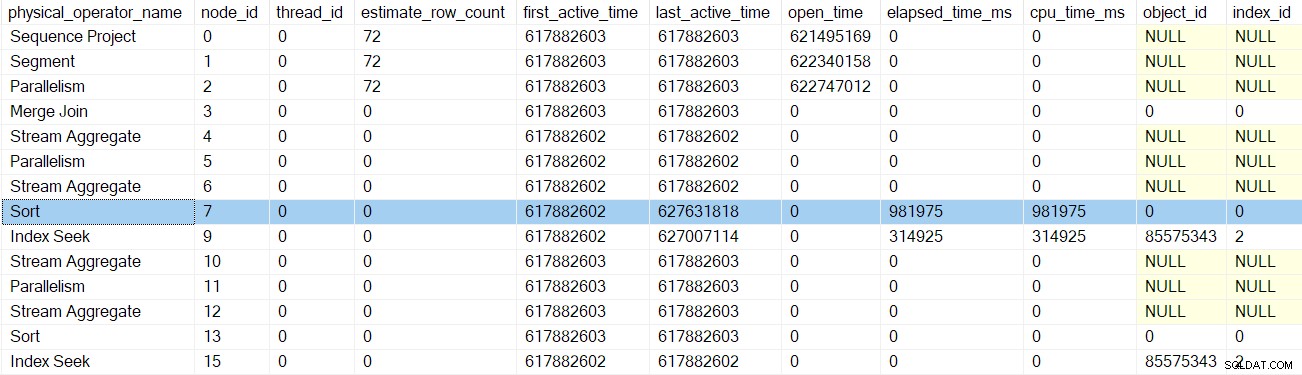
След ранните фази на следващия профайлър се обажда връщане, сортиране времената се актуализират:
Следващото връщане ни отвежда покрай профайлъра за агрегата на потока на възел 6:
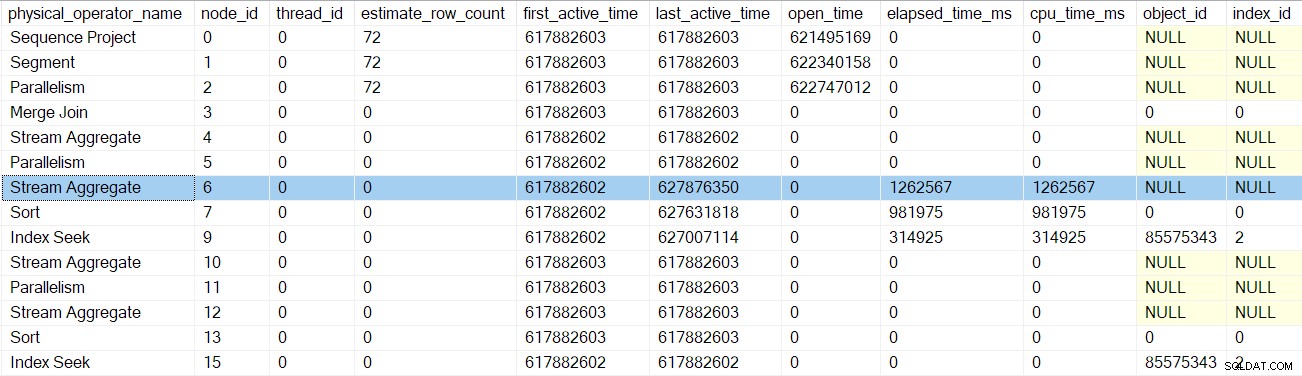
Връщането от този профайлър ни връща към EarlyPhases обадете се в потоците за преразпределяне обмен навъзел 5 . Не забравяйте, че това не е мястото, където започва последователността от извиквания в ранните фази — това е обменът на събиране на потоци на възел 2.
Поредени паралелни задачи на клон C
Освен актуализирането на данни за профилиране, предишните обаждания в ранните фази изглежда не са направили много. Всичко това се променя с потоците за преразпределяне обмен на възел 5.
Ще опиша клон C доста подробно, за да представя редица важни понятия, които ще важат и за другите паралелни клонове. Покриването на тази основа веднъж сега означава, че по-късната дискусия в клона може да бъде по-сбита.
След като завърши обработката на вложена ранна фаза за своето поддърво (до търсенето на индекс на възел 9), обменът може да започне своя собствена работа в ранна фаза. Това започва по същия начин като отварянето събирането на потоци се обменя на възел 2:
CXTransLocal::Open(отваряне на локалната паралелна подтранзакция).CXPort::Register(регистриране в порта за обмен).
Следващите стъпки са различни, защото клон C съдържа напълно блокиране итератор (сортирането на възел 7). Ранната фазова обработка в потоците за преразпределяне на възел 5 прави следното:
- Обажда
CQScanExchangeNew::StartAllProducers. Това е първият път, когато се сблъскаме с нещо, отнасящо се до продуцентската страна на борсата. Node 5 е първата борса в този план, която създава своя производител. - Придобива мютекс така че никоя друга нишка не може да поставя задачи в опашка по едно и също време.
- Стартира паралелни вложени транзакции за задачите на производителя (
CXPort::StartNestedTransactionsиReadOnlyXactImp::BeginParallelNestedXact). - Регистрира подтранзакциите с обекта за сканиране на родителска заявка (
CQueryScan::AddSubXact). - Създава дескриптори на производител (
CQScanExchangeNew::PxproddescCreate). - Създава нови контексти за изпълнение на производител (
CExecContext) извлечен от нулев контекст на изпълнение. - Актуализира свързаната карта на итераторите на план.
- Задава DOP за новия контекст (
CQueryExecContext::SetDop), така че всички задачи да знаят каква е общата настройка на DOP. - Инициализира кеша на параметрите (
CQueryExecContext::InitParamCache). - Свързва паралелно вложените транзакции с основната транзакция (
CExecContext::SetBaseXact). - Поставя на опашка новите подпроцеси за изпълнение (
SubprocessMgr::EnqueueMultipleSubprocesses). - Създава нови паралелни задачи задачи чрез
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
Стекът от обаждания на родителската задача (за тези от вас, които харесват тези неща) към този момент е:
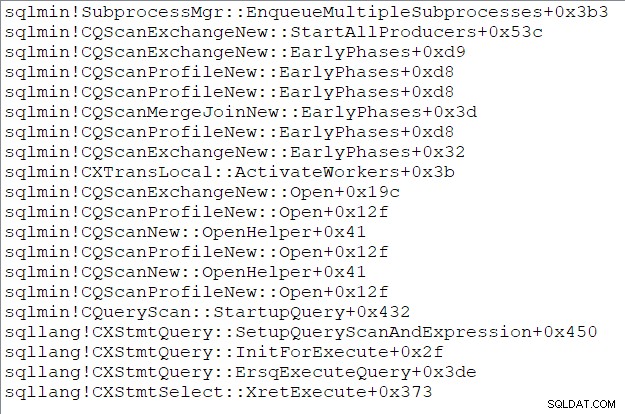
Край на трета част
Вече създадохме продуцентската страна на обмен на потоци за преразпределение на възел 5, създаде допълнителни паралелни задачи за да стартирате клон C и свърза всичко обратно с родител структури според изискванията. Клон C е първият клон, за да стартирате всички паралелни задачи. Последната част от тази серия ще разгледа подробно отварянето на клон C и ще стартира останалите паралелни задачи.